* Update install_windows_gpu.md * Update install_windows_gpu.md * Update install_windows_gpu.md * fix numbering * Update install_windows_gpu.md * Update install_windows_gpu.md
6.5 KiB
Install BigDL-LLM on Windows for Intel GPU
This guide demonstrates how to install BigDL-LLM on Windows with Intel GPUs.
This process applies to Intel Core Ultra and Core 12 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU.
Install GPU driver
-
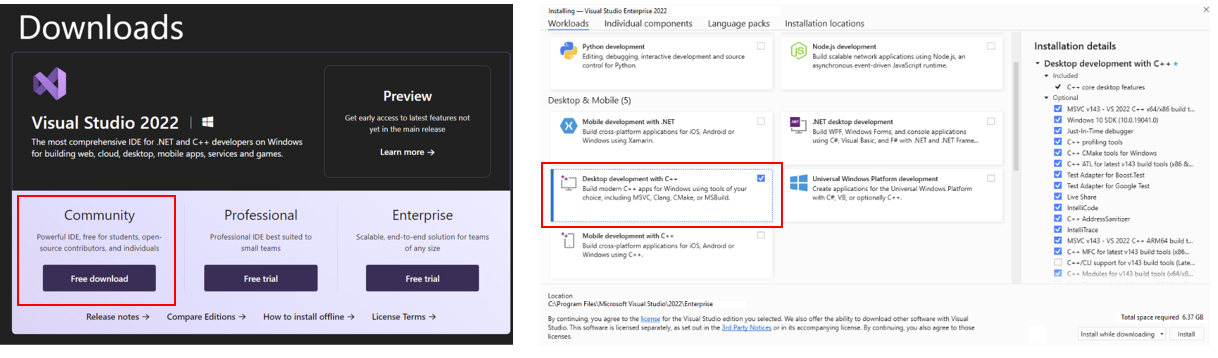
Download and Install Visual Studio 2022 Community Edition from the official Microsoft Visual Studio website. Ensure you select the Desktop development with C++ workload during the installation process.
Note: The installation could take around 15 minutes, and requires at least 7GB of free disk space. If you accidentally skip adding the Desktop development with C++ workload during the initial setup, you can add it afterward by navigating to Tools > Get Tools and Features.... Follow the instructions on this Microsoft guide to update your installation.
-
Download and install the latest GPU driver from the official Intel download page. A system reboot is necessary to apply the changes after the installation is complete.
Note: the process could take around 10 minutes. After reboot, check for the Intel Arc Control application to verify the driver has been installed correctly. If the installation was successful, you should see the Arc Control interface similar to the figure below

-
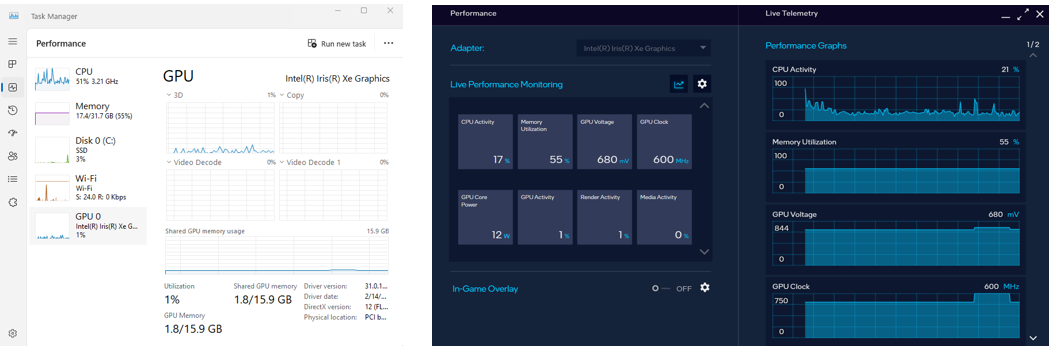
To monitor your GPU's performance and status, you can use either use the Windows Task Manager (see the left side of the figure below) or the Arc Control application (see the right side of the figure below) or :
Setup Python Environment
-
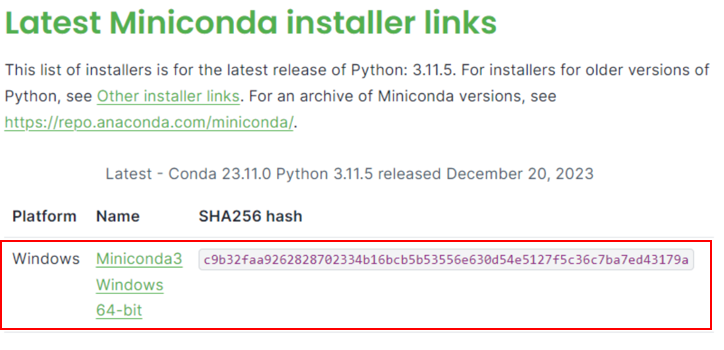
Visit Miniconda installation page, download the Miniconda installer for Windows, and follow the instructions to complete the installation.
-
After installation, open the Anaconda Prompt, create a new python environment
llm:conda create -n llm python=3.9 libuv -
Activate the newly created environment
llm:conda activate llm
Install oneAPI
- With the
llmenvironment active, usepipto install the Intel oneAPI Base Toolkit:pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0
Install bigdl-llm
-
With the
llmenvironment active, usepipto installbigdl-llmfor GPU: Choose either US or CN website for extra index url:- US:
pip install --pre --upgrade bigdl-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ - CN:
pip install --pre --upgrade bigdl-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/
Note: If there are network issues when installing IPEX, refer to this guide for more details.
- US:
-
You can verfy if bigdl-llm is successfully by simply importing a few classes from the library. For example, in the Python interactive shell, execute the following import command:
from bigdl.llm.transformers import AutoModel,AutoModelForCausalLM
A quick example
Now let's play with a real LLM. We'll be using the phi-1.5 model, a 1.3 billion parameter LLM for this demostration. Follow the steps below to setup and run the model, and observe how it responds to a prompt "What is AI?".
-
Step 1: Open the Anaconda Prompt and activate the Python environment
llmyou previously created:conda activate llm -
Step 2: If you're running on integrated GPU, set some environment variables by running below commands:
For more details about runtime configurations, refer to this guide:
set SYCL_CACHE_PERSISTENT=1 set BIGDL_LLM_XMX_DISABLED=1 -
Step 3: To ensure compatibility with
phi-1.5, update the transformers library to version 4.37.0:pip install -U transformers==4.37.0 -
Step 4: Create a new file named
demo.pyand insert the code snippet below.# Copy/Paste the contents to a new file demo.py import torch from bigdl.llm.transformers import AutoModelForCausalLM from transformers import AutoTokenizer, GenerationConfig generation_config = GenerationConfig(use_cache = True) tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1_5", trust_remote_code=True) # load Model using bigdl-llm and load it to GPU model = AutoModelForCausalLM.from_pretrained( "microsoft/phi-1_5", load_in_4bit=True, cpu_embedding=True, trust_remote_code=True) model = model.to('xpu') # Format the prompt question = "What is AI?" prompt = " Question:{prompt}\n\n Answer:".format(prompt=question) # Generate predicted tokens with torch.inference_mode(): input_ids = tokenizer.encode(prompt, return_tensors="pt").to('xpu') output = model.generate(input_ids, do_sample=False, max_new_tokens=32, generation_config = generation_config).cpu() output_str = tokenizer.decode(output[0], skip_special_tokens=True) print(output_str)Note: when running LLMs on Intel iGPUs with limited memory size, we recommend setting
cpu_embedding=Truein the from_pretrained function. This will allow the memory-intensive embedding layer to utilize the CPU instead of GPU. -
Step 5. Run
demo.pywithin the activated Python environment using the following command:python demo.pyExample output
Example output on a system equipped with an 11th Gen Intel Core i7 CPU and Iris Xe Graphics iGPU:
Question:What is AI? Answer: AI stands for Artificial Intelligence, which is the simulation of human intelligence in machines.