> [!IMPORTANT]
> ***`bigdl-llm` has now become `ipex-llm` (see the migration guide [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/bigdl_llm_migration.html)); you may find the original `BigDL` project [here](https://github.com/intel-analytics/BigDL-2.x).***
---
# 💫 IPEX-LLM
**`IPEX-LLM`** is a PyTorch library for running **LLM** on Intel CPU and GPU *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)* with very low latency[^1].
> [!NOTE]
> - *It is built on top of **Intel Extension for PyTorch** (**`IPEX`**), as well as the excellent work of **`llama.cpp`**, **`bitsandbytes`**, **`vLLM`**, **`qlora`**, **`AutoGPTQ`**, **`AutoAWQ`**, etc.*
> - *It provides seamless integration with [llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html), [Text-Generation-WebUI](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html), [HuggingFace tansformers](python/llm/example/GPU/HF-Transformers-AutoModels), [HuggingFace PEFT](python/llm/example/GPU/LLM-Finetuning), [LangChain](python/llm/example/GPU/LangChain), [LlamaIndex](python/llm/example/GPU/LlamaIndex), [DeepSpeed-AutoTP](python/llm/example/GPU/Deepspeed-AutoTP), [vLLM](python/llm/example/GPU/vLLM-Serving), [FastChat](python/llm/src/ipex_llm/serving/fastchat), [HuggingFace TRL](python/llm/example/GPU/LLM-Finetuning/DPO), [AutoGen](python/llm/example/CPU/Applications/autogen), [ModeScope](python/llm/example/GPU/ModelScope-Models), etc.*
> - ***50+ models** have been optimized/verified on `ipex-llm` (including LLaMA2, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM, Baichuan, Qwen, RWKV, and more); see the complete list [here](#verified-models).*
## Latest Update 🔥
- [2024/03] `bigdl-llm` has now become `ipex-llm` (see the migration guide [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/bigdl_llm_migration.html)); you may find the original `BigDL` project [here](https://github.com/intel-analytics/bigdl-2.x).
- [2024/02] `ipex-llm` now supports directly loading model from [ModelScope](python/llm/example/GPU/ModelScope-Models) ([魔搭](python/llm/example/CPU/ModelScope-Models)).
- [2024/02] `ipex-llm` added inital **INT2** support (based on llama.cpp [IQ2](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF-IQ2) mechanism), which makes it possible to run large-size LLM (e.g., Mixtral-8x7B) on Intel GPU with 16GB VRAM.
- [2024/02] Users can now use `ipex-llm` through [Text-Generation-WebUI](https://github.com/intel-analytics/text-generation-webui) GUI.
- [2024/02] `ipex-llm` now supports *[Self-Speculative Decoding](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Inference/Self_Speculative_Decoding.html)*, which in practice brings **~30% speedup** for FP16 and BF16 inference latency on Intel [GPU](python/llm/example/GPU/Speculative-Decoding) and [CPU](python/llm/example/CPU/Speculative-Decoding) respectively.
- [2024/02] `ipex-llm` now supports a comprehensive list of LLM **finetuning** on Intel GPU (including [LoRA](python/llm/example/GPU/LLM-Finetuning/LoRA), [QLoRA](python/llm/example/GPU/LLM-Finetuning/QLoRA), [DPO](python/llm/example/GPU/LLM-Finetuning/DPO), [QA-LoRA](python/llm/example/GPU/LLM-Finetuning/QA-LoRA) and [ReLoRA](python/llm/example/GPU/LLM-Finetuning/ReLora)).
- [2024/01] Using `ipex-llm` [QLoRA](python/llm/example/GPU/LLM-Finetuning/QLoRA), we managed to finetune LLaMA2-7B in **21 minutes** and LLaMA2-70B in **3.14 hours** on 8 Intel Max 1550 GPU for [Standford-Alpaca](python/llm/example/GPU/LLM-Finetuning/QLoRA/alpaca-qlora) (see the blog [here](https://www.intel.com/content/www/us/en/developer/articles/technical/finetuning-llms-on-intel-gpus-using-bigdl-llm.html)).
More updates
- [2023/12] `ipex-llm` now supports [ReLoRA](python/llm/example/GPU/LLM-Finetuning/ReLora) (see *["ReLoRA: High-Rank Training Through Low-Rank Updates"](https://arxiv.org/abs/2307.05695)*).
- [2023/12] `ipex-llm` now supports [Mixtral-8x7B](python/llm/example/GPU/HF-Transformers-AutoModels/Model/mixtral) on both Intel [GPU](python/llm/example/GPU/HF-Transformers-AutoModels/Model/mixtral) and [CPU](python/llm/example/CPU/HF-Transformers-AutoModels/Model/mixtral).
- [2023/12] `ipex-llm` now supports [QA-LoRA](python/llm/example/GPU/LLM-Finetuning/QA-LoRA) (see *["QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models"](https://arxiv.org/abs/2309.14717)*).
- [2023/12] `ipex-llm` now supports [FP8 and FP4 inference](python/llm/example/GPU/HF-Transformers-AutoModels/More-Data-Types) on Intel ***GPU***.
- [2023/11] Initial support for directly loading [GGUF](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF), [AWQ](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/AWQ) and [GPTQ](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GPTQ) models into `ipex-llm` is available.
- [2023/11] `ipex-llm` now supports [vLLM continuous batching](python/llm/example/GPU/vLLM-Serving) on both Intel [GPU](python/llm/example/GPU/vLLM-Serving) and [CPU](python/llm/example/CPU/vLLM-Serving).
- [2023/10] `ipex-llm` now supports [QLoRA finetuning](python/llm/example/GPU/LLM-Finetuning/QLoRA) on both Intel [GPU](python/llm/example/GPU/LLM-Finetuning/QLoRA) and [CPU](python/llm/example/CPU/QLoRA-FineTuning).
- [2023/10] `ipex-llm` now supports [FastChat serving](python/llm/src/ipex_llm/llm/serving) on on both Intel CPU and GPU.
- [2023/09] `ipex-llm` now supports [Intel GPU](python/llm/example/GPU) (including iGPU, Arc, Flex and MAX).
- [2023/09] `ipex-llm` [tutorial](https://github.com/intel-analytics/ipex-llm-tutorial) is released.
| 12th Gen Intel Core CPU |
Intel Arc GPU |
|
|
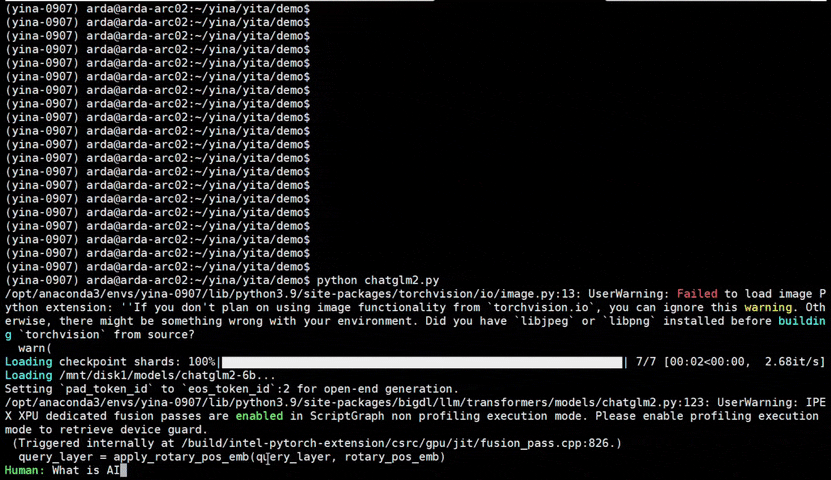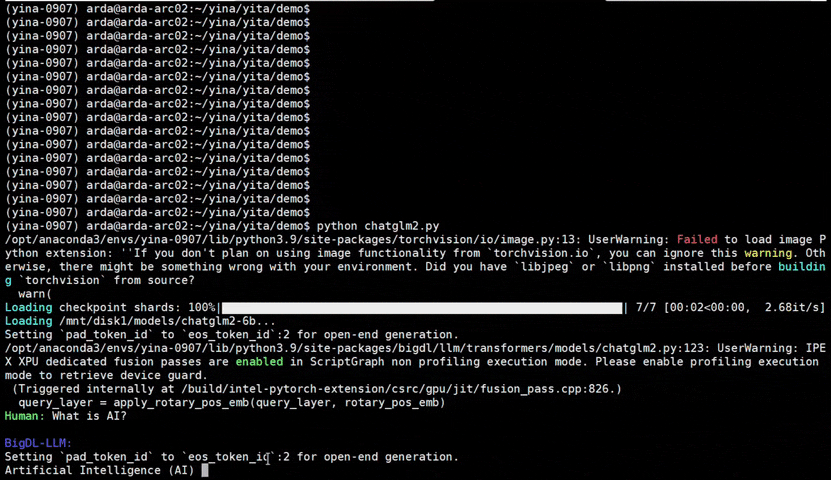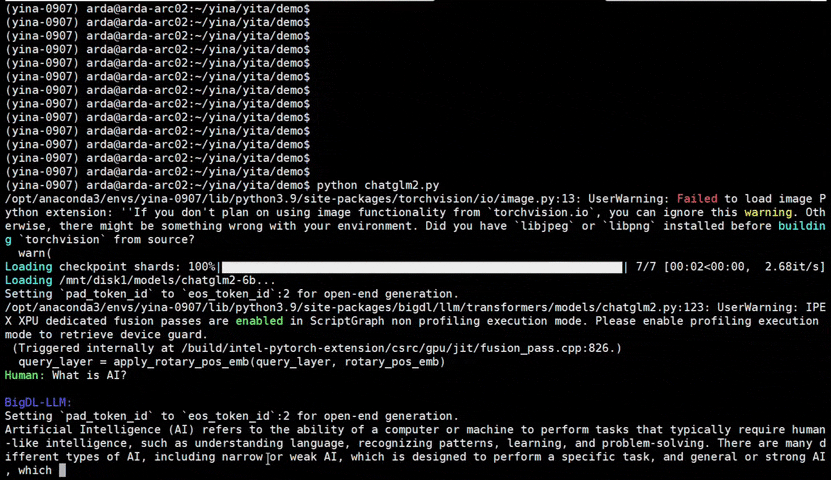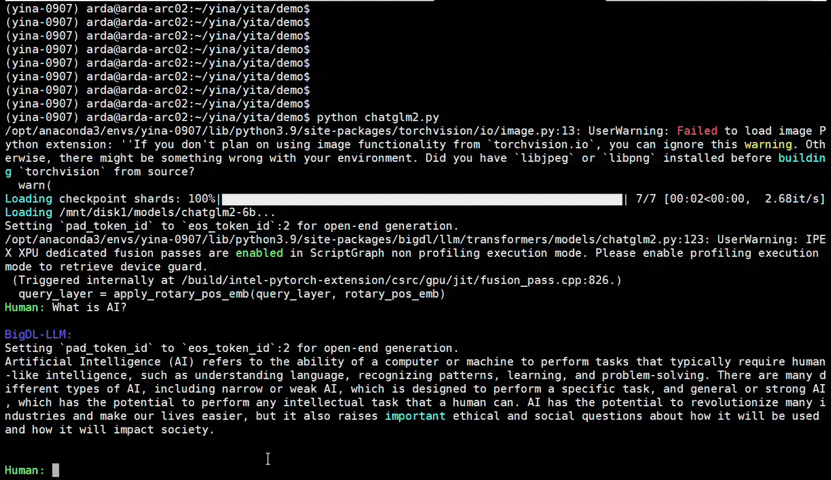
|
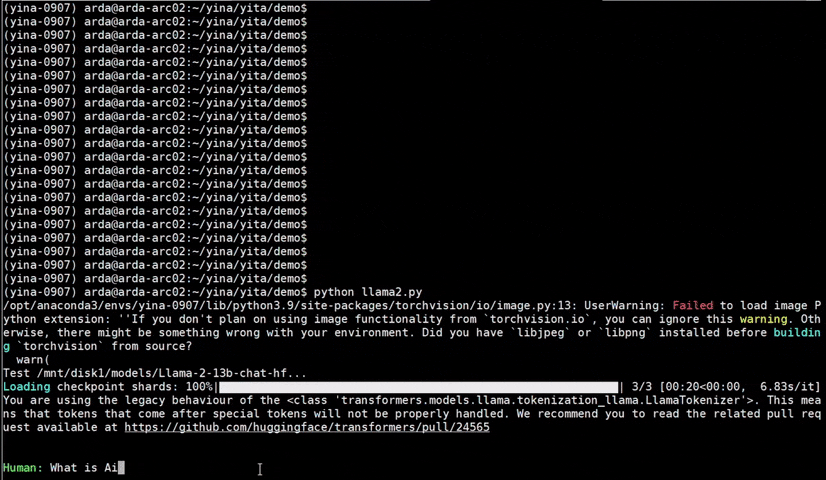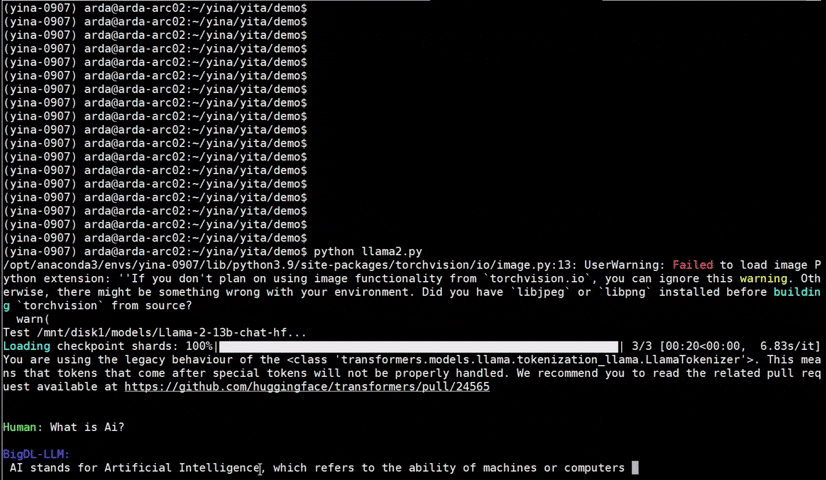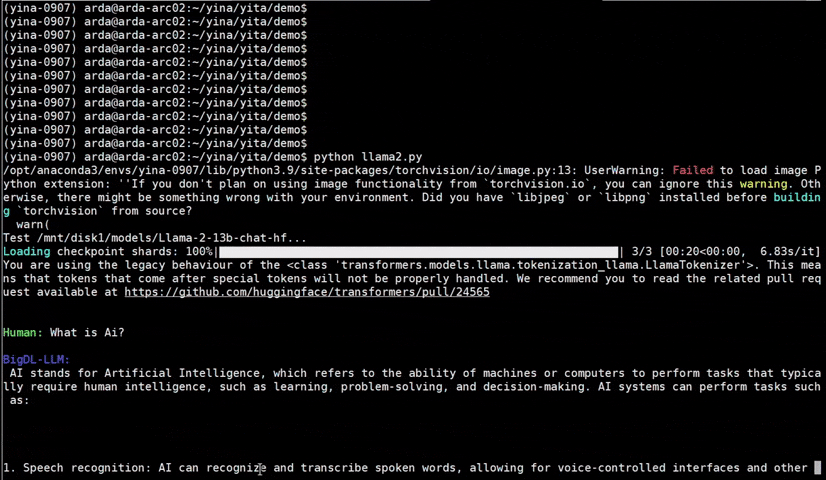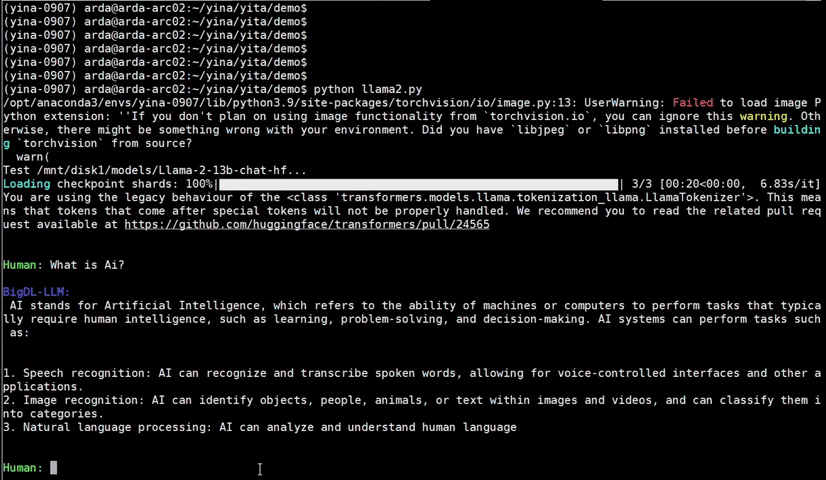
|
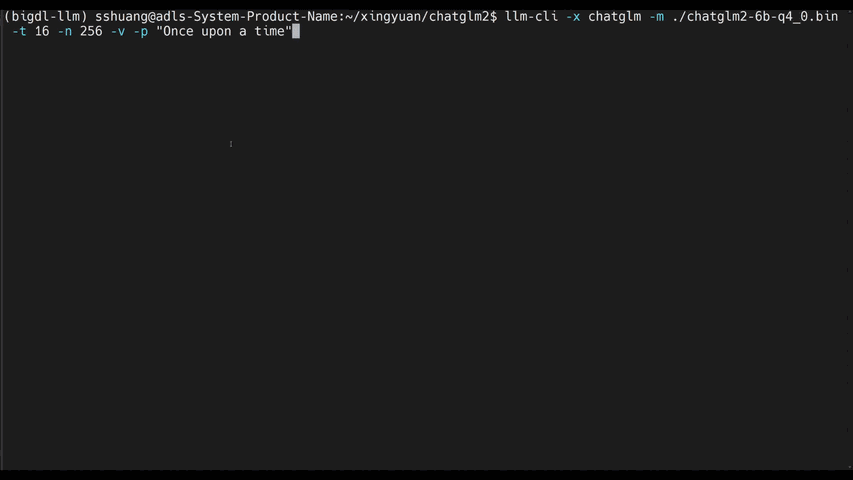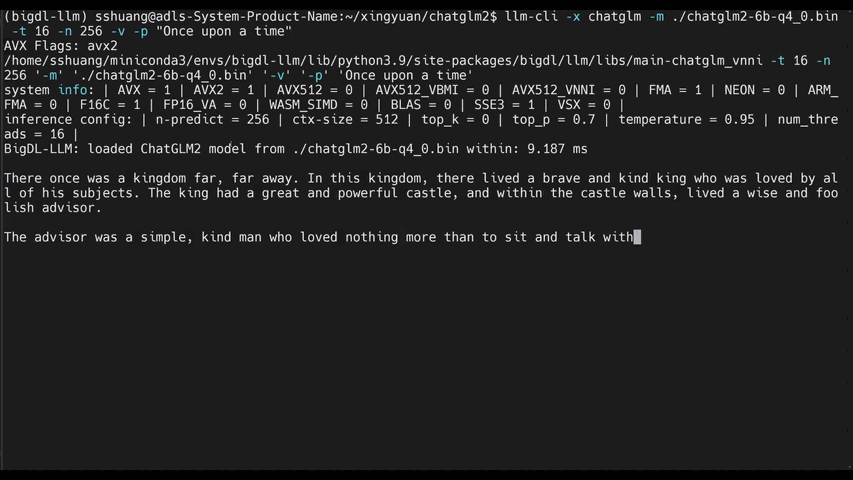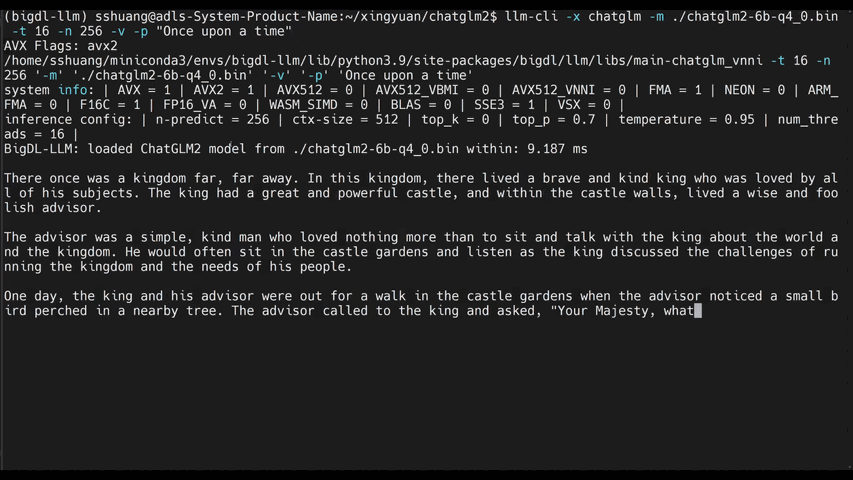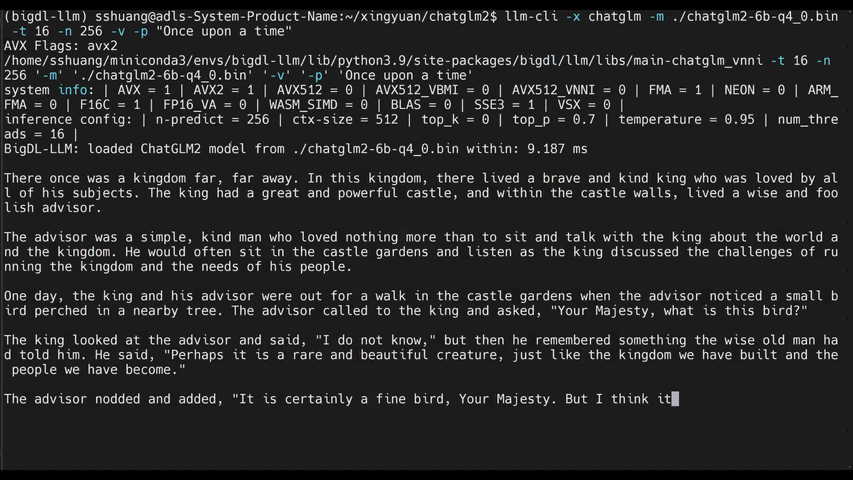
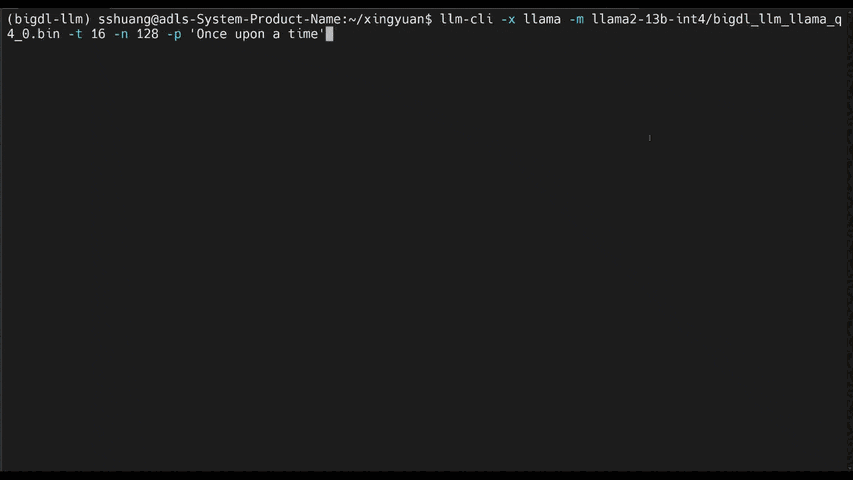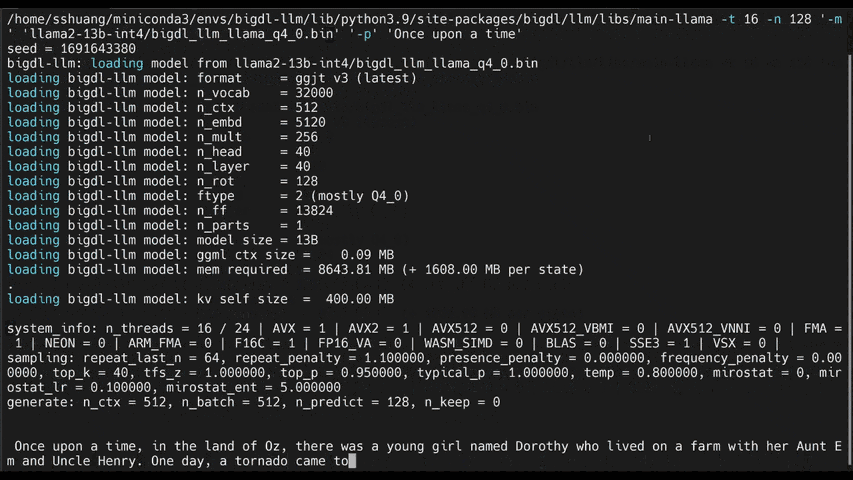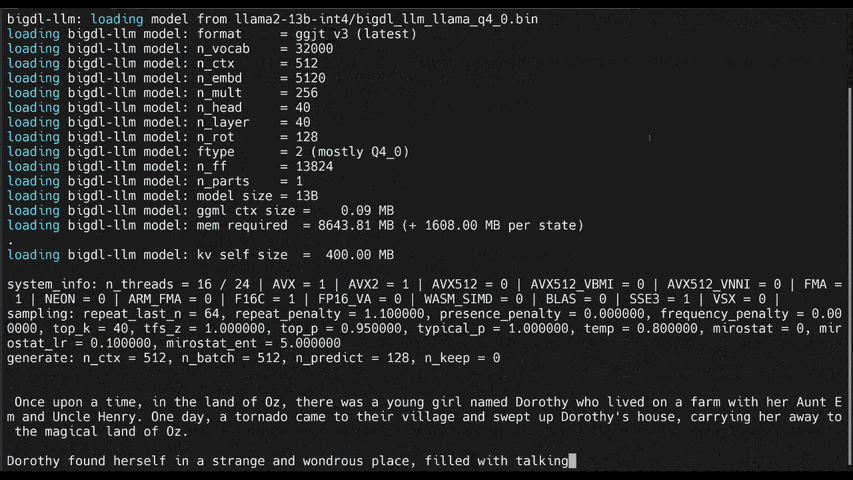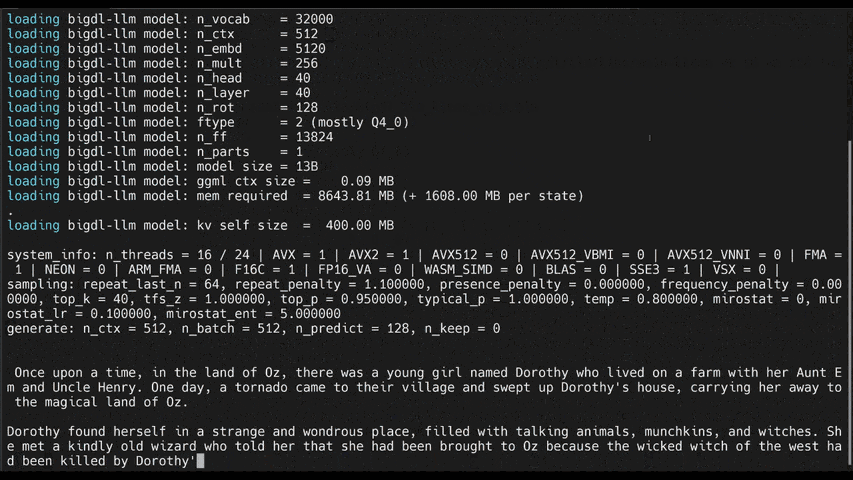
chatglm2-6b |
llama-2-13b-chat |
chatglm2-6b |
llama-2-13b-chat |
## `ipex-llm` Quickstart
### Install `ipex-llm`
- [Windows GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_windows_gpu.html): installing `ipex-llm` on Windows with Intel GPU
- [Linux GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html): installing `ipex-llm` on Linux with Intel GPU
- [Docker](docker/llm): using `ipex-llm` dockers on Intel CPU and GPU
- *For more details, please refer to the [installation guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install.html)*
### Run `ipex-llm`
- [llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html): running **ipex-llm for llama.cpp** (*using C++ interface of `ipex-llm` as an accelerated backend for `llama.cpp` on Intel GPU*)
- [vLLM](python/llm/example/GPU/vLLM-Serving): running `ipex-llm` in `vLLM` on both Intel [GPU](python/llm/example/GPU/vLLM-Serving) and [CPU](python/llm/example/CPU/vLLM-Serving)
- [FastChat](python/llm/src/ipex_llm/serving/fastchat): running `ipex-llm` in `FastChat` serving on on both Intel GPU and CPU
- [LangChain-Chatchat RAG](https://github.com/intel-analytics/Langchain-Chatchat): running `ipex-llm` in `LangChain-Chatchat` (*Knowledge Base QA using **RAG** pipeline*)
- [Text-Generation-WebUI](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html): running `ipex-llm` in `oobabooga` **WebUI**
- [Benchmarking](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/benchmark_quickstart.html): running (latency and throughput) benchmarks for `ipex-llm` on Intel CPU and GPU
### Code Examples
- Low bit inference
- [INT4 inference](python/llm/example/GPU/HF-Transformers-AutoModels/Model): **INT4** LLM inference on Intel [GPU](python/llm/example/GPU/HF-Transformers-AutoModels/Model) and [CPU](python/llm/example/CPU/HF-Transformers-AutoModels/Model)
- [FP8/FP4 inference](python/llm/example/GPU/HF-Transformers-AutoModels/More-Data-Types): **FP8** and **FP4** LLM inference on Intel [GPU](python/llm/example/GPU/HF-Transformers-AutoModels/More-Data-Types)
- [INT8 inference](python/llm/example/GPU/HF-Transformers-AutoModels/More-Data-Types): **INT8** LLM inference on Intel [GPU](python/llm/example/GPU/HF-Transformers-AutoModels/More-Data-Types) and [CPU](python/llm/example/CPU/HF-Transformers-AutoModels/More-Data-Types)
- [INT2 inference](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF-IQ2): **INT2** LLM inference (based on llama.cpp IQ2 mechanism) on Intel [GPU](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF-IQ2)
- FP16/BF16 inference
- **FP16** LLM inference on Intel [GPU](python/llm/example/GPU/Speculative-Decoding), with possible [self-speculative decoding](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Inference/Self_Speculative_Decoding.html) optimization
- **BF16** LLM inference on Intel [CPU](python/llm/example/CPU/Speculative-Decoding), with possible [self-speculative decoding](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Inference/Self_Speculative_Decoding.html) optimization
- Save and load
- [Low-bit models](python/llm/example/CPU/HF-Transformers-AutoModels/Save-Load): saving and loading `ipex-llm` low-bit models
- [GGUF](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF): directly loading GGUF models into `ipex-llm`
- [AWQ](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/AWQ): directly loading AWQ models into `ipex-llm`
- [GPTQ](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GPTQ): directly loading GPTQ models into `ipex-llm`
- Finetuning
- LLM finetuning on Intel [GPU](python/llm/example/GPU/LLM-Finetuning), including [LoRA](python/llm/example/GPU/LLM-Finetuning/LoRA), [QLoRA](python/llm/example/GPU/LLM-Finetuning/QLoRA), [DPO](python/llm/example/GPU/LLM-Finetuning/DPO), [QA-LoRA](python/llm/example/GPU/LLM-Finetuning/QA-LoRA) and [ReLoRA](python/llm/example/GPU/LLM-Finetuning/ReLora)
- QLoRA finetuning on Intel [CPU](python/llm/example/CPU/QLoRA-FineTuning)
- Integration with community libraries
- [HuggingFace tansformers](python/llm/example/GPU/HF-Transformers-AutoModels)
- [Standard PyTorch model](python/llm/example/GPU/PyTorch-Models)
- [DeepSpeed-AutoTP](python/llm/example/GPU/Deepspeed-AutoTP)
- [HuggingFace PEFT](python/llm/example/GPU/LLM-Finetuning/HF-PEFT)
- [HuggingFace TRL](python/llm/example/GPU/LLM-Finetuning/DPO)
- [LangChain](python/llm/example/GPU/LangChain)
- [LlamaIndex](python/llm/example/GPU/LlamaIndex)
- [AutoGen](python/llm/example/CPU/Applications/autogen)
- [ModeScope](python/llm/example/GPU/ModelScope-Models)
- [Tutorials](https://github.com/intel-analytics/ipex-llm-tutorial)
*For more details, please refer to the `ipex-llm` document [website](https://ipex-llm.readthedocs.io/).*
## Verified Models
Over 50 models have been optimized/verified on `ipex-llm`, including *LLaMA/LLaMA2, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM2/ChatGLM3, Baichuan/Baichuan2, Qwen/Qwen-1.5, InternLM* and more; see the list below.
| Model | CPU Example | GPU Example |
|------------|----------------------------------------------------------------|-----------------------------------------------------------------|
| LLaMA *(such as Vicuna, Guanaco, Koala, Baize, WizardLM, etc.)* | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/vicuna) |[link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/vicuna)|
| LLaMA 2 | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama2) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/llama2) |
| ChatGLM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm) | |
| ChatGLM2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm2) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm2) |
| ChatGLM3 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm3) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm3) |
| Mistral | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/mistral) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/mistral) |
| Mixtral | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/mixtral) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/mixtral) |
| Falcon | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/falcon) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/falcon) |
| MPT | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/mpt) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/mpt) |
| Dolly-v1 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/dolly_v1) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/dolly-v1) |
| Dolly-v2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/dolly_v2) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/dolly-v2) |
| Replit Code| [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/replit) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/replit) |
| RedPajama | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/redpajama) | |
| Phoenix | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/phoenix) | |
| StarCoder | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/starcoder) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/starcoder) |
| Baichuan | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan) |
| Baichuan2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan2) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan2) |
| InternLM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/internlm) |
| Qwen | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen) |
| Qwen1.5 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen1.5) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen1.5) |
| Qwen-VL | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen-vl) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen-vl) |
| Aquila | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/aquila) |
| Aquila2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila2) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/aquila2) |
| MOSS | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/moss) | |
| Whisper | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/whisper) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/whisper) |
| Phi-1_5 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/phi-1_5) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/phi-1_5) |
| Flan-t5 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/flan-t5) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/flan-t5) |
| LLaVA | [link](python/llm/example/CPU/PyTorch-Models/Model/llava) | [link](python/llm/example/GPU/PyTorch-Models/Model/llava) |
| CodeLlama | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/codellama) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/codellama) |
| Skywork | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/skywork) | |
| InternLM-XComposer | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm-xcomposer) | |
| WizardCoder-Python | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/wizardcoder-python) | |
| CodeShell | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/codeshell) | |
| Fuyu | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/fuyu) | |
| Distil-Whisper | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/distil-whisper) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/distil-whisper) |
| Yi | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/yi) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/yi) |
| BlueLM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/bluelm) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/bluelm) |
| Mamba | [link](python/llm/example/CPU/PyTorch-Models/Model/mamba) | [link](python/llm/example/GPU/PyTorch-Models/Model/mamba) |
| SOLAR | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/solar) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/solar) |
| Phixtral | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/phixtral) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/phixtral) |
| InternLM2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm2) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/internlm2) |
| RWKV4 | | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/rwkv4) |
| RWKV5 | | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/rwkv5) |
| Bark | [link](python/llm/example/CPU/PyTorch-Models/Model/bark) | [link](python/llm/example/GPU/PyTorch-Models/Model/bark) |
| SpeechT5 | | [link](python/llm/example/GPU/PyTorch-Models/Model/speech-t5) |
| DeepSeek-MoE | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/deepseek-moe) | |
| Ziya-Coding-34B-v1.0 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/ziya) | |
| Phi-2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/phi-2) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/phi-2) |
| Yuan2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/yuan2) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/yuan2) |
| Gemma | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/gemma) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/gemma) |
| DeciLM-7B | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/deciLM-7b) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/deciLM-7b) |
| Deepseek | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/deepseek) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/deepseek) |