|
| You could also click here to watch the demo video. |
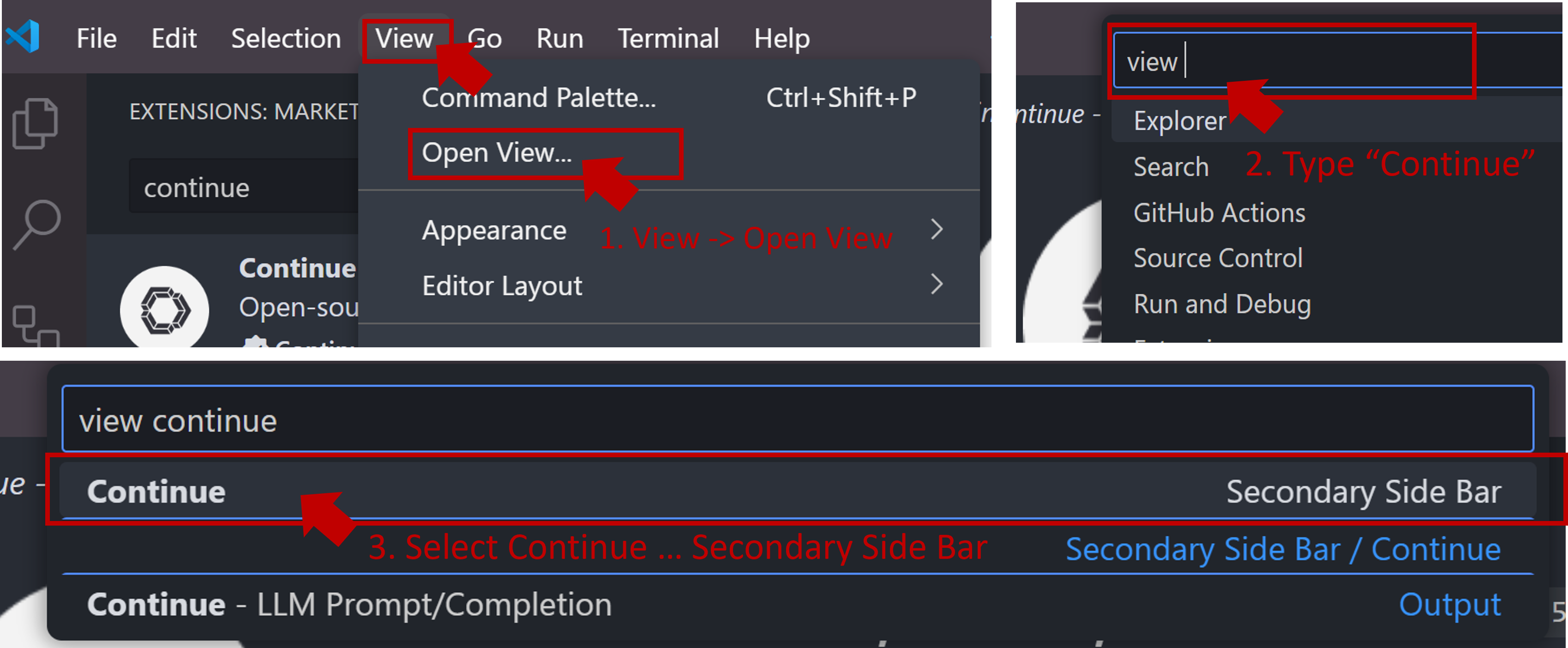
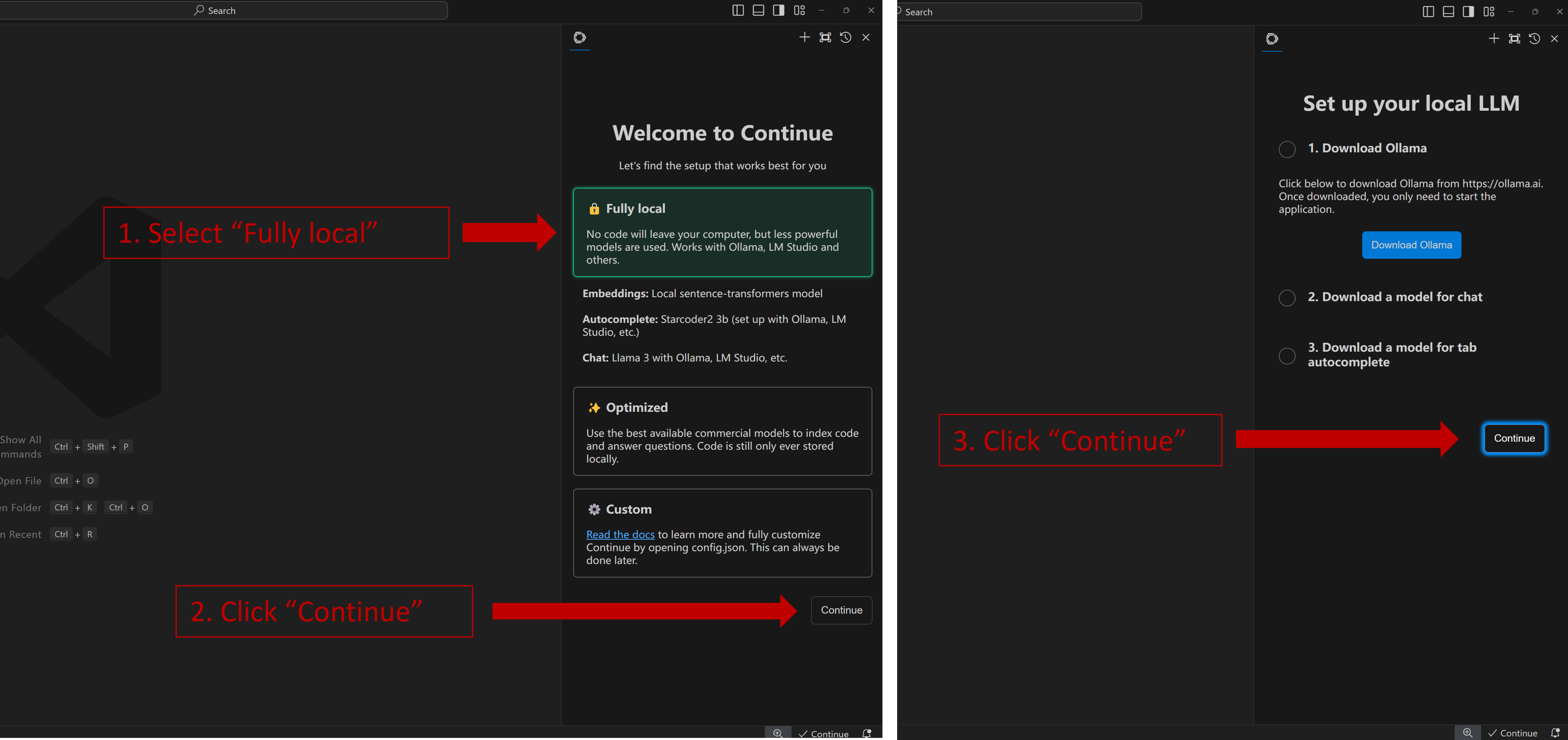 When you see the screen below, your plug-in is ready to use.
When you see the screen below, your plug-in is ready to use.
 ### 4. `Continue` Configuration
Once `Continue` is installed and ready, simply select the model "`Ollama - codeqwen:latest-continue`" from the bottom of the `Continue` view (all models in `ollama list` will appear in the format `Ollama-xxx`).
Now you can start using `Continue`.
#### Connecting to Remote Ollama Service
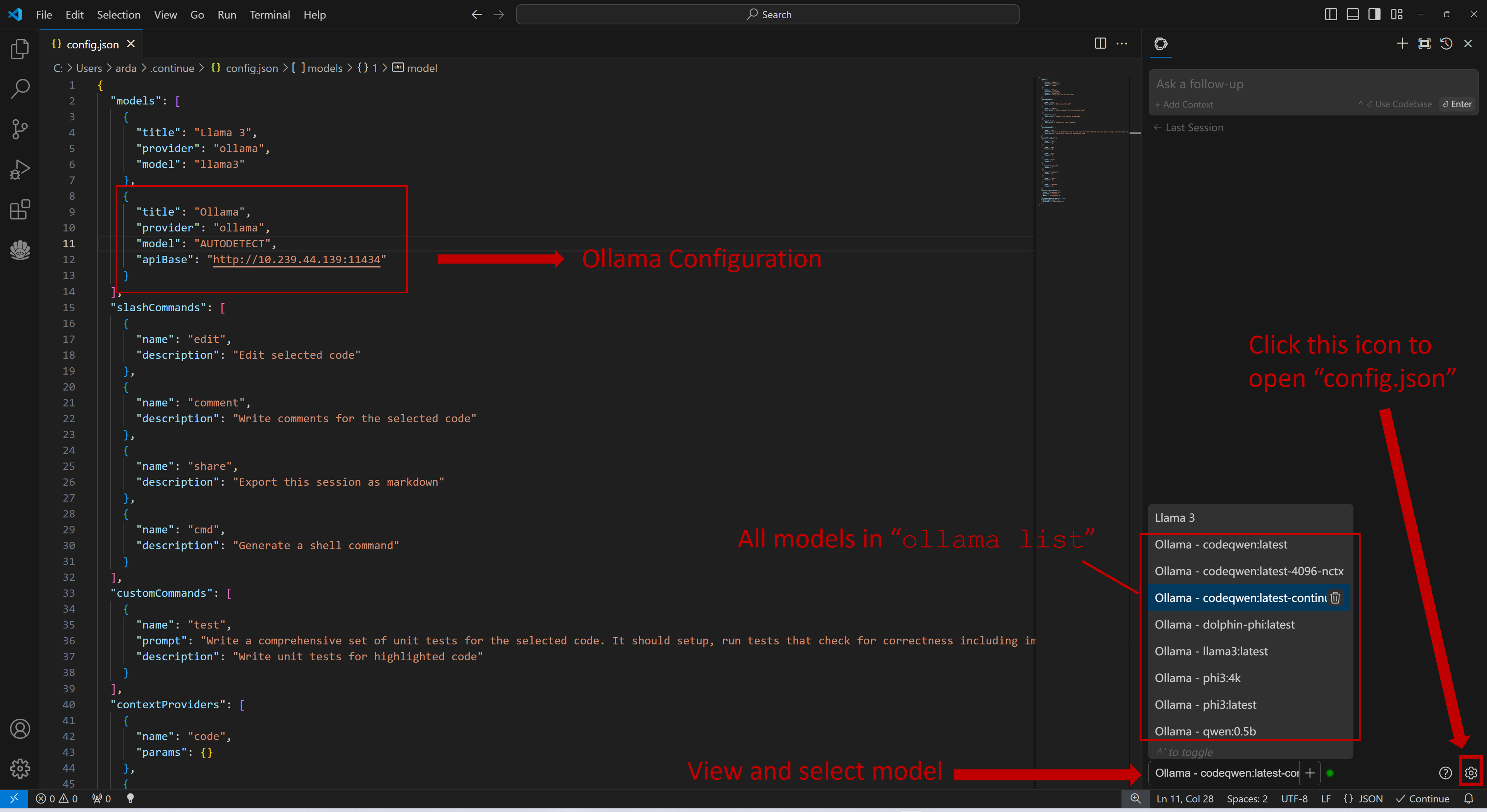
You can configure `Continue` by clicking the small gear icon located at the bottom right of the `Continue` view to open `config.json`. In `config.json`, you will find all necessary configuration settings.
If you are running Ollama on the same machine as `Continue`, no changes are necessary. If Ollama is running on a different machine, you'll need to update the `apiBase` key in `Ollama` item in `config.json` to point to the remote Ollama URL, as shown in the example below and in the figure.
```json
{
"title": "Ollama",
"provider": "ollama",
"model": "AUTODETECT",
"apiBase": "http://your-ollama-service-ip:11434"
}
```
### 4. `Continue` Configuration
Once `Continue` is installed and ready, simply select the model "`Ollama - codeqwen:latest-continue`" from the bottom of the `Continue` view (all models in `ollama list` will appear in the format `Ollama-xxx`).
Now you can start using `Continue`.
#### Connecting to Remote Ollama Service
You can configure `Continue` by clicking the small gear icon located at the bottom right of the `Continue` view to open `config.json`. In `config.json`, you will find all necessary configuration settings.
If you are running Ollama on the same machine as `Continue`, no changes are necessary. If Ollama is running on a different machine, you'll need to update the `apiBase` key in `Ollama` item in `config.json` to point to the remote Ollama URL, as shown in the example below and in the figure.
```json
{
"title": "Ollama",
"provider": "ollama",
"model": "AUTODETECT",
"apiBase": "http://your-ollama-service-ip:11434"
}
```
 ### 5. How to Use `Continue`
For detailed tutorials please refer to [this link](https://continue.dev/docs/how-to-use-continue). Here we are only showing the most common scenarios.
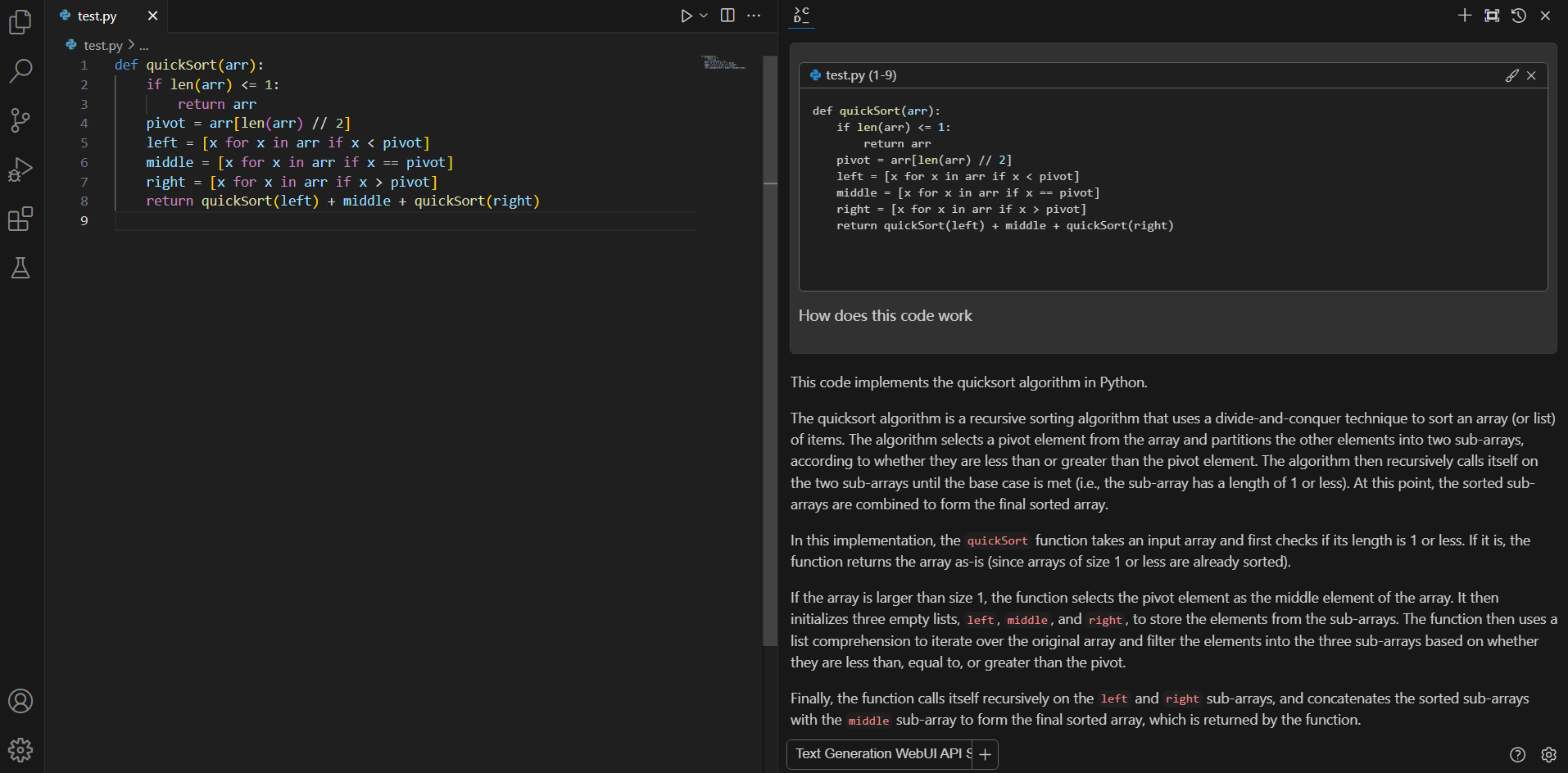
#### Q&A over specific code
If you don't understand how some code works, highlight(press `Ctrl+Shift+L`) it and ask "how does this code work?"
### 5. How to Use `Continue`
For detailed tutorials please refer to [this link](https://continue.dev/docs/how-to-use-continue). Here we are only showing the most common scenarios.
#### Q&A over specific code
If you don't understand how some code works, highlight(press `Ctrl+Shift+L`) it and ask "how does this code work?"
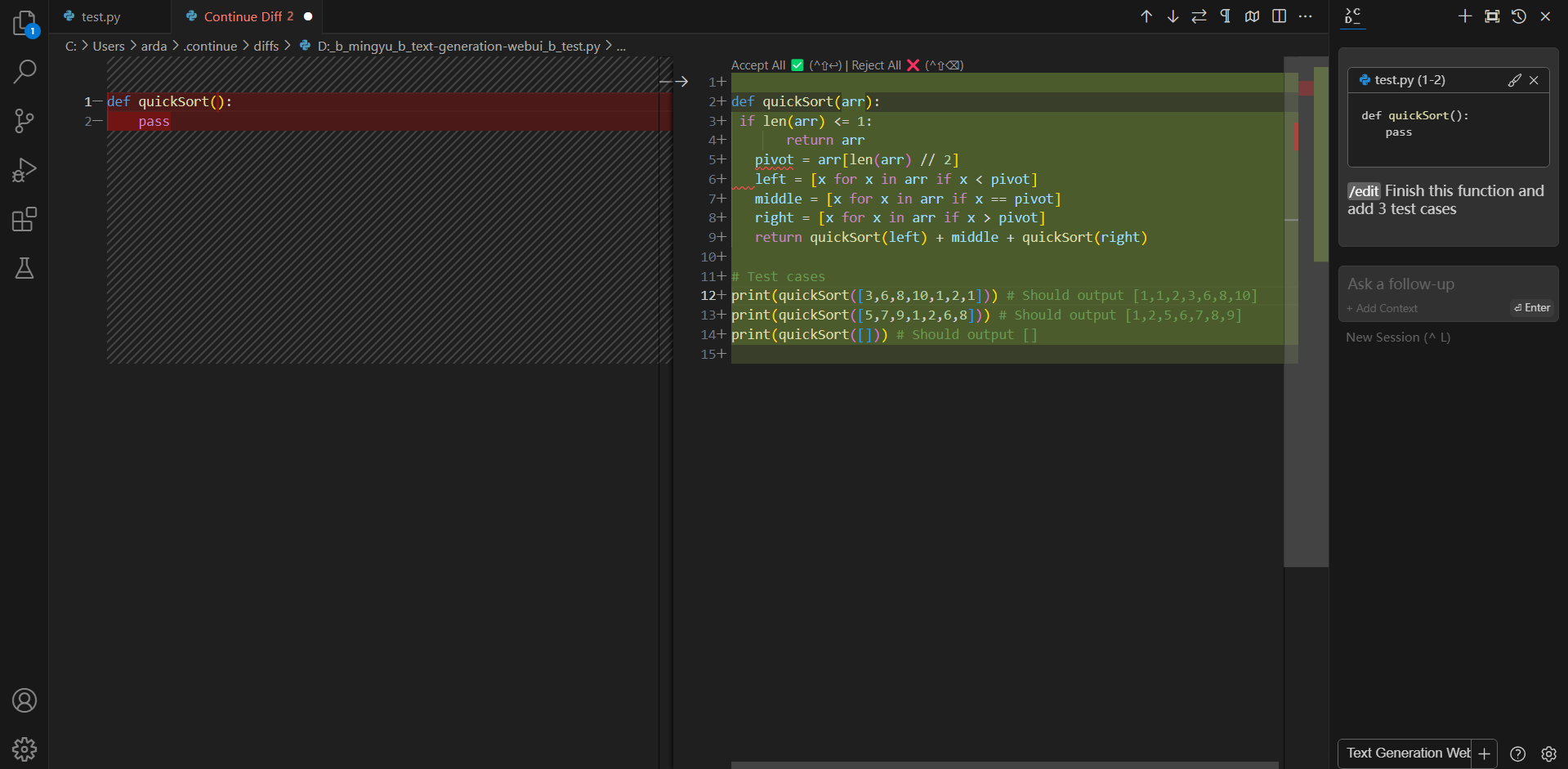
 #### Editing code
You can ask Continue to edit your highlighted code with the command `/edit`.
#### Editing code
You can ask Continue to edit your highlighted code with the command `/edit`.