diff --git a/docs/readthedocs/source/_templates/sidebar_quicklinks.html b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
index d1714000..3ce6d153 100644
--- a/docs/readthedocs/source/_templates/sidebar_quicklinks.html
+++ b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
@@ -43,6 +43,9 @@
Run llama.cpp with IPEX-LLM on Intel GPU
+
+ Run Ollama with IPEX-LLM on Intel GPU
+
diff --git a/docs/readthedocs/source/_toc.yml b/docs/readthedocs/source/_toc.yml
index 97f63a09..cf522a82 100644
--- a/docs/readthedocs/source/_toc.yml
+++ b/docs/readthedocs/source/_toc.yml
@@ -28,6 +28,7 @@ subtrees:
- file: doc/LLM/Quickstart/continue_quickstart
- file: doc/LLM/Quickstart/benchmark_quickstart
- file: doc/LLM/Quickstart/llama_cpp_quickstart
+ - file: doc/LLM/Quickstart/ollama_quickstart
- file: doc/LLM/Overview/KeyFeatures/index
title: "Key Features"
subtrees:
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/index.rst b/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
index ae280e3e..1ed1aa2b 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
@@ -17,6 +17,7 @@ This section includes efficient guide to show you how to:
* `Run Text Generation WebUI on Intel GPU <./webui_quickstart.html>`_
* `Run Code Copilot (Continue) in VSCode with Intel GPU <./continue_quickstart.html>`_
* `Run llama.cpp with IPEX-LLM on Intel GPU <./llama_cpp_quickstart.html>`_
+* `Run Ollama with IPEX-LLM on Intel GPU <./ollama_quickstart.html>`_
.. |bigdl_llm_migration_guide| replace:: ``bigdl-llm`` Migration Guide
.. _bigdl_llm_migration_guide: bigdl_llm_migration.html
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
index b8612cec..04a9fd9b 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
@@ -1,26 +1,70 @@
-# Run Ollama on Intel GPU
+# Run Ollama on Linux with Intel GPU
-### 1 Install Ollama integrated with IPEX-LLM
+The [ollama/ollama](https://github.com/ollama/ollama) is popular framework designed to build and run language models on a local machine. Now you can run Ollama with [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max); see the demo of running LLaMA2-7B on an Intel A770 GPU below.
-First ensure that IPEX-LLM is installed. Follow the instructions on the [IPEX-LLM Installation Quickstart for Windows with Intel GPU](install_windows_gpu.html). And activate your conda environment.
+
-Run `pip install --pre --upgrade ipex-llm[cpp]`, then execute `init-ollama`, you can see a softlink of `ollama`under your current directory.
-### 2 Verify Ollama Serve
+## Quickstart
-To avoid potential proxy issues, run `export no_proxy=localhost,127.0.0.1`. Execute `export ZES_ENABLE_SYSMAN=1` and `source /opt/intel/oneapi/setvars.sh` to enable driver initialization and dependencies for system management.
+### 1 Install IPEX-LLM with Ollama Binaries
-Start the service using `./ollama serve`. It should display something like:
+Visit [Run llama.cpp with IPEX-LLM on Intel GPU Guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html), and follow the instructions in section [Install Prerequisits on Linux](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#linux) , and section [Install IPEX-LLM cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#install-ipex-llm-for-llama-cpp) to install the IPEX-LLM with Ollama binaries.
-
+**After the installation, you should have created a conda environment, named `llm-cpp` for instance, for running `llama.cpp` commands with IPEX-LLM.**
-To expose the `ollama` service port and access it from another machine, use `OLLAMA_HOST=0.0.0.0 ./ollama serve`.
+### 2. Initialize Ollama
-Open another terminal, use `./ollama pull ` to download a model locally.
+Activate the `llm-cpp` conda environment and initialize Ollama by executing the commands below. A symbolic link to `ollama` will appear in your current directory.
-
+```bash
+conda activate llm-cpp
+init-ollama
+```
-Verify the setup with the following command:
+### 3 Run Ollama Serve
+
+
+Launch the Ollama service:
+
+```bash
+conda activate llm-cpp
+
+export no_proxy=localhost,127.0.0.1
+export ZES_ENABLE_SYSMAN=1
+source /opt/intel/oneapi/setvars.sh
+
+./ollama serve
+```
+
+```eval_rst
+.. note::
+
+ To allow the service to accept connections from all IP addresses, use `OLLAMA_HOST=0.0.0.0 ./ollama serve` instead of just `./ollama serve`.
+```
+
+The console will display messages similar to the following:
+
+
+  +
+
+
+
+### 4 Pull Model
+Keep the Ollama service on and open a new terminal and pull a model, e.g. `dolphin-phi:latest`:
+
+
+
+
+
+
+
+### 4 Pull Model
+Keep the Ollama service on and open a new terminal and pull a model, e.g. `dolphin-phi:latest`:
+
+
+  +
+
+
+
+### 5 Using Ollama
+
+#### Using Curl
+
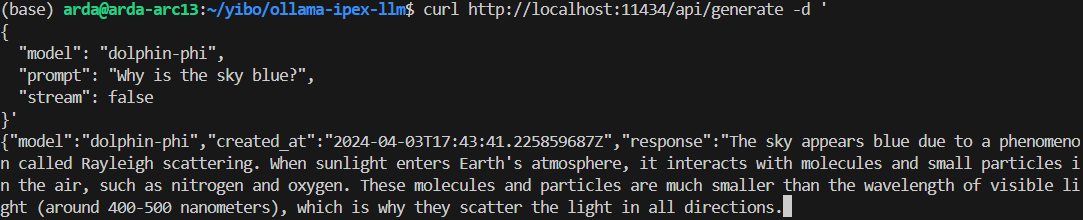
+Using `curl` is the easiest way to verify the API service and model. Execute the following commands in a terminal. **Replace the with your pulled model**, e.g. `dolphin-phi`.
```shell
curl http://localhost:11434/api/generate -d '
@@ -31,14 +75,30 @@ curl http://localhost:11434/api/generate -d '
}'
```
-Expected results:
+An example output of using model `doplphin-phi` looks like the following:
-
+
+
+
+
+
+
+### 5 Using Ollama
+
+#### Using Curl
+
+Using `curl` is the easiest way to verify the API service and model. Execute the following commands in a terminal. **Replace the with your pulled model**, e.g. `dolphin-phi`.
```shell
curl http://localhost:11434/api/generate -d '
@@ -31,14 +75,30 @@ curl http://localhost:11434/api/generate -d '
}'
```
-Expected results:
+An example output of using model `doplphin-phi` looks like the following:
-
+
+  +
-### 3 Example: Ollama Run
-You can use `./ollama run ` to automatically pull and load the model for a stream chat.
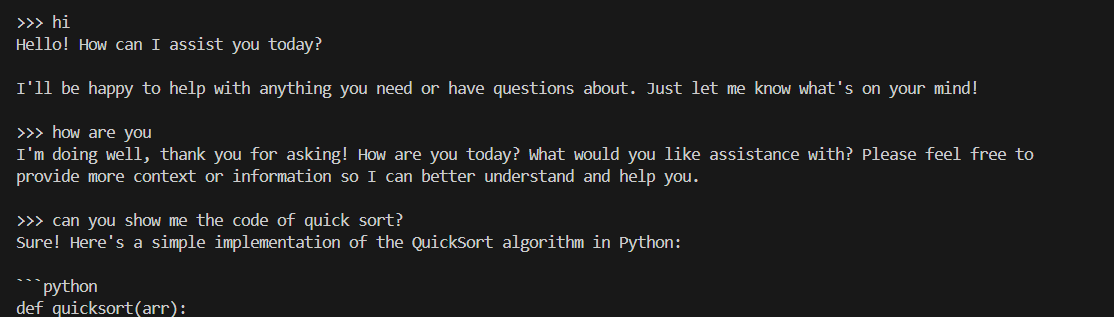
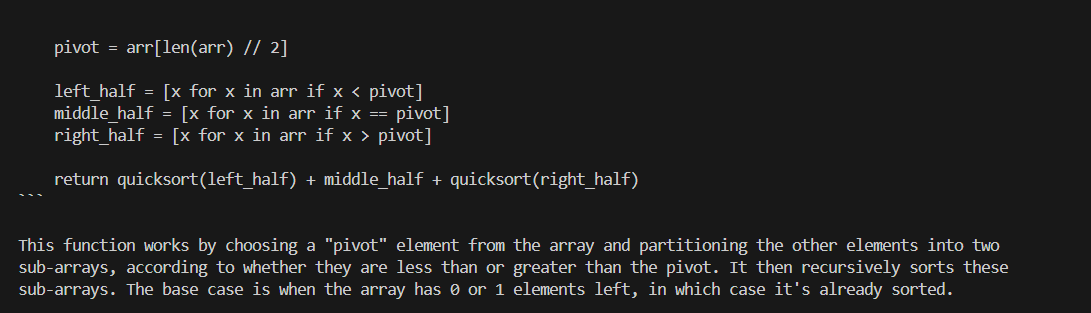
+#### Using Ollama Run
-
+You can also use `ollama run` to run the model directly on console. **Replace the with your pulled model**, e.g. `dolphin-phi`. This command will seamlessly download, load the model, and enable you to interact with it through a streaming conversation."
-
\ No newline at end of file
+
+```bash
+conda activate llm-cpp
+
+export no_proxy=localhost,127.0.0.1
+export ZES_ENABLE_SYSMAN=1
+source /opt/intel/oneapi/setvars.sh
+
+./ollama run
+```
+
+An example process of interacting with model with `ollama run` looks like the following:
+
+
+
+
-### 3 Example: Ollama Run
-You can use `./ollama run ` to automatically pull and load the model for a stream chat.
+#### Using Ollama Run
-
+You can also use `ollama run` to run the model directly on console. **Replace the with your pulled model**, e.g. `dolphin-phi`. This command will seamlessly download, load the model, and enable you to interact with it through a streaming conversation."
-
\ No newline at end of file
+
+```bash
+conda activate llm-cpp
+
+export no_proxy=localhost,127.0.0.1
+export ZES_ENABLE_SYSMAN=1
+source /opt/intel/oneapi/setvars.sh
+
+./ollama run
+```
+
+An example process of interacting with model with `ollama run` looks like the following:
+
+
+ 
 +
+
 +
+
+
+
+### 4 Pull Model
+Keep the Ollama service on and open a new terminal and pull a model, e.g. `dolphin-phi:latest`:
+
+
+
+
+
+
+
+### 4 Pull Model
+Keep the Ollama service on and open a new terminal and pull a model, e.g. `dolphin-phi:latest`:
+
+
+