|
| You could also click here to watch the demo video. |
 ### 2. Run Llama3 using Ollama
#### 2.1 Install IPEX-LLM for Ollama and Initialize
Visit [Run Ollama with IPEX-LLM on Intel GPU](./ollama_quickstart.md), and follow the instructions in section [Install IPEX-LLM for llama.cpp](./llama_cpp_quickstart.md#1-install-ipex-llm-for-llamacpp) to install the IPEX-LLM with Ollama binary, then follow the instructions in section [Initialize Ollama](./ollama_quickstart.md#2-initialize-ollama) to initialize.
**After above steps, you should have created a conda environment, named `llm-cpp` for instance and have ollama binary file in your current directory.**
**Now you can use this executable file by standard Ollama usage.**
#### 2.2 Run Llama3 on Intel GPU using Ollama
[ollama/ollama](https://github.com/ollama/ollama) has alreadly added [Llama3](https://ollama.com/library/llama3) into its library, so it's really easy to run Llama3 using ollama now.
##### 2.2.1 Run Ollama Serve
Launch the Ollama service:
- For **Linux users**:
```bash
export no_proxy=localhost,127.0.0.1
export ZES_ENABLE_SYSMAN=1
export OLLAMA_NUM_GPU=999
source /opt/intel/oneapi/setvars.sh
# [optional] under most circumstances, the following environment variable may improve performance, but sometimes this may also cause performance degradation
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
# [optional] if you want to run on single GPU, use below command to limit GPU may improve performance
export ONEAPI_DEVICE_SELECTOR=level_zero:0
./ollama serve
```
- For **Windows users**:
Please run the following command in Miniforge Prompt.
```cmd
set no_proxy=localhost,127.0.0.1
set ZES_ENABLE_SYSMAN=1
set OLLAMA_NUM_GPU=999
rem under most circumstances, the following environment variable may improve performance, but sometimes this may also cause performance degradation
set SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
ollama serve
```
> [!NOTE]
>
> To allow the service to accept connections from all IP addresses, use `OLLAMA_HOST=0.0.0.0 ./ollama serve` instead of just `./ollama serve`.
> [!TIP]
> When your machine has multi GPUs and you want to run on one of them, you need to set `ONEAPI_DEVICE_SELECTOR=level_zero:[gpu_id]`, here `[gpu_id]` varies based on your requirement. For more details, you can refer to [this section](../Overview/KeyFeatures/multi_gpus_selection.md#2-oneapi-device-selector).
> [!NOTE]
> The environment variable `SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS` determines the usage of immediate command lists for task submission to the GPU. While this mode typically enhances performance, exceptions may occur. Please consider experimenting with and without this environment variable for best performance. For more details, you can refer to [this article](https://www.intel.com/content/www/us/en/developer/articles/guide/level-zero-immediate-command-lists.html).
##### 2.2.2 Using Ollama Run Llama3
Keep the Ollama service on and open another terminal and run llama3 with `ollama run`:
- For **Linux users**:
```bash
export no_proxy=localhost,127.0.0.1
./ollama run llama3:8b-instruct-q4_K_M
```
- For **Windows users**:
Please run the following command in Miniforge Prompt.
```cmd
set no_proxy=localhost,127.0.0.1
ollama run llama3:8b-instruct-q4_K_M
```
> [!NOTE]
>
> Here we just take `llama3:8b-instruct-q4_K_M` for example, you can replace it with any other Llama3 model you want.
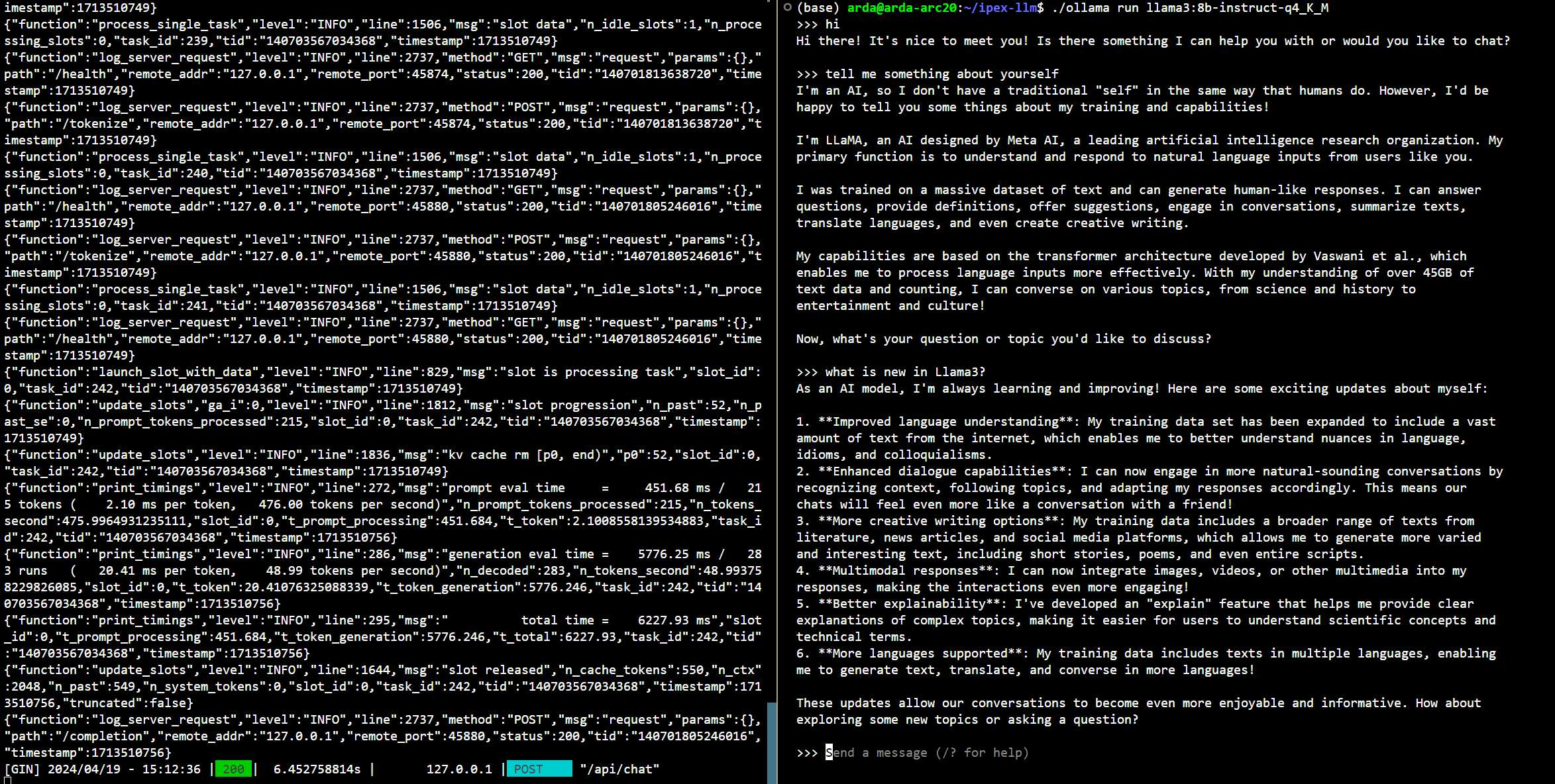
Below is a sample output on Intel Arc GPU :
### 2. Run Llama3 using Ollama
#### 2.1 Install IPEX-LLM for Ollama and Initialize
Visit [Run Ollama with IPEX-LLM on Intel GPU](./ollama_quickstart.md), and follow the instructions in section [Install IPEX-LLM for llama.cpp](./llama_cpp_quickstart.md#1-install-ipex-llm-for-llamacpp) to install the IPEX-LLM with Ollama binary, then follow the instructions in section [Initialize Ollama](./ollama_quickstart.md#2-initialize-ollama) to initialize.
**After above steps, you should have created a conda environment, named `llm-cpp` for instance and have ollama binary file in your current directory.**
**Now you can use this executable file by standard Ollama usage.**
#### 2.2 Run Llama3 on Intel GPU using Ollama
[ollama/ollama](https://github.com/ollama/ollama) has alreadly added [Llama3](https://ollama.com/library/llama3) into its library, so it's really easy to run Llama3 using ollama now.
##### 2.2.1 Run Ollama Serve
Launch the Ollama service:
- For **Linux users**:
```bash
export no_proxy=localhost,127.0.0.1
export ZES_ENABLE_SYSMAN=1
export OLLAMA_NUM_GPU=999
source /opt/intel/oneapi/setvars.sh
# [optional] under most circumstances, the following environment variable may improve performance, but sometimes this may also cause performance degradation
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
# [optional] if you want to run on single GPU, use below command to limit GPU may improve performance
export ONEAPI_DEVICE_SELECTOR=level_zero:0
./ollama serve
```
- For **Windows users**:
Please run the following command in Miniforge Prompt.
```cmd
set no_proxy=localhost,127.0.0.1
set ZES_ENABLE_SYSMAN=1
set OLLAMA_NUM_GPU=999
rem under most circumstances, the following environment variable may improve performance, but sometimes this may also cause performance degradation
set SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
ollama serve
```
> [!NOTE]
>
> To allow the service to accept connections from all IP addresses, use `OLLAMA_HOST=0.0.0.0 ./ollama serve` instead of just `./ollama serve`.
> [!TIP]
> When your machine has multi GPUs and you want to run on one of them, you need to set `ONEAPI_DEVICE_SELECTOR=level_zero:[gpu_id]`, here `[gpu_id]` varies based on your requirement. For more details, you can refer to [this section](../Overview/KeyFeatures/multi_gpus_selection.md#2-oneapi-device-selector).
> [!NOTE]
> The environment variable `SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS` determines the usage of immediate command lists for task submission to the GPU. While this mode typically enhances performance, exceptions may occur. Please consider experimenting with and without this environment variable for best performance. For more details, you can refer to [this article](https://www.intel.com/content/www/us/en/developer/articles/guide/level-zero-immediate-command-lists.html).
##### 2.2.2 Using Ollama Run Llama3
Keep the Ollama service on and open another terminal and run llama3 with `ollama run`:
- For **Linux users**:
```bash
export no_proxy=localhost,127.0.0.1
./ollama run llama3:8b-instruct-q4_K_M
```
- For **Windows users**:
Please run the following command in Miniforge Prompt.
```cmd
set no_proxy=localhost,127.0.0.1
ollama run llama3:8b-instruct-q4_K_M
```
> [!NOTE]
>
> Here we just take `llama3:8b-instruct-q4_K_M` for example, you can replace it with any other Llama3 model you want.
Below is a sample output on Intel Arc GPU :