diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md b/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md
index a6f89c42..873db7cf 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md
@@ -6,23 +6,32 @@ It applies to Intel Core Ultra and Core 12 - 14 gen integrated GPUs (iGPUs), as
## Install Visual Studio 2022
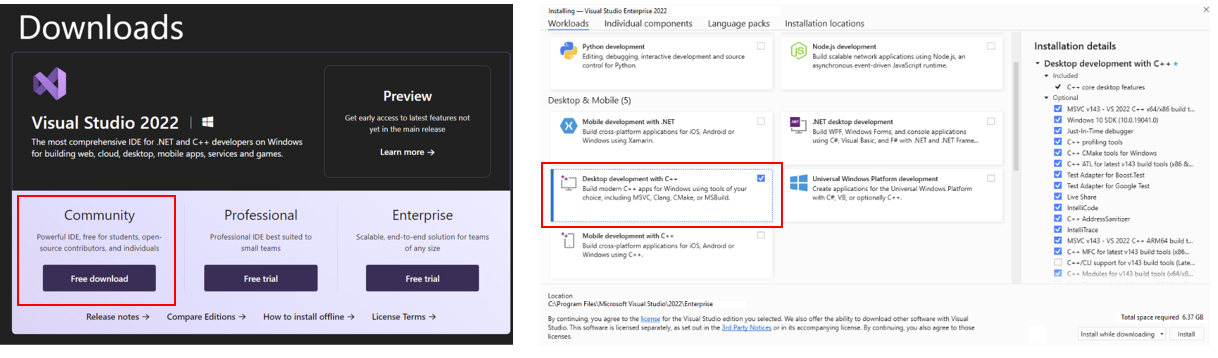
-* Download and Install Visual Studio 2022 Community Edition from the [official Microsoft Visual Studio website](https://visualstudio.microsoft.com/downloads/). Ensure you select the **Desktop development with C++ workload** during the installation process.
+Download and Install Visual Studio 2022 Community Edition from the [official Microsoft Visual Studio website](https://visualstudio.microsoft.com/downloads/). Ensure you select the **Desktop development with C++ workload** during the installation process.
- > Note: The installation could take around 15 minutes, and requires at least 7GB of free disk space.
- > If you accidentally skip adding the **Desktop development with C++ workload** during the initial setup, you can add it afterward by navigating to **Tools > Get Tools and Features...**. Follow the instructions on [this Microsoft guide](https://learn.microsoft.com/en-us/cpp/build/vscpp-step-0-installation?view=msvc-170#step-4---choose-workloads) to update your installation.
- >
- >  +```eval_rst
+.. note::
+
+ The installation could take around 15 minutes, and requires at least 7GB of free disk space.
+ If you accidentally skip adding the **Desktop development with C++ workload** during the initial setup, you can add it afterward by navigating to **Tools > Get Tools and Features...**. Follow the instructions on `this Microsoft guide `_ to update your installation.
+```
+
+
## Install GPU Driver
-* Download and install the latest GPU driver from the [official Intel download page](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html). A system reboot is necessary to apply the changes after the installation is complete.
-
- > Note: The process could take around 10 minutes. After reboot, check for the **Intel Arc Control** application to verify the driver has been installed correctly. If the installation was successful, you should see the **Arc Control** interface similar to the figure below
+Download and install the latest GPU driver from the [official Intel download page](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html). A system reboot is necessary to apply the changes after the installation is complete.
- >
+```eval_rst
+.. note::
+
+ The installation could take around 15 minutes, and requires at least 7GB of free disk space.
+ If you accidentally skip adding the **Desktop development with C++ workload** during the initial setup, you can add it afterward by navigating to **Tools > Get Tools and Features...**. Follow the instructions on `this Microsoft guide `_ to update your installation.
+```
+
+
## Install GPU Driver
-* Download and install the latest GPU driver from the [official Intel download page](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html). A system reboot is necessary to apply the changes after the installation is complete.
-
- > Note: The process could take around 10 minutes. After reboot, check for the **Intel Arc Control** application to verify the driver has been installed correctly. If the installation was successful, you should see the **Arc Control** interface similar to the figure below
+Download and install the latest GPU driver from the [official Intel download page](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html). A system reboot is necessary to apply the changes after the installation is complete.
- >  +```eval_rst
+.. note::
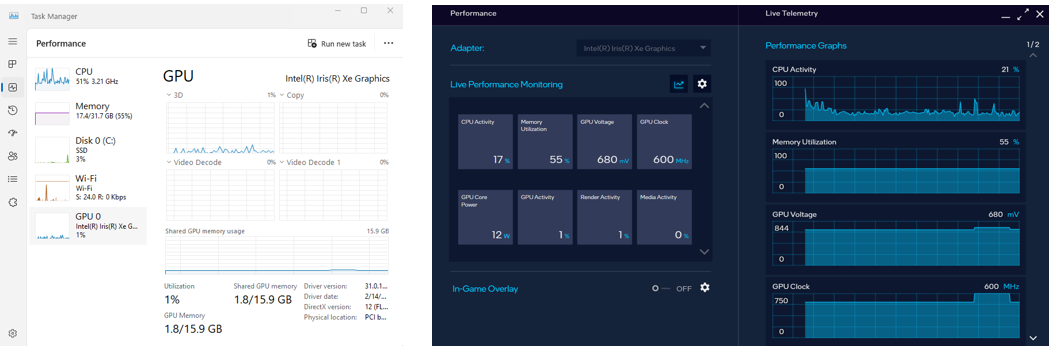
-* To monitor your GPU's performance and status, you can use either the **Windows Task Manager** (see the left side of the figure below) or the **Arc Control** application (see the right side of the figure below) :
- >
+```eval_rst
+.. note::
-* To monitor your GPU's performance and status, you can use either the **Windows Task Manager** (see the left side of the figure below) or the **Arc Control** application (see the right side of the figure below) :
- >  + The process could take around 10 minutes. After reboot, check for the **Intel Arc Control** application to verify the driver has been installed correctly. If the installation was successful, you should see the **Arc Control** interface similar to the figure below
+```
+
+
+
+To monitor your GPU's performance and status, you can use either the **Windows Task Manager** (see the left side of the figure below) or the **Arc Control** application (see the right side of the figure below)
+
+
## Install oneAPI
@@ -31,94 +40,284 @@ It applies to Intel Core Ultra and Core 12 - 14 gen integrated GPUs (iGPUs), as
pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0
``` -->
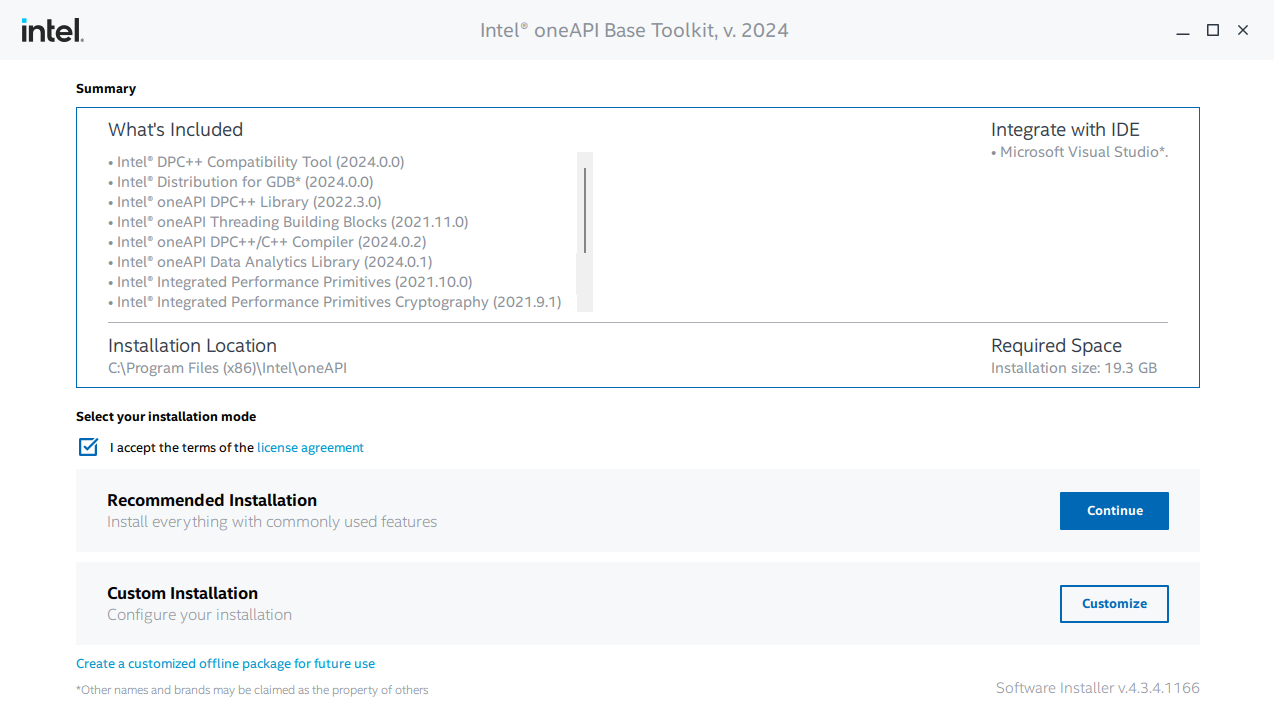
-* Download and install the [**Intel oneAPI Base Toolkit**](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html?operatingsystem=window&distributions=offline). During installation, you can continue with the default installation settings.
+Download and install the [**Intel oneAPI Base Toolkit**](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html?operatingsystem=window&distributions=offline). During installation, you can continue with the default installation settings.
- >
+ The process could take around 10 minutes. After reboot, check for the **Intel Arc Control** application to verify the driver has been installed correctly. If the installation was successful, you should see the **Arc Control** interface similar to the figure below
+```
+
+
+
+To monitor your GPU's performance and status, you can use either the **Windows Task Manager** (see the left side of the figure below) or the **Arc Control** application (see the right side of the figure below)
+
+
## Install oneAPI
@@ -31,94 +40,284 @@ It applies to Intel Core Ultra and Core 12 - 14 gen integrated GPUs (iGPUs), as
pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0
``` -->
-* Download and install the [**Intel oneAPI Base Toolkit**](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html?operatingsystem=window&distributions=offline). During installation, you can continue with the default installation settings.
+Download and install the [**Intel oneAPI Base Toolkit**](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html?operatingsystem=window&distributions=offline). During installation, you can continue with the default installation settings.
- >  +
+
+```eval_rst
+.. tip::
+
+ If the oneAPI installation hangs at the finalization step for more than 10 minutes, the error might be due to a problematic install of Visual Studio. Please reboot your computer and then launch the Visual Studio installer. If you see installation error messages, please repair your Visual Studio installation. After the repair is done, oneAPI installation is completed successfully.
+```
## Setup Python Environment
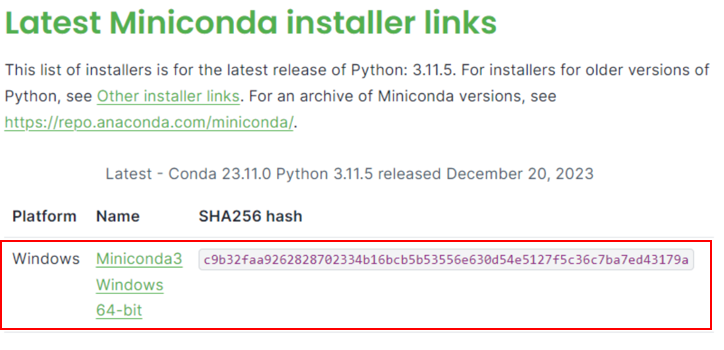
-* Visit [Miniconda installation page](https://docs.anaconda.com/free/miniconda/), download the **Miniconda installer for Windows**, and follow the instructions to complete the installation.
+Visit [Miniconda installation page](https://docs.anaconda.com/free/miniconda/), download the **Miniconda installer for Windows**, and follow the instructions to complete the installation.
- >
+
+
+```eval_rst
+.. tip::
+
+ If the oneAPI installation hangs at the finalization step for more than 10 minutes, the error might be due to a problematic install of Visual Studio. Please reboot your computer and then launch the Visual Studio installer. If you see installation error messages, please repair your Visual Studio installation. After the repair is done, oneAPI installation is completed successfully.
+```
## Setup Python Environment
-* Visit [Miniconda installation page](https://docs.anaconda.com/free/miniconda/), download the **Miniconda installer for Windows**, and follow the instructions to complete the installation.
+Visit [Miniconda installation page](https://docs.anaconda.com/free/miniconda/), download the **Miniconda installer for Windows**, and follow the instructions to complete the installation.
- >  +
+
+
+
 +
@@ -38,7 +38,13 @@ pip install -r requirements_cpu_only.txt
### Set Environment Variables
Configure oneAPI variables by running the following command in **Anaconda Prompt**:
-> Note: For more details about runtime configurations, refer to [this guide](https://bigdl.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#runtime-configuration):
+
+```eval_rst
+.. note::
+
+ For more details about runtime configurations, `refer to this guide `_
+```
+
```cmd
call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
```
@@ -50,7 +56,13 @@ set BIGDL_LLM_XMX_DISABLED=1
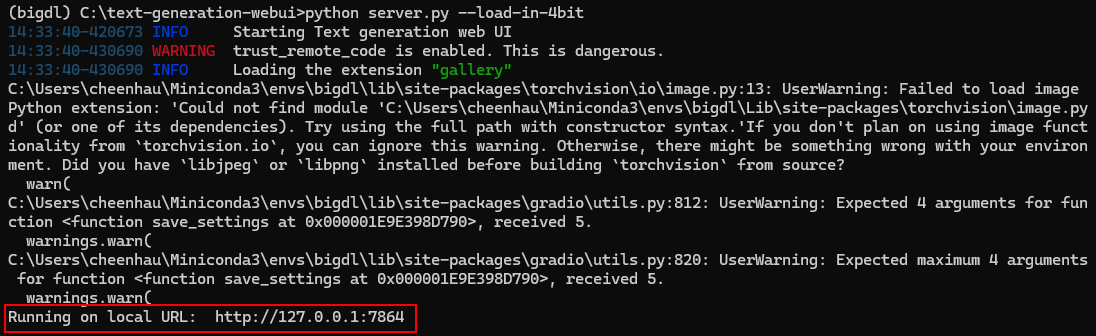
### Launch the Server
In **Anaconda Prompt** with the conda environment `llm` activated, navigate to the text-generation-webui folder and start the server using the following command:
- > Note: with `--load-in-4bit` option, the models will be optimized and run at 4-bit precision. For configuration for other formats and precisions, refer to [this link](https://github.com/intel-analytics/text-generation-webui?tab=readme-ov-file#32-optimizations-for-other-percisions).
+
+```eval_rst
+.. note::
+
+ with ``--load-in-4bit`` option, the models will be optimized and run at 4-bit precision. For configuration for other formats and precisions, refer to `this link `_
+```
+
```cmd
python server.py --load-in-4bit
```
@@ -60,7 +72,7 @@ Upon successful launch, URLs to access the WebUI will be displayed in the termin
-
+
@@ -38,7 +38,13 @@ pip install -r requirements_cpu_only.txt
### Set Environment Variables
Configure oneAPI variables by running the following command in **Anaconda Prompt**:
-> Note: For more details about runtime configurations, refer to [this guide](https://bigdl.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#runtime-configuration):
+
+```eval_rst
+.. note::
+
+ For more details about runtime configurations, `refer to this guide `_
+```
+
```cmd
call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
```
@@ -50,7 +56,13 @@ set BIGDL_LLM_XMX_DISABLED=1
### Launch the Server
In **Anaconda Prompt** with the conda environment `llm` activated, navigate to the text-generation-webui folder and start the server using the following command:
- > Note: with `--load-in-4bit` option, the models will be optimized and run at 4-bit precision. For configuration for other formats and precisions, refer to [this link](https://github.com/intel-analytics/text-generation-webui?tab=readme-ov-file#32-optimizations-for-other-percisions).
+
+```eval_rst
+.. note::
+
+ with ``--load-in-4bit`` option, the models will be optimized and run at 4-bit precision. For configuration for other formats and precisions, refer to `this link `_
+```
+
```cmd
python server.py --load-in-4bit
```
@@ -60,7 +72,7 @@ Upon successful launch, URLs to access the WebUI will be displayed in the termin
-  +
## 4. Using the WebUI
@@ -69,11 +81,11 @@ Upon successful launch, URLs to access the WebUI will be displayed in the termin
Place Huggingface models in `C:\text-generation-webui\models` by either copying locally or downloading via the WebUI. To download, navigate to the **Model** tab, enter the model's huggingface id (for instance, `Qwen/Qwen-7B-Chat`) in the **Download model or LoRA** section, and click **Download**, as illustrated below.
-
+
## 4. Using the WebUI
@@ -69,11 +81,11 @@ Upon successful launch, URLs to access the WebUI will be displayed in the termin
Place Huggingface models in `C:\text-generation-webui\models` by either copying locally or downloading via the WebUI. To download, navigate to the **Model** tab, enter the model's huggingface id (for instance, `Qwen/Qwen-7B-Chat`) in the **Download model or LoRA** section, and click **Download**, as illustrated below.
-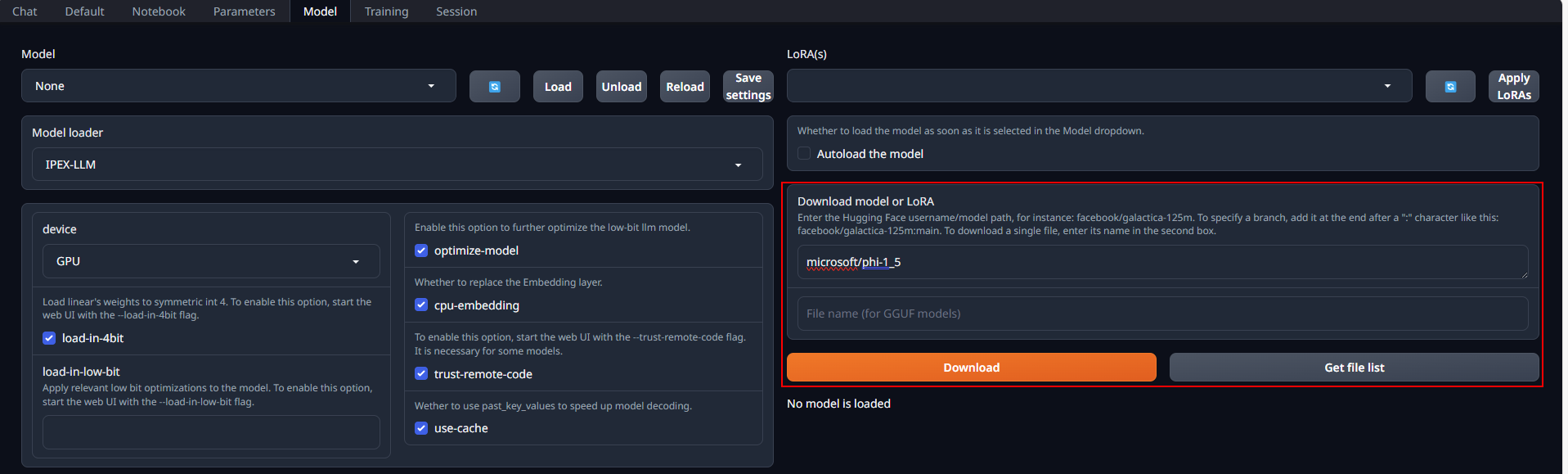 +
After copying or downloading the models, click on the blue **refresh** button to update the **Model** drop-down menu. Then, choose your desired model from the newly updated list.
-
+
After copying or downloading the models, click on the blue **refresh** button to update the **Model** drop-down menu. Then, choose your desired model from the newly updated list.
-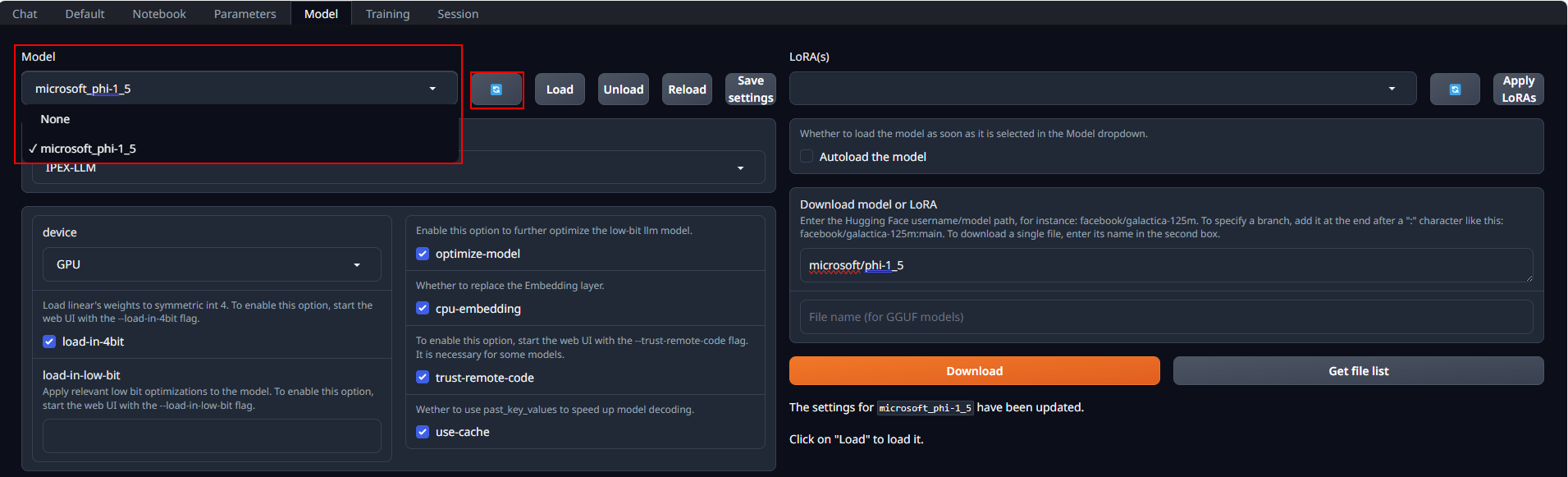 +
### Load Model
@@ -82,7 +94,7 @@ Default settings are recommended for most users. Click **Load** to activate the
If everything goes well, you will get a message as shown below.
-
+
### Load Model
@@ -82,7 +94,7 @@ Default settings are recommended for most users. Click **Load** to activate the
If everything goes well, you will get a message as shown below.
-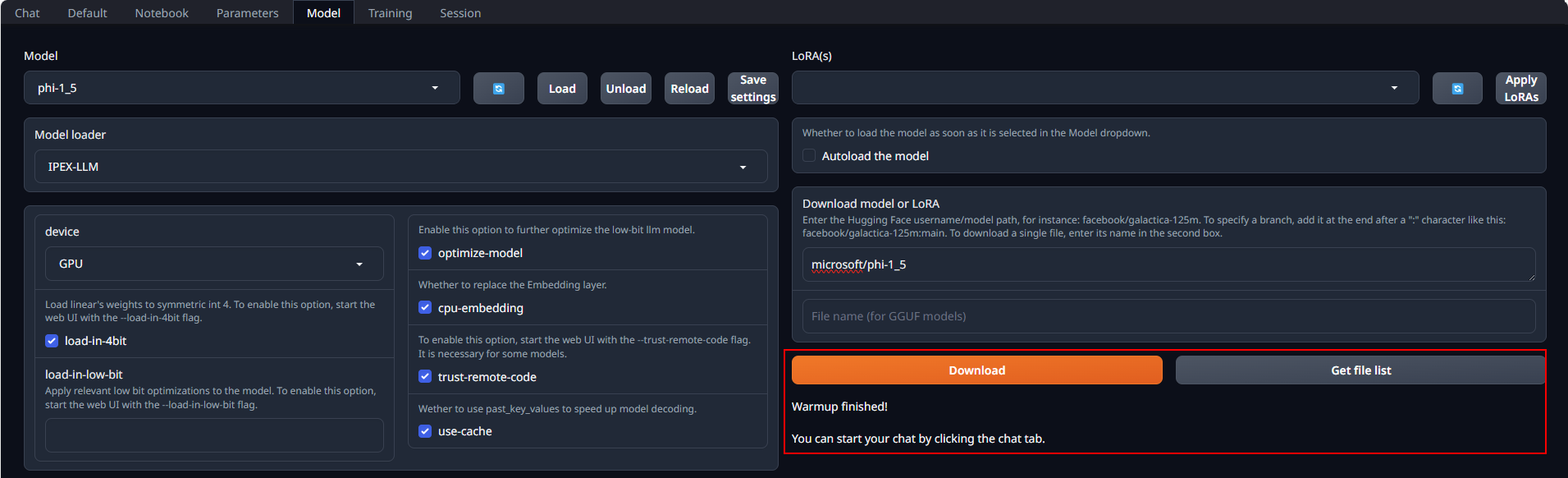 +
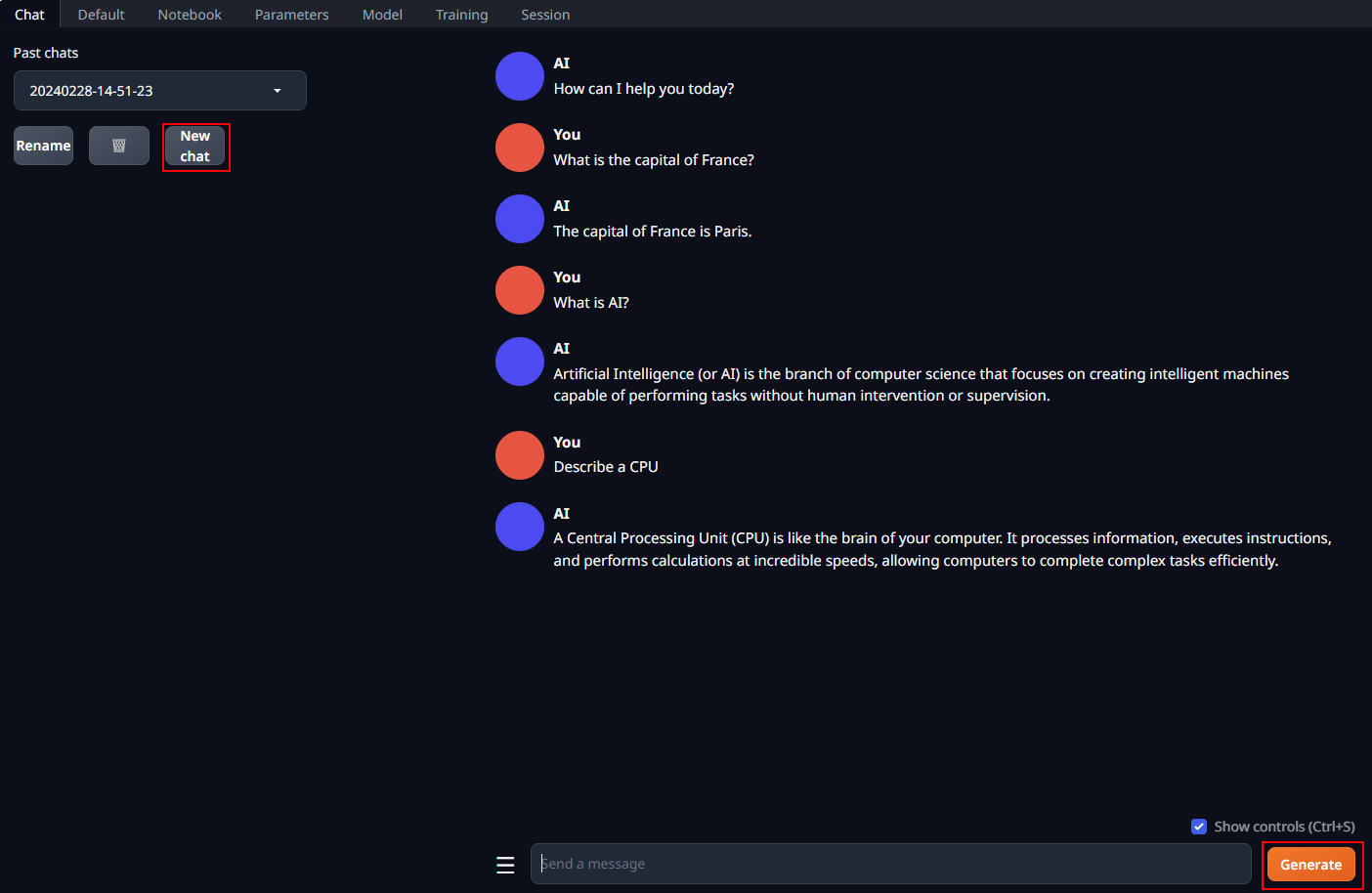
@@ -92,7 +104,7 @@ In the **Chat** tab, start new conversations with **New chat**.
Enter prompts into the textbox at the bottom and press the **Generate** button to receive responses.
-
+
+
@@ -92,7 +104,7 @@ In the **Chat** tab, start new conversations with **New chat**.
Enter prompts into the textbox at the bottom and press the **Generate** button to receive responses.
-
+