- - Basic Forecasting + Basic + Forecasting
-
Forecasting using AutoML
diff --git a/docs/readthedocs/source/_toc.yml b/docs/readthedocs/source/_toc.yml
index fdba5c9a..9cba0641 100644
--- a/docs/readthedocs/source/_toc.yml
+++ b/docs/readthedocs/source/_toc.yml
@@ -19,6 +19,46 @@ subtrees:
- file: doc/Application/powered-by
title: "Powered by"
+ - entries:
+ - file: doc/LLM/index
+ title: "LLM"
+ subtrees:
+ - entries:
+ - file: doc/LLM/Overview/llm
+ title: "LLM in 5 minutes"
+ - file: doc/LLM/Overview/install
+ title: "Installation"
+ subtrees:
+ - entries:
+ - file: doc/LLM/Overview/install_cpu
+ title: "CPU"
+ - file: doc/LLM/Overview/install_gpu
+ title: "GPU"
+ - file: doc/LLM/Overview/KeyFeatures/index
+ title: "Key Features"
+ subtrees:
+ - entries:
+ - file: doc/LLM/Overview/KeyFeatures/transformers_style_api
+ subtrees:
+ - entries:
+ - file: doc/LLM/Overview/KeyFeatures/hugging_face_format
+ - file: doc/LLM/Overview/KeyFeatures/native_format
+ - file: doc/LLM/Overview/KeyFeatures/optimize_model
+ - file: doc/LLM/Overview/KeyFeatures/langchain_api
+ # - file: doc/LLM/Overview/KeyFeatures/cli
+ - file: doc/LLM/Overview/KeyFeatures/gpu_supports
+ - file: doc/LLM/Overview/examples
+ title: "Examples"
+ subtrees:
+ - entries:
+ - file: doc/LLM/Overview/examples_cpu
+ title: "CPU"
+ - file: doc/LLM/Overview/examples_gpu
+ title: "GPU"
+ # - file: doc/LLM/Overview/known_issues
+ # title: "Tips and Known Issues"
+ - file: doc/PythonAPI/LLM/index
+ title: "API Reference"
- entries:
- file: doc/Orca/index
@@ -329,13 +369,6 @@ subtrees:
- file: doc/PPML/QuickStart/tpc-ds_with_sparksql_on_k8s
- file: doc/PPML/Overview/azure_ppml_occlum
- file: doc/PPML/Overview/secure_lightgbm_on_spark
- - entries:
- - file: doc/LLM/index
- title: "LLM"
- subtrees:
- - entries:
- - file: doc/PythonAPI/LLM/index
- title: "API Reference"
- entries:
- file: doc/UserGuide/contributor
diff --git a/docs/readthedocs/source/doc/LLM/Overview/KeyFeatures/cli.md b/docs/readthedocs/source/doc/LLM/Overview/KeyFeatures/cli.md
new file mode 100644
index 00000000..7c21f2f8
--- /dev/null
+++ b/docs/readthedocs/source/doc/LLM/Overview/KeyFeatures/cli.md
@@ -0,0 +1,40 @@
+# CLI (Command Line Interface) Tool
+
+```eval_rst
+
+.. note::
+
+ Currently ``bigdl-llm`` CLI supports *LLaMA* (e.g., vicuna), *GPT-NeoX* (e.g., redpajama), *BLOOM* (e.g., pheonix) and *GPT2* (e.g., starcoder) model architecture; for other models, you may use the ``transformers``-style or LangChain APIs.
+```
+
+## Convert Model
+
+You may convert the downloaded model into native INT4 format using `llm-convert`.
+
+```bash
+# convert PyTorch (fp16 or fp32) model;
+# llama/bloom/gptneox/starcoder model family is currently supported
+llm-convert "/path/to/model/" --model-format pth --model-family "bloom" --outfile "/path/to/output/"
+
+# convert GPTQ-4bit model
+# only llama model family is currently supported
+llm-convert "/path/to/model/" --model-format gptq --model-family "llama" --outfile "/path/to/output/"
+```
+
+## Run Model
+
+You may run the converted model using `llm-cli` or `llm-chat` (built on top of `main.cpp` in [`llama.cpp`](https://github.com/ggerganov/llama.cpp))
+
+```bash
+# help
+# llama/bloom/gptneox/starcoder model family is currently supported
+llm-cli -x gptneox -h
+
+# text completion
+# llama/bloom/gptneox/starcoder model family is currently supported
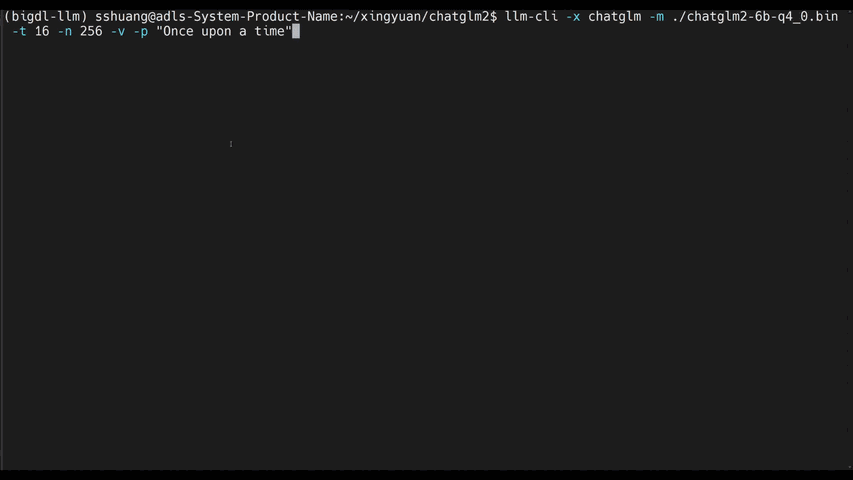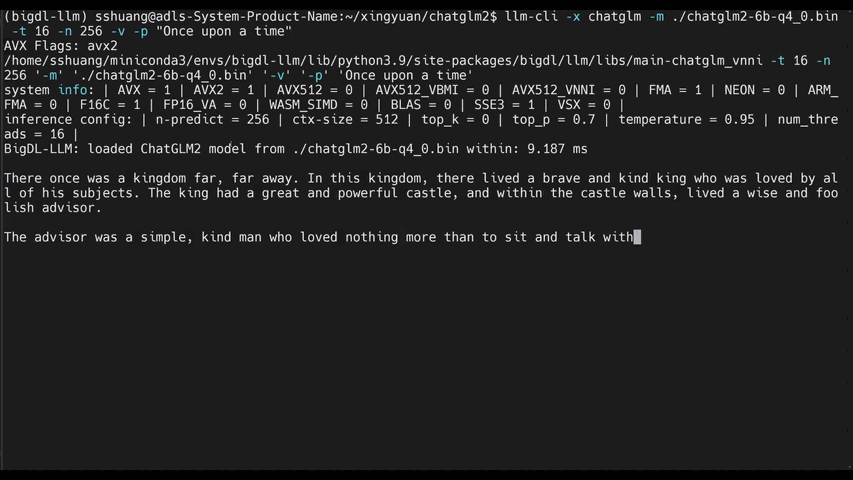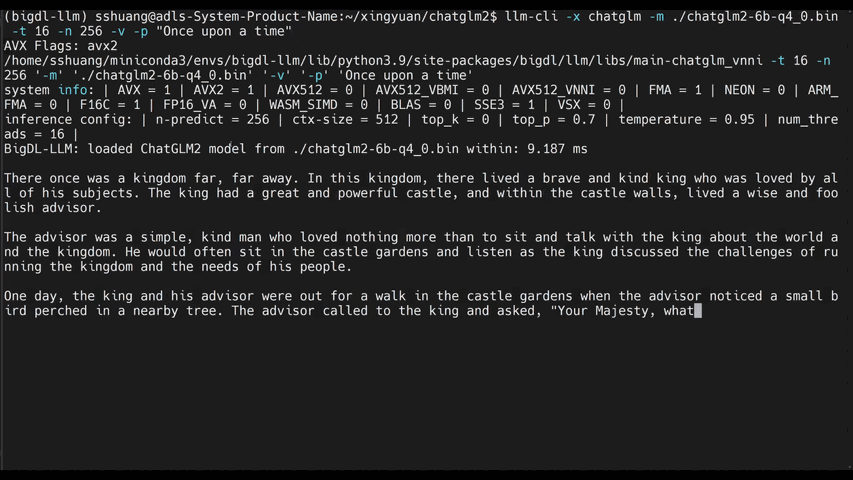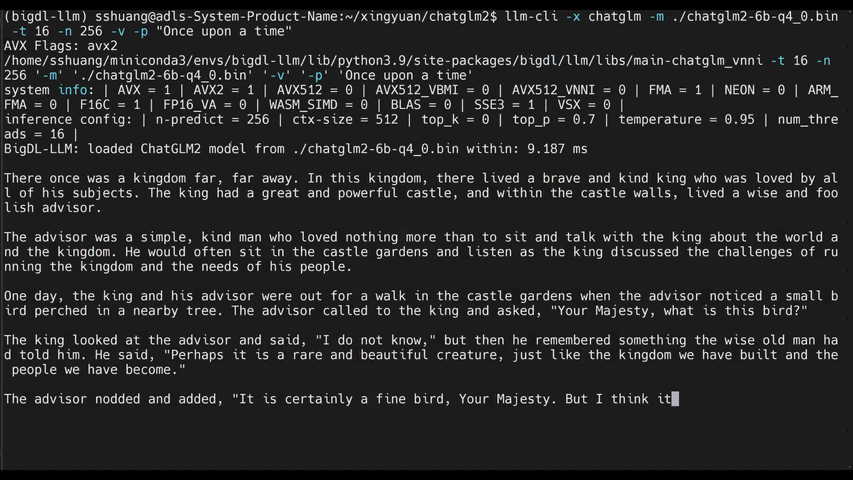
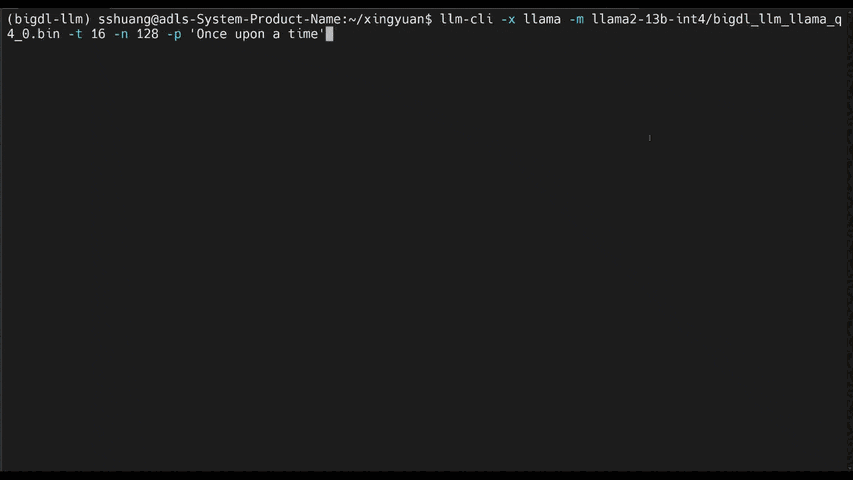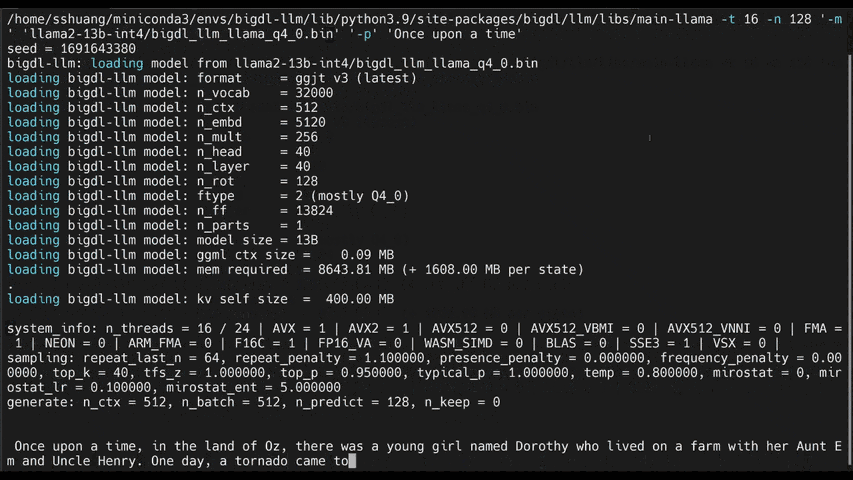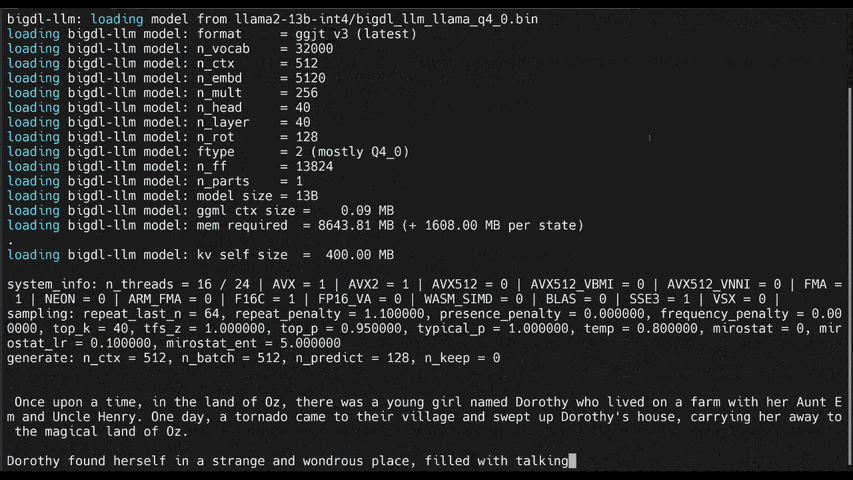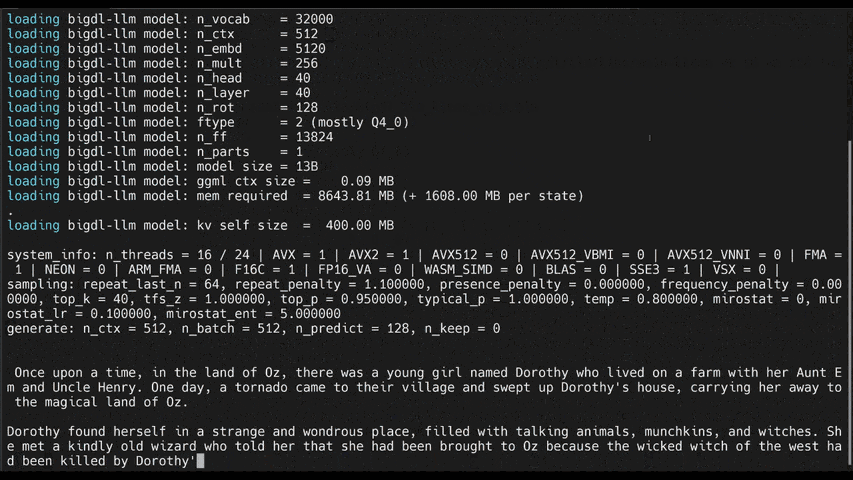
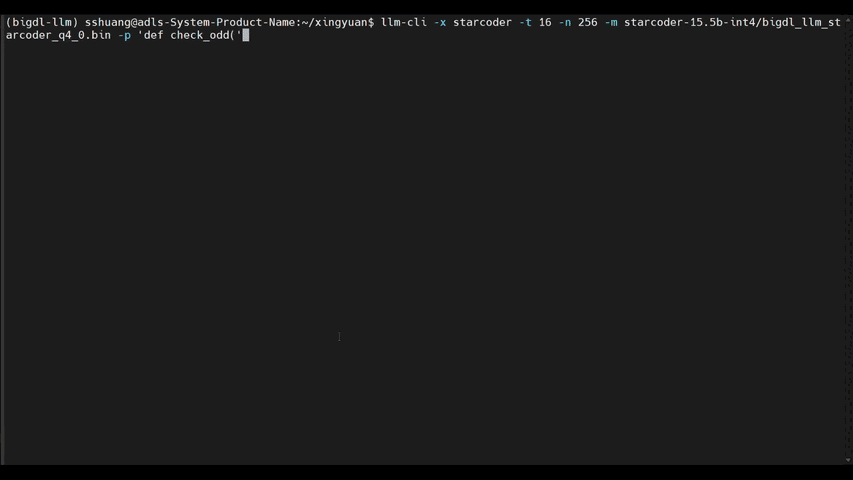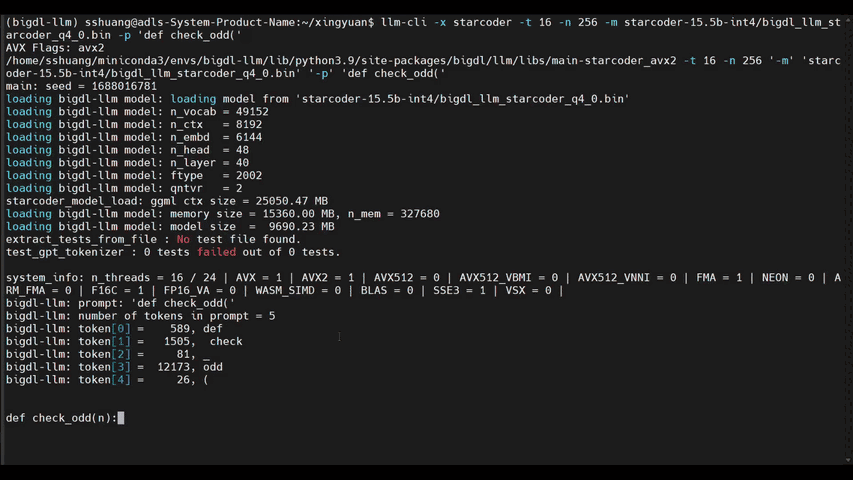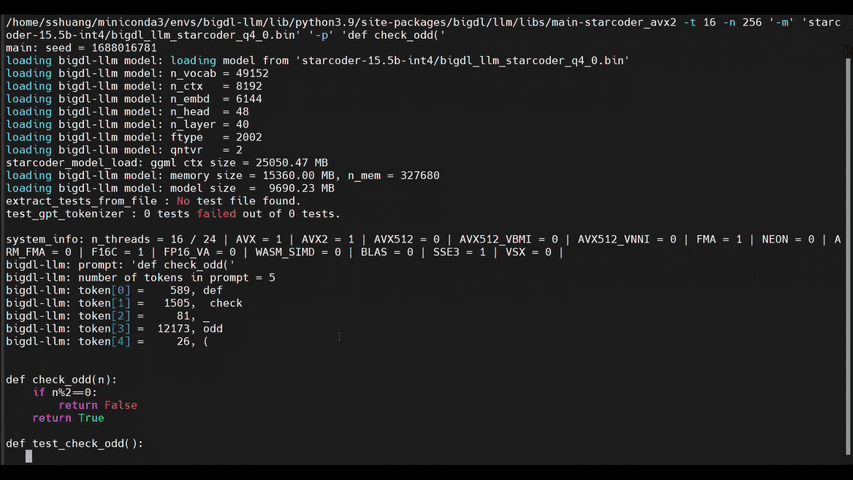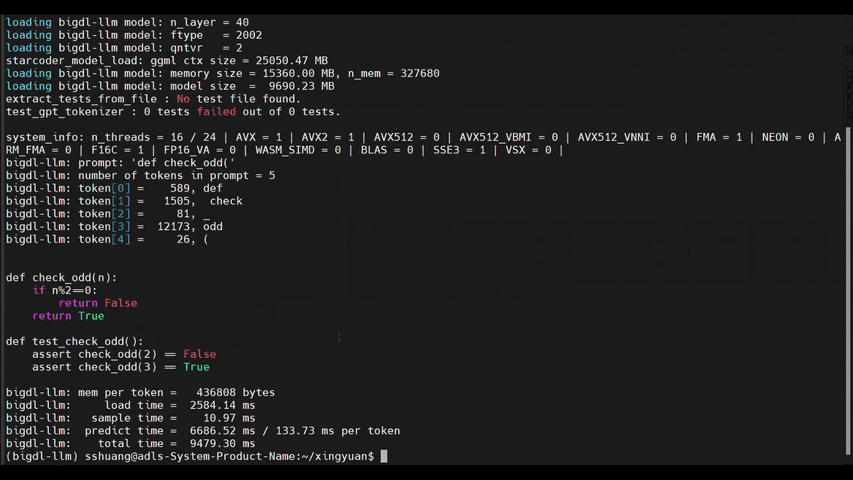
+llm-cli -t 16 -x gptneox -m "/path/to/output/model.bin" -p 'Once upon a time,'
+
+# chat mode
+# llama/gptneox model family is currently supported
+llm-chat -m "/path/to/output/model.bin" -x llama
+```
\ No newline at end of file
diff --git a/docs/readthedocs/source/doc/LLM/Overview/KeyFeatures/gpu_supports.md b/docs/readthedocs/source/doc/LLM/Overview/KeyFeatures/gpu_supports.md
new file mode 100644
index 00000000..7cbd65c3
--- /dev/null
+++ b/docs/readthedocs/source/doc/LLM/Overview/KeyFeatures/gpu_supports.md
@@ -0,0 +1,47 @@
+# GPU Supports
+
+You may apply INT4 optimizations to any Hugging Face *Transformers* models on device with Intel GPUs as follows:
+
+```python
+# import ipex
+import intel_extension_for_pytorch as ipex
+
+# load Hugging Face Transformers model with INT4 optimizations on Intel GPUs
+from bigdl.llm.transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained('/path/to/model/',
+ load_in_4bit=True,
+ optimize_model=False)
+model = model.to('xpu')
+```
+
+```eval_rst
+.. note::
+
+ You may apply INT8 optimizations as follows:
+
+ .. code-block:: python
+
+ model = AutoModelForCausalLM.from_pretrained('/path/to/model/',
+ load_in_low_bit="sym_int8",
+ optimize_model=False)
+ model = model.to('xpu')
+```
+
+After loading the Hugging Face *Transformers* model, you may easily run the optimized model as follows:
+
+```python
+# run the optimized model
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained(model_path)
+input_ids = tokenizer.encode(input_str, ...).to('xpu')
+output_ids = model.generate(input_ids, ...)
+output = tokenizer.batch_decode(output_ids)
+```
+
+```eval_rst
+.. seealso::
+
+ See the complete examples `here +diff --git a/docs/readthedocs/source/doc/LLM/index.rst b/docs/readthedocs/source/doc/LLM/index.rst index ca9e7491..23e7a759 100644 --- a/docs/readthedocs/source/doc/LLM/index.rst +++ b/docs/readthedocs/source/doc/LLM/index.rst @@ -1,14 +1,53 @@ BigDL-LLM ========================= +.. raw:: html -BigDL-LLM is a library for running LLM (Large Language Models) on your Intel laptop using INT4 with very low latency (for any Hugging Face Transformers model). +
+ [1] + Performance varies by use, configuration and other factors.
+bigdl-llmmay not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex. + ++ BigDL-LLM is a library for running LLM (large language model) on your Intel laptop or GPU using INT4 with very low latency [1] (for any PyTorch model). +
------- .. grid:: 1 2 2 2 :gutter: 2 + .. grid-item-card:: + + **Get Started** + ^^^ + + Documents in these sections helps you getting started quickly with BigDL-LLM. + + +++ + :bdg-link:`BigDL-LLM in 5 minutes <./Overview/quick_start.html>` | + :bdg-link:`Installation <./Overview/install.html>` + + .. grid-item-card:: + + **Key Features Guide** + ^^^ + + Each guide in this section provides you with in-depth information, concepts and knowledges about BigDL-LLM key features. + + +++ + + :bdg-link:`transformers-style <./Overview/KeyFeatures/transformers_style_api.html>` | + :bdg-link:`Optimize Model <./Overview/KeyFeatures/optimize_model.html>` | + :bdg-link:`LangChain <./Overview/KeyFeatures/langchain_api.html>` | + :bdg-link:`GPU <./Overview/KeyFeatures/gpu_supports.html>` + + .. grid-item-card:: + + **Examples & Tutorials** + ^^^ + + Examples contain scripts to help you quickly get started using BigDL-LLM to run some popular open-source models in the community. + + +++ + + :bdg-link:`Examples <./Overview/examples.html>` + .. grid-item-card:: **API Document** @@ -20,7 +59,19 @@ BigDL-LLM is a library for running LLM (Large Language Models) on your Intel lap :bdg-link:`API Document <../PythonAPI/LLM/index.html>` +------ + +.. raw:: html + +++ .. toctree:: :hidden: - BigDL-LLM Document+ [1] + Performance varies by use, configuration and other factors.
+bigdl-llmmay not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex. + +\ No newline at end of file + BigDL-LLM Document diff --git a/docs/readthedocs/source/doc/PythonAPI/LLM/transformers.rst b/docs/readthedocs/source/doc/PythonAPI/LLM/transformers.rst index 519b2d27..62b05ac7 100644 --- a/docs/readthedocs/source/doc/PythonAPI/LLM/transformers.rst +++ b/docs/readthedocs/source/doc/PythonAPI/LLM/transformers.rst @@ -1,4 +1,4 @@ -BigDL-LLM Transformers API +BigDL-LLM `transformers`-style API ===================== llm.transformers.model diff --git a/docs/readthedocs/source/index.rst b/docs/readthedocs/source/index.rst index fc5a9549..3fb1f454 100644 --- a/docs/readthedocs/source/index.rst +++ b/docs/readthedocs/source/index.rst @@ -10,7 +10,12 @@ The BigDL Project --------------------------------- BigDL-LLM: low-Bit LLM library --------------------------------- -`bigdl-llm +
.. note:: @@ -33,8 +38,8 @@ See the **optimized performance** of ``chatglm2-6b``, ``llama-2-13b-chat``, and .. raw:: htmlbigdl-llmis a library for running LLM (large language model) on your Intel laptop or GPU using INT4 with very low latency [1] (for any PyTorch model). +-
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ @@ -151,4 +156,12 @@ Choosing the right BigDL library ------ -.. [*] Performance varies by use, configuration and other factors. ``bigdl-llm`` may not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex. +.. raw:: html + +

 -
-  +
+ 
 +
+  +
++ [1] + Performance varies by use, configuration and other factors.
+bigdl-llmmay not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex. + +