diff --git a/README.md b/README.md
index 5d46b3b9..31ac6599 100644
--- a/README.md
+++ b/README.md
@@ -49,7 +49,7 @@ See the demo of running [*Text-Generation-WebUI*](https://ipex-llm.readthedocs.i
## Latest Update 🔥
- [2024/04] `ipex-llm` now supports **Llama 3** on both Intel [GPU](python/llm/example/GPU/HF-Transformers-AutoModels/Model/llama3) and [CPU](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama3).
-- [2024/04] `ipex-llm` now provides C++ interface, which can be used as an accelerated backend for running [llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html) and [ollama](https://ipex-llm.readthedocs.io/en/main/doc/LLM/Quickstart/ollama_quickstart.html) on Intel GPU.
+- [2024/04] `ipex-llm` now provides C++ interface, which can be used as an accelerated backend for running [llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html) and [ollama](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html) on Intel GPU.
- [2024/03] `bigdl-llm` has now become `ipex-llm` (see the migration guide [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/bigdl_llm_migration.html)); you may find the original `BigDL` project [here](https://github.com/intel-analytics/bigdl-2.x).
- [2024/02] `ipex-llm` now supports directly loading model from [ModelScope](python/llm/example/GPU/ModelScope-Models) ([魔搭](python/llm/example/CPU/ModelScope-Models)).
- [2024/02] `ipex-llm` added initial **INT2** support (based on llama.cpp [IQ2](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF-IQ2) mechanism), which makes it possible to run large-size LLM (e.g., Mixtral-8x7B) on Intel GPU with 16GB VRAM.
@@ -84,7 +84,7 @@ See the demo of running [*Text-Generation-WebUI*](https://ipex-llm.readthedocs.i
### Run `ipex-llm`
- [llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html): running **llama.cpp** (*using C++ interface of `ipex-llm` as an accelerated backend for `llama.cpp`*) on Intel GPU
-- [ollama](https://ipex-llm.readthedocs.io/en/main/doc/LLM/Quickstart/ollama_quickstart.html): running **ollama** (*using C++ interface of `ipex-llm` as an accelerated backend for `ollama`*) on Intel GPU
+- [ollama](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html): running **ollama** (*using C++ interface of `ipex-llm` as an accelerated backend for `ollama`*) on Intel GPU
- [vLLM](python/llm/example/GPU/vLLM-Serving): running `ipex-llm` in `vLLM` on both Intel [GPU](python/llm/example/GPU/vLLM-Serving) and [CPU](python/llm/example/CPU/vLLM-Serving)
- [FastChat](python/llm/src/ipex_llm/serving/fastchat): running `ipex-llm` in `FastChat` serving on on both Intel GPU and CPU
- [LangChain-Chatchat RAG](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/chatchat_quickstart.html): running `ipex-llm` in `LangChain-Chatchat` (*Knowledge Base QA using **RAG** pipeline*)
diff --git a/docs/readthedocs/source/_templates/sidebar_quicklinks.html b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
index 673011fa..9465e770 100644
--- a/docs/readthedocs/source/_templates/sidebar_quicklinks.html
+++ b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
@@ -49,6 +49,9 @@
Run Ollama with IPEX-LLM on Intel GPU
+
+ Run Llama 3 on Intel GPU using llama.cpp and ollama with IPEX-LLM
+
Run IPEX-LLM Serving with FastChat
diff --git a/docs/readthedocs/source/_toc.yml b/docs/readthedocs/source/_toc.yml
index 40b6ce20..5076ea0b 100644
--- a/docs/readthedocs/source/_toc.yml
+++ b/docs/readthedocs/source/_toc.yml
@@ -30,6 +30,7 @@ subtrees:
- file: doc/LLM/Quickstart/benchmark_quickstart
- file: doc/LLM/Quickstart/llama_cpp_quickstart
- file: doc/LLM/Quickstart/ollama_quickstart
+ - file: doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart
- file: doc/LLM/Quickstart/fastchat_quickstart
- file: doc/LLM/Overview/KeyFeatures/index
title: "Key Features"
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/index.rst b/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
index adaa6fb8..fc6d3121 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
@@ -19,6 +19,7 @@ This section includes efficient guide to show you how to:
* `Run Coding Copilot (Continue) in VSCode with Intel GPU <./continue_quickstart.html>`_
* `Run llama.cpp with IPEX-LLM on Intel GPU <./llama_cpp_quickstart.html>`_
* `Run Ollama with IPEX-LLM on Intel GPU <./ollama_quickstart.html>`_
+* `Run Llama 3 on Intel GPU using llama.cpp and ollama with IPEX-LLM <./llama3_llamacpp_ollama_quickstart.html>`_
* `Run IPEX-LLM Serving with FastChat <./fastchat_quickstart.html>`_
.. |bigdl_llm_migration_guide| replace:: ``bigdl-llm`` Migration Guide
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md
new file mode 100644
index 00000000..6ec9252a
--- /dev/null
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md
@@ -0,0 +1,157 @@
+# Run Llama 3 on Intel GPU using llama.cpp and ollama with IPEX-LLM
+
+[Llama 3](https://llama.meta.com/llama3/) is the latest Large Language Models released by [Meta](https://llama.meta.com/) which provides state-of-the-art performance and excels at language nuances, contextual understanding, and complex tasks like translation and dialogue generation.
+
+Now, you can easily run Llama 3 on Intel GPU using `llama.cpp` and `Ollama` with IPEX-LLM.
+
+See the demo of running Llama-3-8B-Instruct on Intel Arc GPU using `Ollama` below.
+
+
+
+## Quick Start
+This quickstart guide walks you through how to run Llama 3 on Intel GPU using `llama.cpp` / `Ollama` with IPEX-LLM.
+
+### 1. Run Llama 3 using llama.cpp
+
+#### 1.1 Install IPEX-LLM for llama.cpp and Initialize
+
+Visit [Run llama.cpp with IPEX-LLM on Intel GPU Guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html), and follow the instructions in section [Prerequisites](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#prerequisites) to setup and section [Install IPEX-LLM for llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#install-ipex-llm-for-llama-cpp) to install the IPEX-LLM with llama.cpp binaries, then follow the instructions in section [Initialize llama.cpp with IPEX-LLM](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#prerequisites) to initialize.
+
+**After above steps, you should have created a conda environment, named `llm-cpp` for instance and have llama.cpp binaries in your current directory.**
+
+**Now you can use these executable files by standard llama.cpp usage.**
+
+#### 1.2 Download Llama3
+
+There already are some GGUF models of Llama3 in community, here we take [Meta-Llama-3-8B-Instruct-GGUF](https://huggingface.co/lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF) for example.
+
+Suppose you have downloaded a [Meta-Llama-3-8B-Instruct-Q4_K_M.gguf](https://huggingface.co/lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF/resolve/main/Meta-Llama-3-8B-Instruct-Q4_K_M.gguf) model from [Meta-Llama-3-8B-Instruct-GGUF](https://huggingface.co/lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF) and put it under ``.
+
+#### 1.3 Run Llama3 on Intel GPU using llama.cpp
+
+Under your current directory, exceuting below command to do inference with Llama3:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ ./main -m /Meta-Llama-3-8B-Instruct-Q4_K_M.gguf -n 32 --prompt "Once upon a time, there existed a little girl who liked to have adventures. She wanted to go to places and meet new people, and have fun doing something" -t 8 -e -ngl 33 --color --no-mmap
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: bash
+
+ main -ngl 33 -m /Meta-Llama-3-8B-Instruct-Q4_K_M.gguf -n 32 --prompt "Once upon a time, there existed a little girl who liked to have adventures. She wanted to go to places and meet new people, and have fun doing something" -e -ngl 33 --color --no-mmap
+```
+
+Under your current directory, you can also exceute below command to have interative chat with Llama3:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ ./main -ngl 33 -c 0 --interactive-first --color -e --in-prefix '<|start_header_id|>user<|end_header_id|>\n\n' --in-suffix '<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n' -r '<|eot_id|>' -m /Meta-Llama-3-8B-Instruct-Q4_K_M.gguf
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: bash
+
+ main -ngl 33 -c 0 --interactive-first --color -e --in-prefix '<|start_header_id|>user<|end_header_id|>\n\n' --in-suffix '<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n' -r '<|eot_id|>' -m /Meta-Llama-3-8B-Instruct-Q4_K_M.gguf
+```
+
+Below is a sample output on Intel Arc GPU:
+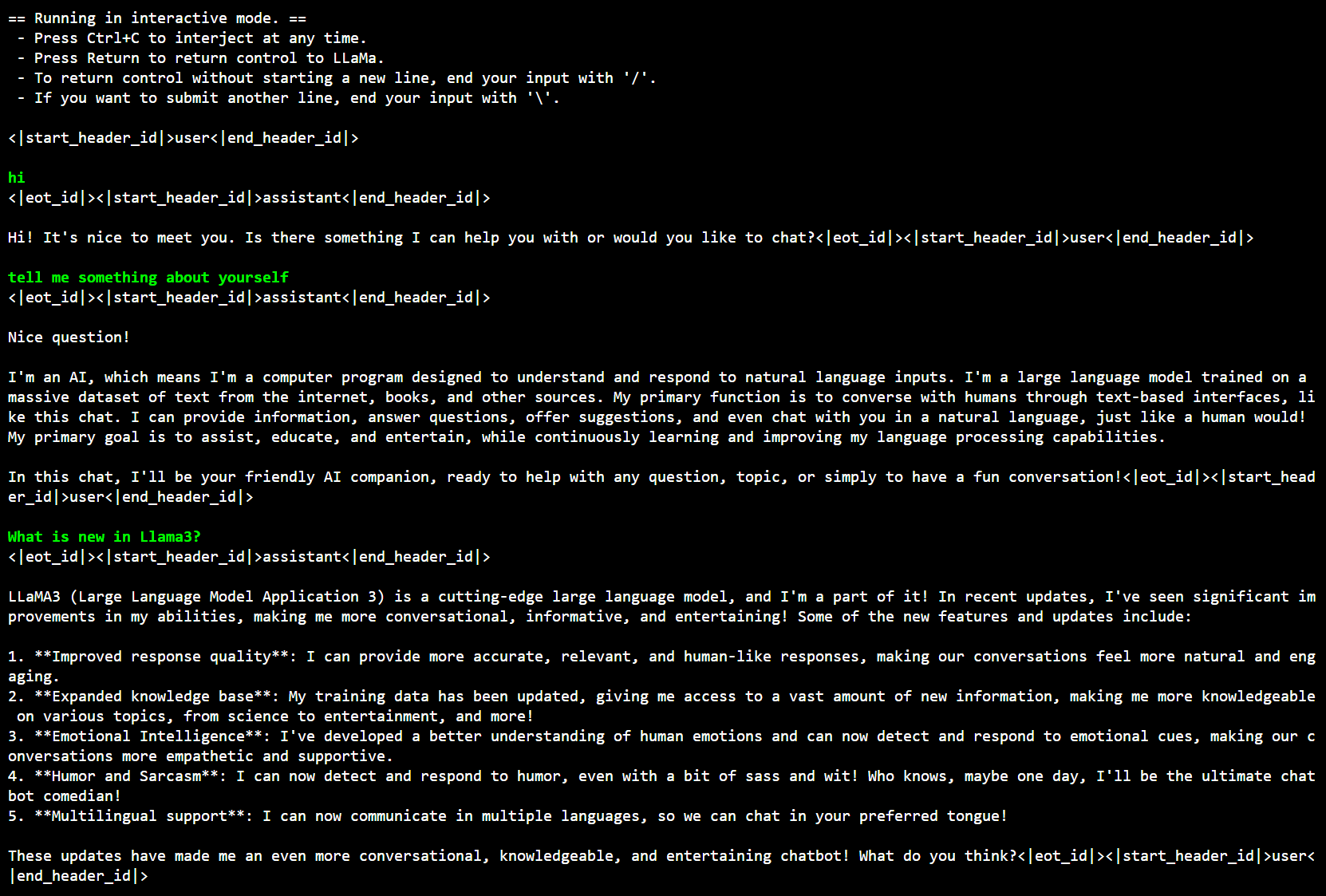 +
+
+### 2. Run Llama3 using Ollama
+
+#### 2.1 Install IPEX-LLM for Ollama and Initialize
+
+Visit [Run Ollama with IPEX-LLM on Intel GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html), and follow the instructions in section [Install IPEX-LLM for llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#install-ipex-llm-for-llama-cpp) to install the IPEX-LLM with Ollama binary, then follow the instructions in section [Initialize Ollama](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html#initialize-ollama) to initialize.
+
+**After above steps, you should have created a conda environment, named `llm-cpp` for instance and have ollama binary file in your current directory.**
+
+**Now you can use this executable file by standard Ollama usage.**
+
+#### 2.2 Run Llama3 on Intel GPU using Ollama
+
+[ollama/ollama](https://github.com/ollama/ollama) has alreadly added [Llama3](https://ollama.com/library/llama3) into its library, so it's really easy to run Llama3 using ollama now.
+
+##### 2.2.1 Run Ollama Serve
+
+Launch the Ollama service:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ export ZES_ENABLE_SYSMAN=1
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+ export OLLAMA_NUM_GPU=999
+ source /opt/intel/oneapi/setvars.sh
+
+ ./ollama serve
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ set ZES_ENABLE_SYSMAN=1
+ set OLLAMA_NUM_GPU=999
+ call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
+
+ ollama serve
+
+```
+
+```eval_rst
+.. note::
+
+ To allow the service to accept connections from all IP addresses, use `OLLAMA_HOST=0.0.0.0 ./ollama serve` instead of just `./ollama serve`.
+```
+
+#### 2.2.2 Using Ollama Run Llama3
+
+Keep the Ollama service on and open another terminal and run llama3 with `ollama run`:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ ./ollama run llama3:8b-instruct-q4_K_M
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ ollama run llama3:8b-instruct-q4_K_M
+```
+
+```eval_rst
+.. note::
+
+ Here we just take `llama3:8b-instruct-q4_K_M` for example, you can replace it with any other Llama3 model you want.
+```
+
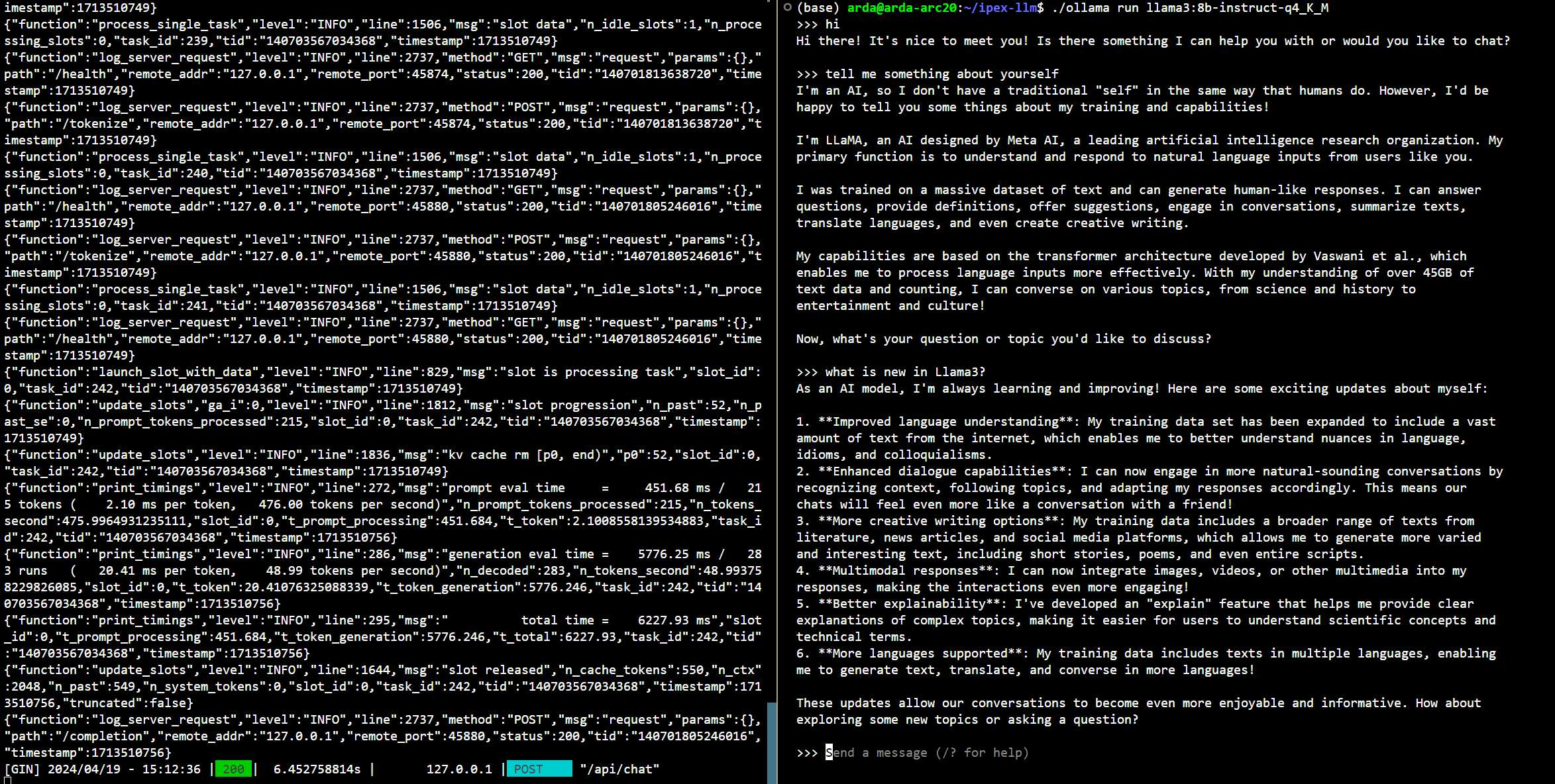
+Below is a sample output on Intel Arc GPU :
+
+
+
+### 2. Run Llama3 using Ollama
+
+#### 2.1 Install IPEX-LLM for Ollama and Initialize
+
+Visit [Run Ollama with IPEX-LLM on Intel GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html), and follow the instructions in section [Install IPEX-LLM for llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#install-ipex-llm-for-llama-cpp) to install the IPEX-LLM with Ollama binary, then follow the instructions in section [Initialize Ollama](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html#initialize-ollama) to initialize.
+
+**After above steps, you should have created a conda environment, named `llm-cpp` for instance and have ollama binary file in your current directory.**
+
+**Now you can use this executable file by standard Ollama usage.**
+
+#### 2.2 Run Llama3 on Intel GPU using Ollama
+
+[ollama/ollama](https://github.com/ollama/ollama) has alreadly added [Llama3](https://ollama.com/library/llama3) into its library, so it's really easy to run Llama3 using ollama now.
+
+##### 2.2.1 Run Ollama Serve
+
+Launch the Ollama service:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ export ZES_ENABLE_SYSMAN=1
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+ export OLLAMA_NUM_GPU=999
+ source /opt/intel/oneapi/setvars.sh
+
+ ./ollama serve
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ set ZES_ENABLE_SYSMAN=1
+ set OLLAMA_NUM_GPU=999
+ call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
+
+ ollama serve
+
+```
+
+```eval_rst
+.. note::
+
+ To allow the service to accept connections from all IP addresses, use `OLLAMA_HOST=0.0.0.0 ./ollama serve` instead of just `./ollama serve`.
+```
+
+#### 2.2.2 Using Ollama Run Llama3
+
+Keep the Ollama service on and open another terminal and run llama3 with `ollama run`:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ ./ollama run llama3:8b-instruct-q4_K_M
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ ollama run llama3:8b-instruct-q4_K_M
+```
+
+```eval_rst
+.. note::
+
+ Here we just take `llama3:8b-instruct-q4_K_M` for example, you can replace it with any other Llama3 model you want.
+```
+
+Below is a sample output on Intel Arc GPU :
+