6.9 KiB
Run Coding Copilot in VSCode with Intel GPU
Continue is a coding copilot extension in Microsoft Visual Studio Code; by porting it to ipex-llm, users can now easily leverage local LLMs running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) for code explanation, code generation/completion, etc.
See the demos of using Continue with Mistral-7B-Instruct-v0.1 running on Intel A770 GPU below.
| Code Generation | Code Explanation |
Quickstart
This guide walks you through setting up and running Continue within Visual Studio Code, empowered by local large language models served via Ollama with ipex-llm optimizations.
1. Install and Run Ollama Serve
Visit Run Ollama with IPEX-LLM on Intel GPU, and follow the steps 1) Install IPEX-LLM for Ollama, 2) Initialize Ollama and 3) Run Ollama Serve to install and initialize and start the Ollama Service.
.. important::
Please make sure you have set ``OLLAMA_HOST=0.0.0.0`` before starting the Ollama service, so that connections from all IP addresses can be accepted.
.. tip::
If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS, it is recommended to additionaly set the following environment variable for optimal performance before the Ollama service is started:
.. code-block:: bash
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
2. Prepare and Run Model
Pull codeqwen:latest
In a new terminal window:
.. tabs::
.. tab:: Linux
.. code-block:: bash
export no_proxy=localhost,127.0.0.1
./ollama pull codeqwen:latest
.. tab:: Windows
Please run the following command in Anaconda Prompt.
.. code-block:: cmd
set no_proxy=localhost,127.0.0.1
ollama pull codeqwen:latest
.. seealso::
Here's a list of models that can be used for coding copilot on local PC:
- Code Llama:
- WizardCoder
- Mistral
- StarCoder
- DeepSeek Coder
You could find them in the `Ollama model library <https://ollama.com/library>`_ and have a try.
Create and Run Model
First, create a Modelfile file with contents:
FROM codeqwen:latest
PARAMETER num_ctx 4096
then:
.. tabs::
.. tab:: Linux
.. code-block:: bash
./ollama create codeqwen:latest-continue -f Modelfile
.. tab:: Windows
Please run the following command in Anaconda Prompt.
.. code-block:: cmd
ollama create codeqwen:latest-continue -f Modelfile
You can now find codeqwen:latest-continue in ollama list.
Finially, run the codeqwen:latest-continue:
.. tabs::
.. tab:: Linux
.. code-block:: bash
./ollama run codeqwen:latest-continue
.. tab:: Windows
Please run the following command in Anaconda Prompt.
.. code-block:: cmd
ollama run codeqwen:latest-continue
3. Install Continue Extension
- Click
Installon the Continue extension in the Visual Studio Marketplace - This will open the Continue extension page in VS Code, where you will need to click
Installagain - Once you do this, you will see the Continue logo show up on the left side bar. If you click it, the Continue extension will open up:
.. note::
Note: We strongly recommend moving Continue to VS Code's right sidebar. This helps keep the file explorer open while using Continue, and the sidebar can be toggled with a simple keyboard shortcut.
4. Configure Continue
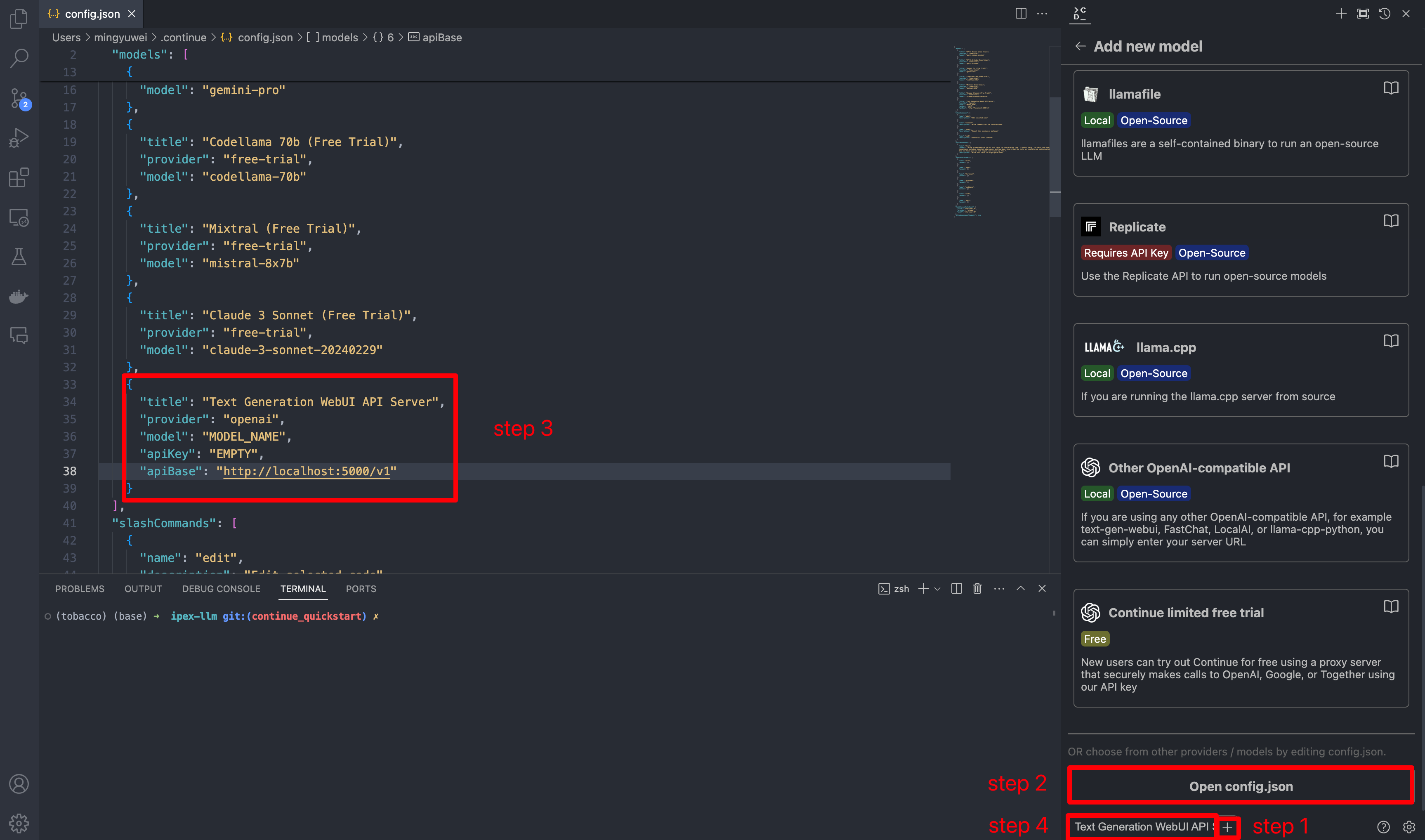
Once you've started the API server, you can now use your local LLMs on Continue. After opening Continue(you can either click the extension icon on the left sidebar or press Ctrl+Shift+L), you can click the + button next to the model dropdown, and scroll down to the bottom and click Open config.json.
In config.json, you'll find the models property, a list of the models that you have saved to use with Continue. Please add the following configuration to models. Note that model, apiKey, apiBase should align with what you specified when starting the Text Generation WebUI server. Finally, remember to select this model in the model dropdown menu.
{
"models": [
{
"title": "Text Generation WebUI API Server",
"provider": "openai",
"model": "MODEL_NAME",
"apiKey": "EMPTY",
"apiBase": "http://localhost:5000/v1"
}
]
}
5. How to Use Continue
For detailed tutorials please refer to this link. Here we are only showing the most common scenarios.
Ask about highlighted code or an entire file
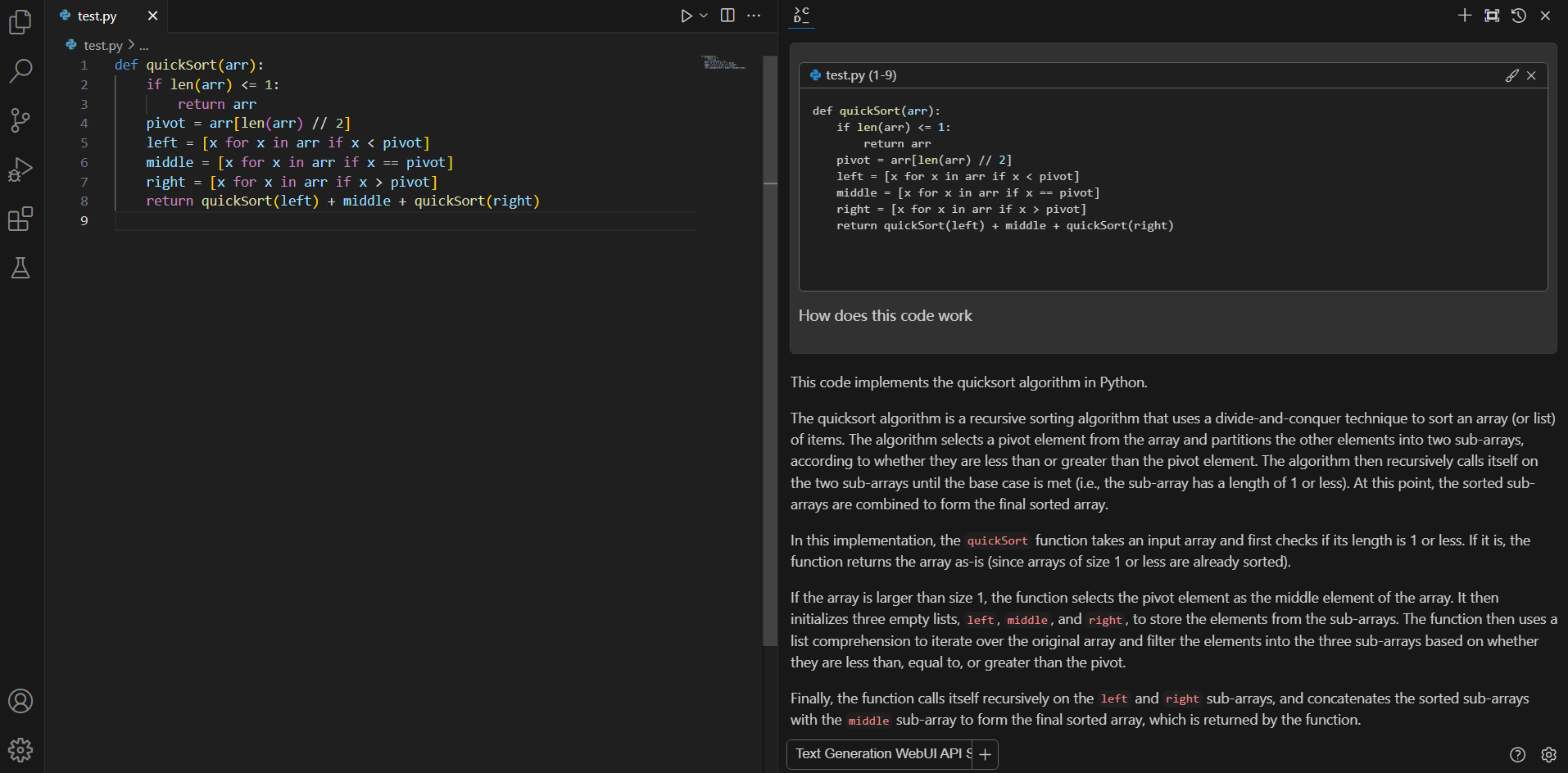
If you don't understand how some code works, highlight(press Ctrl+Shift+L) it and ask "how does this code work?"
Editing existing code
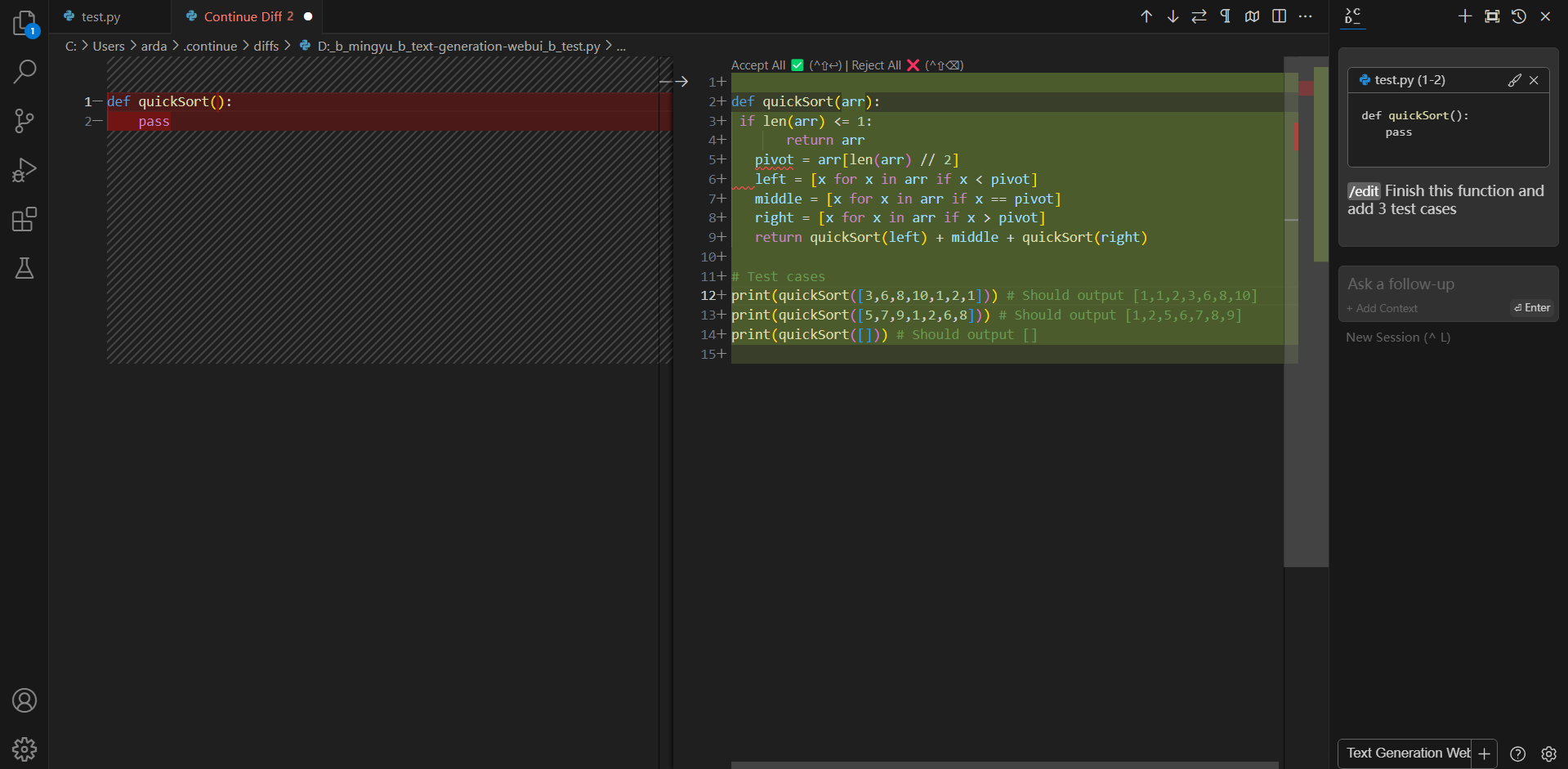
You can ask Continue to edit your highlighted code with the command /edit.
Troubleshooting
Failed to load the extension openai
If you encounter TypeError: unsupported operand type(s) for |: 'type' and 'NoneType' when you run python server.py --load-in-4bit --api, please make sure you are using Python 3.11 instead of lower versions.