* refactor toc * refactor toc * Change to pydata-sphinx-theme and update packages requirement list for ReadtheDocs * Remove customized css for old theme * Add index page to each top bar section and limit dropdown maximum to be 4 * Use js to change 'More' to 'Libraries' * Add custom.css to conf.py for further css changes * Add BigDL logo and search bar * refactor toc * refactor toc and add overview * refactor toc and add overview * refactor toc and add overview * refactor get started * add paper and video section * add videos * add grid columns in landing page * add document roadmap to index * reapply search bar and github icon commit * reorg orca and chronos sections * Test: weaken ads by js * update: change left attrbute * update: add comments * update: change opacity to 0.7 * Remove useless theme template override for old theme * Add sidebar releases component in the home page * Remove sidebar search and restore top nav search button * Add BigDL handouts * Add back to homepage button to pages except from the home page * Update releases contents & styles in left sidebar * Add version badge to the top bar * Test: weaken ads by js * update: add comments * remove landing page contents * rfix chronos install * refactor install * refactor chronos section titles * refactor nano index * change chronos landing * revise chronos landing page * add document navigator to nano landing page * revise install landing page * Improve css of versions in sidebar * Make handouts image pointing to a page in new tab * add win guide to install * add dliib installation * revise title bar * rename index files * add index page for user guide * add dllib and orca API * update user guide landing page * refactor side bar * Remove extra style configuration of card components & make different card usage consistent * Remove extra styles for Nano how-to guides * Remove extra styles for Chronos how-to guides * Remove dark mode for now * Update index page description * Add decision tree for choosing BigDL libraries in index page * add dllib models api, revise core layers formats * Change primary & info color in light mode * Restyle card components * Restructure Chronos landing page * Update card style * Update BigDL library selection decision tree * Fix failed Chronos tutorials filter * refactor PPML documents * refactor and add friesian documents * add friesian arch diagram * update landing pages and fill key features guide index page * Restyle link card component * Style video frames in PPML sections * Adjust Nano landing page * put api docs to the last in index for convinience * Make badge horizontal padding smaller & small changes * Change the second letter of all header titles to be small capitalizd * Small changes on Chronos index page * Revise decision tree to make it smaller * Update: try to change the position of ads. * Bugfix: deleted nonexist file config * Update: update ad JS/CSS/config * Update: change ad. * Update: delete my template and change files. * Update: change chronos installation table color. * Update: change table font color to --pst-color-primary-text * Remove old contents in landing page sidebar * Restyle badge for usage in card footer again * Add quicklinks template on landing page sidebar * add quick links * Add scala logo * move tf, pytorch out of the link * change orca key features cards * fix typo * fix a mistake in wording * Restyle badge for card footer * Update decision tree * Remove useless html templates * add more api docs and update tutorials in dllib * update chronos install using new style * merge changes in nano doc from master * fix quickstart links in sidebar quicklinks * Make tables responsive * Fix overflow in api doc * Fix list indents problems in [User guide] section * Further fixes to nested bullets contents in [User Guide] section * Fix strange title in Nano 5-min doc * Fix list indent problems in [DLlib] section * Fix misnumbered list problems and other small fixes for [Chronos] section * Fix list indent problems and other small fixes for [Friesian] section * Fix list indent problem and other small fixes for [PPML] section * Fix list indent problem for developer guide * Fix list indent problem for [Cluster Serving] section * fix dllib links * Fix wrong relative link in section landing page Co-authored-by: Yuwen Hu <yuwen.hu@intel.com> Co-authored-by: Juntao Luo <1072087358@qq.com>
9.5 KiB
PPML End-to-End Workflow Example
E2E Architecture Overview
In this section we take SimpleQuery as an example to go through the entire BigDL PPML end-to-end workflow. SimpleQuery is simple example to query developers between the ages of 20 and 40 from people.csv.

Step 0. Preparation your environment
To secure your Big Data & AI applications in BigDL PPML manner, you should prepare your environment first, including K8s cluster setup, K8s-SGX plugin setup, key/password preparation, key management service (KMS) and attestation service (AS) setup, BigDL PPML client container preparation. Please follow the detailed steps in Prepare Environment.
Step 1. Encrypt and Upload Data
Encrypt the input data of your Big Data & AI applications (here we use SimpleQuery) and then upload encrypted data to the nfs server. More details in Encrypt Your Data.
-
Generate the input data
people.csvfor SimpleQuery application you can use generate_people_csv.py. The usage command of the script ispython generate_people.py </save/path/of/people.csv> <num_lines>. -
Encrypt
people.csvdocker exec -i $KMSUTIL_CONTAINER_NAME bash -c "bash /home/entrypoint.sh encrypt $appid $apikey $input_file_path"
Step 2. Build Big Data & AI applications
To build your own Big Data & AI applications, refer to develop your own Big Data & AI applications with BigDL PPML. The code of SimpleQuery is in here, it is already built into bigdl-ppml-spark_3.1.2-2.1.0-SNAPSHOT.jar, and the jar is put into PPML image.
Step 3. Attestation
To enable attestation, you should have a running Attestation Service (EHSM-KMS here for example) in your environment. (You can start a KMS refering to this link). Configure your KMS app_id and app_key with kubectl, and then configure KMS settings in spark-driver-template.yaml and spark-executor-template.yaml in the container.
kubectl create secret generic kms-secret --from-literal=app_id=your-kms-app-id --from-literal=app_key=your-kms-app-key
Configure spark-driver-template.yaml for example. (spark-executor-template.yaml is similar)
apiVersion: v1
kind: Pod
spec:
containers:
- name: spark-driver
securityContext:
privileged: true
env:
- name: ATTESTATION
value: true
- name: ATTESTATION_URL
value: your_attestation_url
- name: ATTESTATION_ID
valueFrom:
secretKeyRef:
name: kms-secret
key: app_id
- name: ATTESTATION_KEY
valueFrom:
secretKeyRef:
name: kms-secret
key: app_key
...
You should get Attestation Success! in logs after you submit a PPML job if the quote generated with user report is verified successfully by Attestation Service, or you will get Attestation Fail! Application killed! and the job will be stopped.
Step 4. Submit Job
When the Big Data & AI application and its input data is prepared, you are ready to submit BigDL PPML jobs. You need to choose the deploy mode and the way to submit job first.
-
There are 4 modes to submit job:
-
local mode: run jobs locally without connecting to cluster. It is exactly same as using spark-submit to run your application:
$SPARK_HOME/bin/spark-submit --class "SimpleApp" --master local[4] target.jar, driver and executors are not protected by SGX.
-
local SGX mode: run jobs locally with SGX guarded. As the picture shows, the client JVM is running in a SGX Enclave so that driver and executors can be protected.

-
client SGX mode: run jobs in k8s client mode with SGX guarded. As we know, in K8s client mode, the driver is deployed locally as an external client to the cluster. With client SGX mode, the executors running in K8S cluster are protected by SGX, the driver running in client is also protected by SGX.

-
cluster SGX mode: run jobs in k8s cluster mode with SGX guarded. As we know, in K8s cluster mode, the driver is deployed on the k8s worker nodes like executors. With cluster SGX mode, the driver and executors running in K8S cluster are protected by SGX.

-
-
There are two options to submit PPML jobs:
- use PPML CLI to submit jobs manually
- use helm chart to submit jobs automatically
Here we use k8s client mode and PPML CLI to run SimpleQuery. Check other modes, please see PPML CLI Usage Examples. Alternatively, you can also use Helm to submit jobs automatically, see the details in Helm Chart Usage.
expand to see details of submitting SimpleQuery
-
enter the ppml container
docker exec -it bigdl-ppml-client-k8s bash -
run simplequery on k8s client mode
#!/bin/bash export secure_password=`openssl rsautl -inkey /ppml/trusted-big-data-ml/work/password/key.txt -decrypt </ppml/trusted-big-data-ml/work/password/output.bin` bash bigdl-ppml-submit.sh \ --master $RUNTIME_SPARK_MASTER \ --deploy-mode client \ --sgx-enabled true \ --sgx-log-level error \ --sgx-driver-memory 64g \ --sgx-driver-jvm-memory 12g \ --sgx-executor-memory 64g \ --sgx-executor-jvm-memory 12g \ --driver-memory 32g \ --driver-cores 8 \ --executor-memory 32g \ --executor-cores 8 \ --num-executors 2 \ --conf spark.kubernetes.container.image=$RUNTIME_K8S_SPARK_IMAGE \ --name simplequery \ --verbose \ --class com.intel.analytics.bigdl.ppml.examples.SimpleQuerySparkExample \ --jars local:///ppml/trusted-big-data-ml/spark-encrypt-io-0.3.0-SNAPSHOT.jar \ local:///ppml/trusted-big-data-ml/work/data/simplequery/spark-encrypt-io-0.3.0-SNAPSHOT.jar \ --inputPath /ppml/trusted-big-data-ml/work/data/simplequery/people_encrypted \ --outputPath /ppml/trusted-big-data-ml/work/data/simplequery/people_encrypted_output \ --inputPartitionNum 8 \ --outputPartitionNum 8 \ --inputEncryptModeValue AES/CBC/PKCS5Padding \ --outputEncryptModeValue AES/CBC/PKCS5Padding \ --primaryKeyPath /ppml/trusted-big-data-ml/work/data/simplequery/keys/primaryKey \ --dataKeyPath /ppml/trusted-big-data-ml/work/data/simplequery/keys/dataKey \ --kmsType EHSMKeyManagementService --kmsServerIP your_ehsm_kms_server_ip \ --kmsServerPort your_ehsm_kms_server_port \ --ehsmAPPID your_ehsm_kms_appid \ --ehsmAPIKEY your_ehsm_kms_apikey -
check runtime status: exit the container or open a new terminal
To check the logs of the Spark driver, run
sudo kubectl logs $( sudo kubectl get pod | grep "simplequery.*-driver" -m 1 | cut -d " " -f1 )To check the logs of an Spark executor, run
sudo kubectl logs $( sudo kubectl get pod | grep "simplequery-.*-exec" -m 1 | cut -d " " -f1 ) -
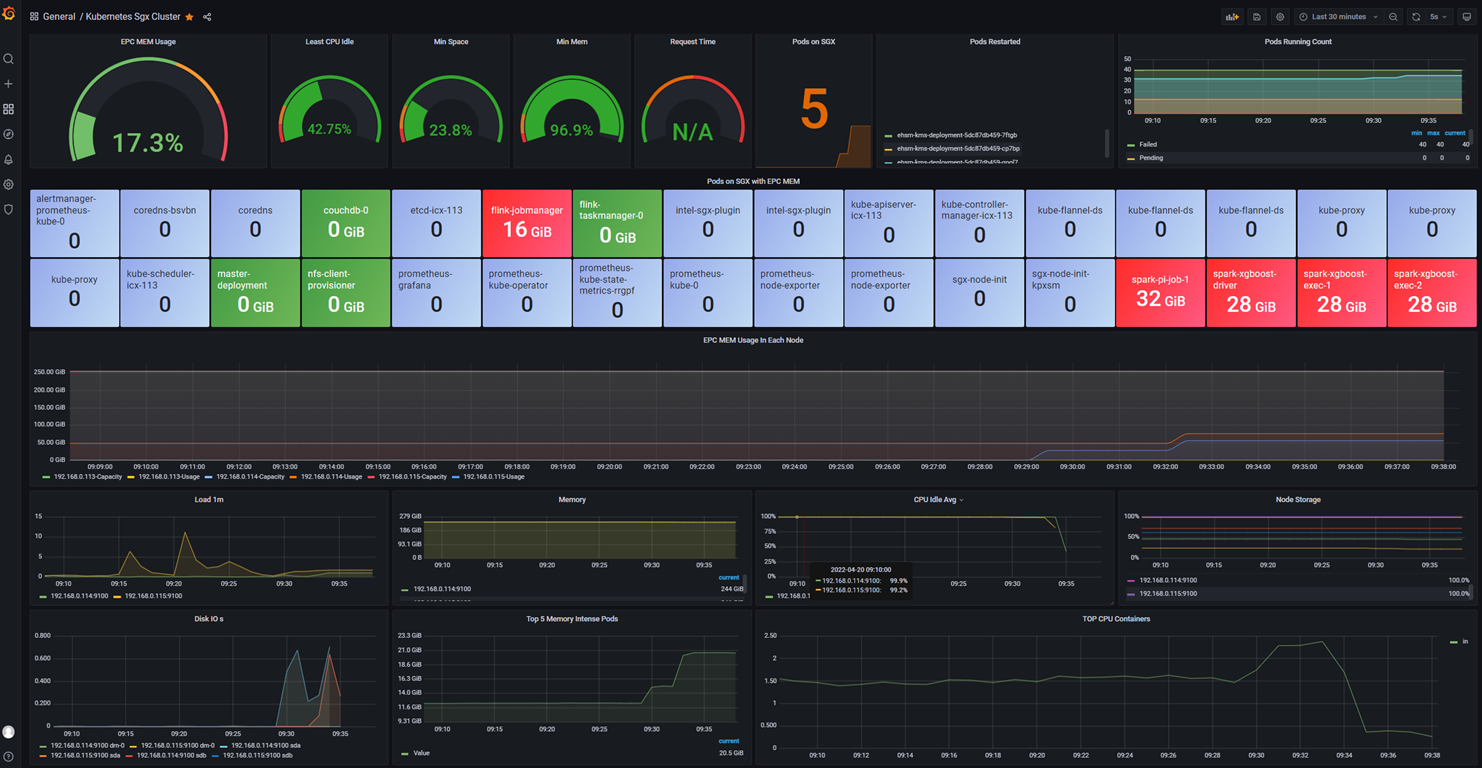
If you setup PPML Monitoring, you can check PPML Dashboard to monitor the status in http://kubernetes_master_url:3000
Step 5. Decrypt and Read Result
When the job is done, you can decrypt and read result of the job. More details in Decrypt Job Result.
docker exec -i $KMSUTIL_CONTAINER_NAME bash -c "bash /home/entrypoint.sh decrypt $appid $apikey $input_path"