57 lines
4.4 KiB
Markdown
57 lines
4.4 KiB
Markdown
## Run BF16-Optimized Lora Finetuning on Kubernetes with OneCCL
|
||
|
||
[Alpaca Lora](https://github.com/tloen/alpaca-lora/tree/main) uses [low-rank adaption](https://arxiv.org/pdf/2106.09685.pdf) to speed up the finetuning process of base model [Llama2-7b](https://huggingface.co/meta-llama/Llama-2-7b), and tries to reproduce the standard Alpaca, a general finetuned LLM. This is on top of Hugging Face transformers with Pytorch backend, which natively requires a number of expensive GPU resources and takes significant time.
|
||
|
||
By constract, IPEX-LLM here provides a CPU optimization to accelerate the lora finetuning of Llama2-7b, in the power of mixed-precision and distributed training. Detailedly, [Intel OneCCL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/oneccl.html), an available Hugging Face backend, is able to speed up the Pytorch computation with BF16 datatype on CPUs, as well as parallel processing on Kubernetes enabled by [Intel MPI](https://www.intel.com/content/www/us/en/developer/tools/oneapi/mpi-library.html).
|
||
|
||
The architecture is illustrated in the following:
|
||
|
||
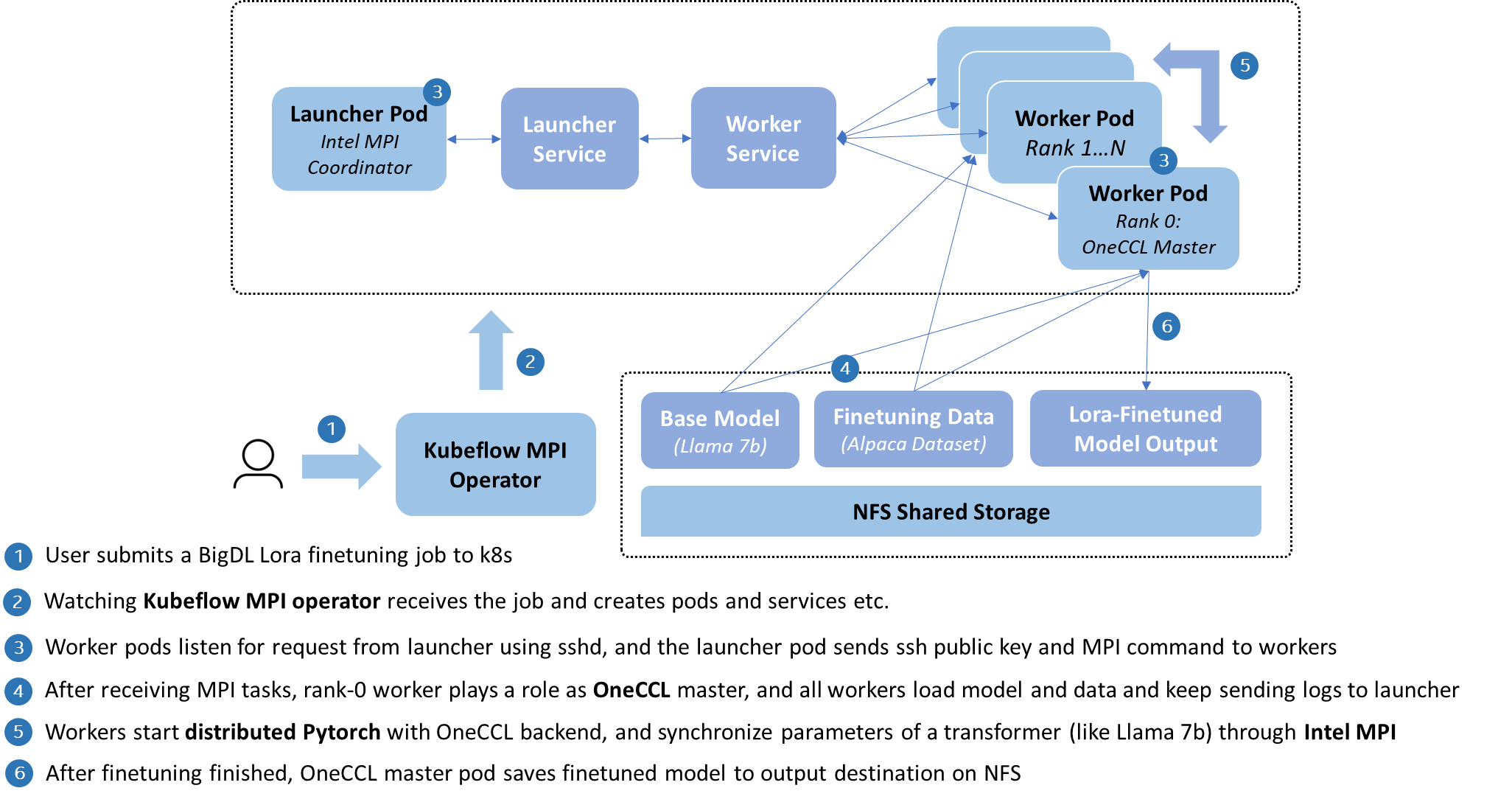
|
||
|
||
As above, IPEX-LLM implements its MPI training with [Kubeflow MPI operator](https://github.com/kubeflow/mpi-operator/tree/master), which encapsulates the deployment as MPIJob CRD, and assists users to handle the construction of a MPI worker cluster on Kubernetes, such as public key distribution, SSH connection, and log collection.
|
||
|
||
Now, let's go to deploy a Lora finetuning to create a LLM from Llama2-7b.
|
||
|
||
**Note: Please make sure you have already have an available Kubernetes infrastructure and NFS shared storage, and install [Helm CLI](https://helm.sh/docs/helm/helm_install/) for Kubernetes job submission.**
|
||
|
||
### 1. Install Kubeflow MPI Operator
|
||
|
||
Follow [here](https://github.com/kubeflow/mpi-operator/tree/master#installation) to install a Kubeflow MPI operator in your Kubernetes, which will listen and receive the following MPIJob request at backend.
|
||
|
||
### 2. Download Image, Base Model and Finetuning Data
|
||
|
||
Follow [here](https://github.com/intel-analytics/IPEX-LLM/tree/main/docker/llm/finetune/lora/docker#prepare-ipex-llm-image-for-lora-finetuning) to prepare IPEX-LLM Lora Finetuning image in your cluster.
|
||
|
||
As finetuning is from a base model, first download [Llama2-7b model from the public download site of Hugging Face](https://huggingface.co/meta-llama/Llama-2-7b). Then, download [cleaned alpaca data](https://raw.githubusercontent.com/tloen/alpaca-lora/main/alpaca_data_cleaned_archive.json), which contains all kinds of general knowledge and has already been cleaned. Next, move the downloaded files to a shared directory on your NFS server.
|
||
|
||
### 3. Deploy through Helm Chart
|
||
|
||
You are allowed to edit and experiment with different parameters in `./kubernetes/values.yaml` to improve finetuning performance and accuracy. For example, you can adjust `trainerNum` and `cpuPerPod` according to node and CPU core numbers in your cluster to make full use of these resources, and different `microBatchSize` result in different training speed and loss (here note that `microBatchSize`×`trainerNum` should not more than 128, as it is the batch size).
|
||
|
||
**Note: `dataSubPath` and `modelSubPath` need to have the same names as files under the NFS directory in step 2.**
|
||
|
||
After preparing parameters in `./kubernetes/values.yaml`, submit the job as beflow:
|
||
|
||
```bash
|
||
cd ./kubernetes
|
||
helm install ipex-llm-lora-finetuning .
|
||
```
|
||
|
||
### 4. Check Deployment
|
||
```bash
|
||
kubectl get all -n ipex-llm-lora-finetuning # you will see launcher and worker pods running
|
||
```
|
||
|
||
### 5. Check Finetuning Process
|
||
|
||
After deploying successfully, you can find a launcher pod, and then go inside this pod and check the logs collected from all workers.
|
||
|
||
```bash
|
||
kubectl get all -n ipex-llm-lora-finetuning # you will see a launcher pod
|
||
kubectl exec -it <launcher_pod_name> bash -n ipex-llm-lora-finetuning # enter launcher pod
|
||
cat launcher.log # display logs collected from other workers
|
||
```
|
||
|
||
From the log, you can see whether finetuning process has been invoked successfully in all MPI worker pods, and a progress bar with finetuning speed and estimated time will be showed after some data preprocessing steps (this may take quiet a while).
|
||
|
||
For the fine-tuned model, it is written by the worker 0 (who holds rank 0), so you can find the model output inside the pod, which can be saved to host by command tools like `kubectl cp` or `scp`.
|