4.1 KiB
Run Ollama on Linux with Intel GPU
ollama/ollama is popular framework designed to build and run language models on a local machine; you can now use the C++ interface of ipex-llm as an accelerated backend for ollama running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max).
.. note::
Only Linux is currently supported.
See the demo of running LLaMA2-7B on Intel Arc GPU below.
Quickstart
1 Install IPEX-LLM with Ollama Binaries
Visit Run llama.cpp with IPEX-LLM on Intel GPU Guide, and follow the instructions in section Install Prerequisits on Linux , and section Install IPEX-LLM cpp to install the IPEX-LLM with Ollama binaries.
After the installation, you should have created a conda environment, named llm-cpp for instance, for running llama.cpp commands with IPEX-LLM.
2. Initialize Ollama
Activate the llm-cpp conda environment and initialize Ollama by executing the commands below. A symbolic link to ollama will appear in your current directory.
conda activate llm-cpp
init-ollama
3 Run Ollama Serve
Launch the Ollama service:
conda activate llm-cpp
export no_proxy=localhost,127.0.0.1
export ZES_ENABLE_SYSMAN=1
source /opt/intel/oneapi/setvars.sh
./ollama serve
.. note::
To allow the service to accept connections from all IP addresses, use `OLLAMA_HOST=0.0.0.0 ./ollama serve` instead of just `./ollama serve`.
The console will display messages similar to the following:

4 Pull Model
Keep the Ollama service on and open another terminal and run ./ollama pull <model_name> to automatically pull a model. e.g. dolphin-phi:latest:

5 Using Ollama
Using Curl
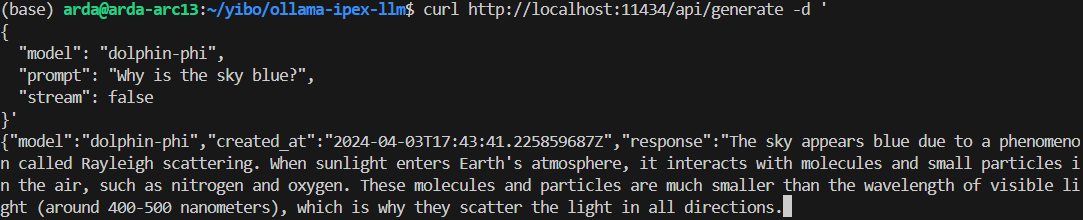
Using curl is the easiest way to verify the API service and model. Execute the following commands in a terminal. Replace the <model_name> with your pulled model, e.g. dolphin-phi.
curl http://localhost:11434/api/generate -d '
{
"model": "<model_name>",
"prompt": "Why is the sky blue?",
"stream": false
}'
An example output of using model doplphin-phi looks like the following:
Using Ollama Run
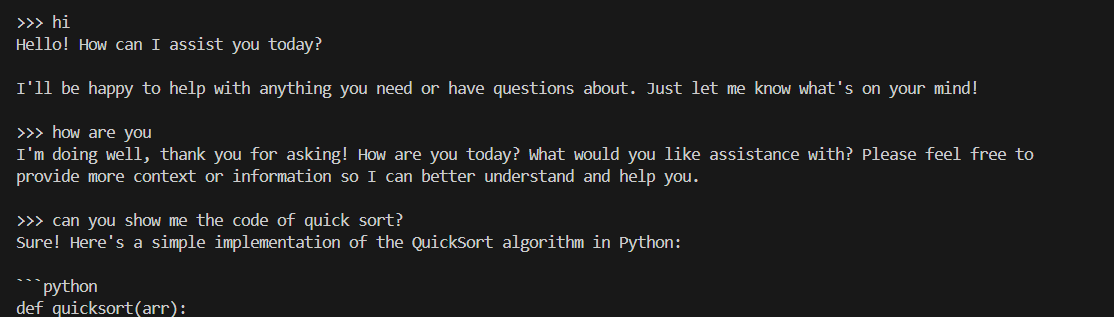
You can also use ollama run to run the model directly on console. Replace the <model_name> with your pulled model, e.g. dolphin-phi. This command will seamlessly download, load the model, and enable you to interact with it through a streaming conversation."
conda activate llm-cpp
export no_proxy=localhost,127.0.0.1
export ZES_ENABLE_SYSMAN=1
source /opt/intel/oneapi/setvars.sh
./ollama run <model_name>
An example process of interacting with model with ollama run looks like the following: