# Run PrivateGPT with IPEX-LLM on Intel GPU
[zylon-ai/private-gpt](https://github.com/zylon-ai/private-gpt) is a production-ready AI project that allows you to ask questions about your documents using the power of Large Language Models (LLMs), even in scenarios without an Internet connection; you can easily run PrivateGPT using `Ollama` with IPEX-LLM on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
See the demo of running Mistral-7B on Intel iGPU below:
## Quickstart
### 1 Run Ollama with Intel GPU
Follow the instructions on the [Run Ollama with IPEX-LLM on Intel GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html) to install and run Ollama Serve. Please ensure that the Ollama server continues to run while you're using the PrivateGPT.
### 2. Install PrivateGPT
#### Download PrivateGPT
Use `git` to clone the [zylon-ai/private-gpt](https://github.com/zylon-ai/private-gpt).
#### Install Dependencies
You may run below commands to install PrivateGPT dependencies:
```cmd
pip install poetry
pip install ffmpy==0.3.1
poetry install --extras "ui llms-ollama embeddings-ollama vector-stores-qdrant"
```
### 3. Start PrivateGPT
#### Configure PrivateGPT
Change PrivateGPT settings by modifying `settings.yaml` and `settings-ollama.yaml`.
* `settings.yaml` is always loaded and contains the default configuration. In order to run PrivateGPT locally, you need to replace the tokenizer path under the `llm` option with your local path.
* `settings-ollama.yaml` is loaded if the ollama profile is specified in the PGPT_PROFILES environment variable. It can override configuration from the default `settings.yaml`. You can modify the settings in this file according to your preference. It is worth noting that to use the options `llm_model: ` and `embedding_model: `, you need to first use `ollama pull` to fetch the models locally.
To learn more about the configuration of PrivatePGT, please refer to [PrivateGPT Main Concepts](https://docs.privategpt.dev/installation/getting-started/main-concepts)
#### Start the service
Please ensure that the Ollama server continues to run in a terminal while you're using the PrivateGPT.
Run below commands to start the service in another terminal:
```eval_rst
.. tabs::
.. tab:: Linux
.. code-block:: bash
export no_proxy=localhost,127.0.0.1
PGPT_PROFILES=ollama make run
.. note:
Setting ``PGPT_PROFILES=ollama`` will load the configuration from ``settings.yaml`` and ``settings-ollama.yaml``.
.. tab:: Windows
.. code-block:: bash
set no_proxy=localhost,127.0.0.1
set PGPT_PROFILES=ollama
make run
.. note:
Setting ``PGPT_PROFILES=ollama`` will load the configuration from ``settings.yaml`` and ``settings-ollama.yaml``.
```
### 4. Using PrivateGPT
#### Chat with the Model
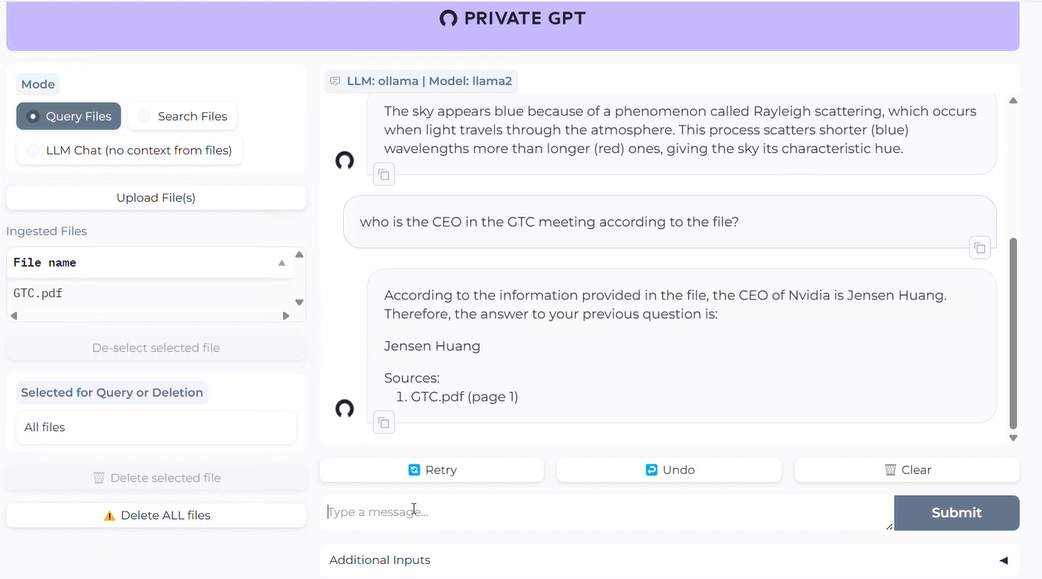
Select the "LLM Chat" option in the upper left corner of the page to chat with LLM.
 #### Using RAG
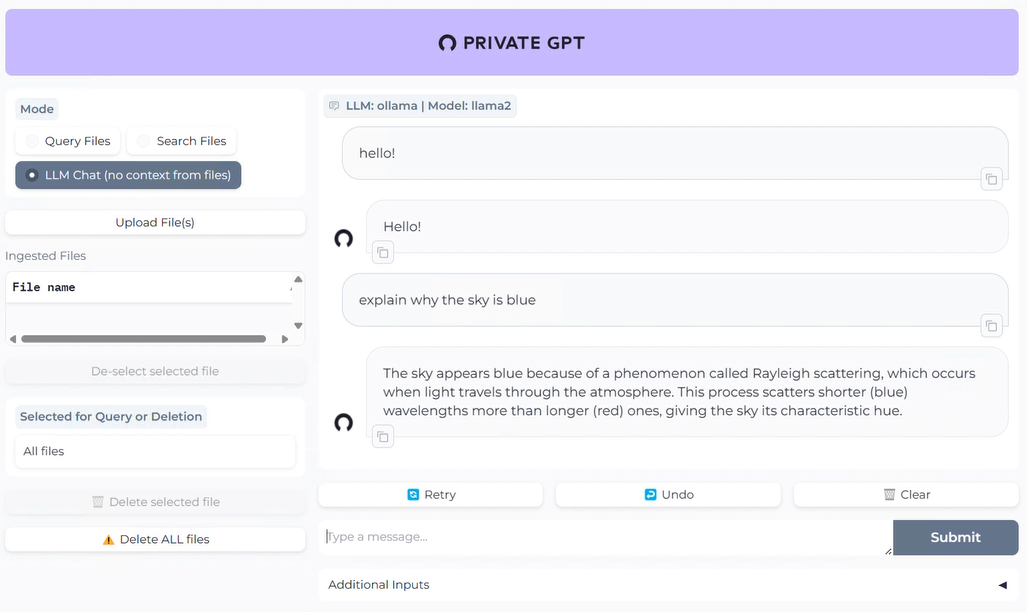
Select the "Query Files" option in the upper left corner of the page, then click the "Upload File(s)" button to upload documents. Once the document vectorization is completed, you can proceed with document-based QA.
#### Using RAG
Select the "Query Files" option in the upper left corner of the page, then click the "Upload File(s)" button to upload documents. Once the document vectorization is completed, you can proceed with document-based QA.