diff --git a/README.md b/README.md
index ae2935a2..73cb0aed 100644
--- a/README.md
+++ b/README.md
@@ -17,12 +17,34 @@
- Over 20 models have been optimized/verified on `bigdl-llm`, including *LLaMA/LLaMA2, ChatGLM/ChatGLM2, MPT, Falcon, Dolly-v1/Dolly-v2, StarCoder, Whisper, QWen, Baichuan, MOSS,* and more; see the complete list [here](python/llm/README.md#verified-models).
### `bigdl-llm` Demos
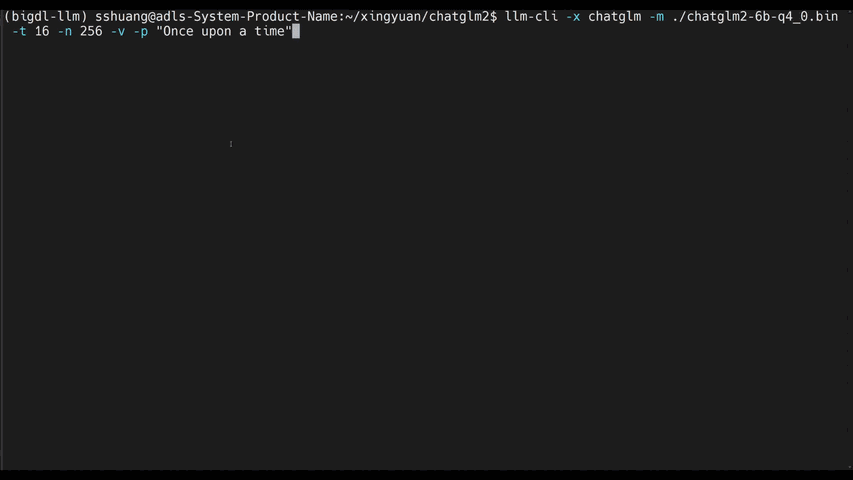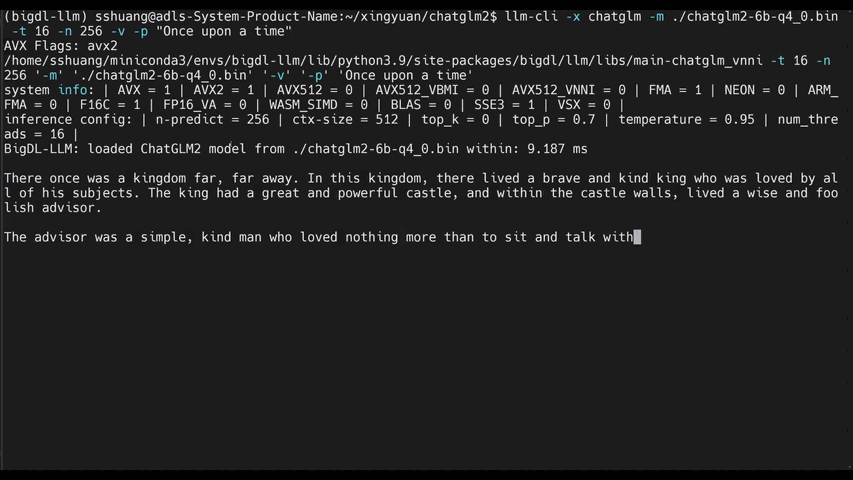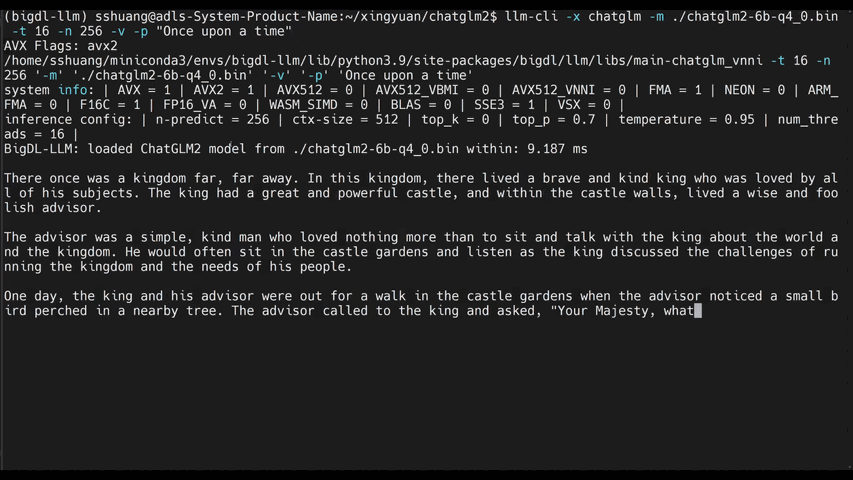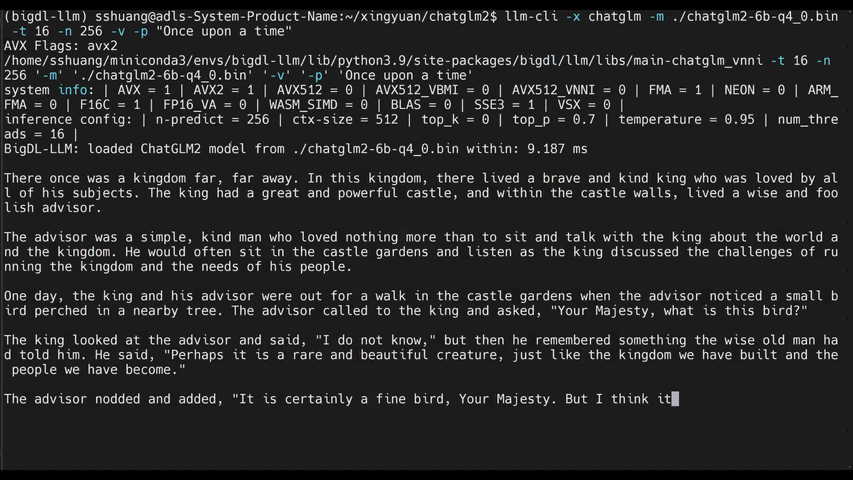
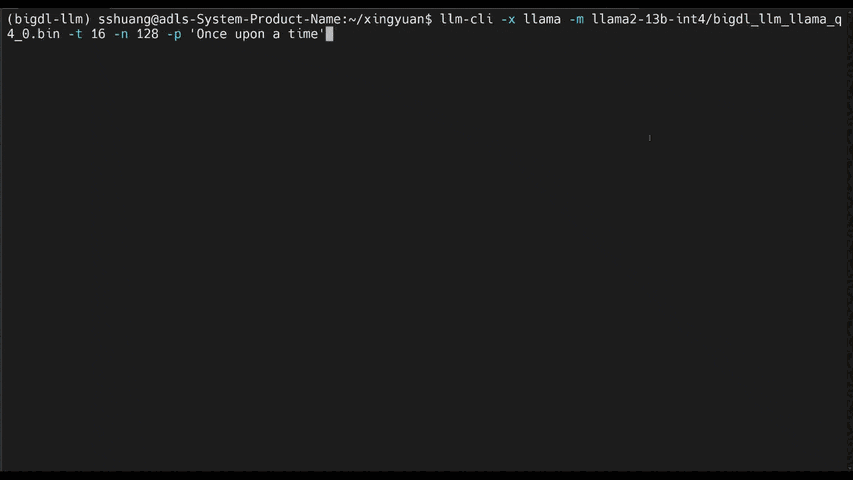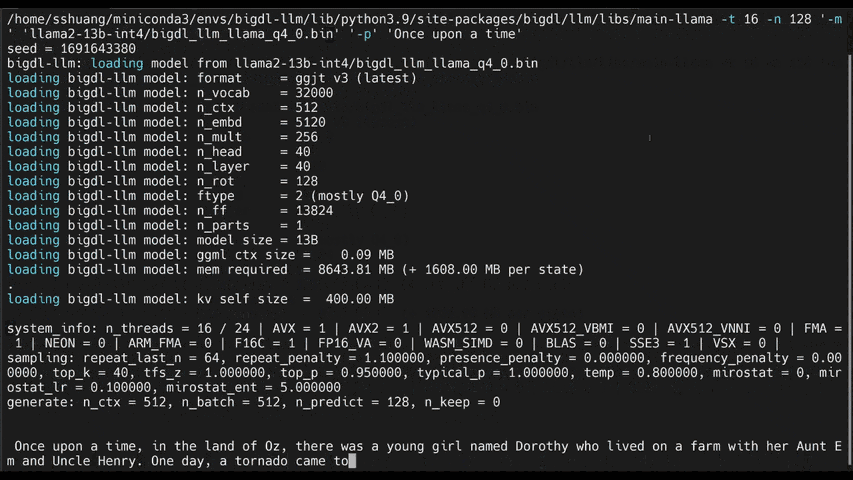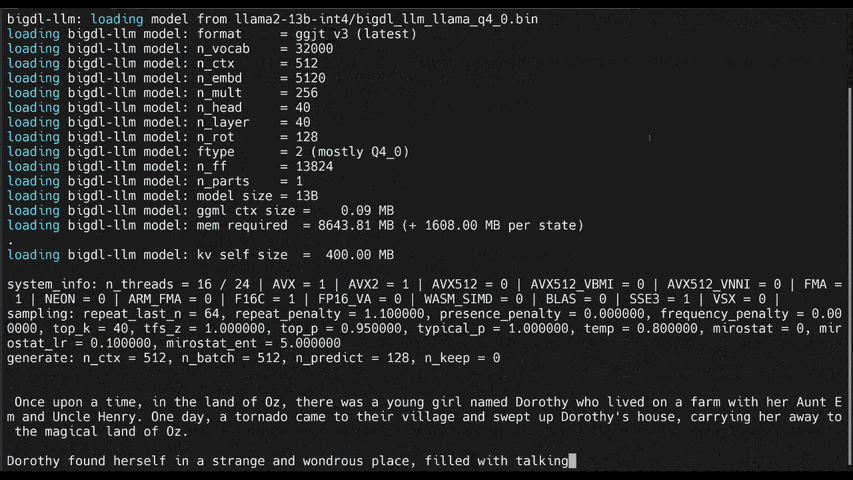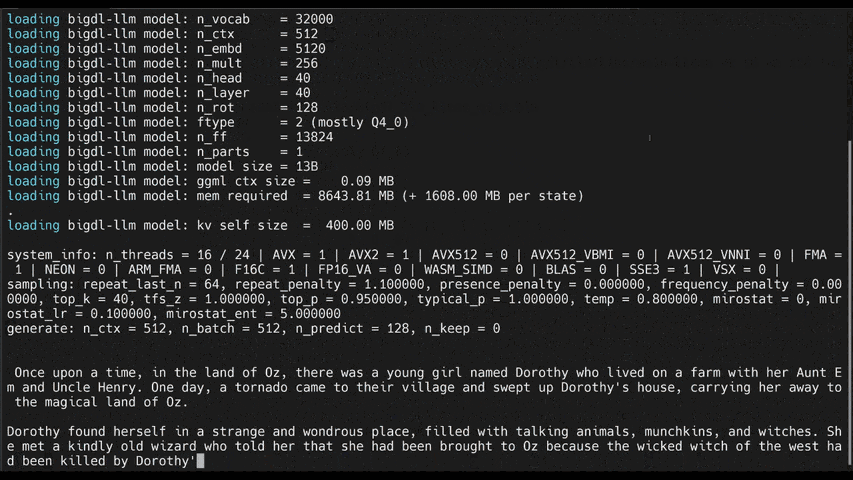
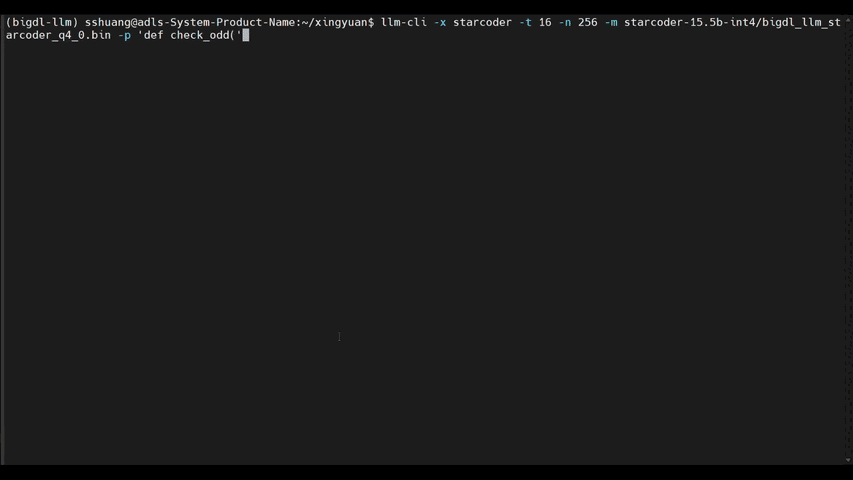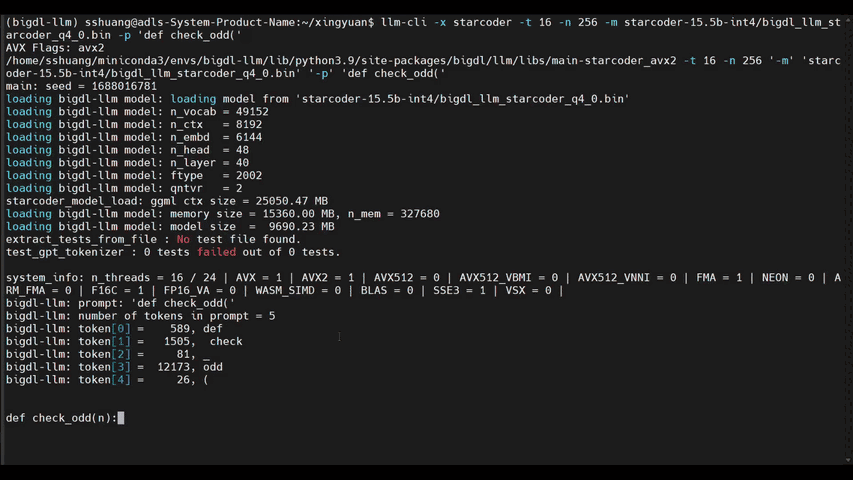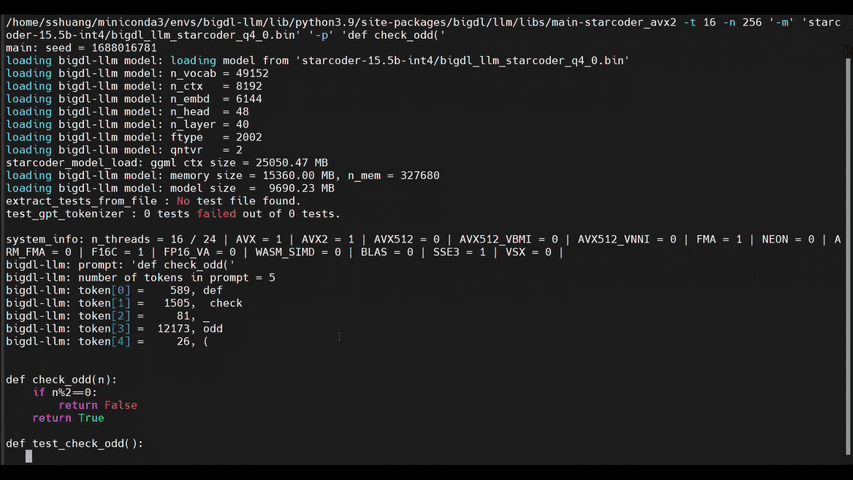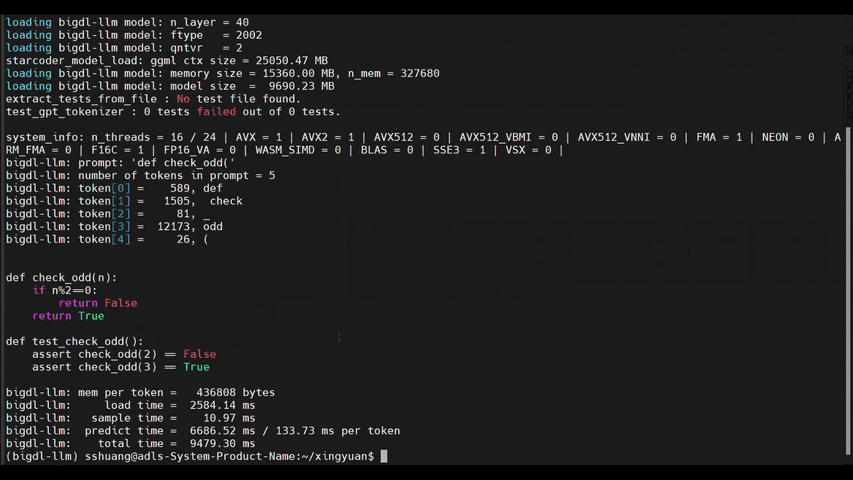
-See the ***optimized performance*** of `chatglm2-6b`, `llama-2-13b-chat`, and `starcoder-15.5b` models on a 12th Gen Intel Core CPU below.
+See the ***optimized performance*** of `chatglm2-6b` and `llama-2-13b-chat` models on 12th Gen Intel Core CPU and Intel Arc GPU below.
-
- 
 -
-  -
-
+
+
+ | 12th Gen Intel Core CPU |
+ Intel Arc GPU |
+
+
+ |
+
+ |
+
+
+ |
+
+ 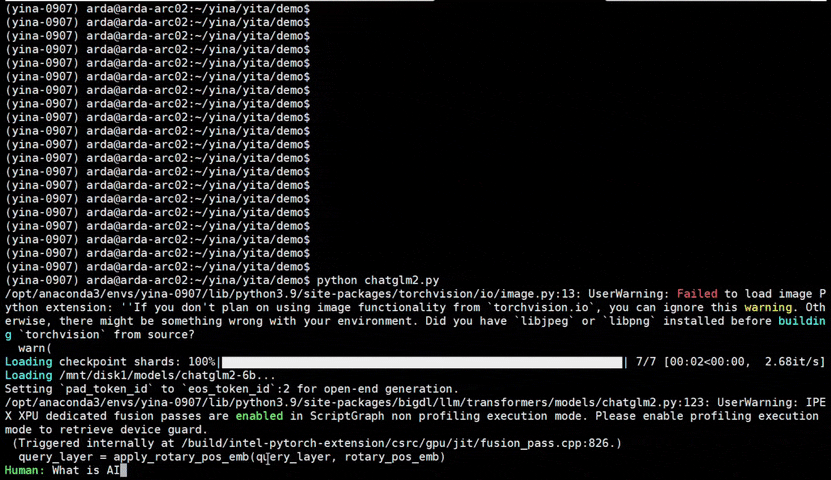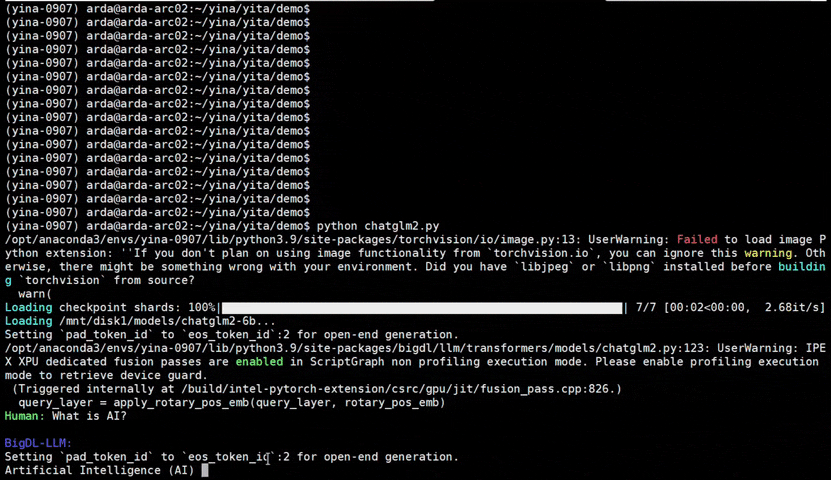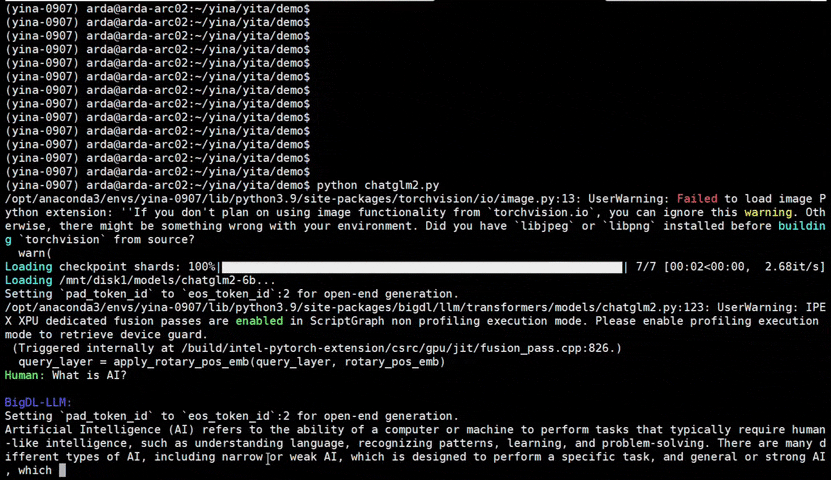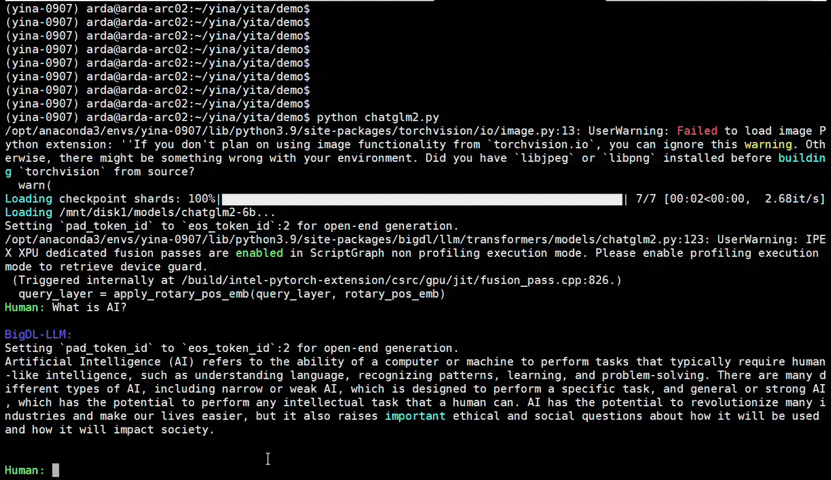 +
+ |
+
+ 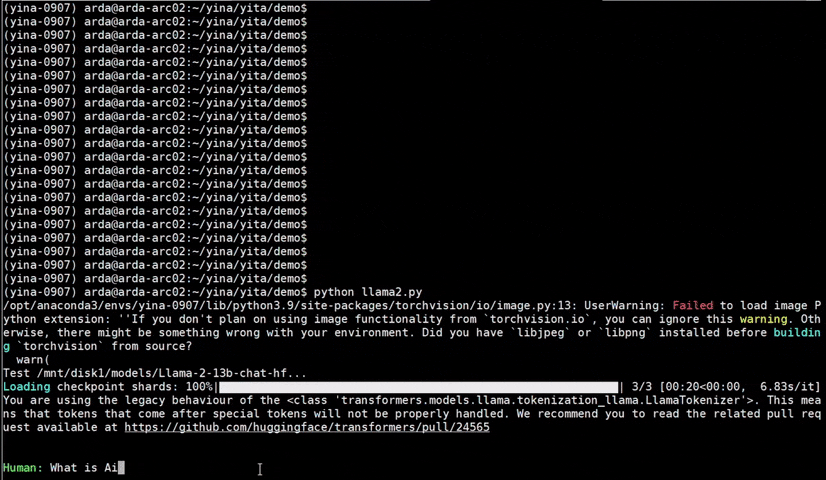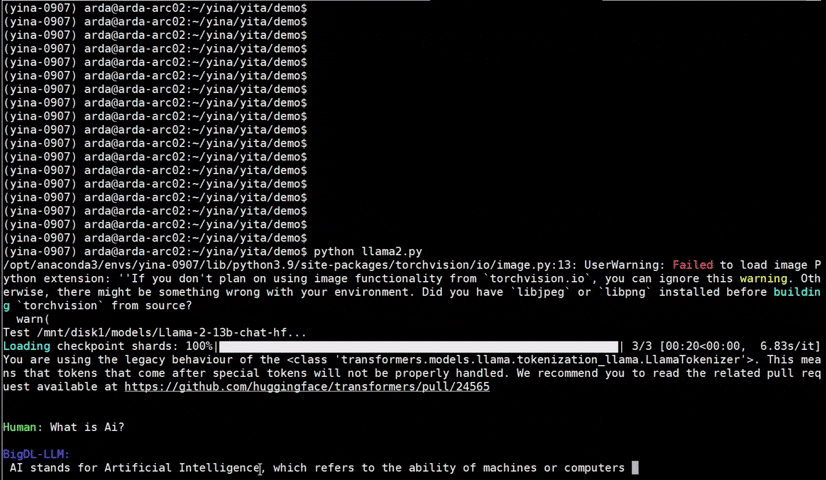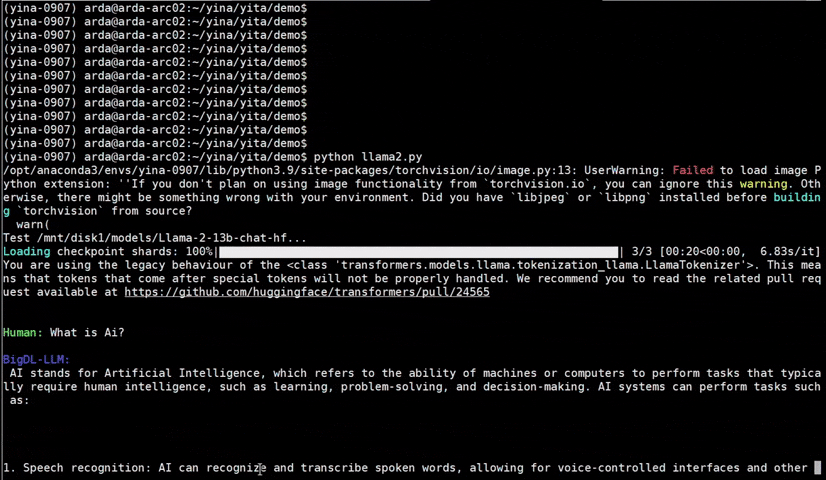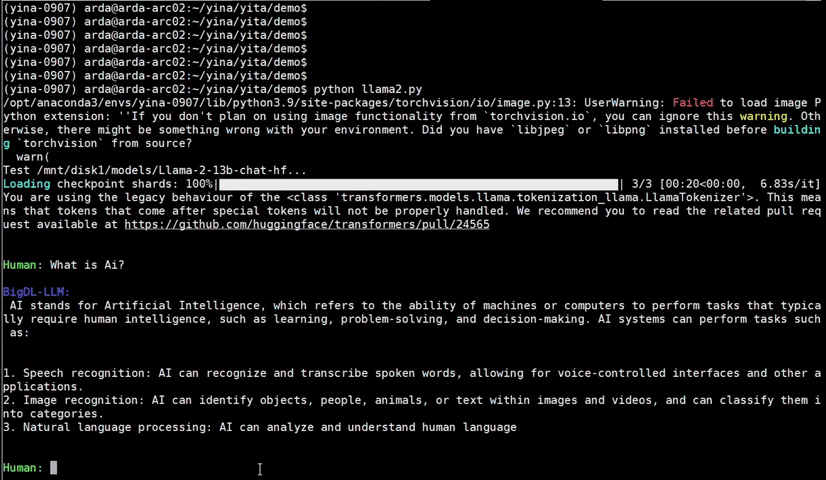 +
+ |
+
+
+ chatglm2-6b |
+ llama-2-13b-chat |
+ chatglm2-6b |
+ llama-2-13b-chat |
+
+
### `bigdl-llm` quickstart
diff --git a/docs/readthedocs/source/doc/LLM/index.rst b/docs/readthedocs/source/doc/LLM/index.rst
index bbef9f64..f18aa1ab 100644
--- a/docs/readthedocs/source/doc/LLM/index.rst
+++ b/docs/readthedocs/source/doc/LLM/index.rst
@@ -3,9 +3,9 @@ BigDL-LLM
.. raw:: html
-
- BigDL-LLM is a library for running LLM (large language model) on your Intel laptop or GPU using INT4 with very low latency [1] (for any PyTorch model).
-
+
+ bigdl-llm is a library for running LLM (large language model) on Intel XPU (from Laptop to GPU to Cloud) using INT4 with very low latency [1] (for any PyTorch model).
+
-------
diff --git a/docs/readthedocs/source/index.rst b/docs/readthedocs/source/index.rst
index 3d7ae561..e395fed0 100644
--- a/docs/readthedocs/source/index.rst
+++ b/docs/readthedocs/source/index.rst
@@ -33,14 +33,36 @@ Latest update
``bigdl-llm`` demos
============================================
-See the **optimized performance** of ``chatglm2-6b``, ``llama-2-13b-chat``, and ``starcoder-15.5b`` models on a 12th Gen Intel Core CPU below.
+See the **optimized performance** of ``chatglm2-6b`` and ``llama-2-13b-chat`` models on 12th Gen Intel Core CPU and Intel Arc GPU below.
.. raw:: html
-
-
-
-
+
+
+ | 12th Gen Intel Core CPU |
+ Intel Arc GPU |
+
+
+ |
+
+ |
+
+
+ |
+
+
+ |
+
+
+ |
+
+
+ chatglm2-6b |
+ llama-2-13b-chat |
+ chatglm2-6b |
+ llama-2-13b-chat |
+
+
============================================
``bigdl-llm`` quickstart
diff --git a/python/llm/README.md b/python/llm/README.md
index c8569827..e04e9417 100644
--- a/python/llm/README.md
+++ b/python/llm/README.md
@@ -8,12 +8,34 @@
- `bigdl-llm` now supports Intel Arc or Flex GPU; see the the latest GPU examples [here](example/gpu).
### Demos
-See the ***optimized performance*** of `chatglm2-6b`, `llama-2-13b-chat`, and `starcoder-15.5b` models on a 12th Gen Intel Core CPU below.
+See the ***optimized performance*** of `chatglm2-6b` and `llama-2-13b-chat` models on 12th Gen Intel Core CPU and Intel Arc GPU below.
-
-
-
-
+
+
+ | 12th Gen Intel Core CPU |
+ Intel Arc GPU |
+
+
+ |
+
+ |
+
+
+ |
+
+
+ |
+
+
+ |
+
+
+ chatglm2-6b |
+ llama-2-13b-chat |
+ chatglm2-6b |
+ llama-2-13b-chat |
+
+
### Verified models