# Run Local RAG using Langchain-Chatchat on Intel CPU and GPU
[chatchat-space/Langchain-Chatchat](https://github.com/chatchat-space/Langchain-Chatchat) is a Knowledge Base QA application using RAG pipeline; by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily run ***local RAG pipelines*** using [Langchain-Chatchat](https://github.com/intel-analytics/Langchain-Chatchat) with LLMs and Embedding models on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max);
*See the demos of running LLaMA2-7B (English) and ChatGLM-3-6B (Chinese) on an Intel Core Ultra laptop below.*
>You can change the UI language in the left-side menu. We currently support **English** and **简体中文** (see video demos below).
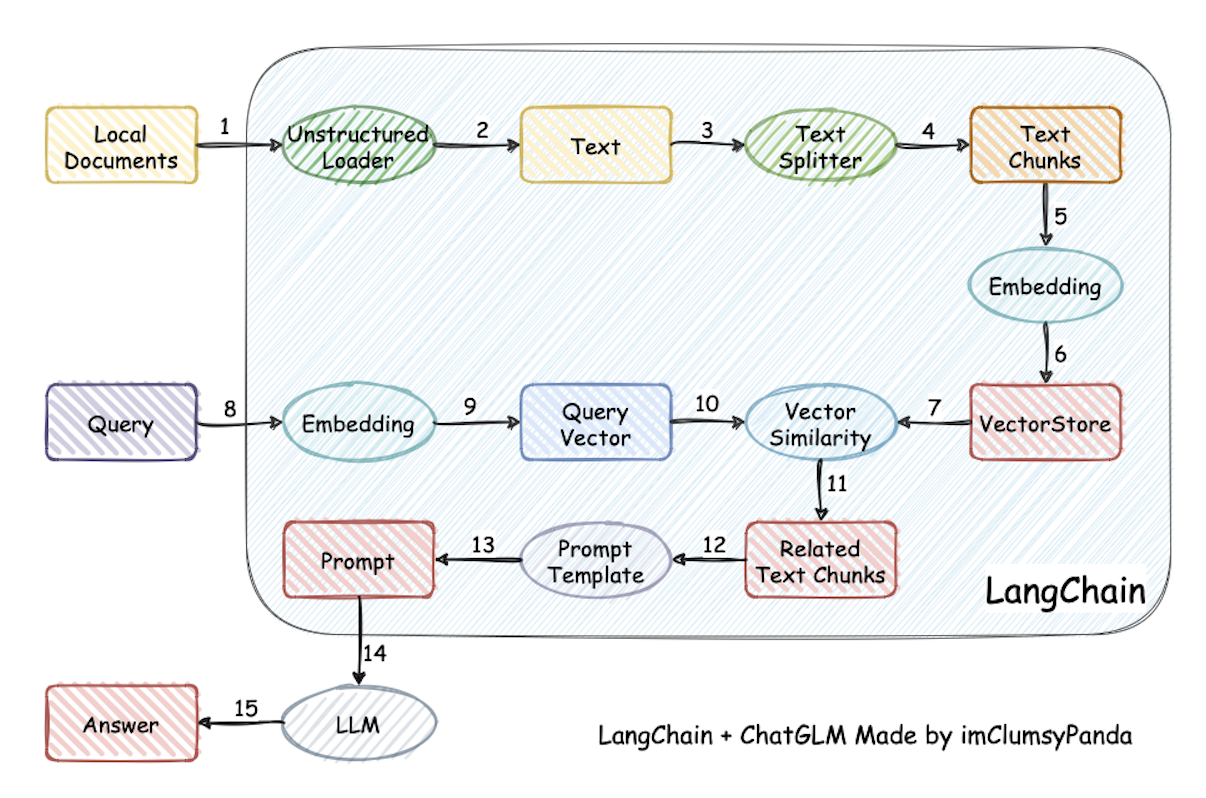
## Langchain-Chatchat Architecture
See the Langchain-Chatchat architecture below ([source](https://github.com/chatchat-space/Langchain-Chatchat/blob/master/img/langchain%2Bchatglm.png)).
 ## Quickstart
### Install and Run
Follow the guide that corresponds to your specific system and device from the links provided below:
- For systems with Intel Core Ultra integrated GPU: [Windows Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_win_mtl.md#)
- For systems with Intel Arc A-Series GPU: [Windows Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_win_arc.md#) | [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_arc.md#)
- For systems with Intel Data Center Max Series GPU: [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_max.md#)
- For systems with Xeon-Series CPU: [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_xeon.md#)
### How to use RAG
#### Step 1: Create Knowledge Base
- Select `Manage Knowledge Base` from the menu on the left, then choose `New Knowledge Base` from the dropdown menu on the right side.
## Quickstart
### Install and Run
Follow the guide that corresponds to your specific system and device from the links provided below:
- For systems with Intel Core Ultra integrated GPU: [Windows Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_win_mtl.md#)
- For systems with Intel Arc A-Series GPU: [Windows Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_win_arc.md#) | [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_arc.md#)
- For systems with Intel Data Center Max Series GPU: [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_max.md#)
- For systems with Xeon-Series CPU: [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_xeon.md#)
### How to use RAG
#### Step 1: Create Knowledge Base
- Select `Manage Knowledge Base` from the menu on the left, then choose `New Knowledge Base` from the dropdown menu on the right side.
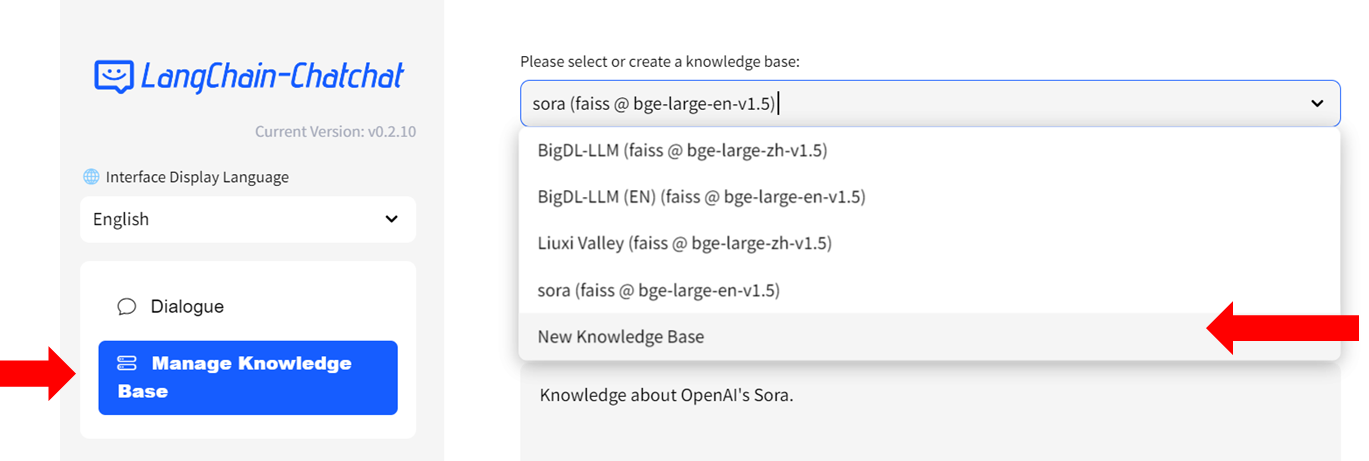
- Fill in the name of your new knowledge base (example: "test") and press the `Create` button. Adjust any other settings as needed.
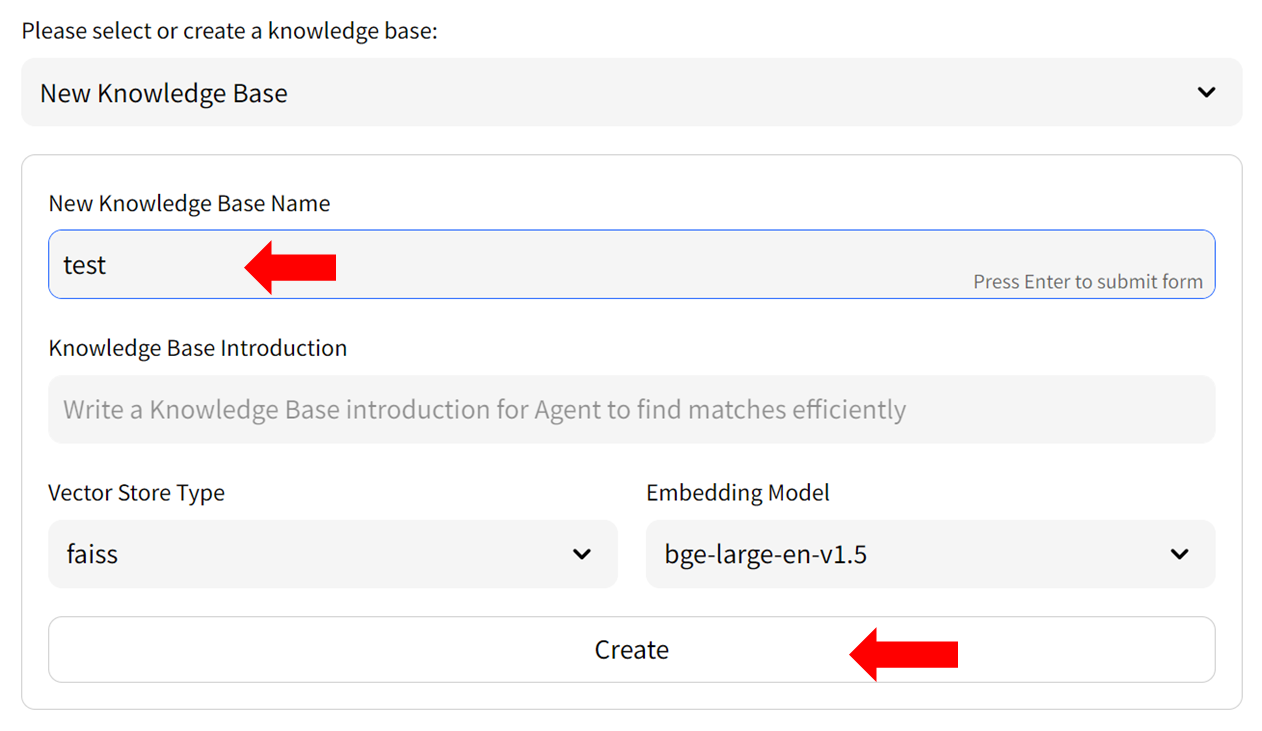
- Upload knowledge files from your computer and allow some time for the upload to complete. Once finished, click on `Add files to Knowledge Base` button to build the vector store. Note: this process may take several minutes.
#### Step 2: Chat with RAG
You can now click `Dialogue` on the left-side menu to return to the chat UI. Then in `Knowledge base settings` menu, choose the Knowledge Base you just created, e.g, "test". Now you can start chatting.
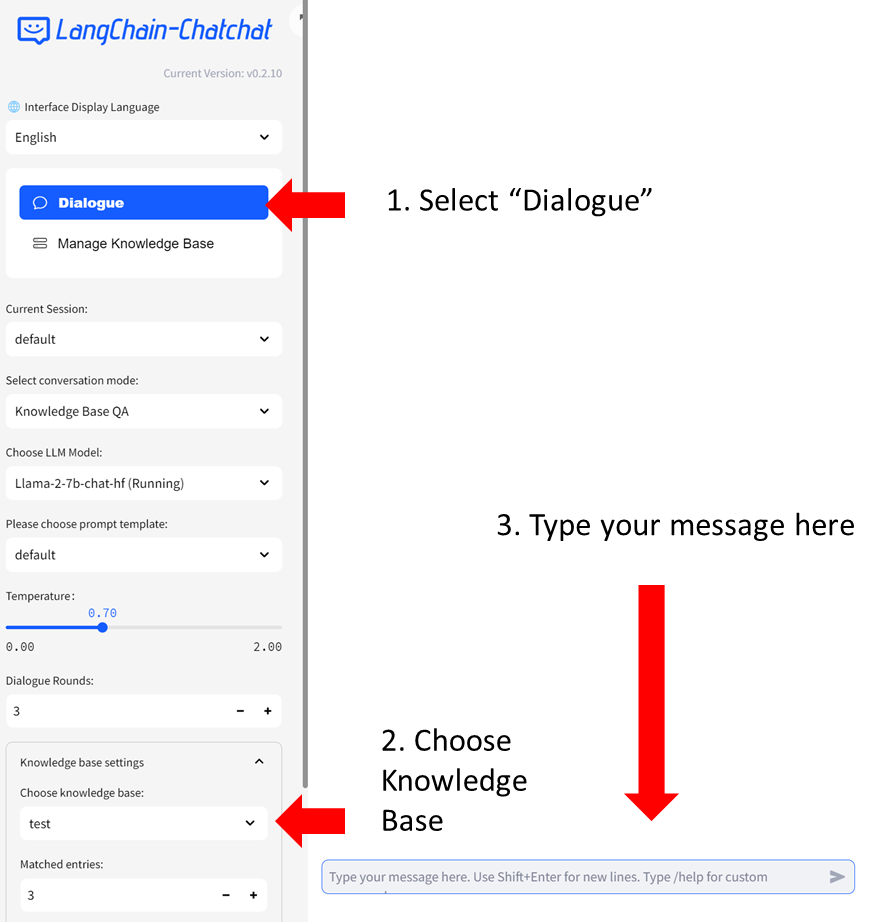
For more information about how to use Langchain-Chatchat, refer to Official Quickstart guide in [English](./README_en.md#), [Chinese](./README_chs.md#), or the [Wiki](https://github.com/chatchat-space/Langchain-Chatchat/wiki/).
### Trouble Shooting & Tips
#### 1. Version Compatibility
Ensure that you have installed `ipex-llm>=2.1.0b20240327`. To upgrade `ipex-llm`, use
```bash
pip install --pre --upgrade ipex-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpu
```
#### 2. Prompt Templates
In the left-side menu, you have the option to choose a prompt template. There're several pre-defined templates - those ending with '_cn' are Chinese templates, and those ending with '_en' are English templates. You can also define your own prompt templates in `configs/prompt_config.py`. Remember to restart the service to enable these changes.