* add instruction for MacOS/Linux * modify html label of gif images * organize structure of README * change title name * add inference-xpu, serving-cpu and serving-xpu parts * revise README * revise README * revise README |
||
|---|---|---|
| .. | ||
| finetune | ||
| inference | ||
| serving | ||
| README.md | ||
Getting started with BigDL-LLM in Docker
Index
- Docker installation guide for BigDL-LLM on CPU
- Docker installation guide for BigDL LLM on XPU
- Docker installation guide for BigDL LLM Serving on CPU
- Docker installation guide for BigDL LLM Serving on XPU
- Docker installation guide for BigDL LLM Fine Tuning on CPU
- Docker installation guide for BigDL LLM Fine Tuning on XPU
Docker installation guide for BigDL-LLM on CPU
BigDL-LLM on Windows
Install docker
New users can quickly get started with Docker using this official link.
For Windows users, make sure WSL2 or Hyper-V is enabled on your computer. The instructions for installing can be accessed from here.
Pull bigdl-llm-cpu image
To pull image from hub, you can execute command on console:
docker pull intelanalytics/bigdl-llm-cpu:2.4.0-SNAPSHOT
to check if the image is successfully downloaded, you can use:
docker images | sls intelanalytics/bigdl-llm-cpu:2.4.0-SNAPSHOT
Start bigdl-llm-cpu container
To run the image and do inference, you could create and run a bat script on Windows.
An example on Windows could be:
@echo off
set DOCKER_IMAGE=intelanalytics/bigdl-llm-cpu:2.4.0-SNAPSHOT
set CONTAINER_NAME=my_container
set MODEL_PATH=D:/llm/models[change to your model path]
:: Run the Docker container
docker run -itd ^
-p 12345:12345 ^
--cpuset-cpus="0-7" ^
--cpuset-mems="0" ^
--memory="8G" ^
--name=%CONTAINER_NAME% ^
-v %MODEL_PATH%:/llm/models ^
%DOCKER_IMAGE%
After the container is booted, you could get into the container through docker exec.
docker exec -it my_container bash
To run inference using BigDL-LLM using cpu, you could refer to this documentation.
Getting started with chat
chat.py can be used to initiate a conversation with a specified model. The file is under directory '/llm'.
You can download models and bind the model directory from host machine to container when start a container.
After entering the container through docker exec, you can run chat.py by:
cd /llm
python chat.py --model-path YOUR_MODEL_PATH
If your model is chatglm-6b and mounted on /llm/models, you can excute:
python chat.py --model-path /llm/models/chatglm-6b
Here is a demostration:

Getting started with tutorials
You could start a jupyter-lab serving to explore bigdl-llm-tutorial which can help you build a more sophisticated Chatbo.
To start serving, run the script under '/llm':
cd /llm
./start-notebook.sh [--port EXPECTED_PORT]
You could assign a port to serving, or the default port 12345 will be assigned.
If you use host network mode when booted the container, after successfully running service, you can access http://127.0.0.1:12345/lab to get into tutorial, or you should bind the correct ports between container and host.
Here is a demostration of how to use tutorial in explorer:
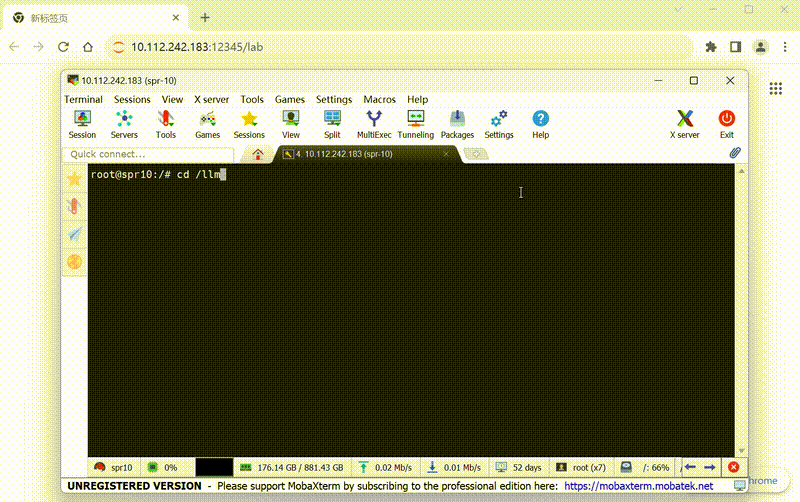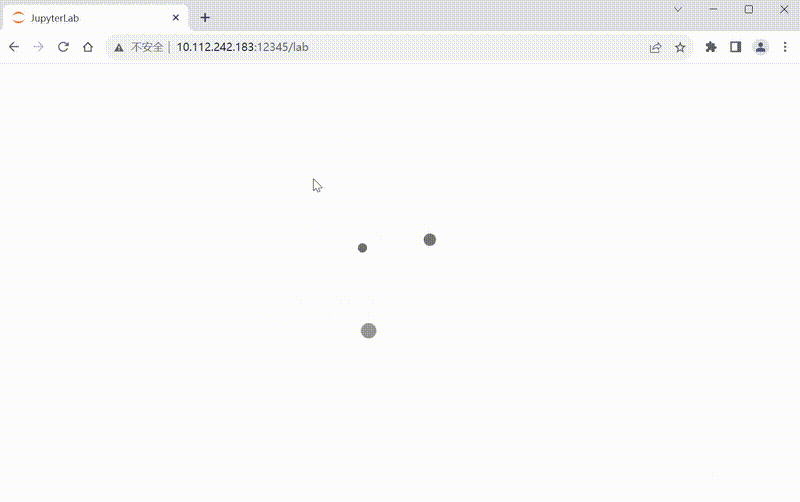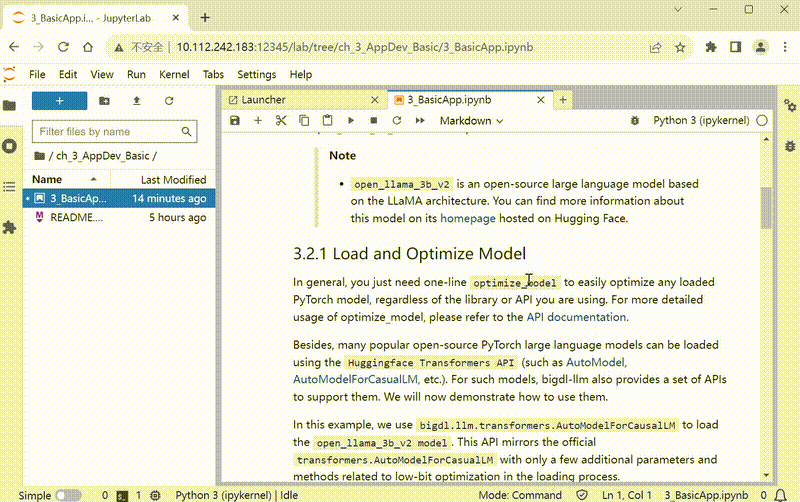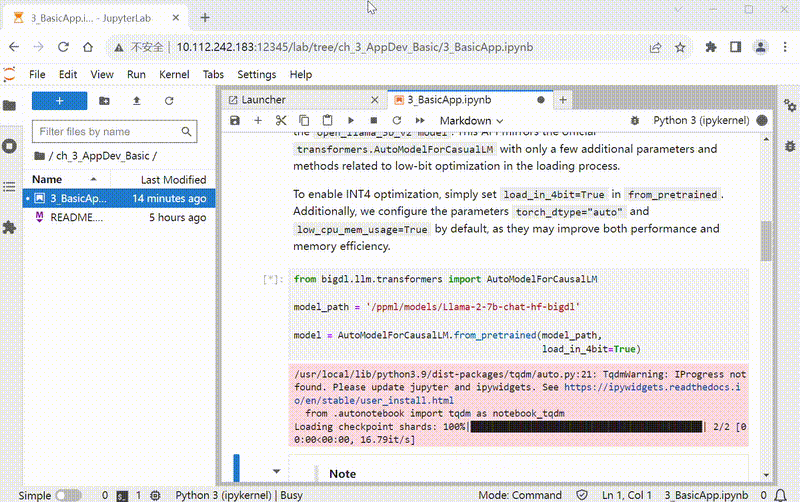
BigDL-LLM on Linux/MacOS
To run container on Linux/MacOS:
#/bin/bash
export DOCKER_IMAGE=intelanalytics/bigdl-llm-cpu:2.4.0-SNAPSHOT
export CONTAINER_NAME=my_container
export MODEL_PATH=/llm/models[change to your model path]
docker run -itd \
-p 12345:12345 \
--cpuset-cpus="0-7" \
--cpuset-mems="0" \
--memory="8G" \
--name=$CONTAINER_NAME \
-v $MODEL_PATH:/llm/models \
$DOCKER_IMAGE
Also, you could use chat.py and bigdl-llm-tutorial for development.
Getting started with tutorials
Docker installation guide for BigDL LLM on XPU
First, pull docker image from docker hub:
docker pull intelanalytics/bigdl-llm-xpu:2.4.0-SNAPSHOT
To map the xpu into the container, you need to specify --device=/dev/dri when booting the container. An example could be:
#/bin/bash
export DOCKER_IMAGE=intelanalytics/bigdl-llm-xpu:2.4.0-SNAPSHOT
export CONTAINER_NAME=my_container
export MODEL_PATH=/llm/models[change to your model path]
sudo docker run -itd \
--net=host \
--device=/dev/dri \
--memory="32G" \
--name=$CONTAINER_NAME \
--shm-size="16g" \
-v $MODEL_PATH:/llm/models \
$DOCKER_IMAGE
After the container is booted, you could get into the container through docker exec.
To verify the device is successfully mapped into the container, run sycl-ls to check the result. In a machine with Arc A770, the sampled output is:
root@arda-arc12:/# sycl-ls
[opencl:acc:0] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device 1.2 [2023.16.7.0.21_160000]
[opencl:cpu:1] Intel(R) OpenCL, 13th Gen Intel(R) Core(TM) i9-13900K 3.0 [2023.16.7.0.21_160000]
[opencl:gpu:2] Intel(R) OpenCL Graphics, Intel(R) Arc(TM) A770 Graphics 3.0 [23.17.26241.33]
[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) A770 Graphics 1.3 [1.3.26241]
To run inference using BigDL-LLM using xpu, you could refer to this documentation.
Docker installation guide for BigDL LLM Serving on CPU
Boot container
Pull image:
docker pull intelanalytics/bigdl-llm-serving-cpu:2.4.0-SNAPSHOT
You could use the following bash script to start the container. Please be noted that the CPU config is specified for Xeon CPUs, change it accordingly if you are not using a Xeon CPU.
export DOCKER_IMAGE=intelanalytics/bigdl-llm-serving-cpu:2.4.0-SNAPSHOT
export CONTAINER_NAME=my_container
export MODEL_PATH=/llm/models[change to your model path]
docker run -itd \
--net=host \
--cpuset-cpus="0-47" \
--cpuset-mems="0" \
--memory="32G" \
--name=$CONTAINER_NAME \
-v $MODEL_PATH:/llm/models \
$DOCKER_IMAGE
After the container is booted, you could get into the container through docker exec.
Models
Using BigDL-LLM in FastChat does not impose any new limitations on model usage. Therefore, all Hugging Face Transformer models can be utilized in FastChat.
FastChat determines the Model adapter to use through path matching. Therefore, in order to load models using BigDL-LLM, you need to make some modifications to the model's name.
For instance, assuming you have downloaded the llama-7b-hf from HuggingFace. Then, to use the BigDL-LLM as backend, you need to change name from llama-7b-hf to bigdl-7b.
The key point here is that the model's path should include "bigdl" and should not include paths matched by other model adapters.
A special case is ChatGLM models. For these models, you do not need to do any changes after downloading the model and the BigDL-LLM backend will be used automatically.
Start the service
Serving with Web UI
To serve using the Web UI, you need three main components: web servers that interface with users, model workers that host one or more models, and a controller to coordinate the web server and model workers.
Launch the Controller
python3 -m fastchat.serve.controller
This controller manages the distributed workers.
Launch the model worker(s)
python3 -m bigdl.llm.serving.model_worker --model-path lmsys/vicuna-7b-v1.3 --device cpu
Wait until the process finishes loading the model and you see "Uvicorn running on ...". The model worker will register itself to the controller.
To run model worker using Intel GPU, simply change the --device cpu option to --device xpu
Launch the Gradio web server
python3 -m fastchat.serve.gradio_web_server
This is the user interface that users will interact with.
By following these steps, you will be able to serve your models using the web UI with BigDL-LLM as the backend. You can open your browser and chat with a model now.
Serving with OpenAI-Compatible RESTful APIs
To start an OpenAI API server that provides compatible APIs using BigDL-LLM backend, you need three main components: an OpenAI API Server that serves the in-coming requests, model workers that host one or more models, and a controller to coordinate the web server and model workers.
First, launch the controller
python3 -m fastchat.serve.controller
Then, launch the model worker(s):
python3 -m bigdl.llm.serving.model_worker --model-path lmsys/vicuna-7b-v1.3 --device cpu
Finally, launch the RESTful API server
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
Docker installation guide for BigDL LLM Serving on XPU
Boot container
Pull image:
docker pull intelanalytics/bigdl-llm-serving-xpu:2.4.0-SNAPSHOT
To map the xpu into the container, you need to specify --device=/dev/dri when booting the container.
An example could be:
#/bin/bash
export DOCKER_IMAGE=intelanalytics/bigdl-llm-serving-cpu:2.4.0-SNAPSHOT
export CONTAINER_NAME=my_container
export MODEL_PATH=/llm/models[change to your model path]
docker run -itd \
--net=host \
--device=/dev/dri \
--memory="32G" \
--name=$CONTAINER_NAME \
--shm-size="16g" \
-v $MODEL_PATH:/llm/models \
$DOCKER_IMAGE
To verify the device is successfully mapped into the container, run sycl-ls to check the result. In a machine with Arc A770, the sampled output is:
root@arda-arc12:/# sycl-ls
[opencl:acc:0] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device 1.2 [2023.16.7.0.21_160000]
[opencl:cpu:1] Intel(R) OpenCL, 13th Gen Intel(R) Core(TM) i9-13900K 3.0 [2023.16.7.0.21_160000]
[opencl:gpu:2] Intel(R) OpenCL Graphics, Intel(R) Arc(TM) A770 Graphics 3.0 [23.17.26241.33]
[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) A770 Graphics 1.3 [1.3.26241]
After the container is booted, you could get into the container through docker exec.
Start the service
Serving with Web UI
To serve using the Web UI, you need three main components: web servers that interface with users, model workers that host one or more models, and a controller to coordinate the web server and model workers.
Launch the Controller
python3 -m fastchat.serve.controller
This controller manages the distributed workers.
Launch the model worker(s)
python3 -m bigdl.llm.serving.model_worker --model-path lmsys/vicuna-7b-v1.3 --device xpu
Wait until the process finishes loading the model and you see "Uvicorn running on ...". The model worker will register itself to the controller.
Launch the Gradio web server
python3 -m fastchat.serve.gradio_web_server
This is the user interface that users will interact with.
By following these steps, you will be able to serve your models using the web UI with BigDL-LLM as the backend. You can open your browser and chat with a model now.
Serving with OpenAI-Compatible RESTful APIs
To start an OpenAI API server that provides compatible APIs using BigDL-LLM backend, you need three main components: an OpenAI API Server that serves the in-coming requests, model workers that host one or more models, and a controller to coordinate the web server and model workers.
First, launch the controller
python3 -m fastchat.serve.controller
Then, launch the model worker(s):
python3 -m bigdl.llm.serving.model_worker --model-path lmsys/vicuna-7b-v1.3 --device xpu
Finally, launch the RESTful API server
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000