[PPML] Refine Occlum Ali ECS Development Guide Doc Style (#7602)
* Fix Occlum arch link * Fix style * Refine words
This commit is contained in:
parent
2bc6e03635
commit
aea71ce4d7
1 changed files with 20 additions and 13 deletions
|
|
@ -130,8 +130,10 @@ bash /opt/run_spark_on_occlum_glibc.sh pysql
|
|||
|
||||
##### 前提条件:
|
||||
1. 阿里云实例上k8s集群已经配置好,k8s SGX device plugin已经安装好。
|
||||
设置环境变量 "kubernetes_master_url"。
|
||||
设置环境变量`kubernetes_master_url`。
|
||||
```bash
|
||||
export kubernetes_master_url=${master_node_ip}
|
||||
```
|
||||
|
||||
2. 阿里云实例上安装spark client工具(以3.1.2版本为例),用于提交spark任务。
|
||||
```bash
|
||||
|
|
@ -139,7 +141,7 @@ wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tg
|
|||
sudo mkdir /opt/spark
|
||||
sudo tar -xf spark*.tgz -C /opt/spark --strip-component 1
|
||||
sudo chmod -R 777 /opt/spark
|
||||
export SPARK_HOME=/opt/spark"
|
||||
export SPARK_HOME=/opt/spark
|
||||
```
|
||||
|
||||
3. 下载BigDL的代码,为后续的修改做准备。
|
||||
|
|
@ -147,7 +149,7 @@ export SPARK_HOME=/opt/spark"
|
|||
git clone https://github.com/intel-analytics/BigDL.git
|
||||
```
|
||||
|
||||
接下来的改动位于路径“BigDL/ppml/trusted-big-data-ml/scala/docker-occlum/kubernetes”。
|
||||
接下来的改动位于路径`BigDL/ppml/trusted-big-data-ml/scala/docker-occlum/kubernetes`。
|
||||
|
||||
##### 运行步骤:
|
||||
1. 配置合适的资源在driver.yml和executor.yaml中
|
||||
|
|
@ -332,9 +334,8 @@ KMS是SGX应用部署中的核心服务。用户可以直接使用阿里云提
|
|||
为了提升安全水位,我们提供了带TEE 保护的开源KMS的部署方式供用户参考。即EHSM(运行在SGX中的KMS)。
|
||||
|
||||
### 3.1 安装和配置EHSM
|
||||
安装EHSM的教程请参照文档《Deploy BigDL-eHSM-KMS on Kubernetes》。
|
||||
使用PPMLContext和EHSM实现输入输出数据加解密
|
||||
用PPMLContext和EHSM实现SimpleQuery应用的数据加解密流程
|
||||
安装EHSM的教程请参照文档[Deploy BigDL-eHSM-KMS on Kubernetes](https://github.com/intel-analytics/BigDL/tree/main/ppml/services/ehsm/kubernetes)。
|
||||
**使用PPMLContext和EHSM实现输入输出数据加解密。**基本流程如下:
|
||||
1. 按照EHSM教程配置好PCCS和EHSM等环境。
|
||||
注意因为是部署在阿里云上,阿里云有可用的PCCS服务,所以对于教程里的第一步“Deploy BigDL-PCCS on Kubernetes”可以忽略。
|
||||
2. 注册获取app_id和api_key。
|
||||
|
|
@ -433,9 +434,12 @@ docker pull intelanalytics/bigdl-ppml-trusted-big-data-ml-scala-occlum-producti
|
|||
docker pull intelanalytics/bigdl-ppml-trusted-big-data-ml-scala-occlum-production-customer:2.2.0-build
|
||||
```
|
||||
|
||||
intelanalytics/bigdl-ppml-trusted-big-data-ml-scala-occlum-production: 2.2.0 image是提供给有定制docker image需求的客户的,下面以 pyspark sql example为例,说明如何定制化runnable image。
|
||||
`intelanalytics/bigdl-ppml-trusted-big-data-ml-scala-occlum-production:2.2.0` image是提供给有定制docker image需求的客户的,下面以 pyspark sql example为例,说明如何定制化runnable image。
|
||||
|
||||
1. 获取production image
|
||||
```bash
|
||||
docker pull intelanalytics/bigdl-ppml-trusted-big-data-ml-scala-occlum-production:2.2.0
|
||||
```
|
||||
|
||||
2. 运行启动脚本进入容器内部
|
||||
```bash
|
||||
|
|
@ -459,6 +463,7 @@ sudo docker run -it \
|
|||
```
|
||||
|
||||
3. 添加相关python源码(/opt/py-examples/)或jar包依赖($BIGDL_HOME/jars/)或python依赖(/opt/python-occlum/)。如添加sql_example.py到/opt/py-examples/目录下。
|
||||
|
||||
4. 构建runnable occlum instance。这一步的作用是初始化occlum文件夹,并将源码和相关配置和依赖拷贝进/opt/occlum_spark中,并执行occlum build构建occlum runnable instance即production-build image。
|
||||
```bash
|
||||
bash /opt/run_spark_on_occlum_glibc.sh init
|
||||
|
|
@ -469,7 +474,7 @@ bash /opt/run_spark_on_occlum_glibc.sh init
|
|||
docker commit $container_name $container_name-build
|
||||
```
|
||||
|
||||
得到的未定制的intelanalytics/bigdl-ppml-trusted-big-data-ml-scala-occlum-production: 2.2.0-build大小有14.2GB,其中仅有/opt/occlum_spark文件夹和少部分配置文件是运行时所需的,其余大多数是拷贝和编译产生的垃圾文件。可在 production-build image的基础上copy occlum runnable instance 并安装Occlum运行时依赖和其他一些依赖得到最终的customer image,其大小仅不到5GB,且其功能与production-build image基本相同, intelanalytics/bigdl-ppml-trusted-big-data-ml-scala-occlum-production-customer: 2.2.0-build 即不经过任何定制的customer image。(通过修改运行build-customer-image.sh文件构建customer image)
|
||||
得到的未定制的`intelanalytics/bigdl-ppml-trusted-big-data-ml-scala-occlum-production: 2.2.0-build`大小有14.2GB,其中仅有`/opt/occlum_spark`文件夹和少部分配置文件是运行时所需的,其余大多数是拷贝和编译产生的垃圾文件。可在 production-build image的基础上copy occlum runnable instance 并安装Occlum运行时依赖和其他一些依赖得到最终的customer image,其大小仅不到5GB,且其功能与production-build image基本相同,`intelanalytics/bigdl-ppml-trusted-big-data-ml-scala-occlum-production-customer:2.2.0-build`即不经过任何定制的customer image。(通过修改运行build-customer-image.sh文件构建customer image)
|
||||
|
||||
Production-build 或 Customer image的attestation流程
|
||||
1. 配置PCCS和EHSM环境,注册得到app_id和api_key,启动任务时,增加相关环境变量(同上)。
|
||||
|
|
@ -491,15 +496,17 @@ bash start-spark-local.sh register
|
|||
env:
|
||||
- name: policy_Id
|
||||
value: "${policy_Id}"
|
||||
5. 在docker或k8s启动应用(同上),仅会在SGX中运行EHSM对应用程序进行验证(IV. attest MREnclave)。
|
||||
```
|
||||
|
||||
5. 在docker或k8s启动应用(同上),仅会在SGX中运行EHSM对应用程序进行验证(IV. attest MREnclave)。
|
||||
|
||||
## 4. 背景知识
|
||||
|
||||
### 4.1 Intel SGX
|
||||
|
||||
英特尔软件防护扩展(英语:Intel Software Guard Extensions,SGX)是一组安全相关的指令,它被内置于一些现代Intel 中央处理器(CPU)中。它们允许用户态及内核态代码定义将特定内存区域,设置为私有区域,此区域也被称作飞地(Enclaves)。其内容受到保护,不能被本身以外的任何进程存取,包括以更高权限级别运行的进程。
|
||||
|
||||
CPU对受SGX保护的内存进行加密处理。受保护区域的代码和数据的加解密操作在CPU内部动态(on the fly)完成。因此,处理器可以保护代码不被其他代码窥视或检查。SGX使用的威胁模型如下:Enclaves是可信的,但Enclaves之外的任何进程都不可信(包括操作系统本身和任何虚拟化管理程序),所有这些不可信的主体都被视为有存在恶意行为的风险。Enclaves之外代码的任何代码读取受保护区域,只能得到加密后的内容。[3]由于SGX不能防止针对运行时间等侧信道信息的测量和观察,在SGX内部运行的程序本身必须能抵抗侧信道攻击。
|
||||
CPU对受SGX保护的内存进行加密处理。受保护区域的代码和数据的加解密操作在CPU内部动态(on the fly)完成。因此,处理器可以保护代码不被其他代码窥视或检查。SGX使用的威胁模型如下:Enclaves是可信的,但Enclaves之外的任何进程都不可信(包括操作系统本身和任何虚拟化管理程序),所有这些不可信的主体都被视为有存在恶意行为的风险。Enclaves之外代码的任何代码读取受保护区域,只能得到加密后的内容。
|
||||
|
||||
SGX被设计用于实现安全远程计算、安全网页浏览和数字版权管理(DRM)。其他应用也包括保护专有算法和加密密钥。
|
||||
|
||||
|
|
@ -509,7 +516,7 @@ SGX被设计用于实现安全远程计算、安全网页浏览和数字版权
|
|||
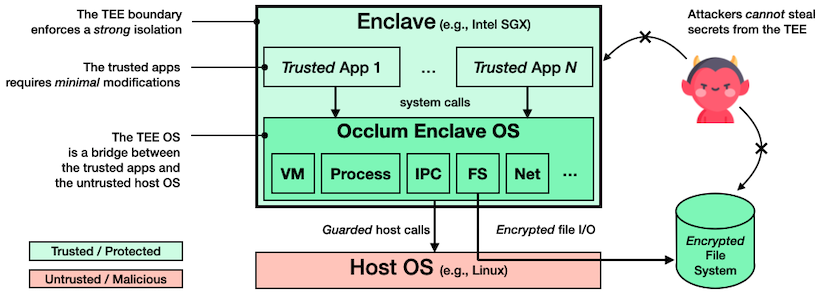
使用 Occlum 后,机器学习工作负载等只需修改极少量(甚至无需修改)源代码即可在英特尔® SGX 上运行,以高度透明的方式保护了用户数据的机密性和完整性。用于英特尔® SGX 的 Occlum 架构如图所示。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
Occlum有以下显著特征:
|
||||
* 高效的多任务处理。 Occlum提供轻量级LibOS流程:它们是轻量级的,因为所有LibOS流程共享同一个SGX enclave。 与重型、per-enclave的LibOS进程相比,Occlum的轻型LibOS进程在启动时最高快1000倍,在IPC上快3倍。 此外,如果需要,Occlum还提供了一个可选的多域软件故障隔离方案来隔离Occlum LibOS进程。
|
||||
|
|
|
|||
Loading…
Reference in a new issue