## BigDL-LLM
**[`bigdl-llm`](https://bigdl.readthedocs.io/en/latest/doc/LLM/index.html)** is a library for running **LLM** (large language model) on Intel **XPU** (from *Laptop* to *GPU* to *Cloud*) using **INT4** with very low latency[^1] (for any **PyTorch** model).
> *It is built on top of the excellent work of [llama.cpp](https://github.com/ggerganov/llama.cpp), [gptq](https://github.com/IST-DASLab/gptq), [ggml](https://github.com/ggerganov/ggml), [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), [bitsandbytes](https://github.com/TimDettmers/bitsandbytes), [qlora](https://github.com/artidoro/qlora), [gptq_for_llama](https://github.com/qwopqwop200/GPTQ-for-LLaMa), [chatglm.cpp](https://github.com/li-plus/chatglm.cpp), [redpajama.cpp](https://github.com/togethercomputer/redpajama.cpp), [gptneox.cpp](https://github.com/byroneverson/gptneox.cpp), [bloomz.cpp](https://github.com/NouamaneTazi/bloomz.cpp/), etc.*
### Demos
See the ***optimized performance*** of `chatglm2-6b` and `llama-2-13b-chat` models on 12th Gen Intel Core CPU and Intel Arc GPU below.
| 12th Gen Intel Core CPU |
Intel Arc GPU |
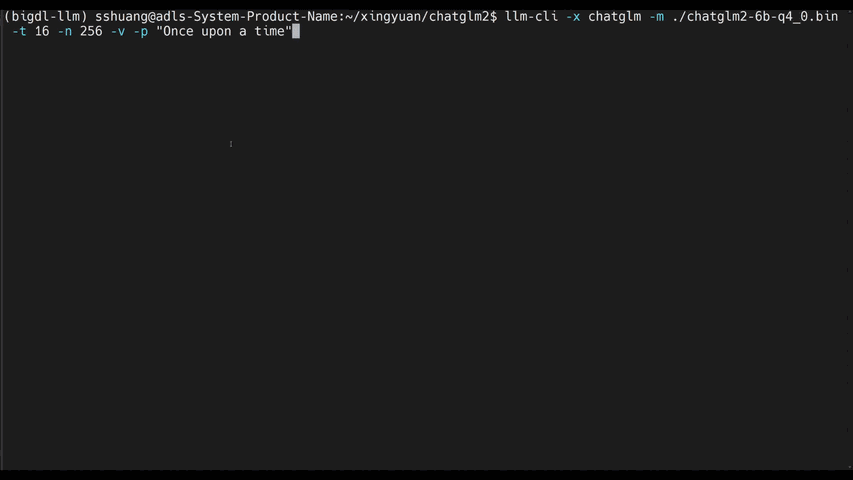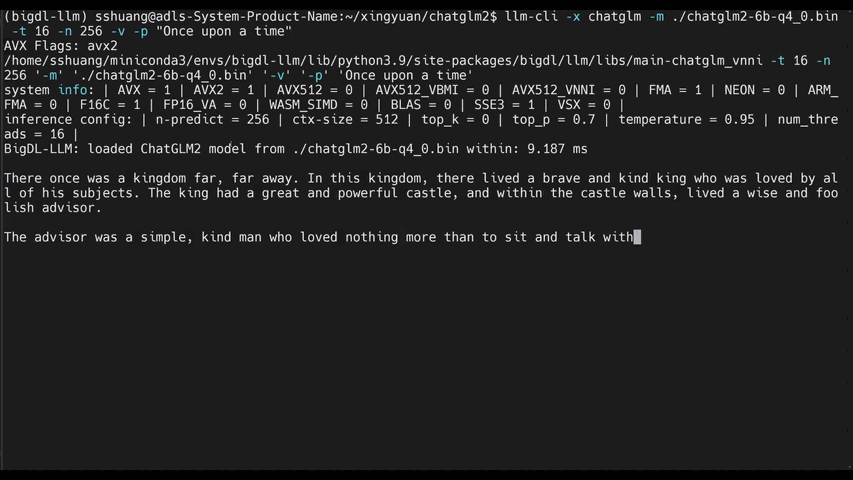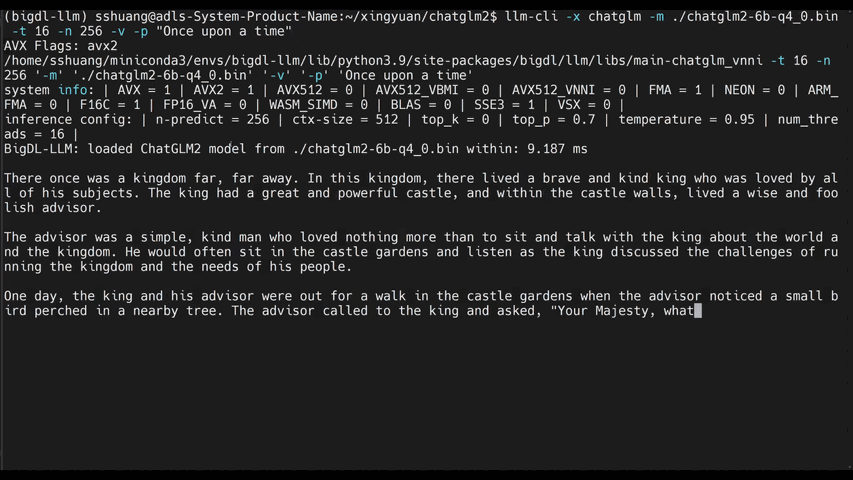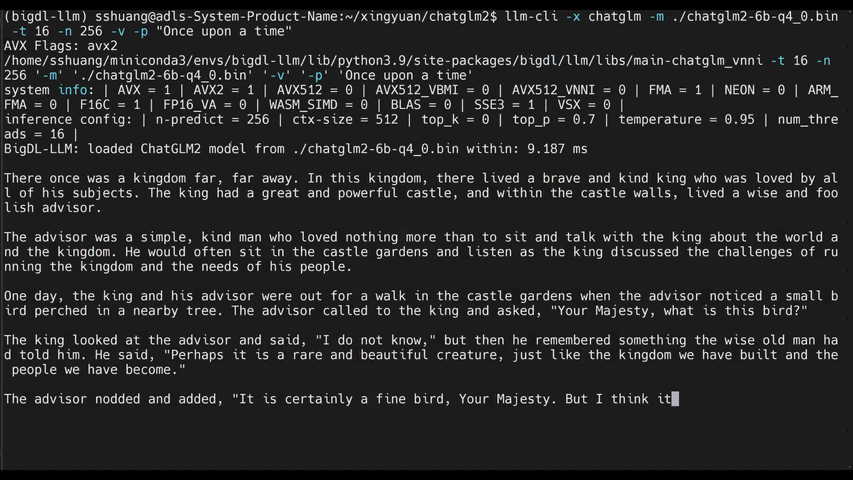
|
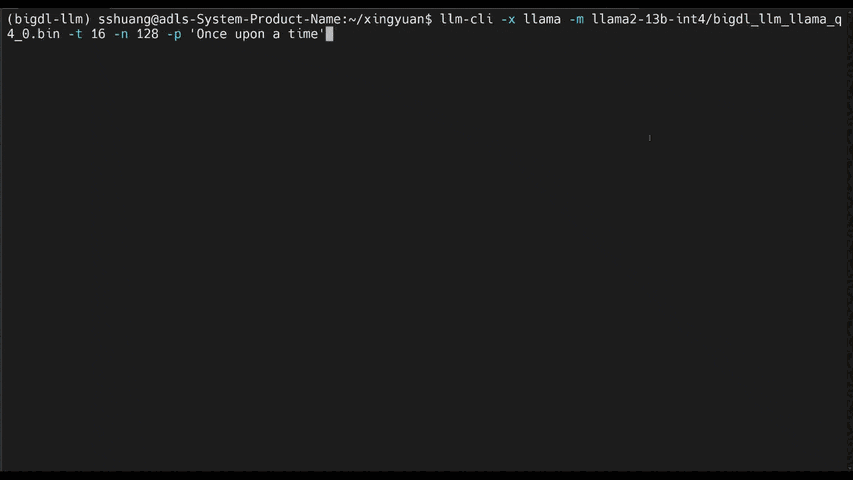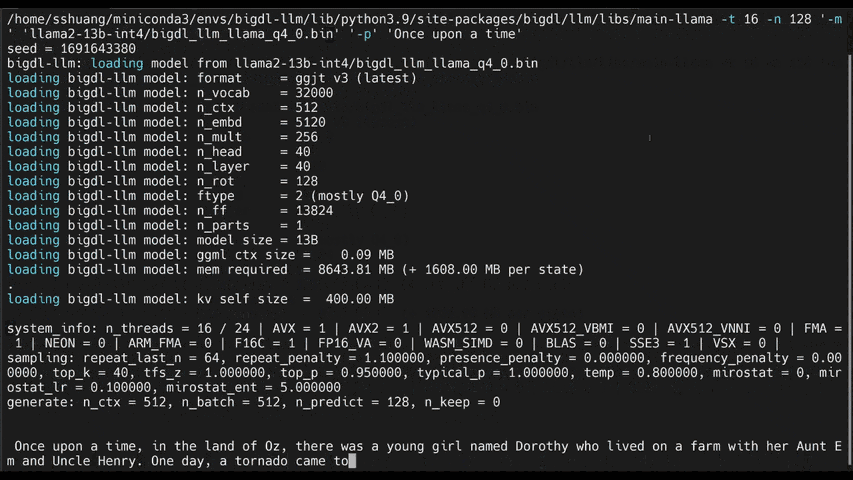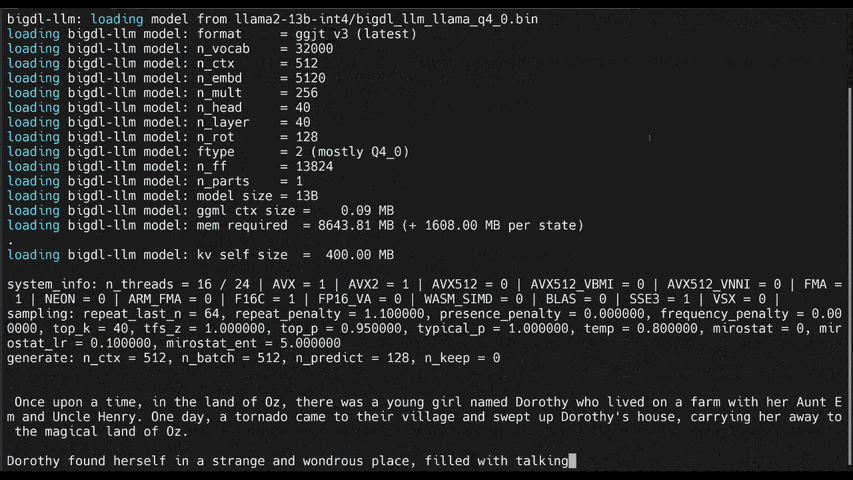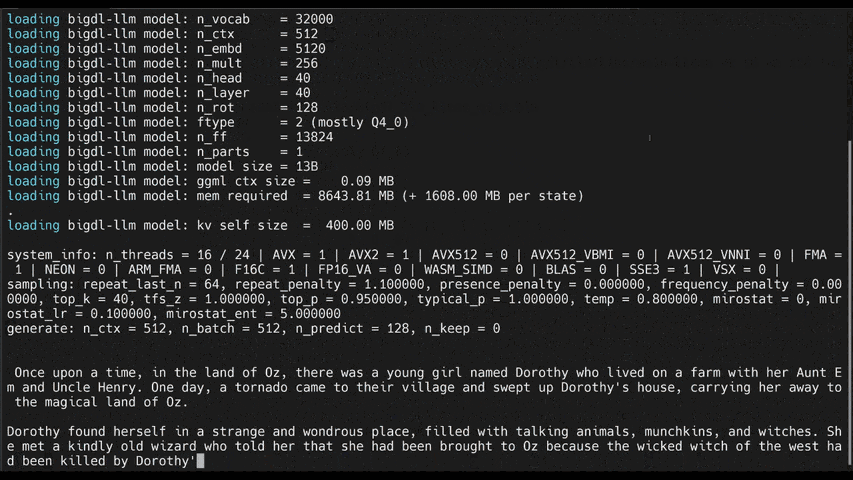
|
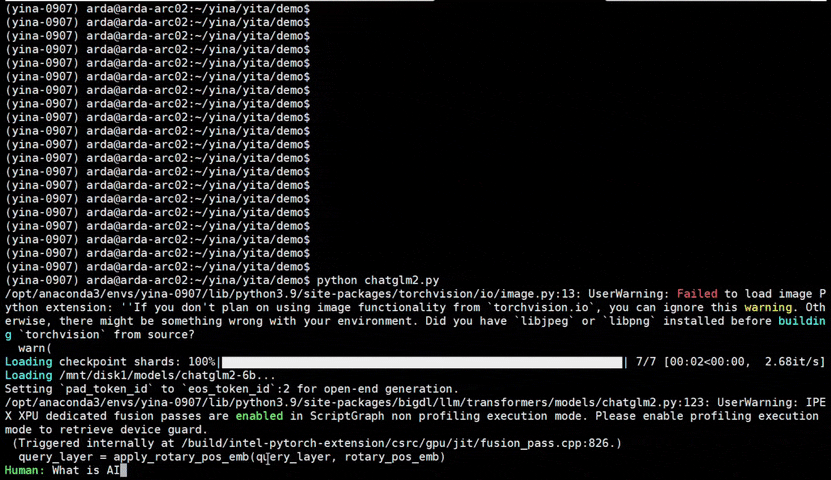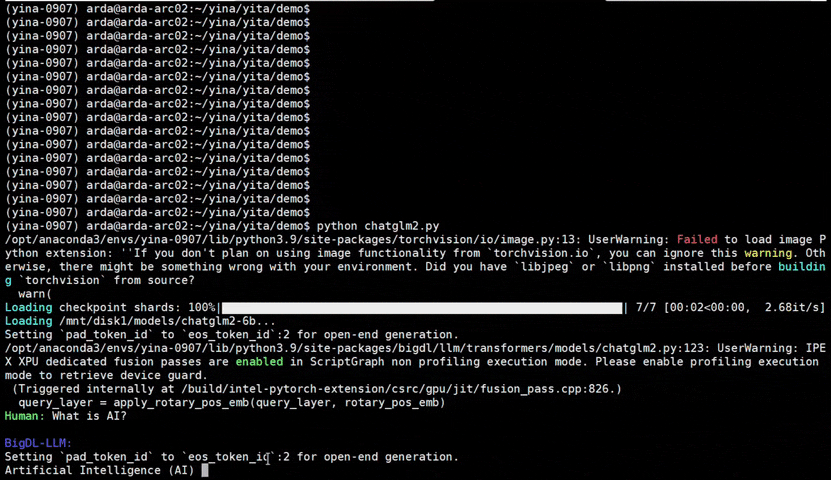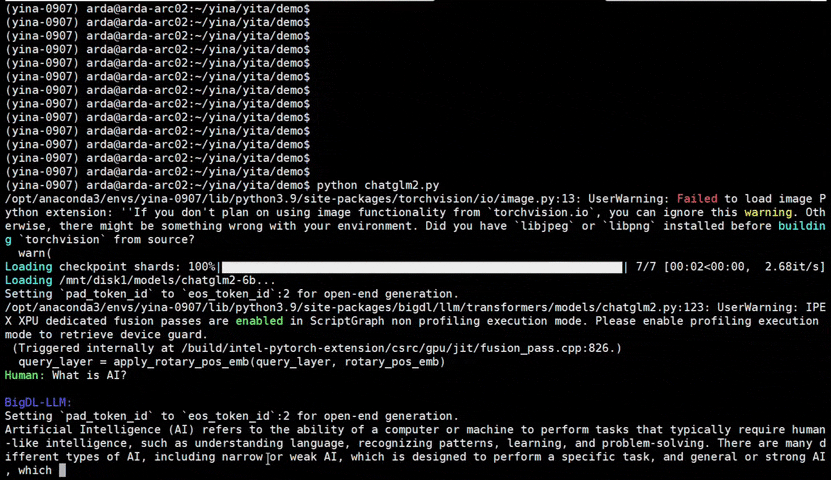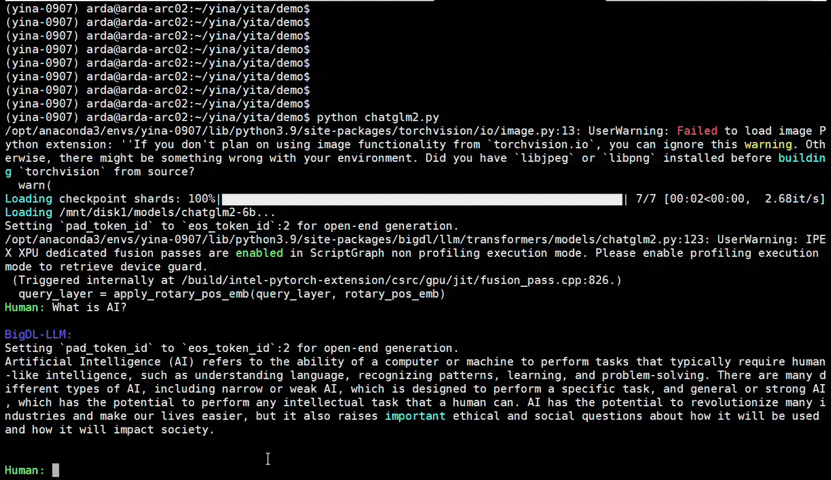
|
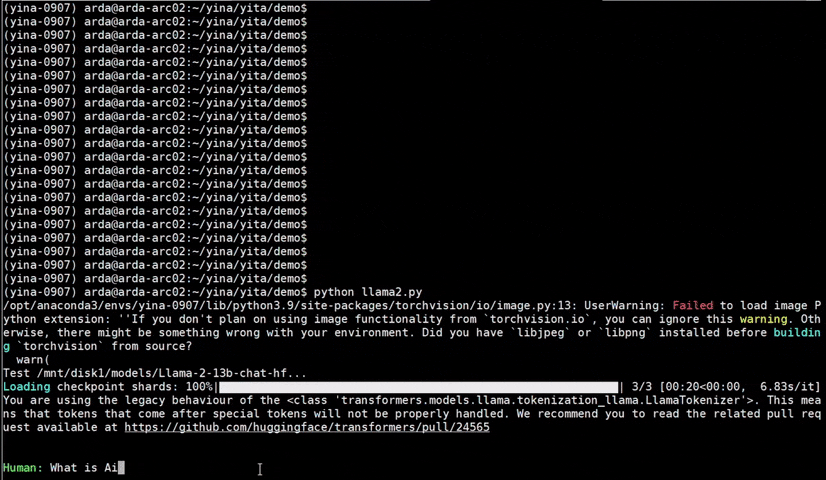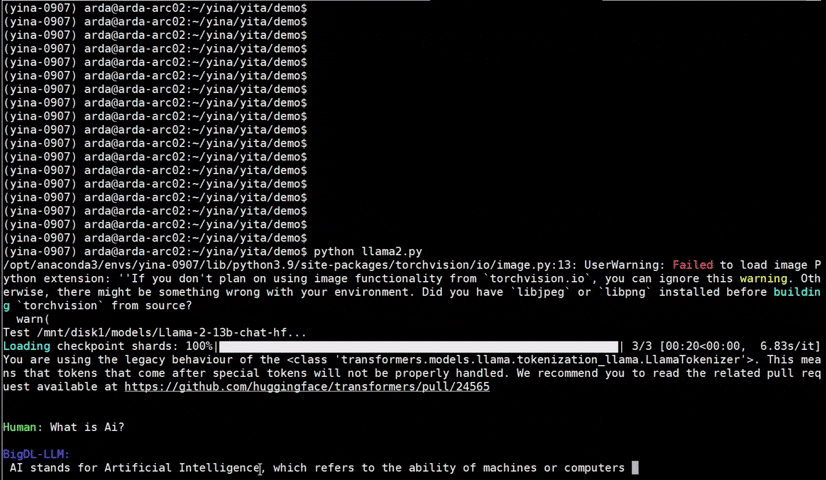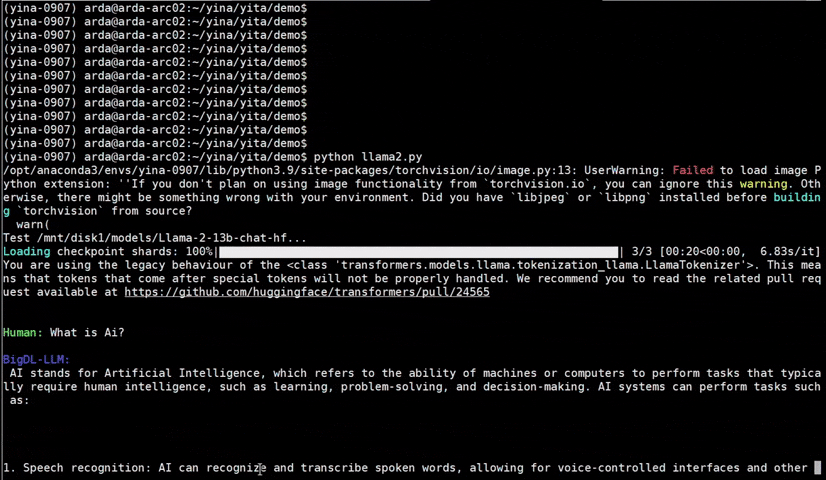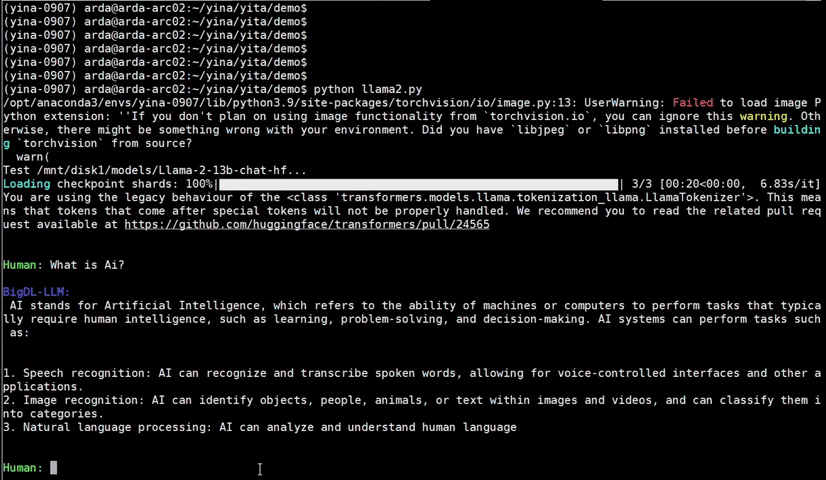
|
chatglm2-6b |
llama-2-13b-chat |
chatglm2-6b |
llama-2-13b-chat |
### Verified models
Over 20 models have been optimized/verified on `bigdl-llm`, including *LLaMA/LLaMA2, ChatGLM/ChatGLM2, Mistral, Falcon, MPT, Dolly, StarCoder, Whisper, Baichuan, InternLM, QWen, Aquila, MOSS,* and more; see the complete list below.
| Model | CPU Example | GPU Example |
|------------|----------------------------------------------------------------|-----------------------------------------------------------------|
| LLaMA *(such as Vicuna, Guanaco, Koala, Baize, WizardLM, etc.)* | [link1](example/CPU/Native-Models), [link2](example/CPU/HF-Transformers-AutoModels/Model/vicuna) |[link](example/GPU/HF-Transformers-AutoModels/Model/vicuna)|
| LLaMA 2 | [link1](example/CPU/Native-Models), [link2](example/CPU/HF-Transformers-AutoModels/Model/llama2) | [link1](example/GPU/HF-Transformers-AutoModels/Model/llama2), [link2-low GPU memory example](example/GPU/PyTorch-Models/Model/llama2#example-2---low-memory-version-predict-tokens-using-generate-api) |
| ChatGLM | [link](example/CPU/HF-Transformers-AutoModels/Model/chatglm) | |
| ChatGLM2 | [link](example/CPU/HF-Transformers-AutoModels/Model/chatglm2) | [link](example/GPU/HF-Transformers-AutoModels/Model/chatglm2) |
| ChatGLM3 | [link](example/CPU/HF-Transformers-AutoModels/Model/chatglm3) | [link](example/GPU/HF-Transformers-AutoModels/Model/chatglm3) |
| Mistral | [link](example/CPU/HF-Transformers-AutoModels/Model/mistral) | [link](example/GPU/HF-Transformers-AutoModels/Model/mistral) |
| Falcon | [link](example/CPU/HF-Transformers-AutoModels/Model/falcon) | [link](example/GPU/HF-Transformers-AutoModels/Model/falcon) |
| MPT | [link](example/CPU/HF-Transformers-AutoModels/Model/mpt) | [link](example/GPU/HF-Transformers-AutoModels/Model/mpt) |
| Dolly-v1 | [link](example/CPU/HF-Transformers-AutoModels/Model/dolly_v1) | [link](example/GPU/HF-Transformers-AutoModels/Model/dolly_v1) |
| Dolly-v2 | [link](example/CPU/HF-Transformers-AutoModels/Model/dolly_v2) | [link](example/GPU/HF-Transformers-AutoModels/Model/dolly_v2) |
| Replit Code| [link](example/CPU/HF-Transformers-AutoModels/Model/replit) | [link](example/GPU/HF-Transformers-AutoModels/Model/replit) |
| RedPajama | [link1](example/CPU/Native-Models), [link2](example/CPU/HF-Transformers-AutoModels/Model/redpajama) | |
| Phoenix | [link1](example/CPU/Native-Models), [link2](example/CPU/HF-Transformers-AutoModels/Model/phoenix) | |
| StarCoder | [link1](example/CPU/Native-Models), [link2](example/CPU/HF-Transformers-AutoModels/Model/starcoder) | [link](example/GPU/HF-Transformers-AutoModels/Model/starcoder) |
| Baichuan | [link](example/CPU/HF-Transformers-AutoModels/Model/baichuan) | [link](example/GPU/HF-Transformers-AutoModels/Model/baichuan) |
| Baichuan2 | [link](example/CPU/HF-Transformers-AutoModels/Model/baichuan2) | [link](example/GPU/HF-Transformers-AutoModels/Model/baichuan2) |
| InternLM | [link](example/CPU/HF-Transformers-AutoModels/Model/internlm) | [link](example/GPU/HF-Transformers-AutoModels/Model/internlm) |
| Qwen | [link](example/CPU/HF-Transformers-AutoModels/Model/qwen) | [link](example/GPU/HF-Transformers-AutoModels/Model/qwen) |
| Qwen1.5 | [link](example/CPU/HF-Transformers-AutoModels/Model/qwen1.5) | [link](example/GPU/HF-Transformers-AutoModels/Model/qwen1.5) |
| Qwen-VL | [link](example/CPU/HF-Transformers-AutoModels/Model/qwen-vl) | [link](example/GPU/HF-Transformers-AutoModels/Model/qwen-vl) |
| Aquila | [link](example/CPU/HF-Transformers-AutoModels/Model/aquila) | [link](example/GPU/HF-Transformers-AutoModels/Model/aquila) |
| Aquila2 | [link](example/CPU/HF-Transformers-AutoModels/Model/aquila2) | [link](example/GPU/HF-Transformers-AutoModels/Model/aquila2) |
| MOSS | [link](example/CPU/HF-Transformers-AutoModels/Model/moss) | |
| Whisper | [link](example/CPU/HF-Transformers-AutoModels/Model/whisper) | [link](example/GPU/HF-Transformers-AutoModels/Model/whisper) |
| Phi-1_5 | [link](example/CPU/HF-Transformers-AutoModels/Model/phi-1_5) | [link](example/GPU/HF-Transformers-AutoModels/Model/phi-1_5) |
| Flan-t5 | [link](example/CPU/HF-Transformers-AutoModels/Model/flan-t5) | [link](example/GPU/HF-Transformers-AutoModels/Model/flan-t5) |
| LLaVA | [link](example/CPU/PyTorch-Models/Model/llava) | [link](example/GPU/PyTorch-Models/Model/llava) |
| CodeLlama | [link](example/CPU/HF-Transformers-AutoModels/Model/codellama) | [link](example/GPU/HF-Transformers-AutoModels/Model/codellama) |
| Skywork | [link](example/CPU/HF-Transformers-AutoModels/Model/skywork) | |
| InternLM-XComposer | [link](example/CPU/HF-Transformers-AutoModels/Model/internlm-xcomposer) | |
| WizardCoder-Python | [link](example/CPU/HF-Transformers-AutoModels/Model/wizardcoder-python) | |
| CodeShell | [link](example/CPU/HF-Transformers-AutoModels/Model/codeshell) | |
| Fuyu | [link](example/CPU/HF-Transformers-AutoModels/Model/fuyu) | |
| Distil-Whisper | [link](example/CPU/HF-Transformers-AutoModels/Model/distil-whisper) | [link](example/GPU/HF-Transformers-AutoModels/Model/distil-whisper) |
| Yi | [link](example/CPU/HF-Transformers-AutoModels/Model/yi) | [link](example/GPU/HF-Transformers-AutoModels/Model/yi) |
| BlueLM | [link](example/CPU/HF-Transformers-AutoModels/Model/bluelm) | [link](example/GPU/HF-Transformers-AutoModels/Model/bluelm) |
| Mamba | [link](example/CPU/PyTorch-Models/Model/mamba) | [link](example/GPU/PyTorch-Models/Model/mamba) |
| SOLAR | [link](example/CPU/HF-Transformers-AutoModels/Model/solar) | [link](example/GPU/HF-Transformers-AutoModels/Model/solar) |
| Phixtral | [link](example/CPU/HF-Transformers-AutoModels/Model/phixtral) | [link](example/GPU/HF-Transformers-AutoModels/Model/phixtral) |
| InternLM2 | [link](example/CPU/HF-Transformers-AutoModels/Model/internlm2) | [link](example/GPU/HF-Transformers-AutoModels/Model/internlm2) |
| RWKV4 | | [link](example/GPU/HF-Transformers-AutoModels/Model/rwkv4) |
| RWKV5 | | [link](example/GPU/HF-Transformers-AutoModels/Model/rwkv5) |
| Bark | [link](example/CPU/PyTorch-Models/Model/bark) | [link](example/GPU/PyTorch-Models/Model/bark) |
| SpeechT5 | | [link](example/GPU/PyTorch-Models/Model/speech-t5) |
| DeepSeek-MoE | [link](example/CPU/HF-Transformers-AutoModels/Model/deepseek-moe) | |
| Ziya-Coding-34B-v1.0 | [link](example/CPU/HF-Transformers-AutoModels/Model/ziya) | |
| Phi-2 | [link](example/CPU/HF-Transformers-AutoModels/Model/phi-2) | [link](example/GPU/HF-Transformers-AutoModels/Model/phi-2) |
| Yuan2 | [link](example/CPU/HF-Transformers-AutoModels/Model/yuan2) | [link](example/GPU/HF-Transformers-AutoModels/Model/yuan2) |
| DeciLM-7B | [link](example/CPU/HF-Transformers-AutoModels/Model/deciLM-7b) | [link](example/GPU/HF-Transformers-AutoModels/Model/deciLM-7b) |
| Deepseek | [link](example/CPU/HF-Transformers-AutoModels/Model/deepseek) | [link](example/GPU/HF-Transformers-AutoModels/Model/deepseek) |
### Working with `bigdl-llm`
Table of Contents
- [BigDL-LLM](#bigdl-llm)
- [Demos](#demos)
- [Verified models](#verified-models)
- [Working with `bigdl-llm`](#working-with-bigdl-llm)
- [Install](#install)
- [CPU](#cpu)
- [GPU](#gpu)
- [Run Model](#run-model)
- [1. Hugging Face `transformers` API](#1-hugging-face-transformers-api)
- [CPU INT4](#cpu-int4)
- [GPU INT4](#gpu-int4)
- [More Low-Bit Support](#more-low-bit-support)
- [2. Native INT4 model](#2-native-int4-model)
- [3. LangChain API](#3-langchain-api)
- [4. CLI Tool](#4-cli-tool)
- [`bigdl-llm` API Doc](#bigdl-llm-api-doc)
- [`bigdl-llm` Dependency](#bigdl-llm-dependency)