Update_docker by heyang (#29)
This commit is contained in:
parent
5dc121ee5e
commit
e2d25de17d
37 changed files with 261 additions and 270 deletions
|
|
@ -1,18 +1,18 @@
|
||||||
# Getting started with BigDL-LLM in Docker
|
# Getting started with IPEX-LLM in Docker
|
||||||
|
|
||||||
### Index
|
### Index
|
||||||
- [Docker installation guide for BigDL-LLM on CPU](#docker-installation-guide-for-bigdl-llm-on-cpu)
|
- [Docker installation guide for IPEX-LLM on CPU](#docker-installation-guide-for-ipex-llm-on-cpu)
|
||||||
- [BigDL-LLM on Windows](#bigdl-llm-on-windows)
|
- [IPEX-LLM on Windows](#ipex-llm-on-windows)
|
||||||
- [BigDL-LLM on Linux/MacOS](#bigdl-llm-on-linuxmacos)
|
- [IPEX-LLM on Linux/MacOS](#ipex-llm-on-linuxmacos)
|
||||||
- [Docker installation guide for BigDL LLM on XPU](#docker-installation-guide-for-bigdl-llm-on-xpu)
|
- [Docker installation guide for IPEX LLM on XPU](#docker-installation-guide-for-ipex-llm-on-xpu)
|
||||||
- [Docker installation guide for BigDL LLM Serving on CPU](#docker-installation-guide-for-bigdl-llm-serving-on-cpu)
|
- [Docker installation guide for IPEX LLM Serving on CPU](#docker-installation-guide-for-ipex-llm-serving-on-cpu)
|
||||||
- [Docker installation guide for BigDL LLM Serving on XPU](#docker-installation-guide-for-bigdl-llm-serving-on-xpu)
|
- [Docker installation guide for IPEX LLM Serving on XPU](#docker-installation-guide-for-ipex-llm-serving-on-xpu)
|
||||||
- [Docker installation guide for BigDL LLM Fine Tuning on CPU](#docker-installation-guide-for-bigdl-llm-fine-tuning-on-cpu)
|
- [Docker installation guide for IPEX LLM Fine Tuning on CPU](#docker-installation-guide-for-ipex-llm-fine-tuning-on-cpu)
|
||||||
- [Docker installation guide for BigDL LLM Fine Tuning on XPU](#docker-installation-guide-for-bigdl-llm-fine-tuning-on-xpu)
|
- [Docker installation guide for IPEX LLM Fine Tuning on XPU](#docker-installation-guide-for-ipex-llm-fine-tuning-on-xpu)
|
||||||
|
|
||||||
## Docker installation guide for BigDL-LLM on CPU
|
## Docker installation guide for IPEX-LLM on CPU
|
||||||
|
|
||||||
### BigDL-LLM on Windows
|
### IPEX-LLM on Windows
|
||||||
|
|
||||||
#### Install docker
|
#### Install docker
|
||||||
|
|
||||||
|
|
@ -23,26 +23,26 @@ The instructions for installing can be accessed from
|
||||||
[here](https://docs.docker.com/desktop/install/windows-install/).
|
[here](https://docs.docker.com/desktop/install/windows-install/).
|
||||||
|
|
||||||
|
|
||||||
#### Pull bigdl-llm-cpu image
|
#### Pull ipex-llm-cpu image
|
||||||
|
|
||||||
To pull image from hub, you can execute command on console:
|
To pull image from hub, you can execute command on console:
|
||||||
```bash
|
```bash
|
||||||
docker pull intelanalytics/bigdl-llm-cpu:2.5.0-SNAPSHOT
|
docker pull intelanalytics/ipex-llm-cpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
to check if the image is successfully downloaded, you can use:
|
to check if the image is successfully downloaded, you can use:
|
||||||
```powershell
|
```powershell
|
||||||
docker images | sls intelanalytics/bigdl-llm-cpu:2.5.0-SNAPSHOT
|
docker images | sls intelanalytics/ipex-llm-cpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
#### Start bigdl-llm-cpu container
|
#### Start ipex-llm-cpu container
|
||||||
|
|
||||||
To run the image and do inference, you could create and run a bat script on Windows.
|
To run the image and do inference, you could create and run a bat script on Windows.
|
||||||
|
|
||||||
An example on Windows could be:
|
An example on Windows could be:
|
||||||
```bat
|
```bat
|
||||||
@echo off
|
@echo off
|
||||||
set DOCKER_IMAGE=intelanalytics/bigdl-llm-cpu:2.5.0-SNAPSHOT
|
set DOCKER_IMAGE=intelanalytics/ipex-llm-cpu:2.5.0-SNAPSHOT
|
||||||
set CONTAINER_NAME=my_container
|
set CONTAINER_NAME=my_container
|
||||||
set MODEL_PATH=D:/llm/models[change to your model path]
|
set MODEL_PATH=D:/llm/models[change to your model path]
|
||||||
|
|
||||||
|
|
@ -62,7 +62,7 @@ After the container is booted, you could get into the container through `docker
|
||||||
docker exec -it my_container bash
|
docker exec -it my_container bash
|
||||||
```
|
```
|
||||||
|
|
||||||
To run inference using `BigDL-LLM` using cpu, you could refer to this [documentation](https://github.com/intel-analytics/BigDL/tree/main/python/llm#cpu-int4).
|
To run inference using `IPEX-LLM` using cpu, you could refer to this [documentation](https://github.com/intel-analytics/IPEX/tree/main/python/llm#cpu-int4).
|
||||||
|
|
||||||
|
|
||||||
#### Getting started with chat
|
#### Getting started with chat
|
||||||
|
|
@ -89,7 +89,7 @@ Here is a demostration:
|
||||||
|
|
||||||
#### Getting started with tutorials
|
#### Getting started with tutorials
|
||||||
|
|
||||||
You could start a jupyter-lab serving to explore bigdl-llm-tutorial which can help you build a more sophisticated Chatbo.
|
You could start a jupyter-lab serving to explore ipex-llm-tutorial which can help you build a more sophisticated Chatbo.
|
||||||
|
|
||||||
To start serving, run the script under '/llm':
|
To start serving, run the script under '/llm':
|
||||||
```bash
|
```bash
|
||||||
|
|
@ -107,12 +107,12 @@ Here is a demostration of how to use tutorial in explorer:
|
||||||
|
|
||||||
</a>
|
</a>
|
||||||
|
|
||||||
### BigDL-LLM on Linux/MacOS
|
### IPEX-LLM on Linux/MacOS
|
||||||
|
|
||||||
To run container on Linux/MacOS:
|
To run container on Linux/MacOS:
|
||||||
```bash
|
```bash
|
||||||
#/bin/bash
|
#/bin/bash
|
||||||
export DOCKER_IMAGE=intelanalytics/bigdl-llm-cpu:2.5.0-SNAPSHOT
|
export DOCKER_IMAGE=intelanalytics/ipex-llm-cpu:2.5.0-SNAPSHOT
|
||||||
export CONTAINER_NAME=my_container
|
export CONTAINER_NAME=my_container
|
||||||
export MODEL_PATH=/llm/models[change to your model path]
|
export MODEL_PATH=/llm/models[change to your model path]
|
||||||
|
|
||||||
|
|
@ -126,23 +126,23 @@ docker run -itd \
|
||||||
$DOCKER_IMAGE
|
$DOCKER_IMAGE
|
||||||
```
|
```
|
||||||
|
|
||||||
Also, you could use chat.py and bigdl-llm-tutorial for development.
|
Also, you could use chat.py and ipex-llm-tutorial for development.
|
||||||
|
|
||||||
[Getting started with chat](#getting-started-with-chat)
|
[Getting started with chat](#getting-started-with-chat)
|
||||||
|
|
||||||
[Getting started with tutorials](#getting-started-with-tutorials)
|
[Getting started with tutorials](#getting-started-with-tutorials)
|
||||||
|
|
||||||
## Docker installation guide for BigDL LLM on XPU
|
## Docker installation guide for IPEX LLM on XPU
|
||||||
|
|
||||||
First, pull docker image from docker hub:
|
First, pull docker image from docker hub:
|
||||||
```
|
```
|
||||||
docker pull intelanalytics/bigdl-llm-xpu:2.5.0-SNAPSHOT
|
docker pull intelanalytics/ipex-llm-xpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
To map the xpu into the container, you need to specify --device=/dev/dri when booting the container.
|
To map the xpu into the container, you need to specify --device=/dev/dri when booting the container.
|
||||||
An example could be:
|
An example could be:
|
||||||
```bash
|
```bash
|
||||||
#/bin/bash
|
#/bin/bash
|
||||||
export DOCKER_IMAGE=intelanalytics/bigdl-llm-xpu:2.5.0-SNAPSHOT
|
export DOCKER_IMAGE=intelanalytics/ipex-llm-xpu:2.5.0-SNAPSHOT
|
||||||
export CONTAINER_NAME=my_container
|
export CONTAINER_NAME=my_container
|
||||||
export MODEL_PATH=/llm/models[change to your model path]
|
export MODEL_PATH=/llm/models[change to your model path]
|
||||||
|
|
||||||
|
|
@ -168,20 +168,20 @@ root@arda-arc12:/# sycl-ls
|
||||||
[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) A770 Graphics 1.3 [1.3.26241]
|
[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) A770 Graphics 1.3 [1.3.26241]
|
||||||
```
|
```
|
||||||
|
|
||||||
To run inference using `BigDL-LLM` using xpu, you could refer to this [documentation](https://github.com/intel-analytics/BigDL/tree/main/python/llm/example/GPU).
|
To run inference using `IPEX-LLM` using xpu, you could refer to this [documentation](https://github.com/intel-analytics/IPEX/tree/main/python/llm/example/GPU).
|
||||||
|
|
||||||
## Docker installation guide for BigDL LLM Serving on CPU
|
## Docker installation guide for IPEX LLM Serving on CPU
|
||||||
|
|
||||||
### Boot container
|
### Boot container
|
||||||
|
|
||||||
Pull image:
|
Pull image:
|
||||||
```
|
```
|
||||||
docker pull intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT
|
docker pull intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
You could use the following bash script to start the container. Please be noted that the CPU config is specified for Xeon CPUs, change it accordingly if you are not using a Xeon CPU.
|
You could use the following bash script to start the container. Please be noted that the CPU config is specified for Xeon CPUs, change it accordingly if you are not using a Xeon CPU.
|
||||||
```bash
|
```bash
|
||||||
export DOCKER_IMAGE=intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT
|
export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT
|
||||||
export CONTAINER_NAME=my_container
|
export CONTAINER_NAME=my_container
|
||||||
export MODEL_PATH=/llm/models[change to your model path]
|
export MODEL_PATH=/llm/models[change to your model path]
|
||||||
|
|
||||||
|
|
@ -198,14 +198,11 @@ After the container is booted, you could get into the container through `docker
|
||||||
|
|
||||||
### Models
|
### Models
|
||||||
|
|
||||||
Using BigDL-LLM in FastChat does not impose any new limitations on model usage. Therefore, all Hugging Face Transformer models can be utilized in FastChat.
|
Using IPEX-LLM in FastChat does not impose any new limitations on model usage. Therefore, all Hugging Face Transformer models can be utilized in FastChat.
|
||||||
|
|
||||||
FastChat determines the Model adapter to use through path matching. Therefore, in order to load models using BigDL-LLM, you need to make some modifications to the model's name.
|
FastChat determines the Model adapter to use through path matching. Therefore, in order to load models using IPEX-LLM, you need to make some modifications to the model's name.
|
||||||
|
|
||||||
For instance, assuming you have downloaded the `llama-7b-hf` from [HuggingFace](https://huggingface.co/decapoda-research/llama-7b-hf). Then, to use the `BigDL-LLM` as backend, you need to change name from `llama-7b-hf` to `bigdl-7b`.
|
A special case is `ChatGLM` models. For these models, you do not need to do any changes after downloading the model and the `IPEX-LLM` backend will be used automatically.
|
||||||
The key point here is that the model's path should include "bigdl" and should not include paths matched by other model adapters.
|
|
||||||
|
|
||||||
A special case is `ChatGLM` models. For these models, you do not need to do any changes after downloading the model and the `BigDL-LLM` backend will be used automatically.
|
|
||||||
|
|
||||||
|
|
||||||
### Start the service
|
### Start the service
|
||||||
|
|
@ -237,11 +234,11 @@ python3 -m fastchat.serve.gradio_web_server
|
||||||
|
|
||||||
This is the user interface that users will interact with.
|
This is the user interface that users will interact with.
|
||||||
|
|
||||||
By following these steps, you will be able to serve your models using the web UI with `BigDL-LLM` as the backend. You can open your browser and chat with a model now.
|
By following these steps, you will be able to serve your models using the web UI with `IPEX-LLM` as the backend. You can open your browser and chat with a model now.
|
||||||
|
|
||||||
#### Serving with OpenAI-Compatible RESTful APIs
|
#### Serving with OpenAI-Compatible RESTful APIs
|
||||||
|
|
||||||
To start an OpenAI API server that provides compatible APIs using `BigDL-LLM` backend, you need three main components: an OpenAI API Server that serves the in-coming requests, model workers that host one or more models, and a controller to coordinate the web server and model workers.
|
To start an OpenAI API server that provides compatible APIs using `IPEX-LLM` backend, you need three main components: an OpenAI API Server that serves the in-coming requests, model workers that host one or more models, and a controller to coordinate the web server and model workers.
|
||||||
|
|
||||||
First, launch the controller
|
First, launch the controller
|
||||||
|
|
||||||
|
|
@ -262,13 +259,13 @@ python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
## Docker installation guide for BigDL LLM Serving on XPU
|
## Docker installation guide for IPEX LLM Serving on XPU
|
||||||
|
|
||||||
### Boot container
|
### Boot container
|
||||||
|
|
||||||
Pull image:
|
Pull image:
|
||||||
```
|
```
|
||||||
docker pull intelanalytics/bigdl-llm-serving-xpu:2.5.0-SNAPSHOT
|
docker pull intelanalytics/ipex-llm-serving-xpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
To map the `xpu` into the container, you need to specify `--device=/dev/dri` when booting the container.
|
To map the `xpu` into the container, you need to specify `--device=/dev/dri` when booting the container.
|
||||||
|
|
@ -276,7 +273,7 @@ To map the `xpu` into the container, you need to specify `--device=/dev/dri` whe
|
||||||
An example could be:
|
An example could be:
|
||||||
```bash
|
```bash
|
||||||
#/bin/bash
|
#/bin/bash
|
||||||
export DOCKER_IMAGE=intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT
|
export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT
|
||||||
export CONTAINER_NAME=my_container
|
export CONTAINER_NAME=my_container
|
||||||
export MODEL_PATH=/llm/models[change to your model path]
|
export MODEL_PATH=/llm/models[change to your model path]
|
||||||
export SERVICE_MODEL_PATH=/llm/models/chatglm2-6b[a specified model path for running service]
|
export SERVICE_MODEL_PATH=/llm/models/chatglm2-6b[a specified model path for running service]
|
||||||
|
|
@ -331,11 +328,11 @@ python3 -m fastchat.serve.gradio_web_server
|
||||||
|
|
||||||
This is the user interface that users will interact with.
|
This is the user interface that users will interact with.
|
||||||
|
|
||||||
By following these steps, you will be able to serve your models using the web UI with `BigDL-LLM` as the backend. You can open your browser and chat with a model now.
|
By following these steps, you will be able to serve your models using the web UI with `IPEX-LLM` as the backend. You can open your browser and chat with a model now.
|
||||||
|
|
||||||
#### Serving with OpenAI-Compatible RESTful APIs
|
#### Serving with OpenAI-Compatible RESTful APIs
|
||||||
|
|
||||||
To start an OpenAI API server that provides compatible APIs using `BigDL-LLM` backend, you need three main components: an OpenAI API Server that serves the in-coming requests, model workers that host one or more models, and a controller to coordinate the web server and model workers.
|
To start an OpenAI API server that provides compatible APIs using `IPEX-LLM` backend, you need three main components: an OpenAI API Server that serves the in-coming requests, model workers that host one or more models, and a controller to coordinate the web server and model workers.
|
||||||
|
|
||||||
First, launch the controller
|
First, launch the controller
|
||||||
|
|
||||||
|
|
@ -355,7 +352,7 @@ Finally, launch the RESTful API server
|
||||||
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
|
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
|
||||||
```
|
```
|
||||||
|
|
||||||
## Docker installation guide for BigDL LLM Fine Tuning on CPU
|
## Docker installation guide for IPEX LLM Fine Tuning on CPU
|
||||||
|
|
||||||
### 1. Prepare Docker Image
|
### 1. Prepare Docker Image
|
||||||
|
|
||||||
|
|
@ -363,10 +360,10 @@ You can download directly from Dockerhub like:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# For standalone
|
# For standalone
|
||||||
docker pull intelanalytics/bigdl-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
docker pull intelanalytics/ipex-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
||||||
|
|
||||||
# For k8s
|
# For k8s
|
||||||
docker pull intelanalytics/bigdl-llm-finetune-qlora-cpu-k8s:2.5.0-SNAPSHOT
|
docker pull intelanalytics/ipex-llm-finetune-qlora-cpu-k8s:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
Or build the image from source:
|
Or build the image from source:
|
||||||
|
|
@ -379,7 +376,7 @@ export HTTPS_PROXY=your_https_proxy
|
||||||
docker build \
|
docker build \
|
||||||
--build-arg http_proxy=${HTTP_PROXY} \
|
--build-arg http_proxy=${HTTP_PROXY} \
|
||||||
--build-arg https_proxy=${HTTPS_PROXY} \
|
--build-arg https_proxy=${HTTPS_PROXY} \
|
||||||
-t intelanalytics/bigdl-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT \
|
-t intelanalytics/ipex-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT \
|
||||||
-f ./Dockerfile .
|
-f ./Dockerfile .
|
||||||
|
|
||||||
# For k8s
|
# For k8s
|
||||||
|
|
@ -389,7 +386,7 @@ export HTTPS_PROXY=your_https_proxy
|
||||||
docker build \
|
docker build \
|
||||||
--build-arg http_proxy=${HTTP_PROXY} \
|
--build-arg http_proxy=${HTTP_PROXY} \
|
||||||
--build-arg https_proxy=${HTTPS_PROXY} \
|
--build-arg https_proxy=${HTTPS_PROXY} \
|
||||||
-t intelanalytics/bigdl-llm-finetune-qlora-cpu-k8s:2.5.0-SNAPSHOT \
|
-t intelanalytics/ipex-llm-finetune-qlora-cpu-k8s:2.5.0-SNAPSHOT \
|
||||||
-f ./Dockerfile.k8s .
|
-f ./Dockerfile.k8s .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -405,12 +402,12 @@ export HTTPS_PROXY=your_https_proxy
|
||||||
|
|
||||||
docker run -itd \
|
docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
--name=bigdl-llm-fintune-qlora-cpu \
|
--name=ipex-llm-fintune-qlora-cpu \
|
||||||
-e http_proxy=${HTTP_PROXY} \
|
-e http_proxy=${HTTP_PROXY} \
|
||||||
-e https_proxy=${HTTPS_PROXY} \
|
-e https_proxy=${HTTPS_PROXY} \
|
||||||
-v $BASE_MODE_PATH:/bigdl/model \
|
-v $BASE_MODE_PATH:/ipex_llm/model \
|
||||||
-v $DATA_PATH:/bigdl/data/alpaca-cleaned \
|
-v $DATA_PATH:/ipex_llm/data/alpaca-cleaned \
|
||||||
intelanalytics/bigdl-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
intelanalytics/ipex-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
The download and mount of base model and data to a docker container demonstrates a standard fine-tuning process. You can skip this step for a quick start, and in this way, the fine-tuning codes will automatically download the needed files:
|
The download and mount of base model and data to a docker container demonstrates a standard fine-tuning process. You can skip this step for a quick start, and in this way, the fine-tuning codes will automatically download the needed files:
|
||||||
|
|
@ -421,10 +418,10 @@ export HTTPS_PROXY=your_https_proxy
|
||||||
|
|
||||||
docker run -itd \
|
docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
--name=bigdl-llm-fintune-qlora-cpu \
|
--name=ipex-llm-fintune-qlora-cpu \
|
||||||
-e http_proxy=${HTTP_PROXY} \
|
-e http_proxy=${HTTP_PROXY} \
|
||||||
-e https_proxy=${HTTPS_PROXY} \
|
-e https_proxy=${HTTPS_PROXY} \
|
||||||
intelanalytics/bigdl-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
intelanalytics/ipex-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
However, we do recommend you to handle them manually, because the automatical download can be blocked by Internet access and Huggingface authentication etc. according to different environment, and the manual method allows you to fine-tune in a custom way (with different base model and dataset).
|
However, we do recommend you to handle them manually, because the automatical download can be blocked by Internet access and Huggingface authentication etc. according to different environment, and the manual method allows you to fine-tune in a custom way (with different base model and dataset).
|
||||||
|
|
@ -434,14 +431,14 @@ However, we do recommend you to handle them manually, because the automatical do
|
||||||
Enter the running container:
|
Enter the running container:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker exec -it bigdl-llm-fintune-qlora-cpu bash
|
docker exec -it ipex-llm-fintune-qlora-cpu bash
|
||||||
```
|
```
|
||||||
|
|
||||||
Then, start QLoRA fine-tuning:
|
Then, start QLoRA fine-tuning:
|
||||||
If the machine memory is not enough, you can try to set `use_gradient_checkpointing=True`.
|
If the machine memory is not enough, you can try to set `use_gradient_checkpointing=True`.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
cd /bigdl
|
cd /ipex_llm
|
||||||
bash start-qlora-finetuning-on-cpu.sh
|
bash start-qlora-finetuning-on-cpu.sh
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -473,16 +470,16 @@ python ./export_merged_model.py --repo-id-or-model-path REPO_ID_OR_MODEL_PATH --
|
||||||
|
|
||||||
Then you can use `./outputs/checkpoint-200-merged` as a normal huggingface transformer model to do inference.
|
Then you can use `./outputs/checkpoint-200-merged` as a normal huggingface transformer model to do inference.
|
||||||
|
|
||||||
## Docker installation guide for BigDL LLM Fine Tuning on XPU
|
## Docker installation guide for IPEX LLM Fine Tuning on XPU
|
||||||
|
|
||||||
The following shows how to fine-tune LLM with Quantization (QLoRA built on BigDL-LLM 4bit optimizations) in a docker environment, which is accelerated by Intel XPU.
|
The following shows how to fine-tune LLM with Quantization (QLoRA built on IPEX-LLM 4bit optimizations) in a docker environment, which is accelerated by Intel XPU.
|
||||||
|
|
||||||
### 1. Prepare Docker Image
|
### 1. Prepare Docker Image
|
||||||
|
|
||||||
You can download directly from Dockerhub like:
|
You can download directly from Dockerhub like:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker pull intelanalytics/bigdl-llm-finetune-qlora-xpu:2.5.0-SNAPSHOT
|
docker pull intelanalytics/ipex-llm-finetune-qlora-xpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
Or build the image from source:
|
Or build the image from source:
|
||||||
|
|
@ -494,7 +491,7 @@ export HTTPS_PROXY=your_https_proxy
|
||||||
docker build \
|
docker build \
|
||||||
--build-arg http_proxy=${HTTP_PROXY} \
|
--build-arg http_proxy=${HTTP_PROXY} \
|
||||||
--build-arg https_proxy=${HTTPS_PROXY} \
|
--build-arg https_proxy=${HTTPS_PROXY} \
|
||||||
-t intelanalytics/bigdl-llm-finetune-qlora-xpu:2.5.0-SNAPSHOT \
|
-t intelanalytics/ipex-llm-finetune-qlora-xpu:2.5.0-SNAPSHOT \
|
||||||
-f ./Dockerfile .
|
-f ./Dockerfile .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -512,13 +509,13 @@ docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
--device=/dev/dri \
|
--device=/dev/dri \
|
||||||
--memory="32G" \
|
--memory="32G" \
|
||||||
--name=bigdl-llm-fintune-qlora-xpu \
|
--name=ipex-llm-fintune-qlora-xpu \
|
||||||
-e http_proxy=${HTTP_PROXY} \
|
-e http_proxy=${HTTP_PROXY} \
|
||||||
-e https_proxy=${HTTPS_PROXY} \
|
-e https_proxy=${HTTPS_PROXY} \
|
||||||
-v $BASE_MODE_PATH:/model \
|
-v $BASE_MODE_PATH:/model \
|
||||||
-v $DATA_PATH:/data/alpaca-cleaned \
|
-v $DATA_PATH:/data/alpaca-cleaned \
|
||||||
--shm-size="16g" \
|
--shm-size="16g" \
|
||||||
intelanalytics/bigdl-llm-fintune-qlora-xpu:2.5.0-SNAPSHOT
|
intelanalytics/ipex-llm-fintune-qlora-xpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
The download and mount of base model and data to a docker container demonstrates a standard fine-tuning process. You can skip this step for a quick start, and in this way, the fine-tuning codes will automatically download the needed files:
|
The download and mount of base model and data to a docker container demonstrates a standard fine-tuning process. You can skip this step for a quick start, and in this way, the fine-tuning codes will automatically download the needed files:
|
||||||
|
|
@ -531,11 +528,11 @@ docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
--device=/dev/dri \
|
--device=/dev/dri \
|
||||||
--memory="32G" \
|
--memory="32G" \
|
||||||
--name=bigdl-llm-fintune-qlora-xpu \
|
--name=ipex-llm-fintune-qlora-xpu \
|
||||||
-e http_proxy=${HTTP_PROXY} \
|
-e http_proxy=${HTTP_PROXY} \
|
||||||
-e https_proxy=${HTTPS_PROXY} \
|
-e https_proxy=${HTTPS_PROXY} \
|
||||||
--shm-size="16g" \
|
--shm-size="16g" \
|
||||||
intelanalytics/bigdl-llm-fintune-qlora-xpu:2.5.0-SNAPSHOT
|
intelanalytics/ipex-llm-fintune-qlora-xpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
However, we do recommend you to handle them manually, because the automatical download can be blocked by Internet access and Huggingface authentication etc. according to different environment, and the manual method allows you to fine-tune in a custom way (with different base model and dataset).
|
However, we do recommend you to handle them manually, because the automatical download can be blocked by Internet access and Huggingface authentication etc. according to different environment, and the manual method allows you to fine-tune in a custom way (with different base model and dataset).
|
||||||
|
|
@ -545,7 +542,7 @@ However, we do recommend you to handle them manually, because the automatical do
|
||||||
Enter the running container:
|
Enter the running container:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker exec -it bigdl-llm-fintune-qlora-xpu bash
|
docker exec -it ipex-llm-fintune-qlora-xpu bash
|
||||||
```
|
```
|
||||||
|
|
||||||
Then, start QLoRA fine-tuning:
|
Then, start QLoRA fine-tuning:
|
||||||
|
|
|
||||||
|
|
@ -2,13 +2,13 @@
|
||||||
|
|
||||||
[Alpaca Lora](https://github.com/tloen/alpaca-lora/tree/main) uses [low-rank adaption](https://arxiv.org/pdf/2106.09685.pdf) to speed up the finetuning process of base model [Llama2-7b](https://huggingface.co/meta-llama/Llama-2-7b), and tries to reproduce the standard Alpaca, a general finetuned LLM. This is on top of Hugging Face transformers with Pytorch backend, which natively requires a number of expensive GPU resources and takes significant time.
|
[Alpaca Lora](https://github.com/tloen/alpaca-lora/tree/main) uses [low-rank adaption](https://arxiv.org/pdf/2106.09685.pdf) to speed up the finetuning process of base model [Llama2-7b](https://huggingface.co/meta-llama/Llama-2-7b), and tries to reproduce the standard Alpaca, a general finetuned LLM. This is on top of Hugging Face transformers with Pytorch backend, which natively requires a number of expensive GPU resources and takes significant time.
|
||||||
|
|
||||||
By constract, BigDL here provides a CPU optimization to accelerate the lora finetuning of Llama2-7b, in the power of mixed-precision and distributed training. Detailedly, [Intel OneCCL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/oneccl.html), an available Hugging Face backend, is able to speed up the Pytorch computation with BF16 datatype on CPUs, as well as parallel processing on Kubernetes enabled by [Intel MPI](https://www.intel.com/content/www/us/en/developer/tools/oneapi/mpi-library.html).
|
By constract, IPEX-LLM here provides a CPU optimization to accelerate the lora finetuning of Llama2-7b, in the power of mixed-precision and distributed training. Detailedly, [Intel OneCCL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/oneccl.html), an available Hugging Face backend, is able to speed up the Pytorch computation with BF16 datatype on CPUs, as well as parallel processing on Kubernetes enabled by [Intel MPI](https://www.intel.com/content/www/us/en/developer/tools/oneapi/mpi-library.html).
|
||||||
|
|
||||||
The architecture is illustrated in the following:
|
The architecture is illustrated in the following:
|
||||||
|
|
||||||
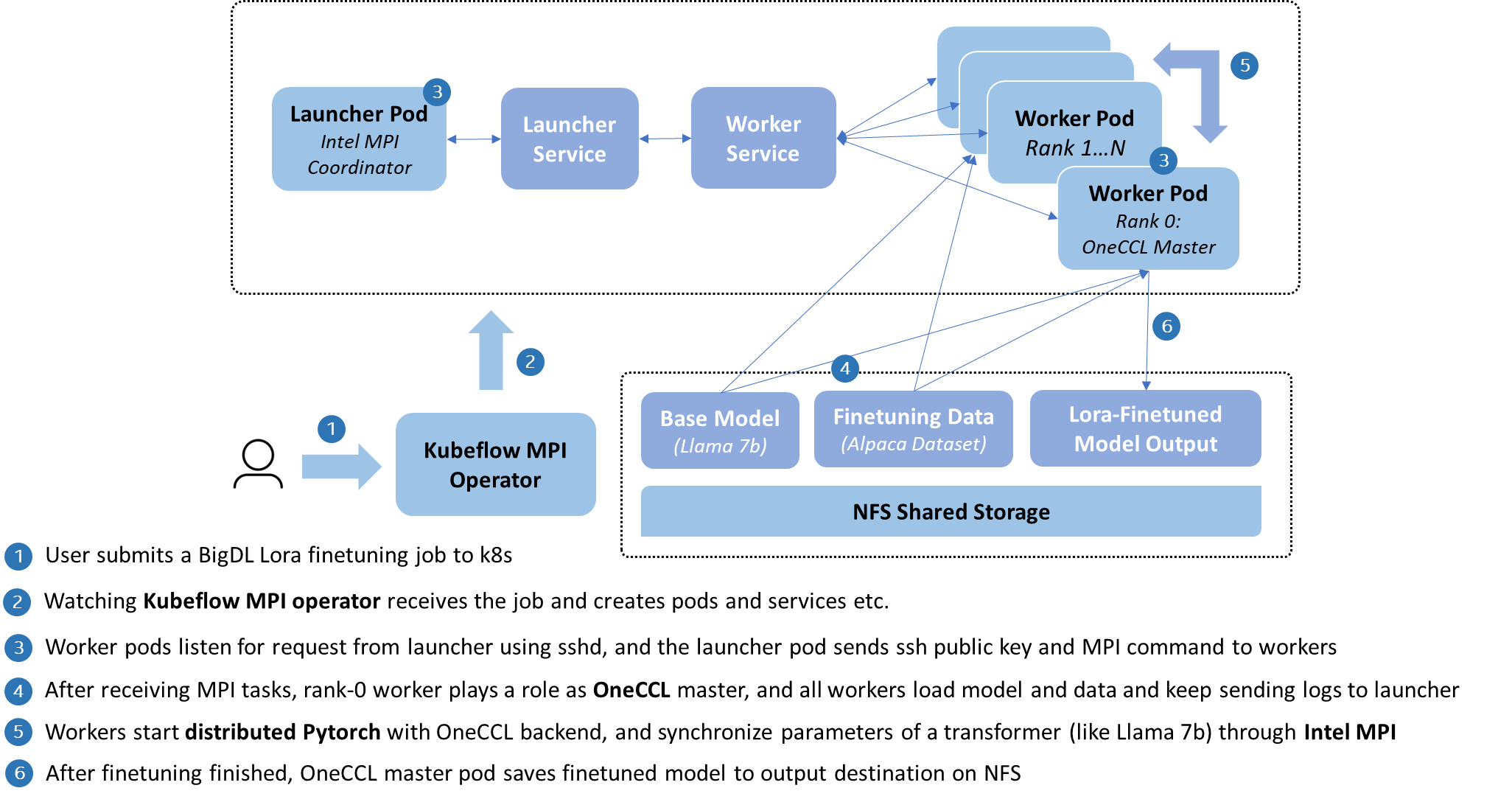
|

|
||||||
|
|
||||||
As above, BigDL implements its MPI training with [Kubeflow MPI operator](https://github.com/kubeflow/mpi-operator/tree/master), which encapsulates the deployment as MPIJob CRD, and assists users to handle the construction of a MPI worker cluster on Kubernetes, such as public key distribution, SSH connection, and log collection.
|
As above, IPEX-LLM implements its MPI training with [Kubeflow MPI operator](https://github.com/kubeflow/mpi-operator/tree/master), which encapsulates the deployment as MPIJob CRD, and assists users to handle the construction of a MPI worker cluster on Kubernetes, such as public key distribution, SSH connection, and log collection.
|
||||||
|
|
||||||
Now, let's go to deploy a Lora finetuning to create a LLM from Llama2-7b.
|
Now, let's go to deploy a Lora finetuning to create a LLM from Llama2-7b.
|
||||||
|
|
||||||
|
|
@ -20,7 +20,7 @@ Follow [here](https://github.com/kubeflow/mpi-operator/tree/master#installation)
|
||||||
|
|
||||||
### 2. Download Image, Base Model and Finetuning Data
|
### 2. Download Image, Base Model and Finetuning Data
|
||||||
|
|
||||||
Follow [here](https://github.com/intel-analytics/BigDL/tree/main/docker/llm/finetune/lora/docker#prepare-bigdl-image-for-lora-finetuning) to prepare BigDL Lora Finetuning image in your cluster.
|
Follow [here](https://github.com/intel-analytics/IPEX-LLM/tree/main/docker/llm/finetune/lora/docker#prepare-ipex-llm-image-for-lora-finetuning) to prepare IPEX-LLM Lora Finetuning image in your cluster.
|
||||||
|
|
||||||
As finetuning is from a base model, first download [Llama2-7b model from the public download site of Hugging Face](https://huggingface.co/meta-llama/Llama-2-7b). Then, download [cleaned alpaca data](https://raw.githubusercontent.com/tloen/alpaca-lora/main/alpaca_data_cleaned_archive.json), which contains all kinds of general knowledge and has already been cleaned. Next, move the downloaded files to a shared directory on your NFS server.
|
As finetuning is from a base model, first download [Llama2-7b model from the public download site of Hugging Face](https://huggingface.co/meta-llama/Llama-2-7b). Then, download [cleaned alpaca data](https://raw.githubusercontent.com/tloen/alpaca-lora/main/alpaca_data_cleaned_archive.json), which contains all kinds of general knowledge and has already been cleaned. Next, move the downloaded files to a shared directory on your NFS server.
|
||||||
|
|
||||||
|
|
@ -34,12 +34,12 @@ After preparing parameters in `./kubernetes/values.yaml`, submit the job as befl
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
cd ./kubernetes
|
cd ./kubernetes
|
||||||
helm install bigdl-lora-finetuning .
|
helm install ipex-llm-lora-finetuning .
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4. Check Deployment
|
### 4. Check Deployment
|
||||||
```bash
|
```bash
|
||||||
kubectl get all -n bigdl-lora-finetuning # you will see launcher and worker pods running
|
kubectl get all -n ipex-llm-lora-finetuning # you will see launcher and worker pods running
|
||||||
```
|
```
|
||||||
|
|
||||||
### 5. Check Finetuning Process
|
### 5. Check Finetuning Process
|
||||||
|
|
@ -47,8 +47,8 @@ kubectl get all -n bigdl-lora-finetuning # you will see launcher and worker pods
|
||||||
After deploying successfully, you can find a launcher pod, and then go inside this pod and check the logs collected from all workers.
|
After deploying successfully, you can find a launcher pod, and then go inside this pod and check the logs collected from all workers.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
kubectl get all -n bigdl-lora-finetuning # you will see a launcher pod
|
kubectl get all -n ipex-llm-lora-finetuning # you will see a launcher pod
|
||||||
kubectl exec -it <launcher_pod_name> bash -n bigdl-ppml-finetuning # enter launcher pod
|
kubectl exec -it <launcher_pod_name> bash -n ipex-llm-lora-finetuning # enter launcher pod
|
||||||
cat launcher.log # display logs collected from other workers
|
cat launcher.log # display logs collected from other workers
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -12,13 +12,13 @@ FROM mpioperator/intel as builder
|
||||||
ARG http_proxy
|
ARG http_proxy
|
||||||
ARG https_proxy
|
ARG https_proxy
|
||||||
ENV PIP_NO_CACHE_DIR=false
|
ENV PIP_NO_CACHE_DIR=false
|
||||||
COPY ./requirements.txt /bigdl/requirements.txt
|
COPY ./requirements.txt /ipex_llm/requirements.txt
|
||||||
|
|
||||||
# add public key
|
# add public key
|
||||||
COPY --from=key-getter /root/intel-oneapi-archive-keyring.gpg /usr/share/keyrings/intel-oneapi-archive-keyring.gpg
|
COPY --from=key-getter /root/intel-oneapi-archive-keyring.gpg /usr/share/keyrings/intel-oneapi-archive-keyring.gpg
|
||||||
RUN echo "deb [signed-by=/usr/share/keyrings/intel-oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main " > /etc/apt/sources.list.d/oneAPI.list
|
RUN echo "deb [signed-by=/usr/share/keyrings/intel-oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main " > /etc/apt/sources.list.d/oneAPI.list
|
||||||
|
|
||||||
RUN mkdir /bigdl/data && mkdir /bigdl/model && \
|
RUN mkdir /ipex_llm/data && mkdir /ipex_llm/model && \
|
||||||
# install pytorch 2.0.1
|
# install pytorch 2.0.1
|
||||||
apt-get update && \
|
apt-get update && \
|
||||||
apt-get install -y python3-pip python3.9-dev python3-wheel git software-properties-common && \
|
apt-get install -y python3-pip python3.9-dev python3-wheel git software-properties-common && \
|
||||||
|
|
@ -29,12 +29,12 @@ RUN mkdir /bigdl/data && mkdir /bigdl/model && \
|
||||||
pip install intel_extension_for_pytorch==2.0.100 && \
|
pip install intel_extension_for_pytorch==2.0.100 && \
|
||||||
pip install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable && \
|
pip install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable && \
|
||||||
# install transformers etc.
|
# install transformers etc.
|
||||||
cd /bigdl && \
|
cd /ipex_llm && \
|
||||||
git clone https://github.com/huggingface/transformers.git && \
|
git clone https://github.com/huggingface/transformers.git && \
|
||||||
cd transformers && \
|
cd transformers && \
|
||||||
git reset --hard 057e1d74733f52817dc05b673a340b4e3ebea08c && \
|
git reset --hard 057e1d74733f52817dc05b673a340b4e3ebea08c && \
|
||||||
pip install . && \
|
pip install . && \
|
||||||
pip install -r /bigdl/requirements.txt && \
|
pip install -r /ipex_llm/requirements.txt && \
|
||||||
# install python
|
# install python
|
||||||
add-apt-repository ppa:deadsnakes/ppa -y && \
|
add-apt-repository ppa:deadsnakes/ppa -y && \
|
||||||
apt-get install -y python3.9 && \
|
apt-get install -y python3.9 && \
|
||||||
|
|
@ -56,9 +56,9 @@ RUN mkdir /bigdl/data && mkdir /bigdl/model && \
|
||||||
echo " UserKnownHostsFile /dev/null" >> /etc/ssh/ssh_config && \
|
echo " UserKnownHostsFile /dev/null" >> /etc/ssh/ssh_config && \
|
||||||
sed -i 's/#\(StrictModes \).*/\1no/g' /etc/ssh/sshd_config
|
sed -i 's/#\(StrictModes \).*/\1no/g' /etc/ssh/sshd_config
|
||||||
|
|
||||||
COPY ./bigdl-lora-finetuing-entrypoint.sh /bigdl/bigdl-lora-finetuing-entrypoint.sh
|
COPY ./ipex-llm-lora-finetuing-entrypoint.sh /ipex_llm/ipex-llm-lora-finetuing-entrypoint.sh
|
||||||
COPY ./lora_finetune.py /bigdl/lora_finetune.py
|
COPY ./lora_finetune.py /ipex_llm/lora_finetune.py
|
||||||
|
|
||||||
RUN chown -R mpiuser /bigdl
|
RUN chown -R mpiuser /ipex_llm
|
||||||
USER mpiuser
|
USER mpiuser
|
||||||
ENTRYPOINT ["/bin/bash"]
|
ENTRYPOINT ["/bin/bash"]
|
||||||
|
|
|
||||||
|
|
@ -1,11 +1,11 @@
|
||||||
## Fine-tune LLM with One CPU
|
## Fine-tune LLM with One CPU
|
||||||
|
|
||||||
### 1. Prepare BigDL image for Lora Finetuning
|
### 1. Prepare IPEX LLM image for Lora Finetuning
|
||||||
|
|
||||||
You can download directly from Dockerhub like:
|
You can download directly from Dockerhub like:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker pull intelanalytics/bigdl-llm-finetune-lora-cpu:2.5.0-SNAPSHOT
|
docker pull intelanalytics/ipex-llm-finetune-lora-cpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
Or build the image from source:
|
Or build the image from source:
|
||||||
|
|
@ -17,7 +17,7 @@ export HTTPS_PROXY=your_https_proxy
|
||||||
docker build \
|
docker build \
|
||||||
--build-arg http_proxy=${HTTP_PROXY} \
|
--build-arg http_proxy=${HTTP_PROXY} \
|
||||||
--build-arg https_proxy=${HTTPS_PROXY} \
|
--build-arg https_proxy=${HTTPS_PROXY} \
|
||||||
-t intelanalytics/bigdl-llm-finetune-lora-cpu:2.5.0-SNAPSHOT \
|
-t intelanalytics/ipex-llm-finetune-lora-cpu:2.5.0-SNAPSHOT \
|
||||||
-f ./Dockerfile .
|
-f ./Dockerfile .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -27,13 +27,13 @@ Here, we try to finetune [Llama2-7b](https://huggingface.co/meta-llama/Llama-2-7
|
||||||
|
|
||||||
```
|
```
|
||||||
docker run -itd \
|
docker run -itd \
|
||||||
--name=bigdl-llm-fintune-lora-cpu \
|
--name=ipex-llm-fintune-lora-cpu \
|
||||||
--cpuset-cpus="your_expected_range_of_cpu_numbers" \
|
--cpuset-cpus="your_expected_range_of_cpu_numbers" \
|
||||||
-e STANDALONE_DOCKER=TRUE \
|
-e STANDALONE_DOCKER=TRUE \
|
||||||
-e WORKER_COUNT_DOCKER=your_worker_count \
|
-e WORKER_COUNT_DOCKER=your_worker_count \
|
||||||
-v your_downloaded_base_model_path:/bigdl/model \
|
-v your_downloaded_base_model_path:/ipex_llm/model \
|
||||||
-v your_downloaded_data_path:/bigdl/data/alpaca_data_cleaned_archive.json \
|
-v your_downloaded_data_path:/ipex_llm/data/alpaca_data_cleaned_archive.json \
|
||||||
intelanalytics/bigdl-llm-finetune-lora-cpu:2.5.0-SNAPSHOT \
|
intelanalytics/ipex-llm-finetune-lora-cpu:2.5.0-SNAPSHOT \
|
||||||
bash
|
bash
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -44,21 +44,21 @@ You can adjust the configuration according to your own environment. After our te
|
||||||
Enter the running container:
|
Enter the running container:
|
||||||
|
|
||||||
```
|
```
|
||||||
docker exec -it bigdl-llm-fintune-lora-cpu bash
|
docker exec -it ipex-llm-fintune-lora-cpu bash
|
||||||
```
|
```
|
||||||
|
|
||||||
Then, run the script to start finetuning:
|
Then, run the script to start finetuning:
|
||||||
|
|
||||||
```
|
```
|
||||||
bash /bigdl/bigdl-lora-finetuing-entrypoint.sh
|
bash /ipex_llm/ipex-llm-lora-finetuing-entrypoint.sh
|
||||||
```
|
```
|
||||||
|
|
||||||
After minutes, it is expected to get results like:
|
After minutes, it is expected to get results like:
|
||||||
|
|
||||||
```
|
```
|
||||||
Training Alpaca-LoRA model with params:
|
Training Alpaca-LoRA model with params:
|
||||||
base_model: /bigdl/model/
|
base_model: /ipex_llm/model/
|
||||||
data_path: /bigdl/data/alpaca_data_cleaned_archive.json
|
data_path: /ipex_llm/data/alpaca_data_cleaned_archive.json
|
||||||
output_dir: /home/mpiuser/finetuned_model
|
output_dir: /home/mpiuser/finetuned_model
|
||||||
batch_size: 128
|
batch_size: 128
|
||||||
micro_batch_size: 8
|
micro_batch_size: 8
|
||||||
|
|
|
||||||
|
|
@ -15,9 +15,9 @@ then
|
||||||
-genv KMP_AFFINITY="granularity=fine,none" \
|
-genv KMP_AFFINITY="granularity=fine,none" \
|
||||||
-genv KMP_BLOCKTIME=1 \
|
-genv KMP_BLOCKTIME=1 \
|
||||||
-genv TF_ENABLE_ONEDNN_OPTS=1 \
|
-genv TF_ENABLE_ONEDNN_OPTS=1 \
|
||||||
python /bigdl/lora_finetune.py \
|
python /ipex_llm/lora_finetune.py \
|
||||||
--base_model '/bigdl/model/' \
|
--base_model '/ipex_llm/model/' \
|
||||||
--data_path "/bigdl/data/alpaca_data_cleaned_archive.json" \
|
--data_path "/ipex_llm/data/alpaca_data_cleaned_archive.json" \
|
||||||
--output_dir "/home/mpiuser/finetuned_model" \
|
--output_dir "/home/mpiuser/finetuned_model" \
|
||||||
--micro_batch_size 8 \
|
--micro_batch_size 8 \
|
||||||
--bf16
|
--bf16
|
||||||
|
|
@ -29,7 +29,7 @@ else
|
||||||
if [ "$WORKER_ROLE" = "launcher" ]
|
if [ "$WORKER_ROLE" = "launcher" ]
|
||||||
then
|
then
|
||||||
sed "s/:1/ /g" /etc/mpi/hostfile > /home/mpiuser/hostfile
|
sed "s/:1/ /g" /etc/mpi/hostfile > /home/mpiuser/hostfile
|
||||||
export DATA_PATH="/bigdl/data/$DATA_SUB_PATH"
|
export DATA_PATH="/ipex_llm/data/$DATA_SUB_PATH"
|
||||||
sleep 10
|
sleep 10
|
||||||
mpirun \
|
mpirun \
|
||||||
-n $WORLD_SIZE \
|
-n $WORLD_SIZE \
|
||||||
|
|
@ -40,8 +40,8 @@ else
|
||||||
-genv KMP_AFFINITY="granularity=fine,none" \
|
-genv KMP_AFFINITY="granularity=fine,none" \
|
||||||
-genv KMP_BLOCKTIME=1 \
|
-genv KMP_BLOCKTIME=1 \
|
||||||
-genv TF_ENABLE_ONEDNN_OPTS=1 \
|
-genv TF_ENABLE_ONEDNN_OPTS=1 \
|
||||||
python /bigdl/lora_finetune.py \
|
python /ipex_llm/lora_finetune.py \
|
||||||
--base_model '/bigdl/model/' \
|
--base_model '/ipex_llm/model/' \
|
||||||
--data_path "$DATA_PATH" \
|
--data_path "$DATA_PATH" \
|
||||||
--output_dir "/home/mpiuser/finetuned_model" \
|
--output_dir "/home/mpiuser/finetuned_model" \
|
||||||
--micro_batch_size $MICRO_BATCH_SIZE \
|
--micro_batch_size $MICRO_BATCH_SIZE \
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
apiVersion: v2
|
apiVersion: v2
|
||||||
name: trusted-fintune-service
|
name: trusted-fintune-service
|
||||||
description: A Helm chart for BigDL PPML Trusted BigData Service on Kubernetes
|
description: A Helm chart for IPEX-LLM Finetuning Service on Kubernetes
|
||||||
type: application
|
type: application
|
||||||
version: 1.1.27
|
version: 1.1.27
|
||||||
appVersion: "1.16.0"
|
appVersion: "1.16.0"
|
||||||
|
|
|
||||||
|
|
@ -1,8 +1,8 @@
|
||||||
apiVersion: kubeflow.org/v2beta1
|
apiVersion: kubeflow.org/v2beta1
|
||||||
kind: MPIJob
|
kind: MPIJob
|
||||||
metadata:
|
metadata:
|
||||||
name: bigdl-lora-finetuning-job
|
name: ipex-llm-lora-finetuning-job
|
||||||
namespace: bigdl-lora-finetuning
|
namespace: ipex-llm-lora-finetuning
|
||||||
spec:
|
spec:
|
||||||
slotsPerWorker: 1
|
slotsPerWorker: 1
|
||||||
runPolicy:
|
runPolicy:
|
||||||
|
|
@ -20,10 +20,10 @@ spec:
|
||||||
claimName: nfs-pvc
|
claimName: nfs-pvc
|
||||||
containers:
|
containers:
|
||||||
- image: {{ .Values.imageName }}
|
- image: {{ .Values.imageName }}
|
||||||
name: bigdl-ppml-finetuning-launcher
|
name: ipex-llm-lora-finetuning-launcher
|
||||||
securityContext:
|
securityContext:
|
||||||
runAsUser: 1000
|
runAsUser: 1000
|
||||||
command: ['sh' , '-c', 'bash /bigdl/bigdl-lora-finetuing-entrypoint.sh']
|
command: ['sh' , '-c', 'bash /ipex_llm/ipex-llm-lora-finetuing-entrypoint.sh']
|
||||||
env:
|
env:
|
||||||
- name: WORKER_ROLE
|
- name: WORKER_ROLE
|
||||||
value: "launcher"
|
value: "launcher"
|
||||||
|
|
@ -34,7 +34,7 @@ spec:
|
||||||
- name: MASTER_PORT
|
- name: MASTER_PORT
|
||||||
value: "42679"
|
value: "42679"
|
||||||
- name: MASTER_ADDR
|
- name: MASTER_ADDR
|
||||||
value: "bigdl-lora-finetuning-job-worker-0.bigdl-lora-finetuning-job-worker"
|
value: "ipex-llm-lora-finetuning-job-worker-0.ipex-llm-lora-finetuning-job-worker"
|
||||||
- name: DATA_SUB_PATH
|
- name: DATA_SUB_PATH
|
||||||
value: "{{ .Values.dataSubPath }}"
|
value: "{{ .Values.dataSubPath }}"
|
||||||
- name: OMP_NUM_THREADS
|
- name: OMP_NUM_THREADS
|
||||||
|
|
@ -46,20 +46,20 @@ spec:
|
||||||
volumeMounts:
|
volumeMounts:
|
||||||
- name: nfs-storage
|
- name: nfs-storage
|
||||||
subPath: {{ .Values.modelSubPath }}
|
subPath: {{ .Values.modelSubPath }}
|
||||||
mountPath: /bigdl/model
|
mountPath: /ipex_llm/model
|
||||||
- name: nfs-storage
|
- name: nfs-storage
|
||||||
subPath: {{ .Values.dataSubPath }}
|
subPath: {{ .Values.dataSubPath }}
|
||||||
mountPath: "/bigdl/data/{{ .Values.dataSubPath }}"
|
mountPath: "/ipex_llm/data/{{ .Values.dataSubPath }}"
|
||||||
Worker:
|
Worker:
|
||||||
replicas: {{ .Values.trainerNum }}
|
replicas: {{ .Values.trainerNum }}
|
||||||
template:
|
template:
|
||||||
spec:
|
spec:
|
||||||
containers:
|
containers:
|
||||||
- image: {{ .Values.imageName }}
|
- image: {{ .Values.imageName }}
|
||||||
name: bigdl-ppml-finetuning-worker
|
name: ipex-llm-lora-finetuning-worker
|
||||||
securityContext:
|
securityContext:
|
||||||
runAsUser: 1000
|
runAsUser: 1000
|
||||||
command: ['sh' , '-c', 'bash /bigdl/bigdl-lora-finetuing-entrypoint.sh']
|
command: ['sh' , '-c', 'bash /ipex_llm/ipex-llm-lora-finetuing-entrypoint.sh']
|
||||||
env:
|
env:
|
||||||
- name: WORKER_ROLE
|
- name: WORKER_ROLE
|
||||||
value: "trainer"
|
value: "trainer"
|
||||||
|
|
@ -70,7 +70,7 @@ spec:
|
||||||
- name: MASTER_PORT
|
- name: MASTER_PORT
|
||||||
value: "42679"
|
value: "42679"
|
||||||
- name: MASTER_ADDR
|
- name: MASTER_ADDR
|
||||||
value: "bigdl-lora-finetuning-job-worker-0.bigdl-lora-finetuning-job-worker"
|
value: "ipex-llm-lora-finetuning-job-worker-0.ipex-llm-lora-finetuning-job-worker"
|
||||||
- name: LOCAL_POD_NAME
|
- name: LOCAL_POD_NAME
|
||||||
valueFrom:
|
valueFrom:
|
||||||
fieldRef:
|
fieldRef:
|
||||||
|
|
@ -78,10 +78,10 @@ spec:
|
||||||
volumeMounts:
|
volumeMounts:
|
||||||
- name: nfs-storage
|
- name: nfs-storage
|
||||||
subPath: {{ .Values.modelSubPath }}
|
subPath: {{ .Values.modelSubPath }}
|
||||||
mountPath: /bigdl/model
|
mountPath: /ipex_llm/model
|
||||||
- name: nfs-storage
|
- name: nfs-storage
|
||||||
subPath: {{ .Values.dataSubPath }}
|
subPath: {{ .Values.dataSubPath }}
|
||||||
mountPath: "/bigdl/data/{{ .Values.dataSubPath }}"
|
mountPath: "/ipex_llm/data/{{ .Values.dataSubPath }}"
|
||||||
resources:
|
resources:
|
||||||
requests:
|
requests:
|
||||||
cpu: {{ .Values.cpuPerPod }}
|
cpu: {{ .Values.cpuPerPod }}
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: Namespace
|
kind: Namespace
|
||||||
metadata:
|
metadata:
|
||||||
name: bigdl-qlora-finetuning
|
name: ipex-llm-lora-finetuning
|
||||||
|
|
@ -1,8 +1,8 @@
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: PersistentVolume
|
kind: PersistentVolume
|
||||||
metadata:
|
metadata:
|
||||||
name: nfs-pv-bigdl-lora-finetuning
|
name: nfs-pv-ipex-llm-lora-finetuning
|
||||||
namespace: bigdl-lora-finetuning
|
namespace: ipex-llm-lora-finetuning
|
||||||
spec:
|
spec:
|
||||||
capacity:
|
capacity:
|
||||||
storage: 15Gi
|
storage: 15Gi
|
||||||
|
|
|
||||||
|
|
@ -2,7 +2,7 @@ kind: PersistentVolumeClaim
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
metadata:
|
metadata:
|
||||||
name: nfs-pvc
|
name: nfs-pvc
|
||||||
namespace: bigdl-lora-finetuning
|
namespace: ipex-llm-lora-finetuning
|
||||||
spec:
|
spec:
|
||||||
accessModes:
|
accessModes:
|
||||||
- ReadWriteOnce
|
- ReadWriteOnce
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
imageName: intelanalytics/bigdl-llm-finetune-lora-cpu:2.5.0-SNAPSHOT
|
imageName: intelanalytics/ipex-llm-finetune-lora-cpu:2.5.0-SNAPSHOT
|
||||||
trainerNum: 8
|
trainerNum: 8
|
||||||
microBatchSize: 8
|
microBatchSize: 8
|
||||||
nfsServerIp: your_nfs_server_ip
|
nfsServerIp: your_nfs_server_ip
|
||||||
|
|
|
||||||
|
|
@ -18,7 +18,7 @@ ENV TRANSFORMERS_COMMIT_ID=95fe0f5
|
||||||
COPY --from=key-getter /root/intel-oneapi-archive-keyring.gpg /usr/share/keyrings/intel-oneapi-archive-keyring.gpg
|
COPY --from=key-getter /root/intel-oneapi-archive-keyring.gpg /usr/share/keyrings/intel-oneapi-archive-keyring.gpg
|
||||||
RUN echo "deb [signed-by=/usr/share/keyrings/intel-oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main " > /etc/apt/sources.list.d/oneAPI.list
|
RUN echo "deb [signed-by=/usr/share/keyrings/intel-oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main " > /etc/apt/sources.list.d/oneAPI.list
|
||||||
|
|
||||||
RUN mkdir -p /bigdl/data && mkdir -p /bigdl/model && \
|
RUN mkdir -p /ipex_llm/data && mkdir -p /ipex_llm/model && \
|
||||||
# install pytorch 2.1.0
|
# install pytorch 2.1.0
|
||||||
apt-get update && \
|
apt-get update && \
|
||||||
apt-get install -y --no-install-recommends python3-pip python3.9-dev python3-wheel python3.9-distutils git software-properties-common && \
|
apt-get install -y --no-install-recommends python3-pip python3.9-dev python3-wheel python3.9-distutils git software-properties-common && \
|
||||||
|
|
@ -27,8 +27,8 @@ RUN mkdir -p /bigdl/data && mkdir -p /bigdl/model && \
|
||||||
pip3 install --upgrade pip && \
|
pip3 install --upgrade pip && \
|
||||||
export PIP_DEFAULT_TIMEOUT=100 && \
|
export PIP_DEFAULT_TIMEOUT=100 && \
|
||||||
pip install --upgrade torch==2.1.0 && \
|
pip install --upgrade torch==2.1.0 && \
|
||||||
# install CPU bigdl-llm
|
# install CPU ipex-llm
|
||||||
pip3 install --pre --upgrade bigdl-llm[all] && \
|
pip3 install --pre --upgrade ipex-llm[all] && \
|
||||||
# install ipex and oneccl
|
# install ipex and oneccl
|
||||||
pip install https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/cpu/intel_extension_for_pytorch-2.1.0%2Bcpu-cp39-cp39-linux_x86_64.whl && \
|
pip install https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/cpu/intel_extension_for_pytorch-2.1.0%2Bcpu-cp39-cp39-linux_x86_64.whl && \
|
||||||
pip install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable && \
|
pip install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable && \
|
||||||
|
|
@ -41,16 +41,16 @@ RUN mkdir -p /bigdl/data && mkdir -p /bigdl/model && \
|
||||||
apt-get update && apt-get install -y curl wget gpg gpg-agent software-properties-common libunwind8-dev && \
|
apt-get update && apt-get install -y curl wget gpg gpg-agent software-properties-common libunwind8-dev && \
|
||||||
# get qlora example code
|
# get qlora example code
|
||||||
ln -s /usr/bin/python3 /usr/bin/python && \
|
ln -s /usr/bin/python3 /usr/bin/python && \
|
||||||
cd /bigdl && \
|
cd /ipex_llm && \
|
||||||
git clone https://github.com/intel-analytics/BigDL.git && \
|
git clone https://github.com/intel-analytics/IPEX-LLM.git && \
|
||||||
mv BigDL/python/llm/example/CPU/QLoRA-FineTuning/* . && \
|
mv IPEX-LLM/python/llm/example/CPU/QLoRA-FineTuning/* . && \
|
||||||
mkdir -p /GPU/LLM-Finetuning && \
|
mkdir -p /GPU/LLM-Finetuning && \
|
||||||
mv BigDL/python/llm/example/GPU/LLM-Finetuning/common /GPU/LLM-Finetuning/common && \
|
mv IPEX-LLM/python/llm/example/GPU/LLM-Finetuning/common /GPU/LLM-Finetuning/common && \
|
||||||
rm -r BigDL && \
|
rm -r IPEX-LLM && \
|
||||||
chown -R mpiuser /bigdl
|
chown -R mpiuser /ipex_llm
|
||||||
|
|
||||||
# for standalone
|
# for standalone
|
||||||
COPY ./start-qlora-finetuning-on-cpu.sh /bigdl/start-qlora-finetuning-on-cpu.sh
|
COPY ./start-qlora-finetuning-on-cpu.sh /ipex_llm/start-qlora-finetuning-on-cpu.sh
|
||||||
|
|
||||||
USER mpiuser
|
USER mpiuser
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -19,7 +19,7 @@ ENV TRANSFORMERS_COMMIT_ID=95fe0f5
|
||||||
COPY --from=key-getter /root/intel-oneapi-archive-keyring.gpg /usr/share/keyrings/intel-oneapi-archive-keyring.gpg
|
COPY --from=key-getter /root/intel-oneapi-archive-keyring.gpg /usr/share/keyrings/intel-oneapi-archive-keyring.gpg
|
||||||
RUN echo "deb [signed-by=/usr/share/keyrings/intel-oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main " > /etc/apt/sources.list.d/oneAPI.list
|
RUN echo "deb [signed-by=/usr/share/keyrings/intel-oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main " > /etc/apt/sources.list.d/oneAPI.list
|
||||||
|
|
||||||
RUN mkdir -p /bigdl/data && mkdir -p /bigdl/model && \
|
RUN mkdir -p /ipex_llm/data && mkdir -p /ipex_llm/model && \
|
||||||
apt-get update && \
|
apt-get update && \
|
||||||
apt install -y --no-install-recommends openssh-server openssh-client libcap2-bin gnupg2 ca-certificates \
|
apt install -y --no-install-recommends openssh-server openssh-client libcap2-bin gnupg2 ca-certificates \
|
||||||
python3-pip python3.9-dev python3-wheel python3.9-distutils git software-properties-common && \
|
python3-pip python3.9-dev python3-wheel python3.9-distutils git software-properties-common && \
|
||||||
|
|
@ -40,8 +40,8 @@ RUN mkdir -p /bigdl/data && mkdir -p /bigdl/model && \
|
||||||
pip3 install --upgrade pip && \
|
pip3 install --upgrade pip && \
|
||||||
export PIP_DEFAULT_TIMEOUT=100 && \
|
export PIP_DEFAULT_TIMEOUT=100 && \
|
||||||
pip install --upgrade torch==2.1.0 --index-url https://download.pytorch.org/whl/cpu && \
|
pip install --upgrade torch==2.1.0 --index-url https://download.pytorch.org/whl/cpu && \
|
||||||
# install CPU bigdl-llm
|
# install CPU ipex-llm
|
||||||
pip3 install --pre --upgrade bigdl-llm[all] && \
|
pip3 install --pre --upgrade ipex-llm[all] && \
|
||||||
# install ipex and oneccl
|
# install ipex and oneccl
|
||||||
pip install intel_extension_for_pytorch==2.0.100 && \
|
pip install intel_extension_for_pytorch==2.0.100 && \
|
||||||
pip install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable && \
|
pip install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable && \
|
||||||
|
|
@ -59,14 +59,14 @@ RUN mkdir -p /bigdl/data && mkdir -p /bigdl/model && \
|
||||||
rm -rf /var/lib/apt/lists/* && \
|
rm -rf /var/lib/apt/lists/* && \
|
||||||
# get qlora example code
|
# get qlora example code
|
||||||
ln -s /usr/bin/python3 /usr/bin/python && \
|
ln -s /usr/bin/python3 /usr/bin/python && \
|
||||||
cd /bigdl && \
|
cd /ipex_llm && \
|
||||||
git clone https://github.com/intel-analytics/BigDL.git && \
|
git clone https://github.com/intel-analytics/IPEX-LLM.git && \
|
||||||
mv BigDL/python/llm/example/CPU/QLoRA-FineTuning/* . && \
|
mv IPEX-LLM/python/llm/example/CPU/QLoRA-FineTuning/* . && \
|
||||||
rm -r BigDL && \
|
rm -r IPEX-LLM && \
|
||||||
chown -R mpiuser /bigdl
|
chown -R mpiuser /ipex_llm
|
||||||
|
|
||||||
# for k8s
|
# for k8s
|
||||||
COPY ./bigdl-qlora-finetuing-entrypoint.sh /bigdl/bigdl-qlora-finetuing-entrypoint.sh
|
COPY ./ipex-llm-qlora-finetuing-entrypoint.sh /ipex_llm/ipex-llm-qlora-finetuing-entrypoint.sh
|
||||||
|
|
||||||
USER mpiuser
|
USER mpiuser
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
## Fine-tune LLM with BigDL LLM Container
|
## Fine-tune LLM with IPEX LLM Container
|
||||||
|
|
||||||
The following shows how to fine-tune LLM with Quantization (QLoRA built on BigDL-LLM 4bit optimizations) in a docker environment, which is accelerated by Intel CPU.
|
The following shows how to fine-tune LLM with Quantization (QLoRA built on IPEX-LLM 4bit optimizations) in a docker environment, which is accelerated by Intel CPU.
|
||||||
|
|
||||||
### 1. Prepare Docker Image
|
### 1. Prepare Docker Image
|
||||||
|
|
||||||
|
|
@ -8,10 +8,10 @@ You can download directly from Dockerhub like:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# For standalone
|
# For standalone
|
||||||
docker pull intelanalytics/bigdl-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
docker pull intelanalytics/ipex-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
||||||
|
|
||||||
# For k8s
|
# For k8s
|
||||||
docker pull intelanalytics/bigdl-llm-finetune-qlora-cpu-k8s:2.5.0-SNAPSHOT
|
docker pull intelanalytics/ipex-llm-finetune-qlora-cpu-k8s:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
Or build the image from source:
|
Or build the image from source:
|
||||||
|
|
@ -24,7 +24,7 @@ export HTTPS_PROXY=your_https_proxy
|
||||||
docker build \
|
docker build \
|
||||||
--build-arg http_proxy=${HTTP_PROXY} \
|
--build-arg http_proxy=${HTTP_PROXY} \
|
||||||
--build-arg https_proxy=${HTTPS_PROXY} \
|
--build-arg https_proxy=${HTTPS_PROXY} \
|
||||||
-t intelanalytics/bigdl-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT \
|
-t intelanalytics/ipex-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT \
|
||||||
-f ./Dockerfile .
|
-f ./Dockerfile .
|
||||||
|
|
||||||
# For k8s
|
# For k8s
|
||||||
|
|
@ -34,7 +34,7 @@ export HTTPS_PROXY=your_https_proxy
|
||||||
docker build \
|
docker build \
|
||||||
--build-arg http_proxy=${HTTP_PROXY} \
|
--build-arg http_proxy=${HTTP_PROXY} \
|
||||||
--build-arg https_proxy=${HTTPS_PROXY} \
|
--build-arg https_proxy=${HTTPS_PROXY} \
|
||||||
-t intelanalytics/bigdl-llm-finetune-qlora-cpu-k8s:2.5.0-SNAPSHOT \
|
-t intelanalytics/ipex-llm-finetune-qlora-cpu-k8s:2.5.0-SNAPSHOT \
|
||||||
-f ./Dockerfile.k8s .
|
-f ./Dockerfile.k8s .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -50,12 +50,12 @@ export HTTPS_PROXY=your_https_proxy
|
||||||
|
|
||||||
docker run -itd \
|
docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
--name=bigdl-llm-fintune-qlora-cpu \
|
--name=ipex-llm-fintune-qlora-cpu \
|
||||||
-e http_proxy=${HTTP_PROXY} \
|
-e http_proxy=${HTTP_PROXY} \
|
||||||
-e https_proxy=${HTTPS_PROXY} \
|
-e https_proxy=${HTTPS_PROXY} \
|
||||||
-v $BASE_MODE_PATH:/bigdl/model \
|
-v $BASE_MODE_PATH:/ipex_llm/model \
|
||||||
-v $DATA_PATH:/bigdl/data/alpaca-cleaned \
|
-v $DATA_PATH:/ipex_llm/data/alpaca-cleaned \
|
||||||
intelanalytics/bigdl-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
intelanalytics/ipex-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
The download and mount of base model and data to a docker container demonstrates a standard fine-tuning process. You can skip this step for a quick start, and in this way, the fine-tuning codes will automatically download the needed files:
|
The download and mount of base model and data to a docker container demonstrates a standard fine-tuning process. You can skip this step for a quick start, and in this way, the fine-tuning codes will automatically download the needed files:
|
||||||
|
|
@ -66,10 +66,10 @@ export HTTPS_PROXY=your_https_proxy
|
||||||
|
|
||||||
docker run -itd \
|
docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
--name=bigdl-llm-fintune-qlora-cpu \
|
--name=ipex-llm-fintune-qlora-cpu \
|
||||||
-e http_proxy=${HTTP_PROXY} \
|
-e http_proxy=${HTTP_PROXY} \
|
||||||
-e https_proxy=${HTTPS_PROXY} \
|
-e https_proxy=${HTTPS_PROXY} \
|
||||||
intelanalytics/bigdl-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
intelanalytics/ipex-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
However, we do recommend you to handle them manually, because the automatical download can be blocked by Internet access and Huggingface authentication etc. according to different environment, and the manual method allows you to fine-tune in a custom way (with different base model and dataset).
|
However, we do recommend you to handle them manually, because the automatical download can be blocked by Internet access and Huggingface authentication etc. according to different environment, and the manual method allows you to fine-tune in a custom way (with different base model and dataset).
|
||||||
|
|
@ -79,14 +79,14 @@ However, we do recommend you to handle them manually, because the automatical do
|
||||||
Enter the running container:
|
Enter the running container:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker exec -it bigdl-llm-fintune-qlora-cpu bash
|
docker exec -it ipex-llm-fintune-qlora-cpu bash
|
||||||
```
|
```
|
||||||
|
|
||||||
Then, start QLoRA fine-tuning:
|
Then, start QLoRA fine-tuning:
|
||||||
If the machine memory is not enough, you can try to set `use_gradient_checkpointing=True`.
|
If the machine memory is not enough, you can try to set `use_gradient_checkpointing=True`.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
cd /bigdl
|
cd /ipex_llm
|
||||||
bash start-qlora-finetuning-on-cpu.sh
|
bash start-qlora-finetuning-on-cpu.sh
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -120,19 +120,17 @@ Then you can use `./outputs/checkpoint-200-merged` as a normal huggingface trans
|
||||||
|
|
||||||
### 4. Start Multi-Porcess Fine-Tuning in One Docker
|
### 4. Start Multi-Porcess Fine-Tuning in One Docker
|
||||||
|
|
||||||
<img src="https://github.com/Uxito-Ada/BigDL/assets/60865256/f25c43b3-2b24-4476-a0fe-804c0ef3c36c" height="240px"><br>
|
Multi-process parallelism enables higher performance for QLoRA fine-tuning, e.g. Xeon server series with multi-processor-socket architecture is suitable to run one instance on each QLoRA. This can be done by simply invoke >=2 OneCCL instances in IPEX-LLM QLoRA docker:
|
||||||
|
|
||||||
Multi-process parallelism enables higher performance for QLoRA fine-tuning, e.g. Xeon server series with multi-processor-socket architecture is suitable to run one instance on each QLoRA. This can be done by simply invoke >=2 OneCCL instances in BigDL QLoRA docker:
|
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker run -itd \
|
docker run -itd \
|
||||||
--name=bigdl-llm-fintune-qlora-cpu \
|
--name=ipex-llm-fintune-qlora-cpu \
|
||||||
--cpuset-cpus="your_expected_range_of_cpu_numbers" \
|
--cpuset-cpus="your_expected_range_of_cpu_numbers" \
|
||||||
-e STANDALONE_DOCKER=TRUE \
|
-e STANDALONE_DOCKER=TRUE \
|
||||||
-e WORKER_COUNT_DOCKER=your_worker_count \
|
-e WORKER_COUNT_DOCKER=your_worker_count \
|
||||||
-v your_downloaded_base_model_path:/bigdl/model \
|
-v your_downloaded_base_model_path:/ipex_llm/model \
|
||||||
-v your_downloaded_data_path:/bigdl/data/alpaca_data_cleaned_archive.json \
|
-v your_downloaded_data_path:/ipex_llm/data/alpaca_data_cleaned_archive.json \
|
||||||
intelanalytics/bigdl-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
intelanalytics/ipex-llm-finetune-qlora-cpu-standalone:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
Note that `STANDALONE_DOCKER` is set to **TRUE** here.
|
Note that `STANDALONE_DOCKER` is set to **TRUE** here.
|
||||||
|
|
@ -145,4 +143,4 @@ bash start-qlora-finetuning-on-cpu.sh
|
||||||
|
|
||||||
### 5. Start Distributed Fine-Tuning on Kubernetes
|
### 5. Start Distributed Fine-Tuning on Kubernetes
|
||||||
|
|
||||||
Besides multi-process mode, you can also run QLoRA on a kubernetes cluster. please refer [here](https://github.com/intel-analytics/BigDL/blob/main/docker/llm/finetune/qlora/cpu/kubernetes/README.md).
|
Besides multi-process mode, you can also run QLoRA on a kubernetes cluster. please refer [here](https://github.com/intel-analytics/IPEX-LLM/blob/main/docker/llm/finetune/qlora/cpu/kubernetes/README.md).
|
||||||
|
|
|
||||||
|
|
@ -3,8 +3,8 @@
|
||||||
set -x
|
set -x
|
||||||
source /opt/intel/oneapi/setvars.sh
|
source /opt/intel/oneapi/setvars.sh
|
||||||
export CCL_WORKER_COUNT=$WORLD_SIZE
|
export CCL_WORKER_COUNT=$WORLD_SIZE
|
||||||
source bigdl-llm-init -t
|
source ipex-llm-init -t
|
||||||
cd /bigdl/alpaca-qlora
|
cd /ipex_llm/alpaca-qlora
|
||||||
if [ "$WORKER_ROLE" = "launcher" ]
|
if [ "$WORKER_ROLE" = "launcher" ]
|
||||||
then
|
then
|
||||||
sed "s/:1/ /g" /etc/mpi/hostfile > /home/mpiuser/hostfile
|
sed "s/:1/ /g" /etc/mpi/hostfile > /home/mpiuser/hostfile
|
||||||
|
|
@ -24,9 +24,9 @@ then
|
||||||
-genv KMP_AFFINITY="granularity=fine,none" \
|
-genv KMP_AFFINITY="granularity=fine,none" \
|
||||||
-genv KMP_BLOCKTIME=1 \
|
-genv KMP_BLOCKTIME=1 \
|
||||||
-genv TF_ENABLE_ONEDNN_OPTS=1 \
|
-genv TF_ENABLE_ONEDNN_OPTS=1 \
|
||||||
python /bigdl/alpaca-qlora/alpaca_qlora_finetuning_cpu.py \
|
python /ipex_llm/alpaca-qlora/alpaca_qlora_finetuning_cpu.py \
|
||||||
--base_model '/bigdl/model' \
|
--base_model '/ipex_llm/model' \
|
||||||
--data_path "/bigdl/data" \
|
--data_path "/ipex_llm/data" \
|
||||||
--output_dir "/home/mpiuser/finetuned_model" \
|
--output_dir "/home/mpiuser/finetuned_model" \
|
||||||
--batch_size 128 \
|
--batch_size 128 \
|
||||||
--micro_batch_size $MICRO_BATCH_SIZE \
|
--micro_batch_size $MICRO_BATCH_SIZE \
|
||||||
|
|
@ -1,10 +1,10 @@
|
||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
set -x
|
set -x
|
||||||
cd /bigdl
|
cd /ipex_llm
|
||||||
export USE_XETLA=OFF
|
export USE_XETLA=OFF
|
||||||
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
|
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
|
||||||
source /opt/intel/oneapi/setvars.sh
|
source /opt/intel/oneapi/setvars.sh
|
||||||
source bigdl-llm-init -t
|
source ipex-llm-init -t
|
||||||
|
|
||||||
if [ -d "./model" ];
|
if [ -d "./model" ];
|
||||||
then
|
then
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,6 @@
|
||||||
apiVersion: v2
|
apiVersion: v2
|
||||||
name: bigdl-fintune-service
|
name: ipex-fintune-service
|
||||||
description: A Helm chart for BigDL Finetune Service on Kubernetes
|
description: A Helm chart for IPEX-LLM Finetune Service on Kubernetes
|
||||||
type: application
|
type: application
|
||||||
version: 1.1.27
|
version: 1.1.27
|
||||||
appVersion: "1.16.0"
|
appVersion: "1.16.0"
|
||||||
|
|
|
||||||
|
|
@ -1,12 +1,10 @@
|
||||||
## Run Distributed QLoRA Fine-Tuning on Kubernetes with OneCCL
|
## Run Distributed QLoRA Fine-Tuning on Kubernetes with OneCCL
|
||||||
|
|
||||||

|
IPEX-LLM here provides a CPU optimization to accelerate the QLoRA finetuning of Llama2-7b, in the power of mixed-precision and distributed training. Detailedly, [Intel OneCCL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/oneccl.html), an available Hugging Face backend, is able to speed up the Pytorch computation with BF16 datatype on CPUs, as well as parallel processing on Kubernetes enabled by [Intel MPI](https://www.intel.com/content/www/us/en/developer/tools/oneapi/mpi-library.html). Moreover, advanaced quantization of IPEX-LLM has been applied to improve memory utilization, which makes CPU large-scale fine-tuning possible with runtime NF4 model storage and BF16 computing types.
|
||||||
|
|
||||||
BigDL here provides a CPU optimization to accelerate the QLoRA finetuning of Llama2-7b, in the power of mixed-precision and distributed training. Detailedly, [Intel OneCCL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/oneccl.html), an available Hugging Face backend, is able to speed up the Pytorch computation with BF16 datatype on CPUs, as well as parallel processing on Kubernetes enabled by [Intel MPI](https://www.intel.com/content/www/us/en/developer/tools/oneapi/mpi-library.html). Moreover, advanaced quantization of BigDL-LLM has been applied to improve memory utilization, which makes CPU large-scale fine-tuning possible with runtime NF4 model storage and BF16 computing types.
|
|
||||||
|
|
||||||
The architecture is illustrated in the following:
|
The architecture is illustrated in the following:
|
||||||
|
|
||||||
As above, BigDL implements its MPI training with [Kubeflow MPI operator](https://github.com/kubeflow/mpi-operator/tree/master), which encapsulates the deployment as MPIJob CRD, and assists users to handle the construction of a MPI worker cluster on Kubernetes, such as public key distribution, SSH connection, and log collection.
|
As above, IPEX-LLM implements its MPI training with [Kubeflow MPI operator](https://github.com/kubeflow/mpi-operator/tree/master), which encapsulates the deployment as MPIJob CRD, and assists users to handle the construction of a MPI worker cluster on Kubernetes, such as public key distribution, SSH connection, and log collection.
|
||||||
|
|
||||||
Now, let's go to deploy a QLoRA finetuning to create a new LLM from Llama2-7b.
|
Now, let's go to deploy a QLoRA finetuning to create a new LLM from Llama2-7b.
|
||||||
|
|
||||||
|
|
@ -18,7 +16,7 @@ Follow [here](https://github.com/kubeflow/mpi-operator/tree/master#installation)
|
||||||
|
|
||||||
### 2. Download Image, Base Model and Finetuning Data
|
### 2. Download Image, Base Model and Finetuning Data
|
||||||
|
|
||||||
Follow [here](https://github.com/intel-analytics/BigDL/tree/main/docker/llm/finetune/qlora/cpu/docker#1-prepare-docker-image) to prepare BigDL QLoRA Finetuning image in your cluster.
|
Follow [here](https://github.com/intel-analytics/IPEX-LLM/tree/main/docker/llm/finetune/qlora/cpu/docker#1-prepare-docker-image) to prepare IPEX-LLM QLoRA Finetuning image in your cluster.
|
||||||
|
|
||||||
As finetuning is from a base model, first download [Llama2-7b model from the public download site of Hugging Face](https://huggingface.co/meta-llama/Llama-2-7b). Then, download [cleaned alpaca data](https://raw.githubusercontent.com/tloen/alpaca-lora/main/alpaca_data_cleaned_archive.json), which contains all kinds of general knowledge and has already been cleaned. Next, move the downloaded files to a shared directory on your NFS server.
|
As finetuning is from a base model, first download [Llama2-7b model from the public download site of Hugging Face](https://huggingface.co/meta-llama/Llama-2-7b). Then, download [cleaned alpaca data](https://raw.githubusercontent.com/tloen/alpaca-lora/main/alpaca_data_cleaned_archive.json), which contains all kinds of general knowledge and has already been cleaned. Next, move the downloaded files to a shared directory on your NFS server.
|
||||||
|
|
||||||
|
|
@ -32,12 +30,12 @@ After preparing parameters in `./kubernetes/values.yaml`, submit the job as befl
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
cd ./kubernetes
|
cd ./kubernetes
|
||||||
helm install bigdl-qlora-finetuning .
|
helm install ipex-llm-qlora-finetuning .
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4. Check Deployment
|
### 4. Check Deployment
|
||||||
```bash
|
```bash
|
||||||
kubectl get all -n bigdl-qlora-finetuning # you will see launcher and worker pods running
|
kubectl get all -n ipex-llm-qlora-finetuning # you will see launcher and worker pods running
|
||||||
```
|
```
|
||||||
|
|
||||||
### 5. Check Finetuning Process
|
### 5. Check Finetuning Process
|
||||||
|
|
@ -45,8 +43,8 @@ kubectl get all -n bigdl-qlora-finetuning # you will see launcher and worker pod
|
||||||
After deploying successfully, you can find a launcher pod, and then go inside this pod and check the logs collected from all workers.
|
After deploying successfully, you can find a launcher pod, and then go inside this pod and check the logs collected from all workers.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
kubectl get all -n bigdl-qlora-finetuning # you will see a launcher pod
|
kubectl get all -n ipex-llm-qlora-finetuning # you will see a launcher pod
|
||||||
kubectl exec -it <launcher_pod_name> bash -n bigdl-qlora-finetuning # enter launcher pod
|
kubectl exec -it <launcher_pod_name> bash -n ipex-llm-qlora-finetuning # enter launcher pod
|
||||||
cat launcher.log # display logs collected from other workers
|
cat launcher.log # display logs collected from other workers
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: Namespace
|
kind: Namespace
|
||||||
metadata:
|
metadata:
|
||||||
name: bigdl-lora-finetuning
|
name: ipex-llm-qlora-finetuning
|
||||||
|
|
@ -1,8 +1,8 @@
|
||||||
apiVersion: kubeflow.org/v2beta1
|
apiVersion: kubeflow.org/v2beta1
|
||||||
kind: MPIJob
|
kind: MPIJob
|
||||||
metadata:
|
metadata:
|
||||||
name: bigdl-qlora-finetuning-job
|
name: ipex-llm-qlora-finetuning-job
|
||||||
namespace: bigdl-qlora-finetuning
|
namespace: ipex-llm-qlora-finetuning
|
||||||
spec:
|
spec:
|
||||||
slotsPerWorker: 1
|
slotsPerWorker: 1
|
||||||
runPolicy:
|
runPolicy:
|
||||||
|
|
@ -20,10 +20,10 @@ spec:
|
||||||
claimName: nfs-pvc
|
claimName: nfs-pvc
|
||||||
containers:
|
containers:
|
||||||
- image: {{ .Values.imageName }}
|
- image: {{ .Values.imageName }}
|
||||||
name: bigdl-qlora-finetuning-launcher
|
name: ipex-llm-qlora-finetuning-launcher
|
||||||
securityContext:
|
securityContext:
|
||||||
runAsUser: 1000
|
runAsUser: 1000
|
||||||
command: ['sh' , '-c', 'bash /bigdl/bigdl-qlora-finetuing-entrypoint.sh']
|
command: ['sh' , '-c', 'bash /ipex_llm/ipex-llm-qlora-finetuing-entrypoint.sh']
|
||||||
env:
|
env:
|
||||||
- name: WORKER_ROLE
|
- name: WORKER_ROLE
|
||||||
value: "launcher"
|
value: "launcher"
|
||||||
|
|
@ -34,7 +34,7 @@ spec:
|
||||||
- name: MASTER_PORT
|
- name: MASTER_PORT
|
||||||
value: "42679"
|
value: "42679"
|
||||||
- name: MASTER_ADDR
|
- name: MASTER_ADDR
|
||||||
value: "bigdl-qlora-finetuning-job-worker-0.bigdl-qlora-finetuning-job-worker"
|
value: "ipex-llm-qlora-finetuning-job-worker-0.ipex-llm-qlora-finetuning-job-worker"
|
||||||
- name: DATA_SUB_PATH
|
- name: DATA_SUB_PATH
|
||||||
value: "{{ .Values.dataSubPath }}"
|
value: "{{ .Values.dataSubPath }}"
|
||||||
- name: ENABLE_GRADIENT_CHECKPOINT
|
- name: ENABLE_GRADIENT_CHECKPOINT
|
||||||
|
|
@ -52,10 +52,10 @@ spec:
|
||||||
volumeMounts:
|
volumeMounts:
|
||||||
- name: nfs-storage
|
- name: nfs-storage
|
||||||
subPath: {{ .Values.modelSubPath }}
|
subPath: {{ .Values.modelSubPath }}
|
||||||
mountPath: /bigdl/model
|
mountPath: /ipex_llm/model
|
||||||
- name: nfs-storage
|
- name: nfs-storage
|
||||||
subPath: {{ .Values.dataSubPath }}
|
subPath: {{ .Values.dataSubPath }}
|
||||||
mountPath: "/bigdl/data/{{ .Values.dataSubPath }}"
|
mountPath: "/ipex_llm/data/{{ .Values.dataSubPath }}"
|
||||||
Worker:
|
Worker:
|
||||||
replicas: {{ .Values.trainerNum }}
|
replicas: {{ .Values.trainerNum }}
|
||||||
template:
|
template:
|
||||||
|
|
@ -74,10 +74,10 @@ spec:
|
||||||
topologyKey: kubernetes.io/hostname
|
topologyKey: kubernetes.io/hostname
|
||||||
containers:
|
containers:
|
||||||
- image: {{ .Values.imageName }}
|
- image: {{ .Values.imageName }}
|
||||||
name: bigdl-qlora-finetuning-worker
|
name: ipex-llm-qlora-finetuning-worker
|
||||||
securityContext:
|
securityContext:
|
||||||
runAsUser: 1000
|
runAsUser: 1000
|
||||||
command: ['sh' , '-c', 'bash /bigdl/bigdl-qlora-finetuing-entrypoint.sh']
|
command: ['sh' , '-c', 'bash /ipex_llm/ipex-llm-qlora-finetuing-entrypoint.sh']
|
||||||
env:
|
env:
|
||||||
- name: WORKER_ROLE
|
- name: WORKER_ROLE
|
||||||
value: "trainer"
|
value: "trainer"
|
||||||
|
|
@ -88,7 +88,7 @@ spec:
|
||||||
- name: MASTER_PORT
|
- name: MASTER_PORT
|
||||||
value: "42679"
|
value: "42679"
|
||||||
- name: MASTER_ADDR
|
- name: MASTER_ADDR
|
||||||
value: "bigdl-qlora-finetuning-job-worker-0.bigdl-qlora-finetuning-job-worker"
|
value: "ipex-llm-qlora-finetuning-job-worker-0.ipex-llm-qlora-finetuning-job-worker"
|
||||||
- name: ENABLE_GRADIENT_CHECKPOINT
|
- name: ENABLE_GRADIENT_CHECKPOINT
|
||||||
value: "{{ .Values.enableGradientCheckpoint }}"
|
value: "{{ .Values.enableGradientCheckpoint }}"
|
||||||
- name: http_proxy
|
- name: http_proxy
|
||||||
|
|
@ -102,10 +102,10 @@ spec:
|
||||||
volumeMounts:
|
volumeMounts:
|
||||||
- name: nfs-storage
|
- name: nfs-storage
|
||||||
subPath: {{ .Values.modelSubPath }}
|
subPath: {{ .Values.modelSubPath }}
|
||||||
mountPath: /bigdl/model
|
mountPath: /ipex_llm/model
|
||||||
- name: nfs-storage
|
- name: nfs-storage
|
||||||
subPath: {{ .Values.dataSubPath }}
|
subPath: {{ .Values.dataSubPath }}
|
||||||
mountPath: "/bigdl/data/{{ .Values.dataSubPath }}"
|
mountPath: "/ipex_llm/data/{{ .Values.dataSubPath }}"
|
||||||
resources:
|
resources:
|
||||||
requests:
|
requests:
|
||||||
cpu: 48
|
cpu: 48
|
||||||
|
|
@ -1,8 +1,8 @@
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: PersistentVolume
|
kind: PersistentVolume
|
||||||
metadata:
|
metadata:
|
||||||
name: nfs-pv-bigdl-qlora-finetuning
|
name: nfs-pv-ipex-llm-qlora-finetuning
|
||||||
namespace: bigdl-qlora-finetuning
|
namespace: ipex-llm-qlora-finetuning
|
||||||
spec:
|
spec:
|
||||||
capacity:
|
capacity:
|
||||||
storage: 15Gi
|
storage: 15Gi
|
||||||
|
|
|
||||||
|
|
@ -2,7 +2,7 @@ kind: PersistentVolumeClaim
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
metadata:
|
metadata:
|
||||||
name: nfs-pvc
|
name: nfs-pvc
|
||||||
namespace: bigdl-qlora-finetuning
|
namespace: ipex-llm-qlora-finetuning
|
||||||
spec:
|
spec:
|
||||||
accessModes:
|
accessModes:
|
||||||
- ReadWriteOnce
|
- ReadWriteOnce
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
imageName: intelanalytics/bigdl-llm-finetune-qlora-cpu-k8s:2.5.0-SNAPSHOT
|
imageName: intelanalytics/ipex-llm-finetune-qlora-cpu-k8s:2.5.0-SNAPSHOT
|
||||||
trainerNum: 2
|
trainerNum: 2
|
||||||
microBatchSize: 8
|
microBatchSize: 8
|
||||||
enableGradientCheckpoint: false # true will save more memory but increase latency
|
enableGradientCheckpoint: false # true will save more memory but increase latency
|
||||||
|
|
|
||||||
|
|
@ -28,15 +28,15 @@ RUN curl -fsSL https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-P
|
||||||
ln -s /usr/bin/python3 /usr/bin/python && \
|
ln -s /usr/bin/python3 /usr/bin/python && \
|
||||||
apt-get install -y python3-pip python3.9-dev python3-wheel python3.9-distutils && \
|
apt-get install -y python3-pip python3.9-dev python3-wheel python3.9-distutils && \
|
||||||
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py && \
|
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py && \
|
||||||
# install XPU bigdl-llm
|
# install XPU ipex-llm
|
||||||
pip install --pre --upgrade bigdl-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpu && \
|
pip install --pre --upgrade ipex-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpu && \
|
||||||
# install huggingface dependencies
|
# install huggingface dependencies
|
||||||
pip install git+https://github.com/huggingface/transformers.git@${TRANSFORMERS_COMMIT_ID} && \
|
pip install git+https://github.com/huggingface/transformers.git@${TRANSFORMERS_COMMIT_ID} && \
|
||||||
pip install peft==0.5.0 datasets accelerate==0.23.0 && \
|
pip install peft==0.5.0 datasets accelerate==0.23.0 && \
|
||||||
pip install bitsandbytes scipy && \
|
pip install bitsandbytes scipy && \
|
||||||
git clone https://github.com/intel-analytics/BigDL.git && \
|
git clone https://github.com/intel-analytics/IPEX-LLM.git && \
|
||||||
mv BigDL/python/llm/example/GPU/LLM-Finetuning/common /common && \
|
mv IPEX-LLM/python/llm/example/GPU/LLM-Finetuning/common /common && \
|
||||||
rm -r BigDL && \
|
rm -r IPEX-LLM && \
|
||||||
wget https://raw.githubusercontent.com/intel-analytics/BigDL/main/python/llm/example/GPU/LLM-Finetuning/QLoRA/simple-example/qlora_finetuning.py
|
wget https://raw.githubusercontent.com/intel-analytics/IPEX-LLM/main/python/llm/example/GPU/LLM-Finetuning/QLoRA/simple-example/qlora_finetuning.py
|
||||||
|
|
||||||
COPY ./start-qlora-finetuning-on-xpu.sh /start-qlora-finetuning-on-xpu.sh
|
COPY ./start-qlora-finetuning-on-xpu.sh /start-qlora-finetuning-on-xpu.sh
|
||||||
|
|
|
||||||
|
|
@ -1,13 +1,13 @@
|
||||||
## Fine-tune LLM with BigDL LLM Container
|
## Fine-tune LLM with IPEX LLM Container
|
||||||
|
|
||||||
The following shows how to fine-tune LLM with Quantization (QLoRA built on BigDL-LLM 4bit optimizations) in a docker environment, which is accelerated by Intel XPU.
|
The following shows how to fine-tune LLM with Quantization (QLoRA built on IPEX-LLM 4bit optimizations) in a docker environment, which is accelerated by Intel XPU.
|
||||||
|
|
||||||
### 1. Prepare Docker Image
|
### 1. Prepare Docker Image
|
||||||
|
|
||||||
You can download directly from Dockerhub like:
|
You can download directly from Dockerhub like:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker pull intelanalytics/bigdl-llm-finetune-qlora-xpu:2.5.0-SNAPSHOT
|
docker pull intelanalytics/ipex-llm-finetune-qlora-xpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
Or build the image from source:
|
Or build the image from source:
|
||||||
|
|
@ -19,7 +19,7 @@ export HTTPS_PROXY=your_https_proxy
|
||||||
docker build \
|
docker build \
|
||||||
--build-arg http_proxy=${HTTP_PROXY} \
|
--build-arg http_proxy=${HTTP_PROXY} \
|
||||||
--build-arg https_proxy=${HTTPS_PROXY} \
|
--build-arg https_proxy=${HTTPS_PROXY} \
|
||||||
-t intelanalytics/bigdl-llm-finetune-qlora-xpu:2.5.0-SNAPSHOT \
|
-t intelanalytics/ipex-llm-finetune-qlora-xpu:2.5.0-SNAPSHOT \
|
||||||
-f ./Dockerfile .
|
-f ./Dockerfile .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -37,13 +37,13 @@ docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
--device=/dev/dri \
|
--device=/dev/dri \
|
||||||
--memory="32G" \
|
--memory="32G" \
|
||||||
--name=bigdl-llm-fintune-qlora-xpu \
|
--name=ipex-llm-fintune-qlora-xpu \
|
||||||
-e http_proxy=${HTTP_PROXY} \
|
-e http_proxy=${HTTP_PROXY} \
|
||||||
-e https_proxy=${HTTPS_PROXY} \
|
-e https_proxy=${HTTPS_PROXY} \
|
||||||
-v $BASE_MODE_PATH:/model \
|
-v $BASE_MODE_PATH:/model \
|
||||||
-v $DATA_PATH:/data/alpaca-cleaned \
|
-v $DATA_PATH:/data/alpaca-cleaned \
|
||||||
--shm-size="16g" \
|
--shm-size="16g" \
|
||||||
intelanalytics/bigdl-llm-fintune-qlora-xpu:2.5.0-SNAPSHOT
|
intelanalytics/ipex-llm-fintune-qlora-xpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
The download and mount of base model and data to a docker container demonstrates a standard fine-tuning process. You can skip this step for a quick start, and in this way, the fine-tuning codes will automatically download the needed files:
|
The download and mount of base model and data to a docker container demonstrates a standard fine-tuning process. You can skip this step for a quick start, and in this way, the fine-tuning codes will automatically download the needed files:
|
||||||
|
|
@ -56,11 +56,11 @@ docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
--device=/dev/dri \
|
--device=/dev/dri \
|
||||||
--memory="32G" \
|
--memory="32G" \
|
||||||
--name=bigdl-llm-fintune-qlora-xpu \
|
--name=ipex-llm-fintune-qlora-xpu \
|
||||||
-e http_proxy=${HTTP_PROXY} \
|
-e http_proxy=${HTTP_PROXY} \
|
||||||
-e https_proxy=${HTTPS_PROXY} \
|
-e https_proxy=${HTTPS_PROXY} \
|
||||||
--shm-size="16g" \
|
--shm-size="16g" \
|
||||||
intelanalytics/bigdl-llm-fintune-qlora-xpu:2.5.0-SNAPSHOT
|
intelanalytics/ipex-llm-fintune-qlora-xpu:2.5.0-SNAPSHOT
|
||||||
```
|
```
|
||||||
|
|
||||||
However, we do recommend you to handle them manually, because the automatical download can be blocked by Internet access and Huggingface authentication etc. according to different environment, and the manual method allows you to fine-tune in a custom way (with different base model and dataset).
|
However, we do recommend you to handle them manually, because the automatical download can be blocked by Internet access and Huggingface authentication etc. according to different environment, and the manual method allows you to fine-tune in a custom way (with different base model and dataset).
|
||||||
|
|
@ -70,7 +70,7 @@ However, we do recommend you to handle them manually, because the automatical do
|
||||||
Enter the running container:
|
Enter the running container:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker exec -it bigdl-llm-fintune-qlora-xpu bash
|
docker exec -it ipex-llm-fintune-qlora-xpu bash
|
||||||
```
|
```
|
||||||
|
|
||||||
Then, start QLoRA fine-tuning:
|
Then, start QLoRA fine-tuning:
|
||||||
|
|
|
||||||
|
|
@ -24,18 +24,18 @@ RUN env DEBIAN_FRONTEND=noninteractive apt-get update && \
|
||||||
rm get-pip.py && \
|
rm get-pip.py && \
|
||||||
pip install --upgrade requests argparse urllib3 && \
|
pip install --upgrade requests argparse urllib3 && \
|
||||||
pip3 install --no-cache-dir --upgrade torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu && \
|
pip3 install --no-cache-dir --upgrade torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu && \
|
||||||
pip install --pre --upgrade bigdl-llm[all] && \
|
pip install --pre --upgrade ipex-llm[all] && \
|
||||||
# Download bigdl-llm-tutorial
|
# Download ipex-llm-tutorial
|
||||||
cd /llm && \
|
cd /llm && \
|
||||||
pip install --upgrade jupyterlab && \
|
pip install --upgrade jupyterlab && \
|
||||||
git clone https://github.com/intel-analytics/bigdl-llm-tutorial && \
|
git clone https://github.com/intel-analytics/ipex-llm-tutorial && \
|
||||||
chmod +x /llm/start-notebook.sh && \
|
chmod +x /llm/start-notebook.sh && \
|
||||||
# Download all-in-one benchmark
|
# Download all-in-one benchmark
|
||||||
git clone https://github.com/intel-analytics/BigDL && \
|
git clone https://github.com/intel-analytics/IPEX-LLM && \
|
||||||
cp -r ./BigDL/python/llm/dev/benchmark/ ./benchmark && \
|
cp -r ./IPEX-LLM/python/llm/dev/benchmark/ ./benchmark && \
|
||||||
# Copy chat.py script
|
# Copy chat.py script
|
||||||
pip install --upgrade colorama && \
|
pip install --upgrade colorama && \
|
||||||
cp -r ./BigDL/python/llm/portable-zip/ ./portable-zip && \
|
cp -r ./IPEX-LLM/python/llm/portable-zip/ ./portable-zip && \
|
||||||
# Install all-in-one dependencies
|
# Install all-in-one dependencies
|
||||||
apt-get install -y numactl && \
|
apt-get install -y numactl && \
|
||||||
pip install --upgrade omegaconf && \
|
pip install --upgrade omegaconf && \
|
||||||
|
|
@ -46,13 +46,13 @@ RUN env DEBIAN_FRONTEND=noninteractive apt-get update && \
|
||||||
# Add Qwen support
|
# Add Qwen support
|
||||||
pip install --upgrade transformers_stream_generator einops && \
|
pip install --upgrade transformers_stream_generator einops && \
|
||||||
# Copy vLLM-Serving
|
# Copy vLLM-Serving
|
||||||
cp -r ./BigDL/python/llm/example/CPU/vLLM-Serving/ ./vLLM-Serving && \
|
cp -r ./IPEX-LLM/python/llm/example/CPU/vLLM-Serving/ ./vLLM-Serving && \
|
||||||
rm -rf ./BigDL && \
|
rm -rf ./IPEX-LLM && \
|
||||||
# Fix vllm service
|
# Fix vllm service
|
||||||
pip install pydantic==1.10.11 && \
|
pip install pydantic==1.10.11 && \
|
||||||
# Install bigdl-llm
|
# Install ipex-llm
|
||||||
cd /llm && \
|
cd /llm && \
|
||||||
pip install --pre --upgrade bigdl-llm[all] && \
|
pip install --pre --upgrade ipex-llm[all] && \
|
||||||
# Fix CVE-2024-22195
|
# Fix CVE-2024-22195
|
||||||
pip install Jinja2==3.1.3 && \
|
pip install Jinja2==3.1.3 && \
|
||||||
pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cpu && \
|
pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cpu && \
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
## Build/Use BigDL-LLM cpu image
|
## Build/Use IPEX-LLM cpu image
|
||||||
|
|
||||||
### Build Image
|
### Build Image
|
||||||
```bash
|
```bash
|
||||||
|
|
@ -6,7 +6,7 @@ docker build \
|
||||||
--build-arg http_proxy=.. \
|
--build-arg http_proxy=.. \
|
||||||
--build-arg https_proxy=.. \
|
--build-arg https_proxy=.. \
|
||||||
--build-arg no_proxy=.. \
|
--build-arg no_proxy=.. \
|
||||||
--rm --no-cache -t intelanalytics/bigdl-llm-cpu:2.5.0-SNAPSHOT .
|
--rm --no-cache -t intelanalytics/ipex-llm-cpu:2.5.0-SNAPSHOT .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -16,7 +16,7 @@ docker build \
|
||||||
An example could be:
|
An example could be:
|
||||||
```bash
|
```bash
|
||||||
#/bin/bash
|
#/bin/bash
|
||||||
export DOCKER_IMAGE=intelanalytics/bigdl-llm-cpu:2.5.0-SNAPSHOT
|
export DOCKER_IMAGE=intelanalytics/ipex-llm-cpu:2.5.0-SNAPSHOT
|
||||||
|
|
||||||
sudo docker run -itd \
|
sudo docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
|
|
@ -31,7 +31,7 @@ sudo docker run -itd \
|
||||||
|
|
||||||
After the container is booted, you could get into the container through `docker exec`.
|
After the container is booted, you could get into the container through `docker exec`.
|
||||||
|
|
||||||
To run inference using `BigDL-LLM` using cpu, you could refer to this [documentation](https://github.com/intel-analytics/BigDL/tree/main/python/llm#cpu-int4).
|
To run inference using `IPEX-LLM` using cpu, you could refer to this [documentation](https://github.com/intel-analytics/IPEX-LLM/tree/main/python/llm#cpu-int4).
|
||||||
|
|
||||||
### Use chat.py
|
### Use chat.py
|
||||||
|
|
||||||
|
|
@ -41,7 +41,7 @@ You can download models and bind the model directory from host machine to contai
|
||||||
|
|
||||||
Here is an example:
|
Here is an example:
|
||||||
```bash
|
```bash
|
||||||
export DOCKER_IMAGE=intelanalytics/bigdl-llm-cpu:2.5.0-SNAPSHOT
|
export DOCKER_IMAGE=intelanalytics/ipex-llm-cpu:2.5.0-SNAPSHOT
|
||||||
export MODEL_PATH=/home/llm/models
|
export MODEL_PATH=/home/llm/models
|
||||||
|
|
||||||
sudo docker run -itd \
|
sudo docker run -itd \
|
||||||
|
|
|
||||||
|
|
@ -1,7 +1,7 @@
|
||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
|
|
||||||
#
|
#
|
||||||
# Copyright 2016 The BigDL Authors.
|
# Copyright 2016 The IPEX-LLM Authors.
|
||||||
#
|
#
|
||||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
# you may not use this file except in compliance with the License.
|
# you may not use this file except in compliance with the License.
|
||||||
|
|
@ -29,4 +29,4 @@ while [ $# -gt 0 ]; do
|
||||||
shift
|
shift
|
||||||
done
|
done
|
||||||
|
|
||||||
jupyter-lab --notebook-dir=/llm/bigdl-llm-tutorial --ip=0.0.0.0 --port=$port --no-browser --NotebookApp.token=$token --allow-root
|
jupyter-lab --notebook-dir=/llm/ipex-llm-tutorial --ip=0.0.0.0 --port=$port --no-browser --NotebookApp.token=$token --allow-root
|
||||||
|
|
|
||||||
|
|
@ -20,7 +20,7 @@ RUN curl -fsSL https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-P
|
||||||
wget -qO - https://repositories.intel.com/graphics/intel-graphics.key | gpg --dearmor --output /usr/share/keyrings/intel-graphics.gpg && \
|
wget -qO - https://repositories.intel.com/graphics/intel-graphics.key | gpg --dearmor --output /usr/share/keyrings/intel-graphics.gpg && \
|
||||||
echo 'deb [arch=amd64,i386 signed-by=/usr/share/keyrings/intel-graphics.gpg] https://repositories.intel.com/graphics/ubuntu jammy arc' | tee /etc/apt/sources.list.d/intel.gpu.jammy.list && \
|
echo 'deb [arch=amd64,i386 signed-by=/usr/share/keyrings/intel-graphics.gpg] https://repositories.intel.com/graphics/ubuntu jammy arc' | tee /etc/apt/sources.list.d/intel.gpu.jammy.list && \
|
||||||
rm /etc/apt/sources.list.d/intel-graphics.list && \
|
rm /etc/apt/sources.list.d/intel-graphics.list && \
|
||||||
# Install PYTHON 3.9 and BigDL-LLM[xpu]
|
# Install PYTHON 3.9 and IPEX-LLM[xpu]
|
||||||
ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone && \
|
ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone && \
|
||||||
env DEBIAN_FRONTEND=noninteractive apt-get update && \
|
env DEBIAN_FRONTEND=noninteractive apt-get update && \
|
||||||
apt install software-properties-common libunwind8-dev vim less -y && \
|
apt install software-properties-common libunwind8-dev vim less -y && \
|
||||||
|
|
@ -35,7 +35,7 @@ RUN curl -fsSL https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-P
|
||||||
python3 get-pip.py && \
|
python3 get-pip.py && \
|
||||||
rm get-pip.py && \
|
rm get-pip.py && \
|
||||||
pip install --upgrade requests argparse urllib3 && \
|
pip install --upgrade requests argparse urllib3 && \
|
||||||
pip install --pre --upgrade bigdl-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpu && \
|
pip install --pre --upgrade ipex-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpu && \
|
||||||
# Fix Trivy CVE Issues
|
# Fix Trivy CVE Issues
|
||||||
pip install transformers==4.36.2 && \
|
pip install transformers==4.36.2 && \
|
||||||
pip install transformers_stream_generator einops tiktoken && \
|
pip install transformers_stream_generator einops tiktoken && \
|
||||||
|
|
@ -48,6 +48,6 @@ RUN curl -fsSL https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-P
|
||||||
pip install --upgrade fastapi && \
|
pip install --upgrade fastapi && \
|
||||||
pip install --upgrade "uvicorn[standard]" && \
|
pip install --upgrade "uvicorn[standard]" && \
|
||||||
# Download vLLM-Serving
|
# Download vLLM-Serving
|
||||||
git clone https://github.com/intel-analytics/BigDL && \
|
git clone https://github.com/intel-analytics/IPEX-LLM && \
|
||||||
cp -r ./BigDL/python/llm/example/GPU/vLLM-Serving/ ./vLLM-Serving && \
|
cp -r ./IPEX-LLM/python/llm/example/GPU/vLLM-Serving/ ./vLLM-Serving && \
|
||||||
rm -rf ./BigDL
|
rm -rf ./IPEX-LLM
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
## Build/Use BigDL-LLM xpu image
|
## Build/Use IPEX-LLM xpu image
|
||||||
|
|
||||||
### Build Image
|
### Build Image
|
||||||
```bash
|
```bash
|
||||||
|
|
@ -6,7 +6,7 @@ docker build \
|
||||||
--build-arg http_proxy=.. \
|
--build-arg http_proxy=.. \
|
||||||
--build-arg https_proxy=.. \
|
--build-arg https_proxy=.. \
|
||||||
--build-arg no_proxy=.. \
|
--build-arg no_proxy=.. \
|
||||||
--rm --no-cache -t intelanalytics/bigdl-llm-xpu:2.5.0-SNAPSHOT .
|
--rm --no-cache -t intelanalytics/ipex-llm-xpu:2.5.0-SNAPSHOT .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -17,7 +17,7 @@ To map the `xpu` into the container, you need to specify `--device=/dev/dri` whe
|
||||||
An example could be:
|
An example could be:
|
||||||
```bash
|
```bash
|
||||||
#/bin/bash
|
#/bin/bash
|
||||||
export DOCKER_IMAGE=intelanalytics/bigdl-llm-xpu:2.5.0-SNAPSHOT
|
export DOCKER_IMAGE=intelanalytics/ipex-llm-xpu:2.5.0-SNAPSHOT
|
||||||
|
|
||||||
sudo docker run -itd \
|
sudo docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
|
|
@ -42,4 +42,4 @@ root@arda-arc12:/# sycl-ls
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
To run inference using `BigDL-LLM` using xpu, you could refer to this [documentation](https://github.com/intel-analytics/BigDL/tree/main/python/llm/example/GPU).
|
To run inference using `IPEX-LLM` using xpu, you could refer to this [documentation](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/GPU).
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
FROM intelanalytics/bigdl-llm-cpu:2.5.0-SNAPSHOT
|
FROM intelanalytics/ipex-llm-cpu:2.5.0-SNAPSHOT
|
||||||
|
|
||||||
ARG http_proxy
|
ARG http_proxy
|
||||||
ARG https_proxy
|
ARG https_proxy
|
||||||
|
|
@ -12,7 +12,7 @@ COPY ./model_adapter.py.patch /llm/model_adapter.py.patch
|
||||||
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /sbin/tini
|
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /sbin/tini
|
||||||
# Install Serving Dependencies
|
# Install Serving Dependencies
|
||||||
RUN cd /llm && \
|
RUN cd /llm && \
|
||||||
pip install --pre --upgrade bigdl-llm[serving] && \
|
pip install --pre --upgrade ipex-llm[serving] && \
|
||||||
# Fix Trivy CVE Issues
|
# Fix Trivy CVE Issues
|
||||||
pip install Jinja2==3.1.3 transformers==4.36.2 gradio==4.19.2 cryptography==42.0.4 && \
|
pip install Jinja2==3.1.3 transformers==4.36.2 gradio==4.19.2 cryptography==42.0.4 && \
|
||||||
# Fix Qwen model adpater in fastchat
|
# Fix Qwen model adpater in fastchat
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
## Build/Use BigDL-LLM-serving cpu image
|
## Build/Use IPEX-LLM-serving cpu image
|
||||||
|
|
||||||
### Build Image
|
### Build Image
|
||||||
```bash
|
```bash
|
||||||
|
|
@ -6,7 +6,7 @@ docker build \
|
||||||
--build-arg http_proxy=.. \
|
--build-arg http_proxy=.. \
|
||||||
--build-arg https_proxy=.. \
|
--build-arg https_proxy=.. \
|
||||||
--build-arg no_proxy=.. \
|
--build-arg no_proxy=.. \
|
||||||
--rm --no-cache -t intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT .
|
--rm --no-cache -t intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT .
|
||||||
```
|
```
|
||||||
|
|
||||||
### Use the image for doing cpu serving
|
### Use the image for doing cpu serving
|
||||||
|
|
@ -16,7 +16,7 @@ You could use the following bash script to start the container. Please be noted
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
#/bin/bash
|
#/bin/bash
|
||||||
export DOCKER_IMAGE=intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT
|
export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT
|
||||||
|
|
||||||
sudo docker run -itd \
|
sudo docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
|
|
@ -30,13 +30,13 @@ sudo docker run -itd \
|
||||||
|
|
||||||
After the container is booted, you could get into the container through `docker exec`.
|
After the container is booted, you could get into the container through `docker exec`.
|
||||||
|
|
||||||
To run model-serving using `BigDL-LLM` as backend, you can refer to this [document](https://github.com/intel-analytics/BigDL/tree/main/python/llm/src/bigdl/llm/serving).
|
To run model-serving using `IPEX-LLM` as backend, you can refer to this [document](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/src/ipex/llm/serving).
|
||||||
Also you can set environment variables and start arguments while running a container to get serving started initially. You may need to boot several containers to support. One controller container and at least one worker container are needed. The api server address(host and port) and controller address are set in controller container, and you need to set the same controller address as above, model path on your machine and worker address in worker container.
|
Also you can set environment variables and start arguments while running a container to get serving started initially. You may need to boot several containers to support. One controller container and at least one worker container are needed. The api server address(host and port) and controller address are set in controller container, and you need to set the same controller address as above, model path on your machine and worker address in worker container.
|
||||||
|
|
||||||
To start a controller container:
|
To start a controller container:
|
||||||
```bash
|
```bash
|
||||||
#/bin/bash
|
#/bin/bash
|
||||||
export DOCKER_IMAGE=intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT
|
export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT
|
||||||
controller_host=localhost
|
controller_host=localhost
|
||||||
controller_port=23000
|
controller_port=23000
|
||||||
api_host=localhost
|
api_host=localhost
|
||||||
|
|
@ -59,7 +59,7 @@ sudo docker run -itd \
|
||||||
To start a worker container:
|
To start a worker container:
|
||||||
```bash
|
```bash
|
||||||
#/bin/bash
|
#/bin/bash
|
||||||
export DOCKER_IMAGE=intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT
|
export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT
|
||||||
export MODEL_PATH=YOUR_MODEL_PATH
|
export MODEL_PATH=YOUR_MODEL_PATH
|
||||||
controller_host=localhost
|
controller_host=localhost
|
||||||
controller_port=23000
|
controller_port=23000
|
||||||
|
|
|
||||||
|
|
@ -196,8 +196,8 @@ else
|
||||||
else
|
else
|
||||||
# Logic for non-controller(worker) mode
|
# Logic for non-controller(worker) mode
|
||||||
worker_address="http://$worker_host:$worker_port"
|
worker_address="http://$worker_host:$worker_port"
|
||||||
# Apply optimizations from bigdl-llm
|
# Apply optimizations from ipex-llm
|
||||||
source bigdl-llm-init -t
|
source ipex-llm-init -t
|
||||||
# First check if user have set OMP_NUM_THREADS by themselves
|
# First check if user have set OMP_NUM_THREADS by themselves
|
||||||
if [[ -n "${omp_num_threads}" ]]; then
|
if [[ -n "${omp_num_threads}" ]]; then
|
||||||
echo "Setting OMP_NUM_THREADS to its original value: $omp_num_threads"
|
echo "Setting OMP_NUM_THREADS to its original value: $omp_num_threads"
|
||||||
|
|
|
||||||
|
|
@ -1,8 +1,8 @@
|
||||||
## Deployment bigdl-llm serving service in K8S environment
|
## Deployment ipex-llm serving service in K8S environment
|
||||||
|
|
||||||
## Image
|
## Image
|
||||||
|
|
||||||
To deploy BigDL-LLM-serving cpu in Kubernetes environment, please use this image: `intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT`
|
To deploy IPEX-LLM-serving cpu in Kubernetes environment, please use this image: `intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT`
|
||||||
|
|
||||||
## Before deployment
|
## Before deployment
|
||||||
|
|
||||||
|
|
@ -10,12 +10,10 @@ To deploy BigDL-LLM-serving cpu in Kubernetes environment, please use this image
|
||||||
|
|
||||||
In this document, we will use `vicuna-7b-v1.5` as the deployment model.
|
In this document, we will use `vicuna-7b-v1.5` as the deployment model.
|
||||||
|
|
||||||
After downloading the model, please change name from `vicuna-7b-v1.5` to `vicuna-7b-v1.5-bigdl` to use `bigdl-llm` as the backend. The `bigdl-llm` backend will be used if model path contains `bigdl`. Otherwise, the original transformer-backend will be used.
|
After downloading the model, please change name from `vicuna-7b-v1.5` to `vicuna-7b-v1.5-ipex` to use `ipex-llm` as the backend. The `ipex-llm` backend will be used if model path contains `ipex-llm`. Otherwise, the original transformer-backend will be used.
|
||||||
|
|
||||||
You can download the model from [here](https://huggingface.co/lmsys/vicuna-7b-v1.5).
|
You can download the model from [here](https://huggingface.co/lmsys/vicuna-7b-v1.5).
|
||||||
|
|
||||||
For ChatGLM models, users do not need to add `bigdl` into model path. We have already used the `BigDL-LLM` backend for this model.
|
|
||||||
|
|
||||||
### Kubernetes config
|
### Kubernetes config
|
||||||
|
|
||||||
We recommend to setup your kubernetes cluster before deployment. Mostly importantly, please set `cpu-management-policy` to `static` by using this [tutorial](https://kubernetes.io/docs/tasks/administer-cluster/cpu-management-policies/). Also, it would be great to also set the `topology management policy` to `single-numa-node`.
|
We recommend to setup your kubernetes cluster before deployment. Mostly importantly, please set `cpu-management-policy` to `static` by using this [tutorial](https://kubernetes.io/docs/tasks/administer-cluster/cpu-management-policies/). Also, it would be great to also set the `topology management policy` to `single-numa-node`.
|
||||||
|
|
@ -67,7 +65,7 @@ We use the following yaml file for controller deployment:
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: Pod
|
kind: Pod
|
||||||
metadata:
|
metadata:
|
||||||
name: bigdl-fschat-a1234bd-controller
|
name: ipex-llm-fschat-a1234bd-controller
|
||||||
labels:
|
labels:
|
||||||
fastchat-appid: a1234bd
|
fastchat-appid: a1234bd
|
||||||
fastchat-app-type: controller
|
fastchat-app-type: controller
|
||||||
|
|
@ -75,7 +73,7 @@ spec:
|
||||||
dnsPolicy: "ClusterFirst"
|
dnsPolicy: "ClusterFirst"
|
||||||
containers:
|
containers:
|
||||||
- name: fastchat-controller # fixed
|
- name: fastchat-controller # fixed
|
||||||
image: intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT
|
image: intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT
|
||||||
imagePullPolicy: IfNotPresent
|
imagePullPolicy: IfNotPresent
|
||||||
env:
|
env:
|
||||||
- name: CONTROLLER_HOST # fixed
|
- name: CONTROLLER_HOST # fixed
|
||||||
|
|
@ -107,7 +105,7 @@ spec:
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: Service
|
kind: Service
|
||||||
metadata:
|
metadata:
|
||||||
name: bigdl-a1234bd-fschat-controller-service
|
name: ipex-llm-a1234bd-fschat-controller-service
|
||||||
spec:
|
spec:
|
||||||
# You may also want to change this to use the cluster's feature
|
# You may also want to change this to use the cluster's feature
|
||||||
type: NodePort
|
type: NodePort
|
||||||
|
|
@ -133,7 +131,7 @@ We use the following deployment for worker deployment:
|
||||||
apiVersion: apps/v1
|
apiVersion: apps/v1
|
||||||
kind: Deployment
|
kind: Deployment
|
||||||
metadata:
|
metadata:
|
||||||
name: bigdl-fschat-a1234bd-worker-deployment
|
name: ipex-llm-fschat-a1234bd-worker-deployment
|
||||||
spec:
|
spec:
|
||||||
# Change this to the number you want
|
# Change this to the number you want
|
||||||
replicas: 1
|
replicas: 1
|
||||||
|
|
@ -148,11 +146,11 @@ spec:
|
||||||
dnsPolicy: "ClusterFirst"
|
dnsPolicy: "ClusterFirst"
|
||||||
containers:
|
containers:
|
||||||
- name: fastchat-worker # fixed
|
- name: fastchat-worker # fixed
|
||||||
image: intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT
|
image: intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT
|
||||||
imagePullPolicy: IfNotPresent
|
imagePullPolicy: IfNotPresent
|
||||||
env:
|
env:
|
||||||
- name: CONTROLLER_HOST # fixed
|
- name: CONTROLLER_HOST # fixed
|
||||||
value: bigdl-a1234bd-fschat-controller-service
|
value: ipex-llm-a1234bd-fschat-controller-service
|
||||||
- name: CONTROLLER_PORT # fixed
|
- name: CONTROLLER_PORT # fixed
|
||||||
value: "21005"
|
value: "21005"
|
||||||
- name: WORKER_HOST # fixed
|
- name: WORKER_HOST # fixed
|
||||||
|
|
@ -162,7 +160,7 @@ spec:
|
||||||
- name: WORKER_PORT # fixed
|
- name: WORKER_PORT # fixed
|
||||||
value: "21841"
|
value: "21841"
|
||||||
- name: MODEL_PATH
|
- name: MODEL_PATH
|
||||||
value: "/llm/models/vicuna-7b-v1.5-bigdl/" # change this to your model
|
value: "/llm/models/vicuna-7b-v1.5-ipex-llm/" # change this to your model
|
||||||
- name: OMP_NUM_THREADS
|
- name: OMP_NUM_THREADS
|
||||||
value: "16"
|
value: "16"
|
||||||
resources:
|
resources:
|
||||||
|
|
@ -190,7 +188,7 @@ You may want to change the `MODEL_PATH` variable in the yaml. Also, please reme
|
||||||
We have set port using `GRADIO_PORT` envrionment variable in `deployment.yaml`, you can use this command
|
We have set port using `GRADIO_PORT` envrionment variable in `deployment.yaml`, you can use this command
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
k port-forward bigdl-fschat-a1234bd-controller --address 0.0.0.0 8002:8002
|
k port-forward ipex-llm-fschat-a1234bd-controller --address 0.0.0.0 8002:8002
|
||||||
```
|
```
|
||||||
|
|
||||||
Then visit http://YOUR_HOST_IP:8002 to access ui.
|
Then visit http://YOUR_HOST_IP:8002 to access ui.
|
||||||
|
|
@ -209,14 +207,14 @@ First, install openai-python:
|
||||||
pip install --upgrade openai
|
pip install --upgrade openai
|
||||||
```
|
```
|
||||||
|
|
||||||
Then, interact with model vicuna-7b-v1.5-bigdl:
|
Then, interact with model vicuna-7b-v1.5-ipex-llm:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
import openai
|
import openai
|
||||||
openai.api_key = "EMPTY"
|
openai.api_key = "EMPTY"
|
||||||
openai.api_base = "http://localhost:8000/v1"
|
openai.api_base = "http://localhost:8000/v1"
|
||||||
|
|
||||||
model = "vicuna-7b-v1.5-bigdl"
|
model = "vicuna-7b-v1.5-ipex-llm"
|
||||||
prompt = "Once upon a time"
|
prompt = "Once upon a time"
|
||||||
|
|
||||||
# create a completion
|
# create a completion
|
||||||
|
|
|
||||||
|
|
@ -16,7 +16,7 @@ spec:
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: Pod
|
kind: Pod
|
||||||
metadata:
|
metadata:
|
||||||
name: bigdl-fschat-a1234bd-controller
|
name: ipex-llm-fschat-a1234bd-controller
|
||||||
labels:
|
labels:
|
||||||
fastchat-appid: a1234bd
|
fastchat-appid: a1234bd
|
||||||
fastchat-app-type: controller
|
fastchat-app-type: controller
|
||||||
|
|
@ -24,7 +24,7 @@ spec:
|
||||||
dnsPolicy: "ClusterFirst"
|
dnsPolicy: "ClusterFirst"
|
||||||
containers:
|
containers:
|
||||||
- name: fastchat-controller # fixed
|
- name: fastchat-controller # fixed
|
||||||
image: intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT
|
image: intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT
|
||||||
imagePullPolicy: IfNotPresent
|
imagePullPolicy: IfNotPresent
|
||||||
env:
|
env:
|
||||||
- name: CONTROLLER_HOST # fixed
|
- name: CONTROLLER_HOST # fixed
|
||||||
|
|
@ -56,7 +56,7 @@ spec:
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: Service
|
kind: Service
|
||||||
metadata:
|
metadata:
|
||||||
name: bigdl-a1234bd-fschat-controller-service
|
name: ipex-llm-a1234bd-fschat-controller-service
|
||||||
spec:
|
spec:
|
||||||
# You may also want to change this to use the cluster's feature
|
# You may also want to change this to use the cluster's feature
|
||||||
type: NodePort
|
type: NodePort
|
||||||
|
|
@ -76,7 +76,7 @@ spec:
|
||||||
apiVersion: apps/v1
|
apiVersion: apps/v1
|
||||||
kind: Deployment
|
kind: Deployment
|
||||||
metadata:
|
metadata:
|
||||||
name: bigdl-fschat-a1234bd-worker-deployment
|
name: ipex-llm-fschat-a1234bd-worker-deployment
|
||||||
spec:
|
spec:
|
||||||
# Change this to the number you want
|
# Change this to the number you want
|
||||||
replicas: 1
|
replicas: 1
|
||||||
|
|
@ -91,11 +91,11 @@ spec:
|
||||||
dnsPolicy: "ClusterFirst"
|
dnsPolicy: "ClusterFirst"
|
||||||
containers:
|
containers:
|
||||||
- name: fastchat-worker # fixed
|
- name: fastchat-worker # fixed
|
||||||
image: intelanalytics/bigdl-llm-serving-cpu:2.5.0-SNAPSHOT
|
image: intelanalytics/ipex-llm-serving-cpu:2.5.0-SNAPSHOT
|
||||||
imagePullPolicy: IfNotPresent
|
imagePullPolicy: IfNotPresent
|
||||||
env:
|
env:
|
||||||
- name: CONTROLLER_HOST # fixed
|
- name: CONTROLLER_HOST # fixed
|
||||||
value: bigdl-a1234bd-fschat-controller-service
|
value: ipex-llm-a1234bd-fschat-controller-service
|
||||||
- name: CONTROLLER_PORT # fixed
|
- name: CONTROLLER_PORT # fixed
|
||||||
value: "21005"
|
value: "21005"
|
||||||
- name: WORKER_HOST # fixed
|
- name: WORKER_HOST # fixed
|
||||||
|
|
@ -105,7 +105,7 @@ spec:
|
||||||
- name: WORKER_PORT # fixed
|
- name: WORKER_PORT # fixed
|
||||||
value: "21841"
|
value: "21841"
|
||||||
- name: MODEL_PATH
|
- name: MODEL_PATH
|
||||||
value: "/llm/models/vicuna-7b-v1.5-bigdl/" # change this to your model
|
value: "/llm/models/vicuna-7b-v1.5-ipex-llm/" # change this to your model
|
||||||
- name: OMP_NUM_THREADS
|
- name: OMP_NUM_THREADS
|
||||||
value: "16"
|
value: "16"
|
||||||
resources:
|
resources:
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
FROM intelanalytics/bigdl-llm-xpu:2.5.0-SNAPSHOT
|
FROM intelanalytics/ipex-llm-xpu:2.5.0-SNAPSHOT
|
||||||
|
|
||||||
ARG http_proxy
|
ARG http_proxy
|
||||||
ARG https_proxy
|
ARG https_proxy
|
||||||
|
|
@ -10,7 +10,7 @@ COPY ./entrypoint.sh /opt/entrypoint.sh
|
||||||
|
|
||||||
# Install Serving Dependencies
|
# Install Serving Dependencies
|
||||||
RUN cd /llm && \
|
RUN cd /llm && \
|
||||||
pip install --pre --upgrade bigdl-llm[serving] && \
|
pip install --pre --upgrade ipex-llm[serving] && \
|
||||||
pip install transformers==4.36.2 gradio==4.19.2 && \
|
pip install transformers==4.36.2 gradio==4.19.2 && \
|
||||||
chmod +x /opt/entrypoint.sh
|
chmod +x /opt/entrypoint.sh
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,4 +1,4 @@
|
||||||
## Build/Use BigDL-LLM-serving xpu image
|
## Build/Use IPEX-LLM-serving xpu image
|
||||||
|
|
||||||
### Build Image
|
### Build Image
|
||||||
```bash
|
```bash
|
||||||
|
|
@ -6,7 +6,7 @@ docker build \
|
||||||
--build-arg http_proxy=.. \
|
--build-arg http_proxy=.. \
|
||||||
--build-arg https_proxy=.. \
|
--build-arg https_proxy=.. \
|
||||||
--build-arg no_proxy=.. \
|
--build-arg no_proxy=.. \
|
||||||
--rm --no-cache -t intelanalytics/bigdl-llm-serving-xpu:2.5.0-SNAPSHOT .
|
--rm --no-cache -t intelanalytics/ipex-llm-serving-xpu:2.5.0-SNAPSHOT .
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -18,7 +18,7 @@ To map the `xpu` into the container, you need to specify `--device=/dev/dri` whe
|
||||||
An example could be:
|
An example could be:
|
||||||
```bash
|
```bash
|
||||||
#/bin/bash
|
#/bin/bash
|
||||||
export DOCKER_IMAGE=intelanalytics/bigdl-llm-serving-xpu:2.5.0-SNAPSHOT
|
export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-xpu:2.5.0-SNAPSHOT
|
||||||
|
|
||||||
sudo docker run -itd \
|
sudo docker run -itd \
|
||||||
--net=host \
|
--net=host \
|
||||||
|
|
@ -43,4 +43,4 @@ root@arda-arc12:/# sycl-ls
|
||||||
```
|
```
|
||||||
After the container is booted, you could get into the container through `docker exec`.
|
After the container is booted, you could get into the container through `docker exec`.
|
||||||
|
|
||||||
To run model-serving using `BigDL-LLM` as backend, you can refer to this [document](https://github.com/intel-analytics/BigDL/tree/main/python/llm/src/bigdl/llm/serving).
|
To run model-serving using `IPEX-LLM` as backend, you can refer to this [document](https://github.com/intel-analytics/IPEX-LLM/tree/main/python/llm/src/ipex_llm/serving).
|
||||||
|
|
|
||||||
Loading…
Reference in a new issue