diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/benchmark_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/benchmark_quickstart.md
index 84d80dbd..6a2aa5ac 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/benchmark_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/benchmark_quickstart.md
@@ -1,6 +1,6 @@
# Run Performance Benchmarking with IPEX-LLM
-We can do benchmarking for IPEX-LLM on Intel CPUs and GPUs using the benchmark scripts we provide.
+We can perform benchmarking for IPEX-LLM on Intel CPUs and GPUs using the benchmark scripts we provide.
## Prepare The Environment
@@ -13,7 +13,7 @@ pip install omegaconf
## Prepare The Scripts
-Navigate to your local workspace and then download IPEX-LLM from GitHub. Modify the `config.yaml` under `all-in-one` folder for your own benchmark configurations.
+Navigate to your local workspace and then download IPEX-LLM from GitHub. Modify the `config.yaml` under `all-in-one` folder for your benchmark configurations.
```
cd your/local/workspace
@@ -47,15 +47,15 @@ Some parameters in the yaml file that you can configure:
- warm_up: The number of runs as warmup trials, executed before performance benchmarking.
- num_trials: The number of runs for performance benchmarking. The final benchmark result would be the average of all the trials.
- low_bit: The low_bit precision you want to convert to for benchmarking.
-- batch_size: The number of samples on which the models makes predictions in one forward pass.
+- batch_size: The number of samples on which the models make predictions in one forward pass.
- in_out_pairs: Input sequence length and output sequence length combined by '-'.
- test_api: Use different test functions on different machines.
- `transformer_int4_gpu` on Intel GPU for Linux
- `transformer_int4_gpu_win` on Intel GPU for Windows
- `transformer_int4` on Intel CPU
-- cpu_embedding: Whether to put embedding on CPU (only avaiable now for windows gpu related test_api).
+- cpu_embedding: Whether to put embedding on CPU (only available now for windows gpu related test_api).
-Remark: If you want to benchmark the performance without warmup, you can set `warm_up: 0` as well as `num_trials: 1` in `config.yaml`, and run each single model and in_out_pair separately.
+Remark: If you want to benchmark the performance without warmup, you can set `warm_up: 0` and `num_trials: 1` in `config.yaml`, and run each single model and in_out_pair separately.
## Run on Windows
@@ -148,4 +148,4 @@ Please refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overvie
## Result
-After the benchmarking completes, you can obtain a CSV result file under the current folder. You can mainly look at the results of columns `1st token avg latency (ms)` and `2+ avg latency (ms/token)` for the benchmark results. You can also check whether the column `actual input/output tokens` is consistent with the column `input/output tokens` and whether the parameters you specified in `config.yaml` have been successfully applied in the benchmarking.
+After the benchmarking is completed, you can obtain a CSV result file under the current folder. You can mainly look at the results of columns `1st token avg latency (ms)` and `2+ avg latency (ms/token)` for the benchmark results. You can also check whether the column `actual input/output tokens` is consistent with the column `input/output tokens` and whether the parameters you specified in `config.yaml` have been successfully applied in the benchmarking.
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/bigdl_llm_migration.md b/docs/readthedocs/source/doc/LLM/Quickstart/bigdl_llm_migration.md
index 420fc9f6..a1ef5051 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/bigdl_llm_migration.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/bigdl_llm_migration.md
@@ -8,7 +8,7 @@ This guide helps you migrate your `bigdl-llm` application to use `ipex-llm`.
.. note::
This step assumes you have already installed `bigdl-llm`.
```
-You need to uninstall `bigdl-llm` and install `ipex-llm`With your `bigdl-llm` conda envionment activated, exeucte the folloiwng command according to your device type and location:
+You need to uninstall `bigdl-llm` and install `ipex-llm`With your `bigdl-llm` conda environment activated, execute the following command according to your device type and location:
### For CPU
@@ -37,7 +37,6 @@ Choose either US or CN website for `extra-index-url`:
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/
```
-
## Migrate `bigdl-llm` code to `ipex-llm`
There are two options to migrate `bigdl-llm` code to `ipex-llm`.
@@ -62,4 +61,3 @@ model = AutoModelForCausalLM.from_pretrained(model_path,
load_in_4bit=True,
trust_remote_code=True)
```
-
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md
index d9d9aacb..1d465f3e 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md
@@ -1,6 +1,6 @@
# Run Local RAG using Langchain-Chatchat on Intel CPU and GPU
-[chatchat-space/Langchain-Chatchat](https://github.com/chatchat-space/Langchain-Chatchat) is a Knowledge Base QA application using RAG pipeline; by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily run ***local RAG pipelines*** using [Langchain-Chatchat](https://github.com/intel-analytics/Langchain-Chatchat) with LLMs and Embedding models on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max);
+[chatchat-space/Langchain-Chatchat](https://github.com/chatchat-space/Langchain-Chatchat) is a Knowledge Base QA application using RAG pipeline; by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily run ***local RAG pipelines*** using [Langchain-Chatchat](https://github.com/intel-analytics/Langchain-Chatchat) with LLMs and Embedding models on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max).
*See the demos of running LLaMA2-7B (English) and ChatGLM-3-6B (Chinese) on an Intel Core Ultra laptop below.*
@@ -15,8 +15,7 @@
-
->You can change the UI language in the left-side menu. We currently support **English** and **简体中文** (see video demos below).
+>You can change the UI language in the left-side menu. We currently support **English** and **简体中文** (see video demos below).
## Langchain-Chatchat Architecture
@@ -26,8 +25,6 @@ See the Langchain-Chatchat architecture below ([source](https://github.com/chatc
## Quickstart
-
-
### Install and Run
Follow the guide that corresponds to your specific system and device from the links provided below:
@@ -43,15 +40,14 @@ Follow the guide that corresponds to your specific system and device from the li
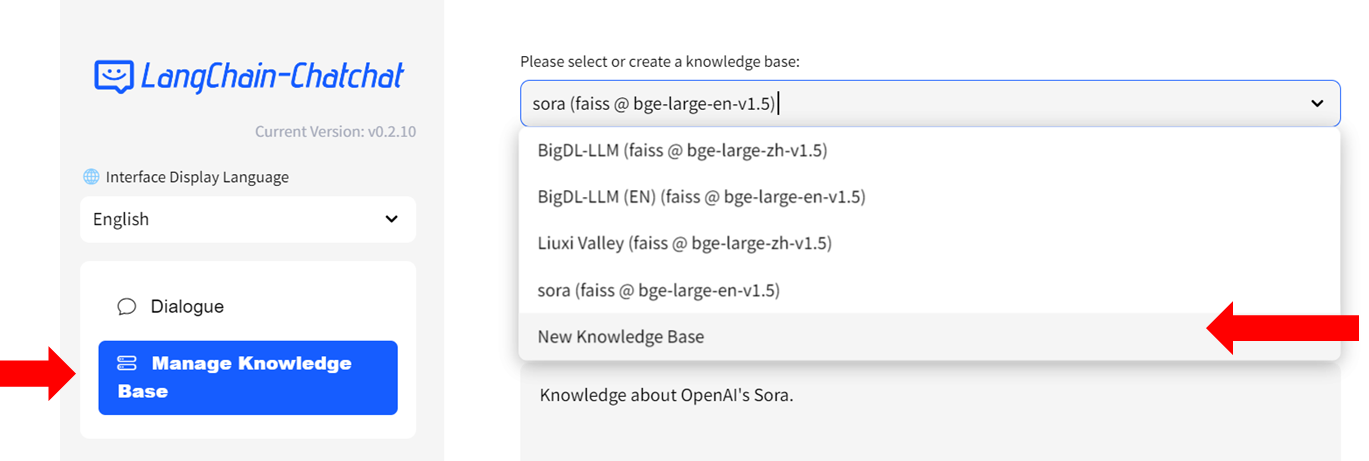
- Select `Manage Knowledge Base` from the menu on the left, then choose `New Knowledge Base` from the dropdown menu on the right side.
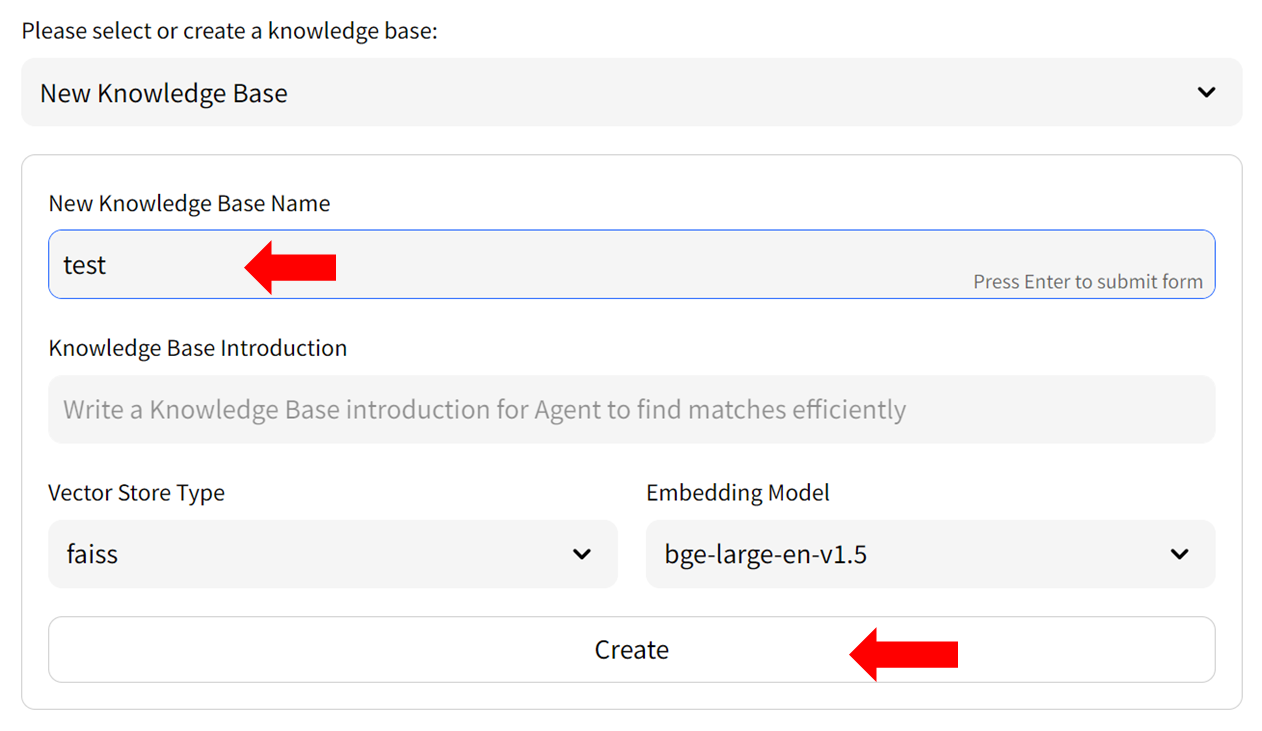
-- Fill in the name of your new knowledge base (example: "test") and press the `Create` button. Adjust any other settings as needed.
+- Fill in the name of your new knowledge base (example: "test") and press the `Create` button. Adjust any other settings as needed.
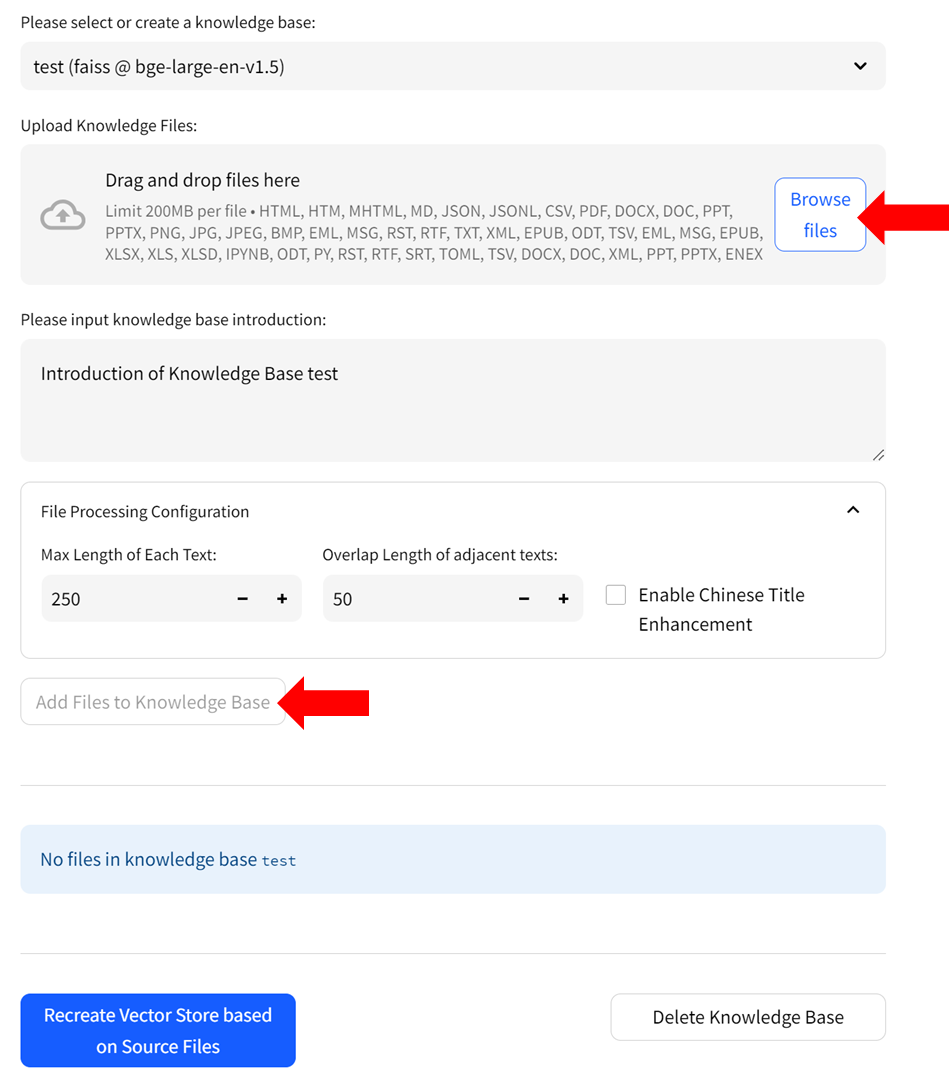
- Upload knowledge files from your computer and allow some time for the upload to complete. Once finished, click on `Add files to Knowledge Base` button to build the vector store. Note: this process may take several minutes.
-
#### Step 2: Chat with RAG
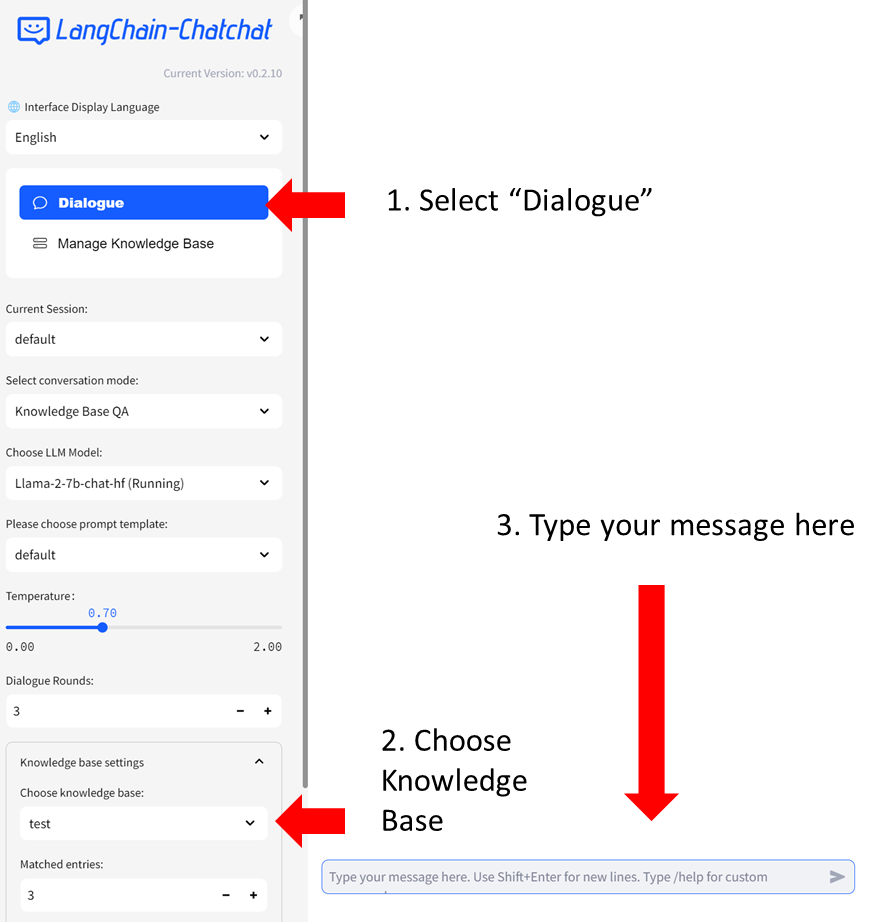
-You can now click `Dialogue` on the left-side menu to return to the chat UI. Then in `Knowledge base settings` menu, choose the Knowledge Base you just created, e.g, "test". Now you can start chatting.
+You can now click `Dialogue` on the left-side menu to return to the chat UI. Then in `Knowledge base settings` menu, choose the Knowledge Base you just created, e.g, "test". Now you can start chatting.
@@ -59,8 +55,6 @@ You can now click `Dialogue` on the left-side menu to return to the chat UI. The
For more information about how to use Langchain-Chatchat, refer to Official Quickstart guide in [English](./README_en.md#), [Chinese](./README_chs.md#), or the [Wiki](https://github.com/chatchat-space/Langchain-Chatchat/wiki/).
-
-
### Trouble Shooting & Tips
#### 1. Version Compatibility
@@ -72,4 +66,4 @@ pip install --pre --upgrade ipex-llm[xpu] -f https://developer.intel.com/ipex-wh
#### 2. Prompt Templates
-In the left-side menu, you have the option to choose a prompt template. There're several pre-defined templates - those ending with '_cn' are Chinese templates, and those ending with '_en' are English templates. You can also define your own prompt templates in `configs/prompt_config.py`. Remember to restart the service to enable these changes.
+In the left-side menu, you have the option to choose a prompt template. There're several pre-defined templates - those ending with '_cn' are Chinese templates, and those ending with '_en' are English templates. You can also define your own prompt templates in `configs/prompt_config.py`. Remember to restart the service to enable these changes.
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
index d5176180..fbec9cb2 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
@@ -16,13 +16,9 @@ See the demos of using Continue with [Mistral-7B-Instruct-v0.1](https://huggingf
-
-
-
## Quickstart
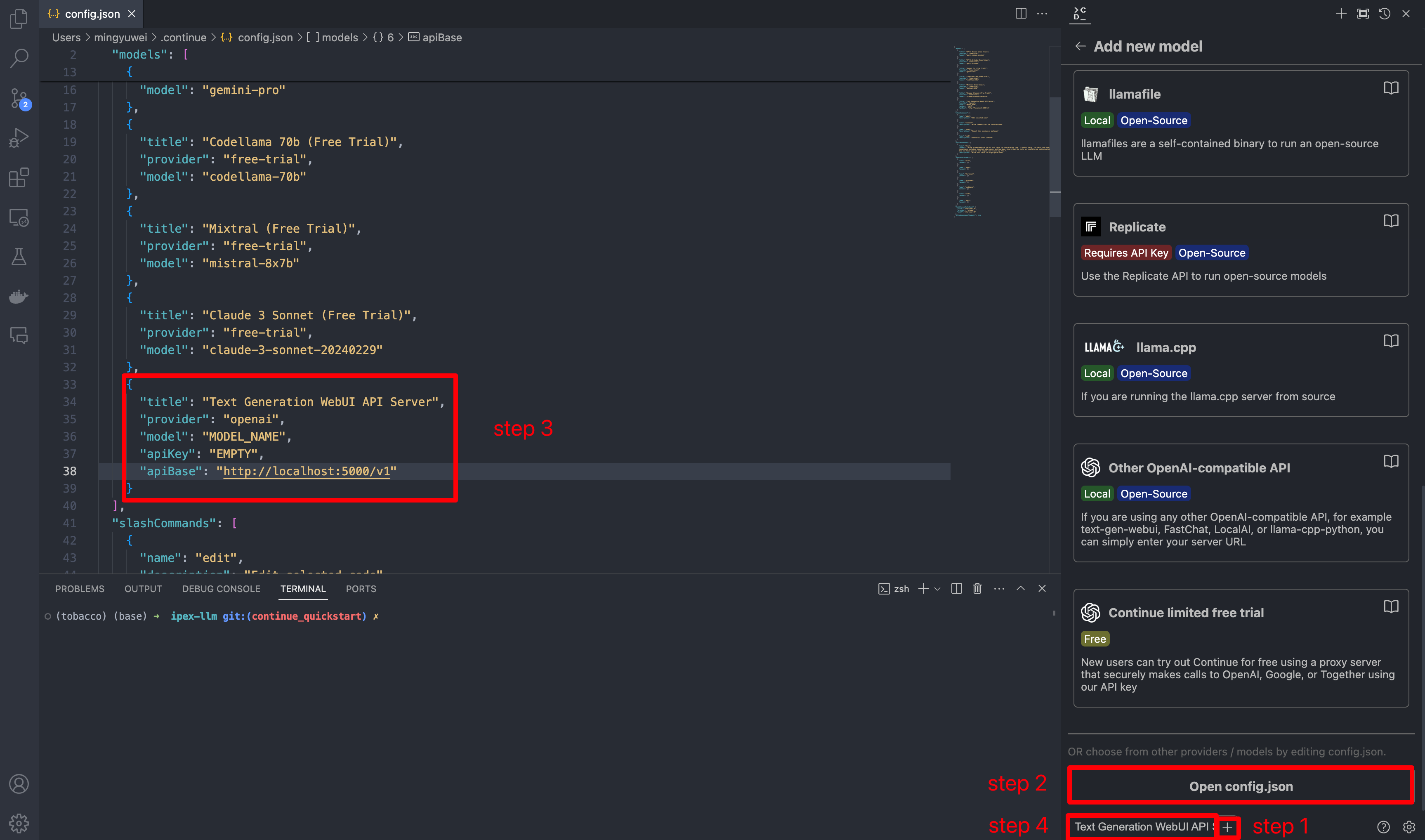
-This guide walks you through setting up and running **Continue** within _Visual Studio Code_, empowered by local large language models served via [Text Generation WebUI](https://github.com/intel-analytics/text-generation-webui/) with `ipex-llm` optimizations.
-
+This guide walks you through setting up and running **Continue** within _Visual Studio Code_, empowered by local large language models served via [Text Generation WebUI](https://github.com/intel-analytics/text-generation-webui/) with `ipex-llm` optimizations.
### 1. Install and Run Text Generation WebUI
@@ -34,28 +30,25 @@ Visit [Run Text Generation WebUI Quickstart Guide](webui_quickstart.html), and f
```
- Remember to launch the server **with API service** as specified in [Launch the Server](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#launch-the-server)
-
-
### 2. Use WebUI to Load Model
#### Access the WebUI
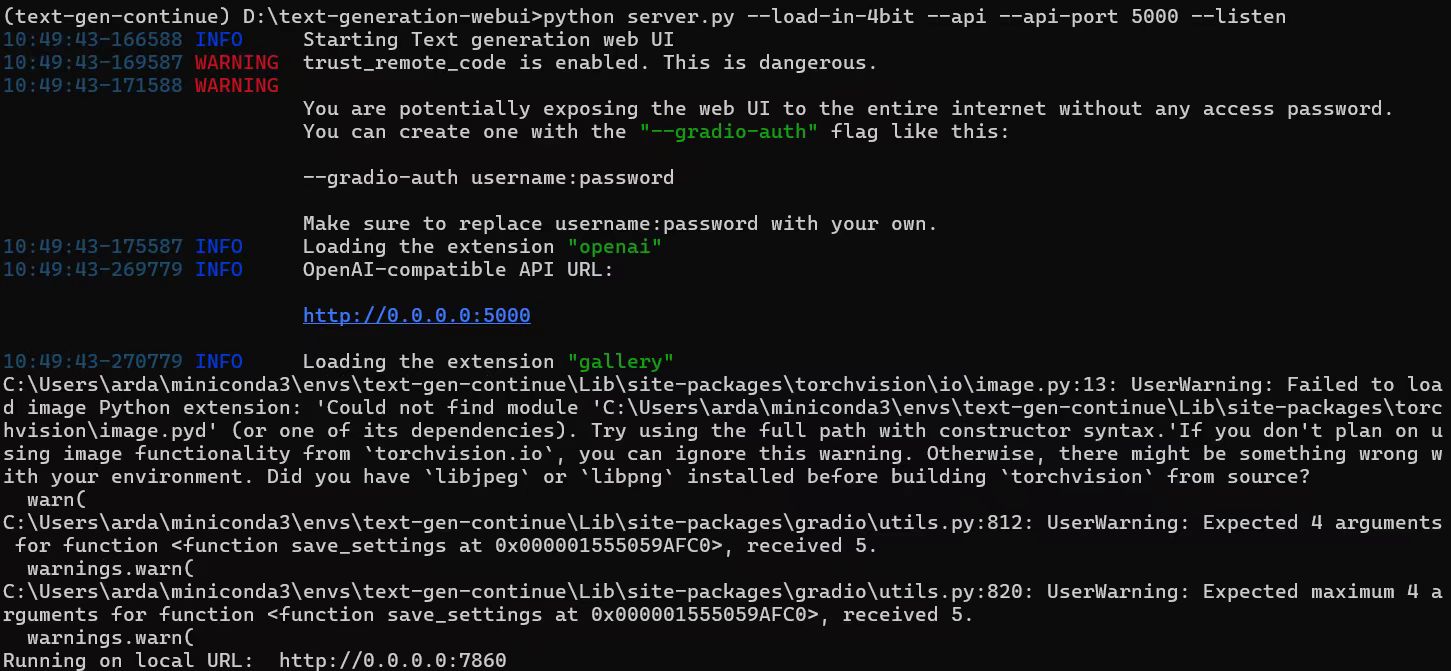
-Upon successful launch, URLs to access the WebUI will be displayed in the terminal as shown below. Open the provided local URL in your browser to interact with the WebUI.
+Upon successful launch, URLs to access the WebUI will be displayed in the terminal as shown below. Open the provided local URL in your browser to interact with the WebUI.
 -
#### Model Download and Loading
-Here's a list of models that can be used for coding copilot on local PC.
+Here's a list of models that can be used for coding copilot on local PC.
- Code Llama:
- WizardCoder
- Mistral
- StarCoder
- DeepSeek Coder
-Follow the steps in [Model Download](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#model-download) and [Load Model](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#load-model) to download and load your coding model.
+Follow the steps in [Model Download](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#model-download) and [Load Model](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#load-model) to download and load your coding model.
```eval_rst
.. note::
@@ -63,8 +56,6 @@ Follow the steps in [Model Download](https://ipex-llm.readthedocs.io/en/latest/d
If you don't need to use the API service anymore, you can follow the instructions in refer to `Exit WebUI `_ to stop the service.
```
-
-
### 3. Install `Continue` Extension
1. Click `Install` on the [Continue extension in the Visual Studio Marketplace](https://marketplace.visualstudio.com/items?itemName=Continue.continue)
2. This will open the Continue extension page in VS Code, where you will need to click `Install` again
@@ -80,8 +71,6 @@ Follow the steps in [Model Download](https://ipex-llm.readthedocs.io/en/latest/d
Note: We strongly recommend moving Continue to VS Code's right sidebar. This helps keep the file explorer open while using Continue, and the sidebar can be toggled with a simple keyboard shortcut.
```
-
-
### 4. Configure `Continue`
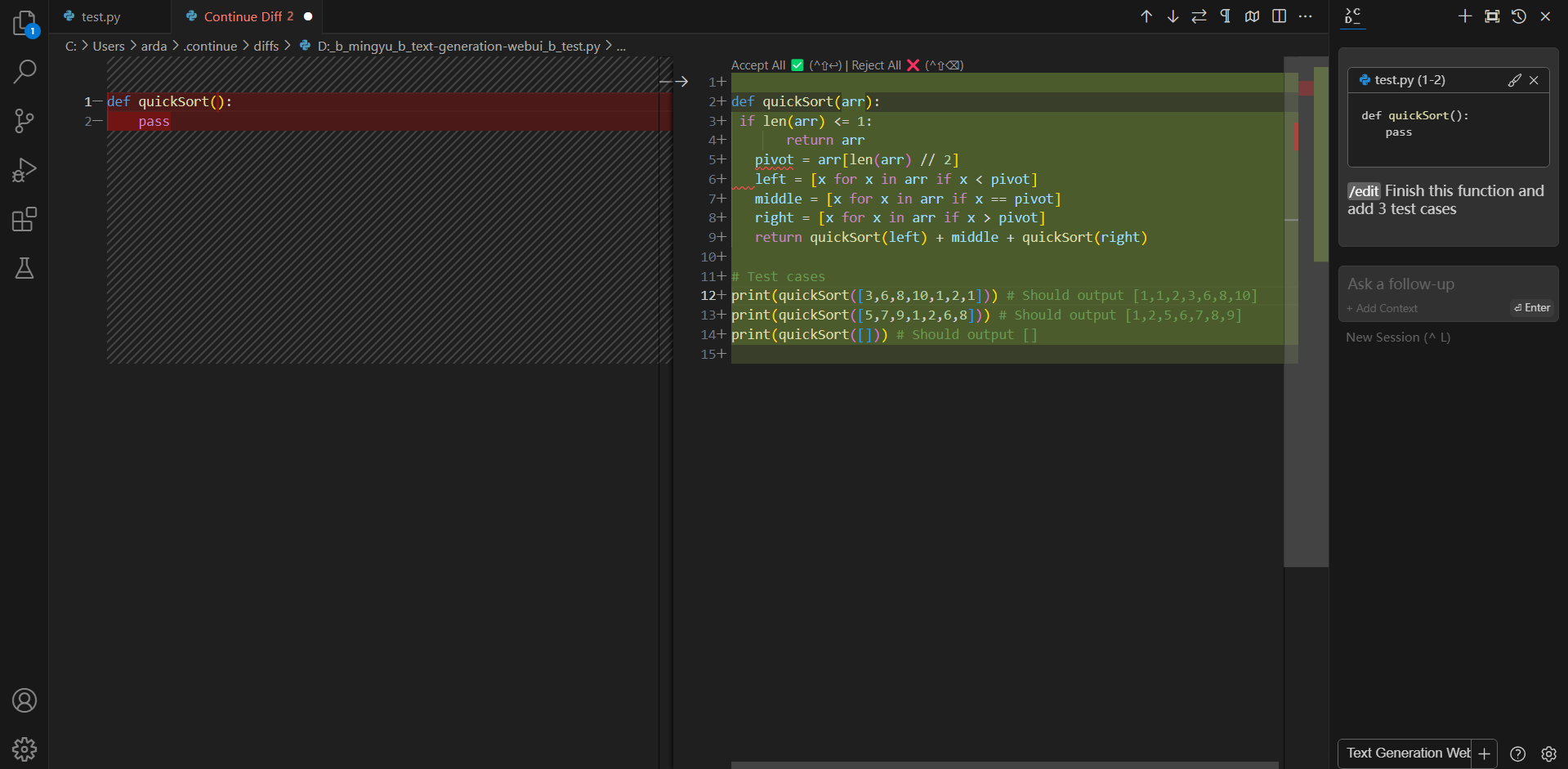
@@ -122,13 +111,8 @@ You can ask Continue to edit your highlighted code with the command `/edit`.
-
#### Model Download and Loading
-Here's a list of models that can be used for coding copilot on local PC.
+Here's a list of models that can be used for coding copilot on local PC.
- Code Llama:
- WizardCoder
- Mistral
- StarCoder
- DeepSeek Coder
-Follow the steps in [Model Download](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#model-download) and [Load Model](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#load-model) to download and load your coding model.
+Follow the steps in [Model Download](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#model-download) and [Load Model](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#load-model) to download and load your coding model.
```eval_rst
.. note::
@@ -63,8 +56,6 @@ Follow the steps in [Model Download](https://ipex-llm.readthedocs.io/en/latest/d
If you don't need to use the API service anymore, you can follow the instructions in refer to `Exit WebUI `_ to stop the service.
```
-
-
### 3. Install `Continue` Extension
1. Click `Install` on the [Continue extension in the Visual Studio Marketplace](https://marketplace.visualstudio.com/items?itemName=Continue.continue)
2. This will open the Continue extension page in VS Code, where you will need to click `Install` again
@@ -80,8 +71,6 @@ Follow the steps in [Model Download](https://ipex-llm.readthedocs.io/en/latest/d
Note: We strongly recommend moving Continue to VS Code's right sidebar. This helps keep the file explorer open while using Continue, and the sidebar can be toggled with a simple keyboard shortcut.
```
-
-
### 4. Configure `Continue`
@@ -122,13 +111,8 @@ You can ask Continue to edit your highlighted code with the command `/edit`.
 -
### Troubleshooting
#### Failed to load the extension `openai`
If you encounter `TypeError: unsupported operand type(s) for |: 'type' and 'NoneType'` when you run `python server.py --load-in-4bit --api`, please make sure you are using `Python 3.11` instead of lower versions.
-
-
-
-
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md b/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
index fd5a52c3..ee066e33 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
@@ -1,14 +1,13 @@
# Install IPEX-LLM in Docker on Windows with Intel GPU
-This guide demonstrates how to install IPEX-LLM in Docker on Windows with Intel GPUs.
+This guide demonstrates how to install IPEX-LLM in Docker on Windows with Intel GPUs.
It applies to Intel Core Core 12 - 14 gen integrated GPUs (iGPUs) and Intel Arc Series GPU.
-> Note:
+> Note:
> - WSL2 support is required during the installation process.
> - This installation method requires at least 35GB of free disk space on C drive.
-
## Install Docker on Windows
**Getting Started with Docker:**
1. **For New Users:**
@@ -16,7 +15,7 @@ It applies to Intel Core Core 12 - 14 gen integrated GPUs (iGPUs) and Intel Arc
- Detailed installation instructions for Windows, including steps for enabling WSL2, can be found on the [Docker Desktop for Windows installation page](https://docs.docker.com/desktop/install/windows-install/).
2. **Detailed installation Steps for Windows Users:**
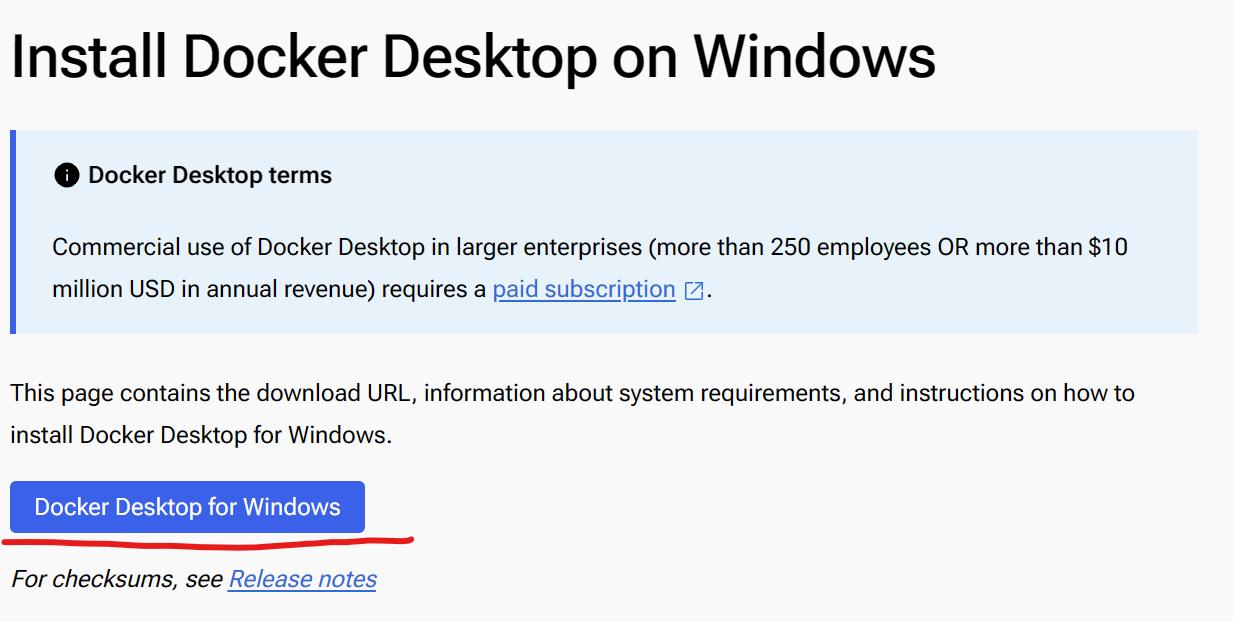
- - **Download and install [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/)**: The installation could take around 5 minutes, and a reboot will be required after installation.
+ - **Download and install [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/)**: The installation could take around 5 minutes, and a reboot will be required after installation.
-
### Troubleshooting
#### Failed to load the extension `openai`
If you encounter `TypeError: unsupported operand type(s) for |: 'type' and 'NoneType'` when you run `python server.py --load-in-4bit --api`, please make sure you are using `Python 3.11` instead of lower versions.
-
-
-
-
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md b/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
index fd5a52c3..ee066e33 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
@@ -1,14 +1,13 @@
# Install IPEX-LLM in Docker on Windows with Intel GPU
-This guide demonstrates how to install IPEX-LLM in Docker on Windows with Intel GPUs.
+This guide demonstrates how to install IPEX-LLM in Docker on Windows with Intel GPUs.
It applies to Intel Core Core 12 - 14 gen integrated GPUs (iGPUs) and Intel Arc Series GPU.
-> Note:
+> Note:
> - WSL2 support is required during the installation process.
> - This installation method requires at least 35GB of free disk space on C drive.
-
## Install Docker on Windows
**Getting Started with Docker:**
1. **For New Users:**
@@ -16,7 +15,7 @@ It applies to Intel Core Core 12 - 14 gen integrated GPUs (iGPUs) and Intel Arc
- Detailed installation instructions for Windows, including steps for enabling WSL2, can be found on the [Docker Desktop for Windows installation page](https://docs.docker.com/desktop/install/windows-install/).
2. **Detailed installation Steps for Windows Users:**
- - **Download and install [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/)**: The installation could take around 5 minutes, and a reboot will be required after installation.
+ - **Download and install [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/)**: The installation could take around 5 minutes, and a reboot will be required after installation.
 @@ -25,7 +24,7 @@ It applies to Intel Core Core 12 - 14 gen integrated GPUs (iGPUs) and Intel Arc
- - **Install WSL2**: Open PowerShell or Windows Command Prompt in administrator mode by right-clicking and selecting "Run as administrator", enter:
+ - **Install WSL2**: Open PowerShell or Windows Command Prompt in administrator mode by right-clicking and selecting "Run as administrator", enter:
```bash
wsl --install
```
@@ -117,7 +116,7 @@ root@docker-desktop:/# sycl-ls
Human: What is AI?
IPEX-LLM:
AI, or Artificial Intelligence, refers to the development of computer systems or machines that can perform tasks that typically require human intelligence. These systems are designed to learn from data and make decisions, or take actions, based on that data.
-```
+```
If your machine has both an integrated GPU (iGPU) and a dedicated GPU (dGPU) like ARC, you may encounter the following issue:
```bash
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md
index e8cb3cb3..2003360e 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md
@@ -1,6 +1,6 @@
-# Run Llama 3 on Intel GPU using llama.cpp and ollama with IPEX-LLM
+# Run Llama 3 on Intel GPU using llama.cpp and ollama with IPEX-LLM
-[Llama 3](https://llama.meta.com/llama3/) is the latest Large Language Models released by [Meta](https://llama.meta.com/) which provides state-of-the-art performance and excels at language nuances, contextual understanding, and complex tasks like translation and dialogue generation.
+[Llama 3](https://llama.meta.com/llama3/) is the latest Large Language Models released by [Meta](https://llama.meta.com/) which provides state-of-the-art performance and excels at language nuances, contextual understanding, and complex tasks like translation and dialogue generation.
Now, you can easily run Llama 3 on Intel GPU using `llama.cpp` and `Ollama` with IPEX-LLM.
@@ -74,7 +74,7 @@ Under your current directory, exceuting below command to do inference with Llama
main -ngl 33 -m /Meta-Llama-3-8B-Instruct-Q4_K_M.gguf -n 32 --prompt "Once upon a time, there existed a little girl who liked to have adventures. She wanted to go to places and meet new people, and have fun doing something" -e -ngl 33 --color --no-mmap
```
-Under your current directory, you can also exceute below command to have interative chat with Llama3:
+Under your current directory, you can also execute below command to have interactive chat with Llama3:
```eval_rst
.. tabs::
@@ -96,7 +96,6 @@ Under your current directory, you can also exceute below command to have interat
Below is a sample output on Intel Arc GPU:
@@ -25,7 +24,7 @@ It applies to Intel Core Core 12 - 14 gen integrated GPUs (iGPUs) and Intel Arc
- - **Install WSL2**: Open PowerShell or Windows Command Prompt in administrator mode by right-clicking and selecting "Run as administrator", enter:
+ - **Install WSL2**: Open PowerShell or Windows Command Prompt in administrator mode by right-clicking and selecting "Run as administrator", enter:
```bash
wsl --install
```
@@ -117,7 +116,7 @@ root@docker-desktop:/# sycl-ls
Human: What is AI?
IPEX-LLM:
AI, or Artificial Intelligence, refers to the development of computer systems or machines that can perform tasks that typically require human intelligence. These systems are designed to learn from data and make decisions, or take actions, based on that data.
-```
+```
If your machine has both an integrated GPU (iGPU) and a dedicated GPU (dGPU) like ARC, you may encounter the following issue:
```bash
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md
index e8cb3cb3..2003360e 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md
@@ -1,6 +1,6 @@
-# Run Llama 3 on Intel GPU using llama.cpp and ollama with IPEX-LLM
+# Run Llama 3 on Intel GPU using llama.cpp and ollama with IPEX-LLM
-[Llama 3](https://llama.meta.com/llama3/) is the latest Large Language Models released by [Meta](https://llama.meta.com/) which provides state-of-the-art performance and excels at language nuances, contextual understanding, and complex tasks like translation and dialogue generation.
+[Llama 3](https://llama.meta.com/llama3/) is the latest Large Language Models released by [Meta](https://llama.meta.com/) which provides state-of-the-art performance and excels at language nuances, contextual understanding, and complex tasks like translation and dialogue generation.
Now, you can easily run Llama 3 on Intel GPU using `llama.cpp` and `Ollama` with IPEX-LLM.
@@ -74,7 +74,7 @@ Under your current directory, exceuting below command to do inference with Llama
main -ngl 33 -m /Meta-Llama-3-8B-Instruct-Q4_K_M.gguf -n 32 --prompt "Once upon a time, there existed a little girl who liked to have adventures. She wanted to go to places and meet new people, and have fun doing something" -e -ngl 33 --color --no-mmap
```
-Under your current directory, you can also exceute below command to have interative chat with Llama3:
+Under your current directory, you can also execute below command to have interactive chat with Llama3:
```eval_rst
.. tabs::
@@ -96,7 +96,6 @@ Under your current directory, you can also exceute below command to have interat
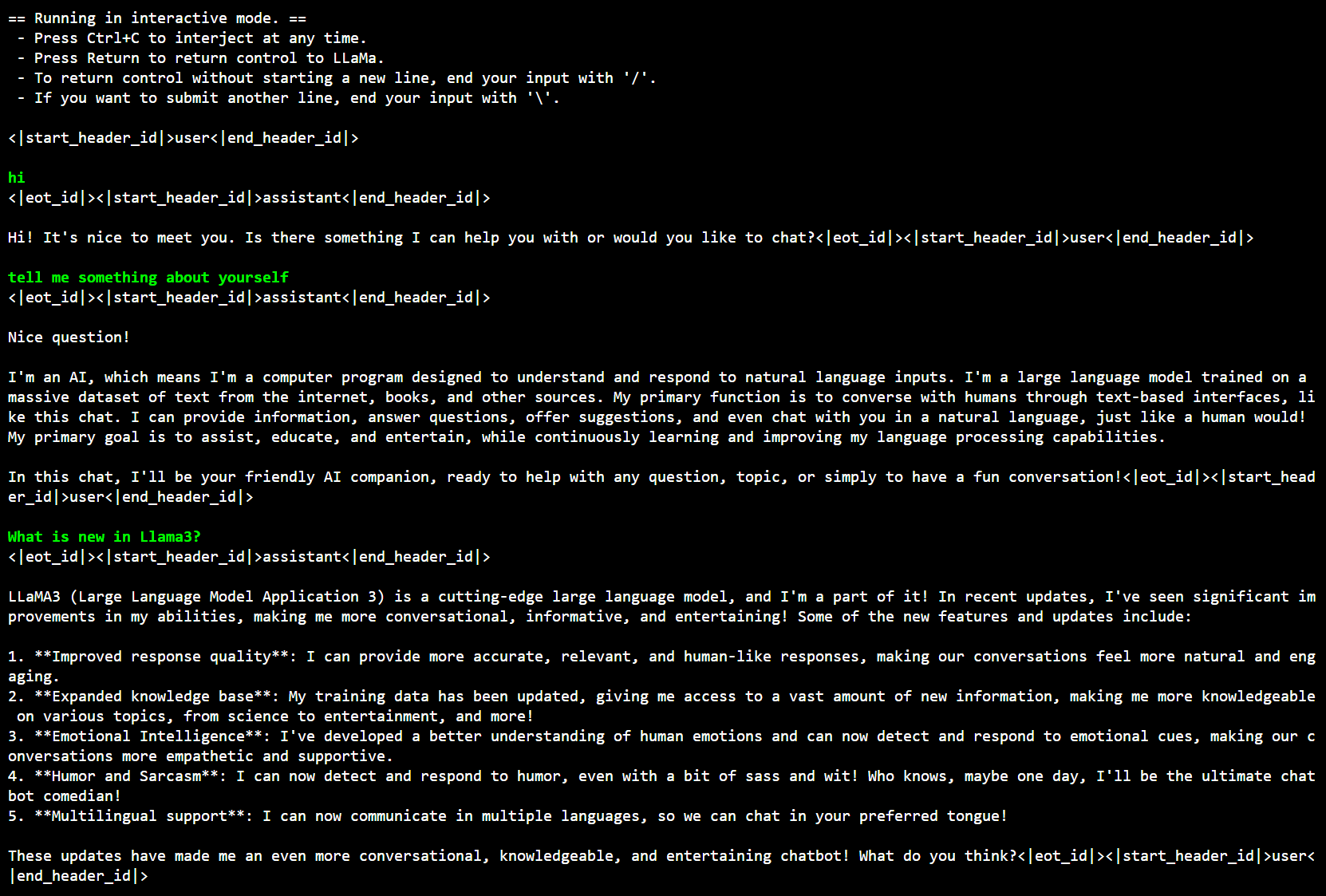
Below is a sample output on Intel Arc GPU:
 -
### 2. Run Llama3 using Ollama
#### 2.1 Install IPEX-LLM for Ollama and Initialize
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
index 1ecd5fd4..9fc7e02b 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
@@ -10,7 +10,7 @@ See the demo of running LLaMA2-7B on Intel Arc GPU below.
This quickstart guide walks you through installing and running `llama.cpp` with `ipex-llm`.
### 0 Prerequisites
-IPEX-LLM's support for `llama.cpp` now is avaliable for Linux system and Windows system.
+IPEX-LLM's support for `llama.cpp` now is available for Linux system and Windows system.
#### Linux
For Linux system, we recommend Ubuntu 20.04 or later (Ubuntu 22.04 is preferred).
@@ -272,4 +272,4 @@ If you encounter `main: failed to quantize model from xxx`, please make sure you
If your program hang after `llm_load_tensors: SYCL_Host buffer size = xx.xx MiB`, you can add `--no-mmap` in your command.
#### How to set `-ngl` parameter
-`-ngl` means the number of layers to store in VRAM. If your VRAM is enough, we recommend putting all layers on GPU, you can just set `-ngl` to a large number like 999 to achieve this goal.
\ No newline at end of file
+`-ngl` means the number of layers to store in VRAM. If your VRAM is enough, we recommend putting all layers on GPU, you can just set `-ngl` to a large number like 999 to achieve this goal.
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
index b911c5d6..695a41df 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
@@ -10,13 +10,13 @@ See the demo of running LLaMA2-7B on Intel Arc GPU below.
### 1 Install IPEX-LLM for Ollama
-IPEX-LLM's support for `ollama` now is avaliable for Linux system and Windows system.
+IPEX-LLM's support for `ollama` now is available for Linux system and Windows system.
-Visit [Run llama.cpp with IPEX-LLM on Intel GPU Guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html), and follow the instructions in section [Prerequisites](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#prerequisites) to setup and section [Install IPEX-LLM cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#install-ipex-llm-for-llama-cpp) to install the IPEX-LLM with Ollama binaries.
+Visit [Run llama.cpp with IPEX-LLM on Intel GPU Guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html), and follow the instructions in section [Prerequisites](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#prerequisites) to setup and section [Install IPEX-LLM cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#install-ipex-llm-for-llama-cpp) to install the IPEX-LLM with Ollama binaries.
**After the installation, you should have created a conda environment, named `llm-cpp` for instance, for running `ollama` commands with IPEX-LLM.**
-### 2. Initialize Ollama
+### 2. Initialize Ollama
Activate the `llm-cpp` conda environment and initialize Ollama by executing the commands below. A symbolic link to `ollama` will appear in your current directory.
-
### 2. Run Llama3 using Ollama
#### 2.1 Install IPEX-LLM for Ollama and Initialize
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
index 1ecd5fd4..9fc7e02b 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
@@ -10,7 +10,7 @@ See the demo of running LLaMA2-7B on Intel Arc GPU below.
This quickstart guide walks you through installing and running `llama.cpp` with `ipex-llm`.
### 0 Prerequisites
-IPEX-LLM's support for `llama.cpp` now is avaliable for Linux system and Windows system.
+IPEX-LLM's support for `llama.cpp` now is available for Linux system and Windows system.
#### Linux
For Linux system, we recommend Ubuntu 20.04 or later (Ubuntu 22.04 is preferred).
@@ -272,4 +272,4 @@ If you encounter `main: failed to quantize model from xxx`, please make sure you
If your program hang after `llm_load_tensors: SYCL_Host buffer size = xx.xx MiB`, you can add `--no-mmap` in your command.
#### How to set `-ngl` parameter
-`-ngl` means the number of layers to store in VRAM. If your VRAM is enough, we recommend putting all layers on GPU, you can just set `-ngl` to a large number like 999 to achieve this goal.
\ No newline at end of file
+`-ngl` means the number of layers to store in VRAM. If your VRAM is enough, we recommend putting all layers on GPU, you can just set `-ngl` to a large number like 999 to achieve this goal.
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
index b911c5d6..695a41df 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
@@ -10,13 +10,13 @@ See the demo of running LLaMA2-7B on Intel Arc GPU below.
### 1 Install IPEX-LLM for Ollama
-IPEX-LLM's support for `ollama` now is avaliable for Linux system and Windows system.
+IPEX-LLM's support for `ollama` now is available for Linux system and Windows system.
-Visit [Run llama.cpp with IPEX-LLM on Intel GPU Guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html), and follow the instructions in section [Prerequisites](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#prerequisites) to setup and section [Install IPEX-LLM cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#install-ipex-llm-for-llama-cpp) to install the IPEX-LLM with Ollama binaries.
+Visit [Run llama.cpp with IPEX-LLM on Intel GPU Guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html), and follow the instructions in section [Prerequisites](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#prerequisites) to setup and section [Install IPEX-LLM cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#install-ipex-llm-for-llama-cpp) to install the IPEX-LLM with Ollama binaries.
**After the installation, you should have created a conda environment, named `llm-cpp` for instance, for running `ollama` commands with IPEX-LLM.**
-### 2. Initialize Ollama
+### 2. Initialize Ollama
Activate the `llm-cpp` conda environment and initialize Ollama by executing the commands below. A symbolic link to `ollama` will appear in your current directory.
 -
### Troubleshooting
#### Failed to load the extension `openai`
If you encounter `TypeError: unsupported operand type(s) for |: 'type' and 'NoneType'` when you run `python server.py --load-in-4bit --api`, please make sure you are using `Python 3.11` instead of lower versions.
-
-
-
-
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md b/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
index fd5a52c3..ee066e33 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
@@ -1,14 +1,13 @@
# Install IPEX-LLM in Docker on Windows with Intel GPU
-This guide demonstrates how to install IPEX-LLM in Docker on Windows with Intel GPUs.
+This guide demonstrates how to install IPEX-LLM in Docker on Windows with Intel GPUs.
It applies to Intel Core Core 12 - 14 gen integrated GPUs (iGPUs) and Intel Arc Series GPU.
-> Note:
+> Note:
> - WSL2 support is required during the installation process.
> - This installation method requires at least 35GB of free disk space on C drive.
-
## Install Docker on Windows
**Getting Started with Docker:**
1. **For New Users:**
@@ -16,7 +15,7 @@ It applies to Intel Core Core 12 - 14 gen integrated GPUs (iGPUs) and Intel Arc
- Detailed installation instructions for Windows, including steps for enabling WSL2, can be found on the [Docker Desktop for Windows installation page](https://docs.docker.com/desktop/install/windows-install/).
2. **Detailed installation Steps for Windows Users:**
- - **Download and install [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/)**: The installation could take around 5 minutes, and a reboot will be required after installation.
+ - **Download and install [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/)**: The installation could take around 5 minutes, and a reboot will be required after installation.
-
### Troubleshooting
#### Failed to load the extension `openai`
If you encounter `TypeError: unsupported operand type(s) for |: 'type' and 'NoneType'` when you run `python server.py --load-in-4bit --api`, please make sure you are using `Python 3.11` instead of lower versions.
-
-
-
-
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md b/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
index fd5a52c3..ee066e33 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
@@ -1,14 +1,13 @@
# Install IPEX-LLM in Docker on Windows with Intel GPU
-This guide demonstrates how to install IPEX-LLM in Docker on Windows with Intel GPUs.
+This guide demonstrates how to install IPEX-LLM in Docker on Windows with Intel GPUs.
It applies to Intel Core Core 12 - 14 gen integrated GPUs (iGPUs) and Intel Arc Series GPU.
-> Note:
+> Note:
> - WSL2 support is required during the installation process.
> - This installation method requires at least 35GB of free disk space on C drive.
-
## Install Docker on Windows
**Getting Started with Docker:**
1. **For New Users:**
@@ -16,7 +15,7 @@ It applies to Intel Core Core 12 - 14 gen integrated GPUs (iGPUs) and Intel Arc
- Detailed installation instructions for Windows, including steps for enabling WSL2, can be found on the [Docker Desktop for Windows installation page](https://docs.docker.com/desktop/install/windows-install/).
2. **Detailed installation Steps for Windows Users:**
- - **Download and install [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/)**: The installation could take around 5 minutes, and a reboot will be required after installation.
+ - **Download and install [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/)**: The installation could take around 5 minutes, and a reboot will be required after installation.