diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
index 2d8adad9..29d82e25 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
@@ -6,7 +6,7 @@ This quickstart guide walks you through setting up and using the [Text Generatio
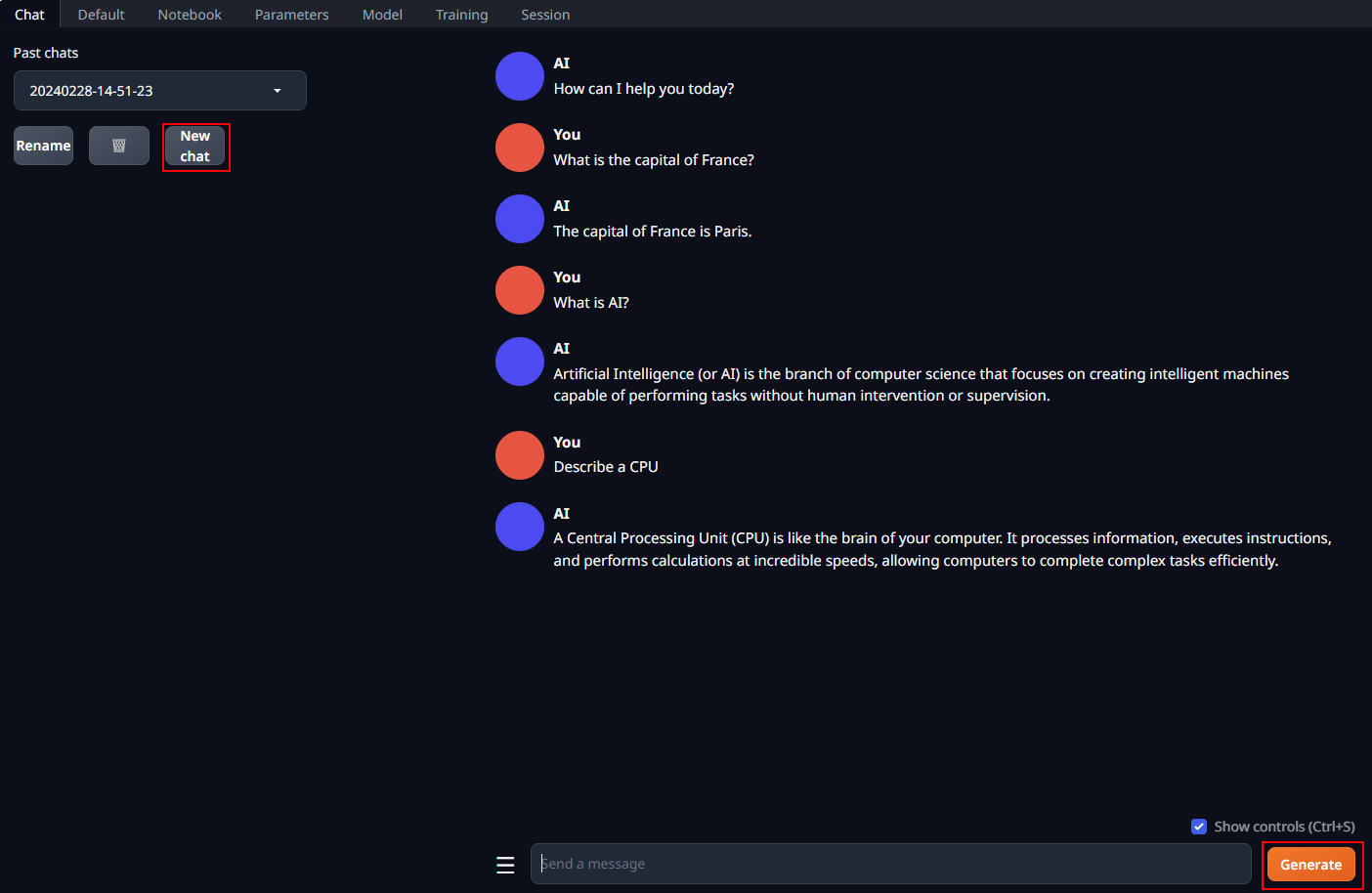
A preview of the WebUI in action is shown below:
-
+
 @@ -71,7 +71,7 @@ In **Anaconda Prompt** with the conda environment `llm` activated, navigate to t
### Access the WebUI
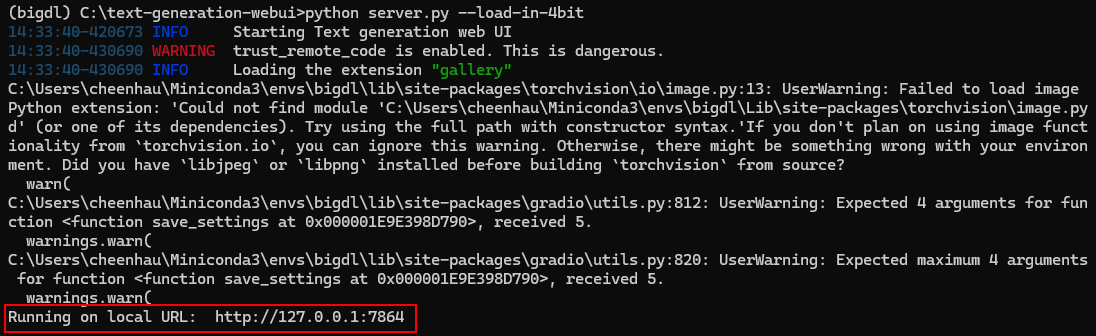
Upon successful launch, URLs to access the WebUI will be displayed in the terminal as shown below. Open the provided local URL in your browser to interact with the WebUI.
-
+
@@ -71,7 +71,7 @@ In **Anaconda Prompt** with the conda environment `llm` activated, navigate to t
### Access the WebUI
Upon successful launch, URLs to access the WebUI will be displayed in the terminal as shown below. Open the provided local URL in your browser to interact with the WebUI.
-
+
 @@ -81,13 +81,13 @@ Upon successful launch, URLs to access the WebUI will be displayed in the termin
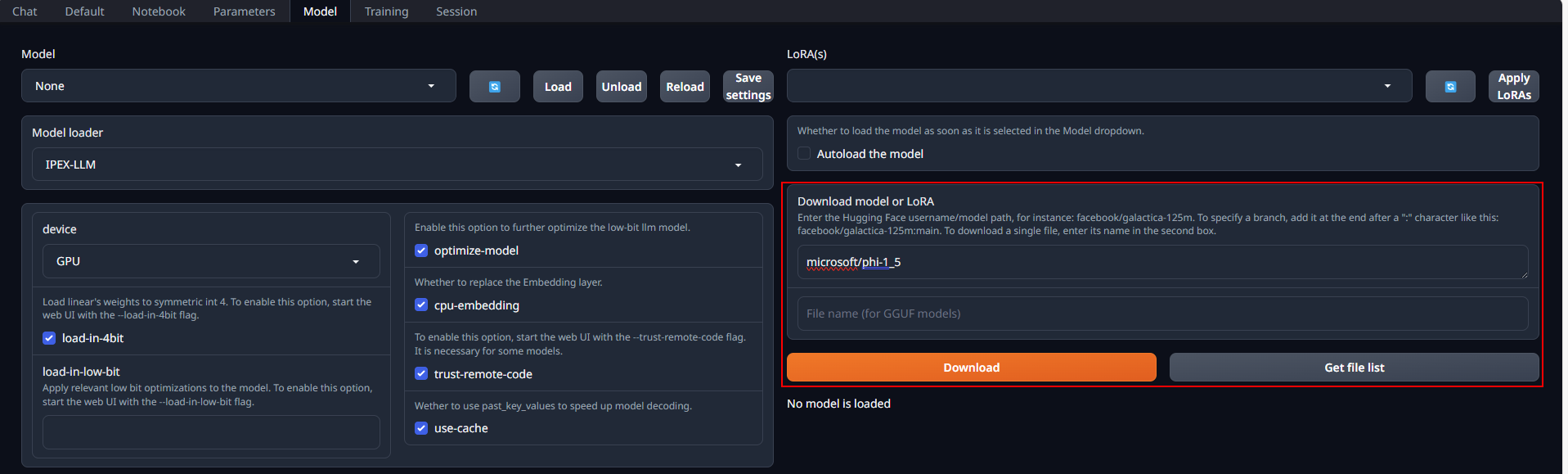
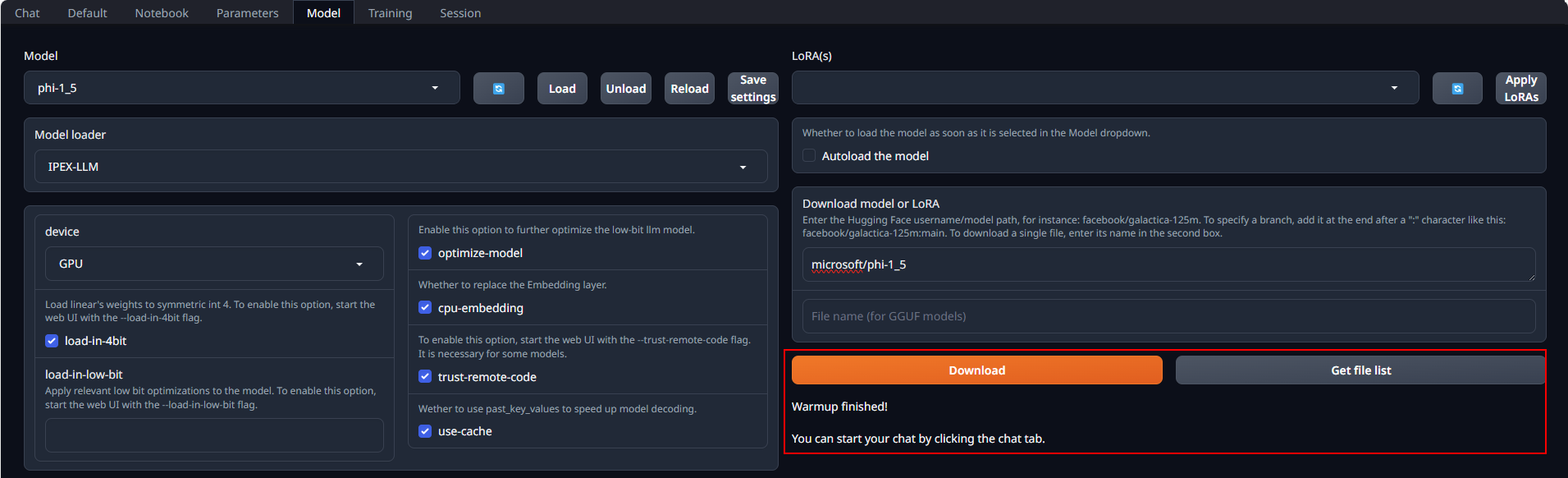
Place Huggingface models in `C:\text-generation-webui\models` by either copying locally or downloading via the WebUI. To download, navigate to the **Model** tab, enter the model's huggingface id (for instance, `microsoft/phi-1_5`) in the **Download model or LoRA** section, and click **Download**, as illustrated below.
-
+
@@ -81,13 +81,13 @@ Upon successful launch, URLs to access the WebUI will be displayed in the termin
Place Huggingface models in `C:\text-generation-webui\models` by either copying locally or downloading via the WebUI. To download, navigate to the **Model** tab, enter the model's huggingface id (for instance, `microsoft/phi-1_5`) in the **Download model or LoRA** section, and click **Download**, as illustrated below.
-
+
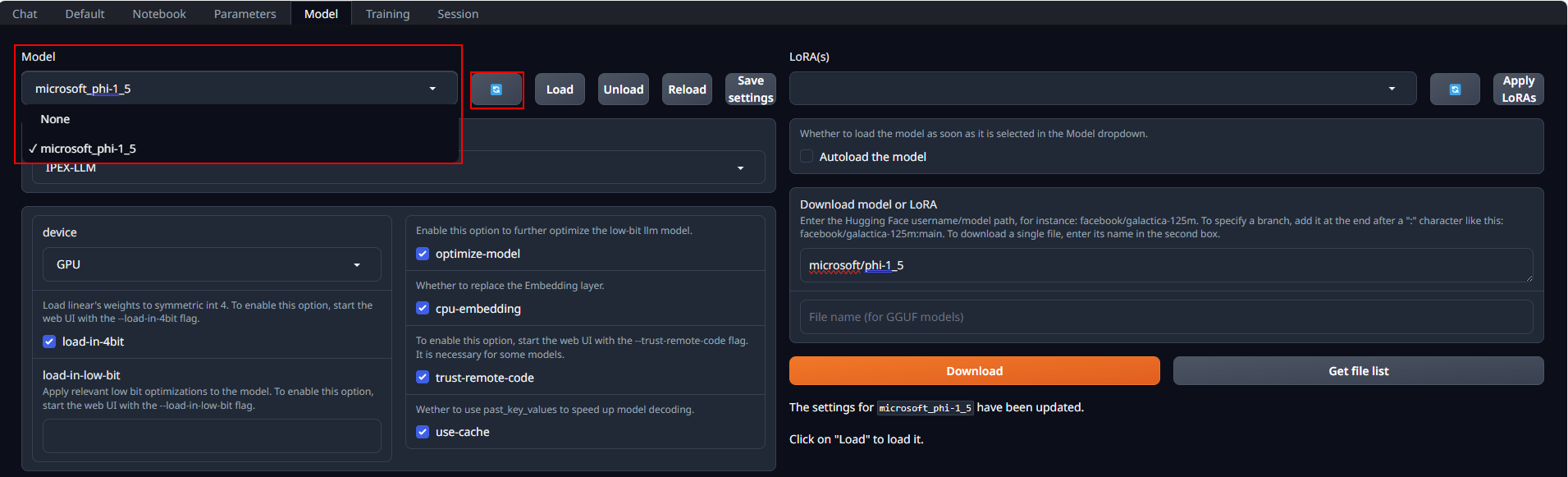
 After copying or downloading the models, click on the blue **refresh** button to update the **Model** drop-down menu. Then, choose your desired model from the newly updated list.
-
+
After copying or downloading the models, click on the blue **refresh** button to update the **Model** drop-down menu. Then, choose your desired model from the newly updated list.
-
+
 @@ -97,7 +97,7 @@ Default settings are recommended for most users. Click **Load** to activate the
If everything goes well, you will get a message as shown below.
-
+
@@ -97,7 +97,7 @@ Default settings are recommended for most users. Click **Load** to activate the
If everything goes well, you will get a message as shown below.
-
+
 @@ -107,7 +107,7 @@ In the **Chat** tab, start new conversations with **New chat**.
Enter prompts into the textbox at the bottom and press the **Generate** button to receive responses.
-
+
@@ -123,6 +123,42 @@ Enter prompts into the textbox at the bottom and press the **Generate** button t
To shut down the WebUI server, use **Ctrl+C** in the **Anaconda Prompt** terminal where the WebUI Server is runing, then close your browser tab.
+## 5. Advanced Usage
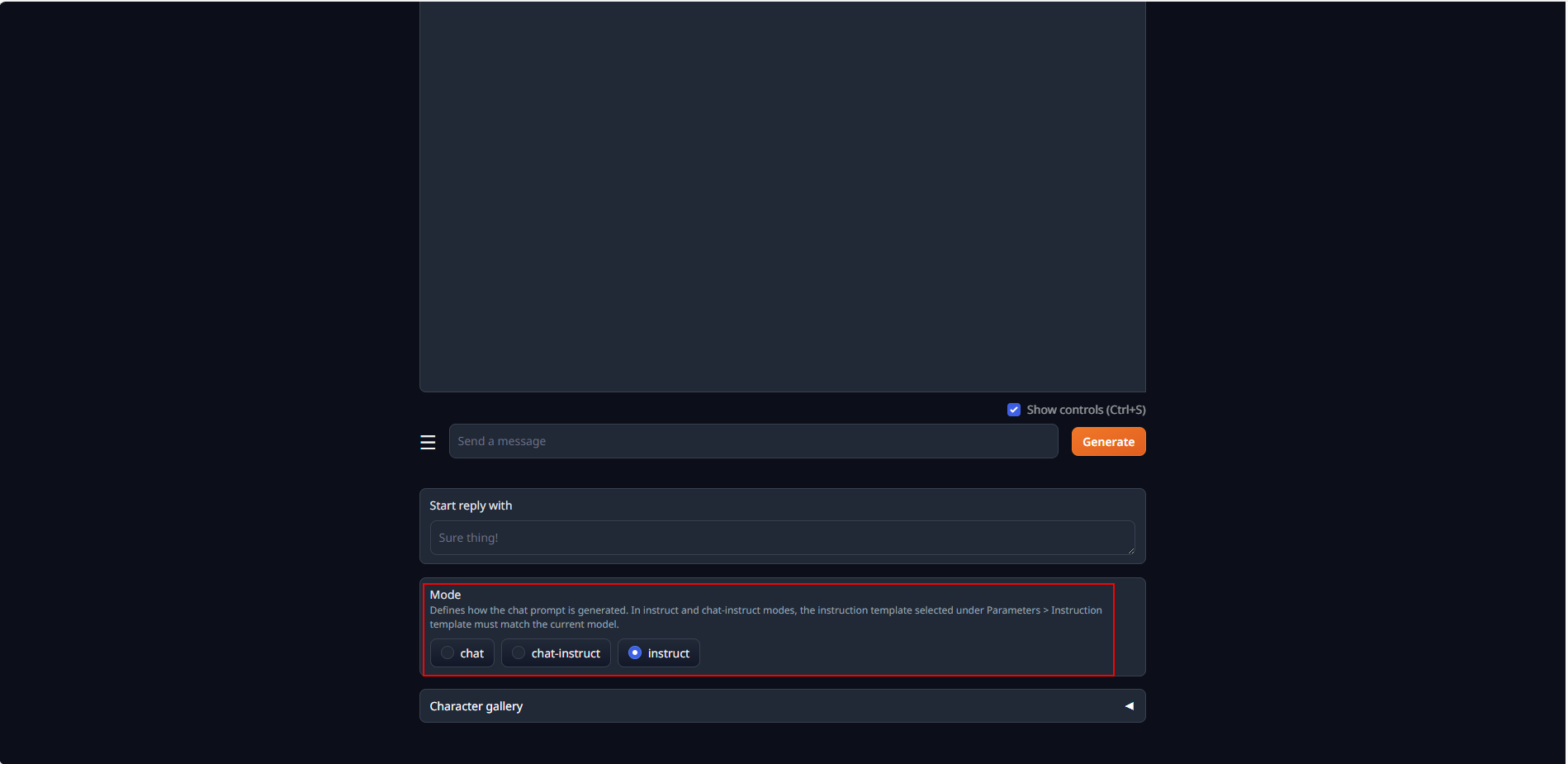
+### Using Instruct mode
+Instruction-following models are models that are fine-tuned with specific prompt formats.
+For these models, you should ideally use the `instruct` chat mode.
+Under this mode, the model receives user prompts that are formatted according to prompt formats it was trained with.
+
+To use `instruct` chat mode, select `chat` tab, scroll down the page, and then select `instruct` under `Mode`.
+
+
+
@@ -107,7 +107,7 @@ In the **Chat** tab, start new conversations with **New chat**.
Enter prompts into the textbox at the bottom and press the **Generate** button to receive responses.
-
+
@@ -123,6 +123,42 @@ Enter prompts into the textbox at the bottom and press the **Generate** button t
To shut down the WebUI server, use **Ctrl+C** in the **Anaconda Prompt** terminal where the WebUI Server is runing, then close your browser tab.
+## 5. Advanced Usage
+### Using Instruct mode
+Instruction-following models are models that are fine-tuned with specific prompt formats.
+For these models, you should ideally use the `instruct` chat mode.
+Under this mode, the model receives user prompts that are formatted according to prompt formats it was trained with.
+
+To use `instruct` chat mode, select `chat` tab, scroll down the page, and then select `instruct` under `Mode`.
+
+
+  +
+
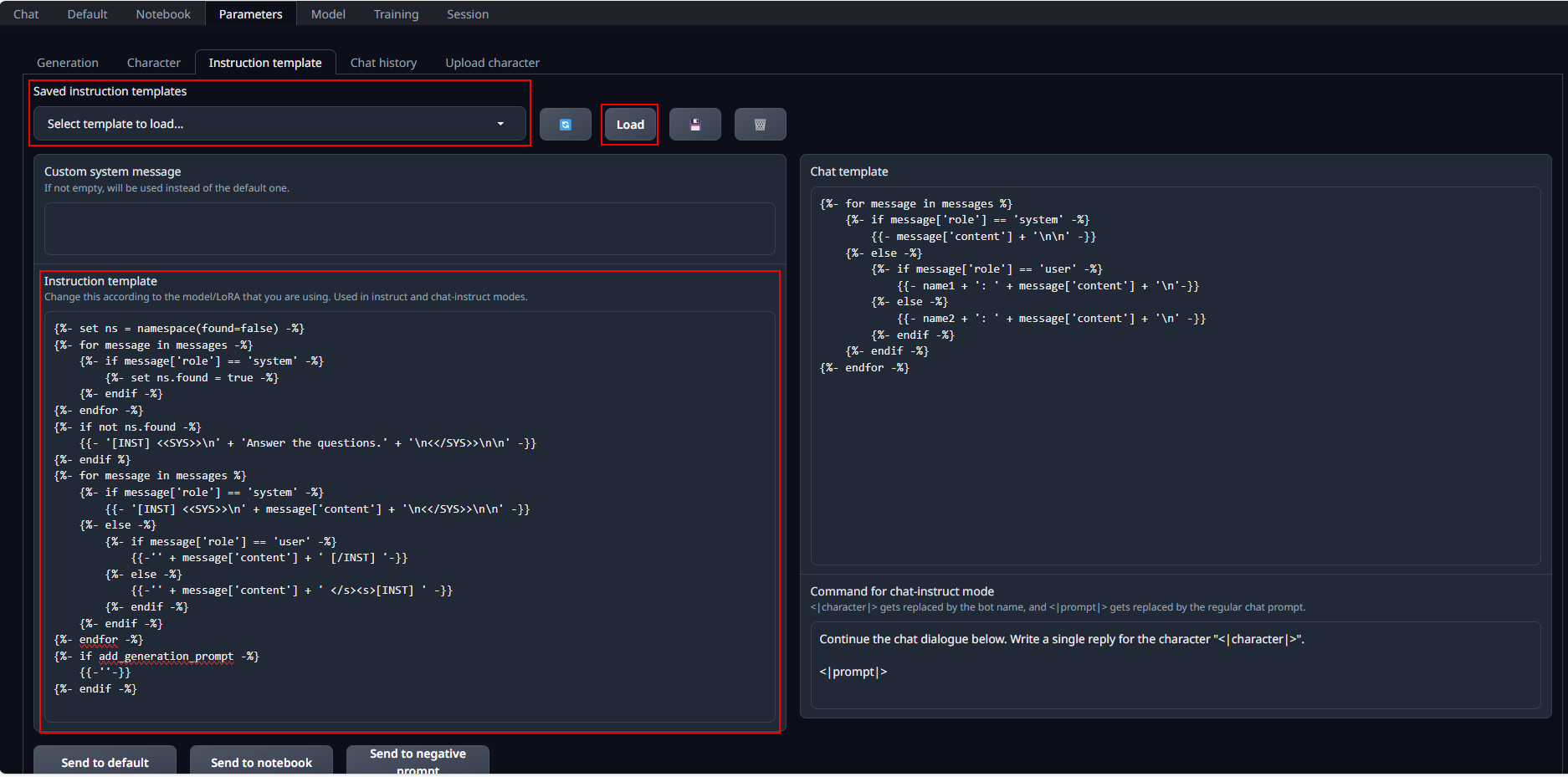
+When a model is loaded, its corresponding instruction template, which contains prompt formatting, is automatically loaded.
+If chat responses are poor, the loaded instruction template might be incorrect.
+In this case, go to `Parameters` tab and then `Instruction template` tab.
+
+
+
+
+
+When a model is loaded, its corresponding instruction template, which contains prompt formatting, is automatically loaded.
+If chat responses are poor, the loaded instruction template might be incorrect.
+In this case, go to `Parameters` tab and then `Instruction template` tab.
+
+
+  +
+
+You can verify and edit the loaded instruction template in the `Instruction template` field.
+You can also manually select an instruction template from `Saved instruction templates` and click `load` to load it into `Instruction template`.
+You can add custom template files to this list in `/instruction-templates/` [folder](https://github.com/intel-analytics/text-generation-webui/tree/bigdl-llm/instruction-templates).
+
+
+### Tested models
+We have tested the following models with `bigdl-llm` using Text Generation WebUI.
+
+| Model | Notes |
+|-------|-------|
+| llama-2-7b-chat-hf | |
+| chatglm3-6b | Manually load ChatGLM3 template for Instruct chat mode |
+| Mistral-7B-v0.1 | |
+| qwen-7B-Chat | |
+
+
## Troubleshooting
### Potentially slower first response
+
+
+You can verify and edit the loaded instruction template in the `Instruction template` field.
+You can also manually select an instruction template from `Saved instruction templates` and click `load` to load it into `Instruction template`.
+You can add custom template files to this list in `/instruction-templates/` [folder](https://github.com/intel-analytics/text-generation-webui/tree/bigdl-llm/instruction-templates).
+
+
+### Tested models
+We have tested the following models with `bigdl-llm` using Text Generation WebUI.
+
+| Model | Notes |
+|-------|-------|
+| llama-2-7b-chat-hf | |
+| chatglm3-6b | Manually load ChatGLM3 template for Instruct chat mode |
+| Mistral-7B-v0.1 | |
+| qwen-7B-Chat | |
+
+
## Troubleshooting
### Potentially slower first response