From 9880ddfc17ad77292c119d1326417d3e8e2d1176 Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Cheen=20Hau=2C=20=E4=BF=8A=E8=B1=AA?=
<33478814+chtanch@users.noreply.github.com>
Date: Wed, 13 Mar 2024 17:59:55 +0800
Subject: [PATCH] Update WebUI quickstart (#10316)
* Enlarge images and make them clickable to open in new window
* Update text to match image
* Remove image for 'AttributeError' since it does not show the error
* Add note on slower first response
* 'gpu models' -> 'gpu types'
---
.../doc/LLM/Quickstart/install_windows_gpu.md | 2 +-
.../doc/LLM/Quickstart/webui_quickstart.md | 45 ++++++++++++-------
2 files changed, 29 insertions(+), 18 deletions(-)
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md b/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md
index 873db7cf..a23ace60 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md
@@ -336,4 +336,4 @@ Now let's play with a real LLM. We'll be using the [Qwen-1.8B-Chat](https://hugg
## Tips & Troubleshooting
### Warm-up for optimal performance on first run
-When running LLMs on GPU for the first time, you might notice the performance is lower than expected, with delays up to several minutes before the first token is generated. This delay occurs because the GPU kernels require compilation and initialization, which varies across different GPU models. To achieve optimal and consistent performance, we recommend a one-time warm-up by running `model.generate(...)` an additional time before starting your actual generation tasks. If you're developing an application, you can incorporate this warm-up step into start-up or loading routine to enhance the user experience.
+When running LLMs on GPU for the first time, you might notice the performance is lower than expected, with delays up to several minutes before the first token is generated. This delay occurs because the GPU kernels require compilation and initialization, which varies across different GPU types. To achieve optimal and consistent performance, we recommend a one-time warm-up by running `model.generate(...)` an additional time before starting your actual generation tasks. If you're developing an application, you can incorporate this warm-up step into start-up or loading routine to enhance the user experience.
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
index 7c7899e8..2d8adad9 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
@@ -6,8 +6,9 @@ This quickstart guide walks you through setting up and using the [Text Generatio
A preview of the WebUI in action is shown below:
- -
+
+
+
## 1 Install BigDL-LLM
@@ -69,24 +70,26 @@ In **Anaconda Prompt** with the conda environment `llm` activated, navigate to t
### Access the WebUI
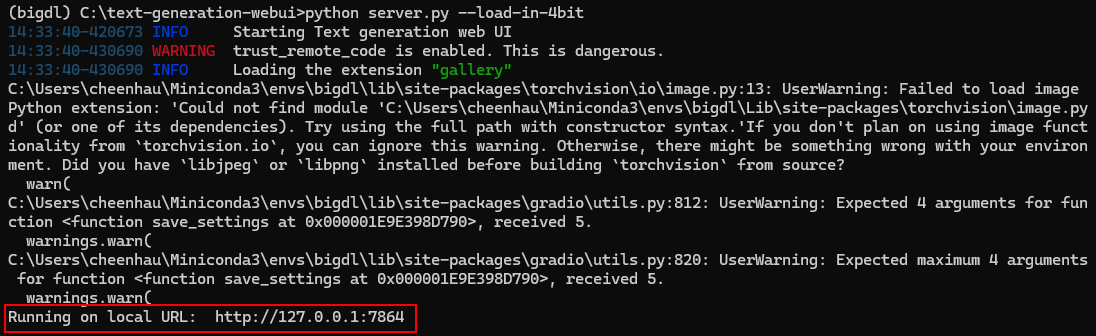
Upon successful launch, URLs to access the WebUI will be displayed in the terminal as shown below. Open the provided local URL in your browser to interact with the WebUI.
-
-
-
+
+
+
## 1 Install BigDL-LLM
@@ -69,24 +70,26 @@ In **Anaconda Prompt** with the conda environment `llm` activated, navigate to t
### Access the WebUI
Upon successful launch, URLs to access the WebUI will be displayed in the terminal as shown below. Open the provided local URL in your browser to interact with the WebUI.
-
-  +
+
+
## 4. Using the WebUI
### Model Download
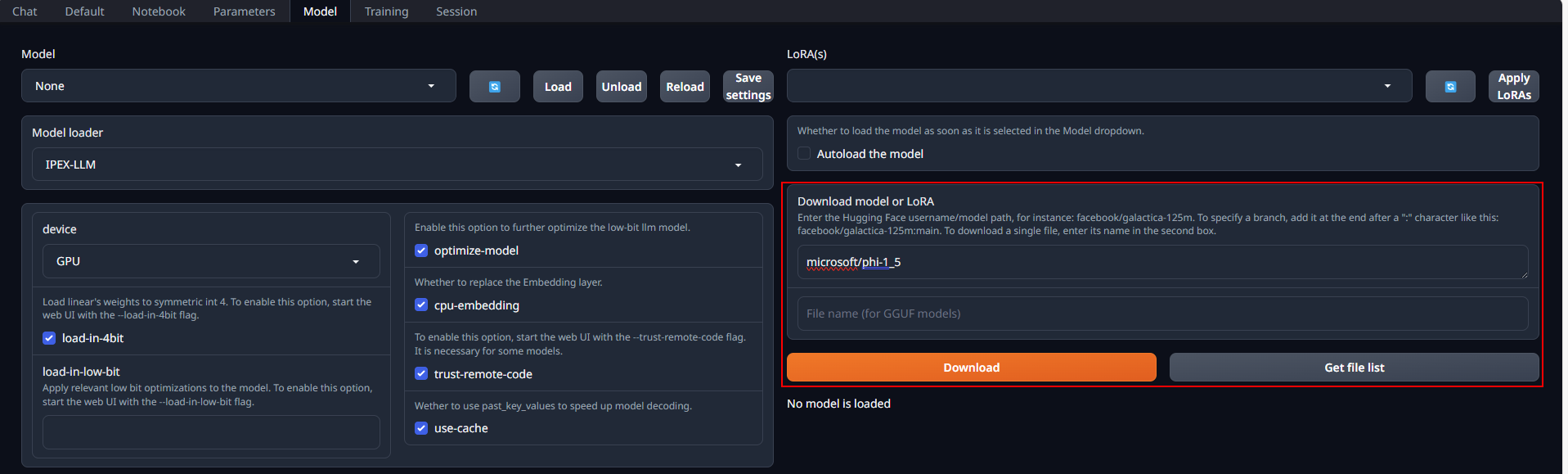
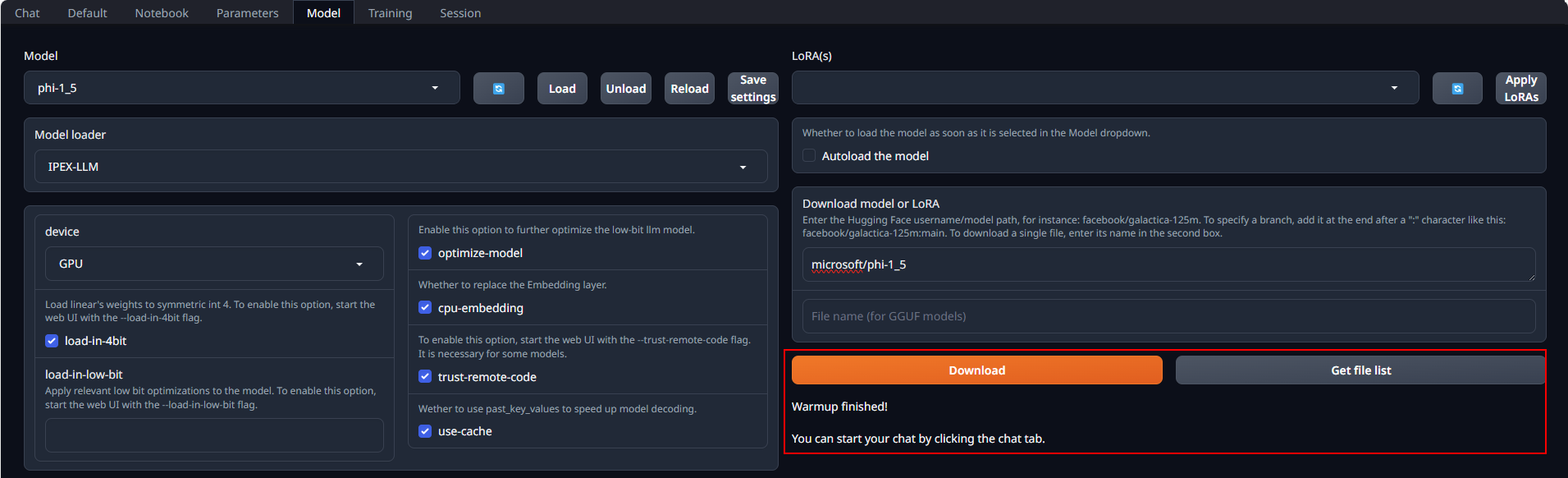
-Place Huggingface models in `C:\text-generation-webui\models` by either copying locally or downloading via the WebUI. To download, navigate to the **Model** tab, enter the model's huggingface id (for instance, `Qwen/Qwen-7B-Chat`) in the **Download model or LoRA** section, and click **Download**, as illustrated below.
+Place Huggingface models in `C:\text-generation-webui\models` by either copying locally or downloading via the WebUI. To download, navigate to the **Model** tab, enter the model's huggingface id (for instance, `microsoft/phi-1_5`) in the **Download model or LoRA** section, and click **Download**, as illustrated below.
-
+
+
+
## 4. Using the WebUI
### Model Download
-Place Huggingface models in `C:\text-generation-webui\models` by either copying locally or downloading via the WebUI. To download, navigate to the **Model** tab, enter the model's huggingface id (for instance, `Qwen/Qwen-7B-Chat`) in the **Download model or LoRA** section, and click **Download**, as illustrated below.
+Place Huggingface models in `C:\text-generation-webui\models` by either copying locally or downloading via the WebUI. To download, navigate to the **Model** tab, enter the model's huggingface id (for instance, `microsoft/phi-1_5`) in the **Download model or LoRA** section, and click **Download**, as illustrated below.
- +
+
+
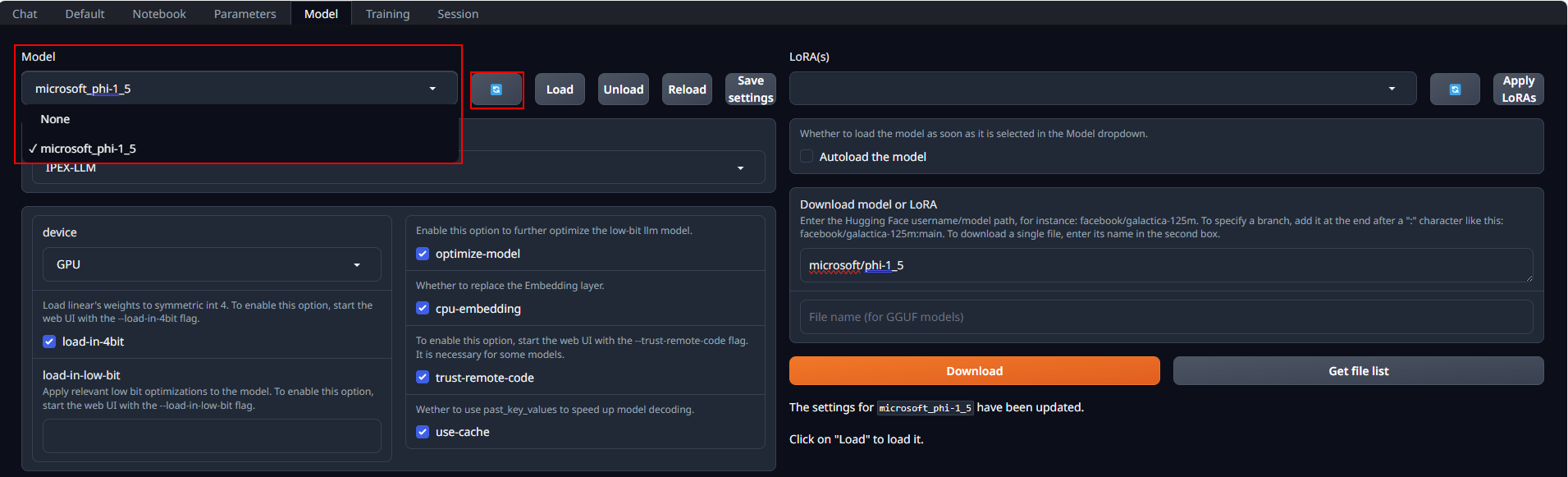
After copying or downloading the models, click on the blue **refresh** button to update the **Model** drop-down menu. Then, choose your desired model from the newly updated list.
-
+
+
+
After copying or downloading the models, click on the blue **refresh** button to update the **Model** drop-down menu. Then, choose your desired model from the newly updated list.
- -
+
+
+
### Load Model
@@ -94,9 +97,9 @@ Default settings are recommended for most users. Click **Load** to activate the
If everything goes well, you will get a message as shown below.
-
-
+
+
+
### Load Model
@@ -94,9 +97,9 @@ Default settings are recommended for most users. Click **Load** to activate the
If everything goes well, you will get a message as shown below.
- -
-
+
+
+
### Chat with the Model
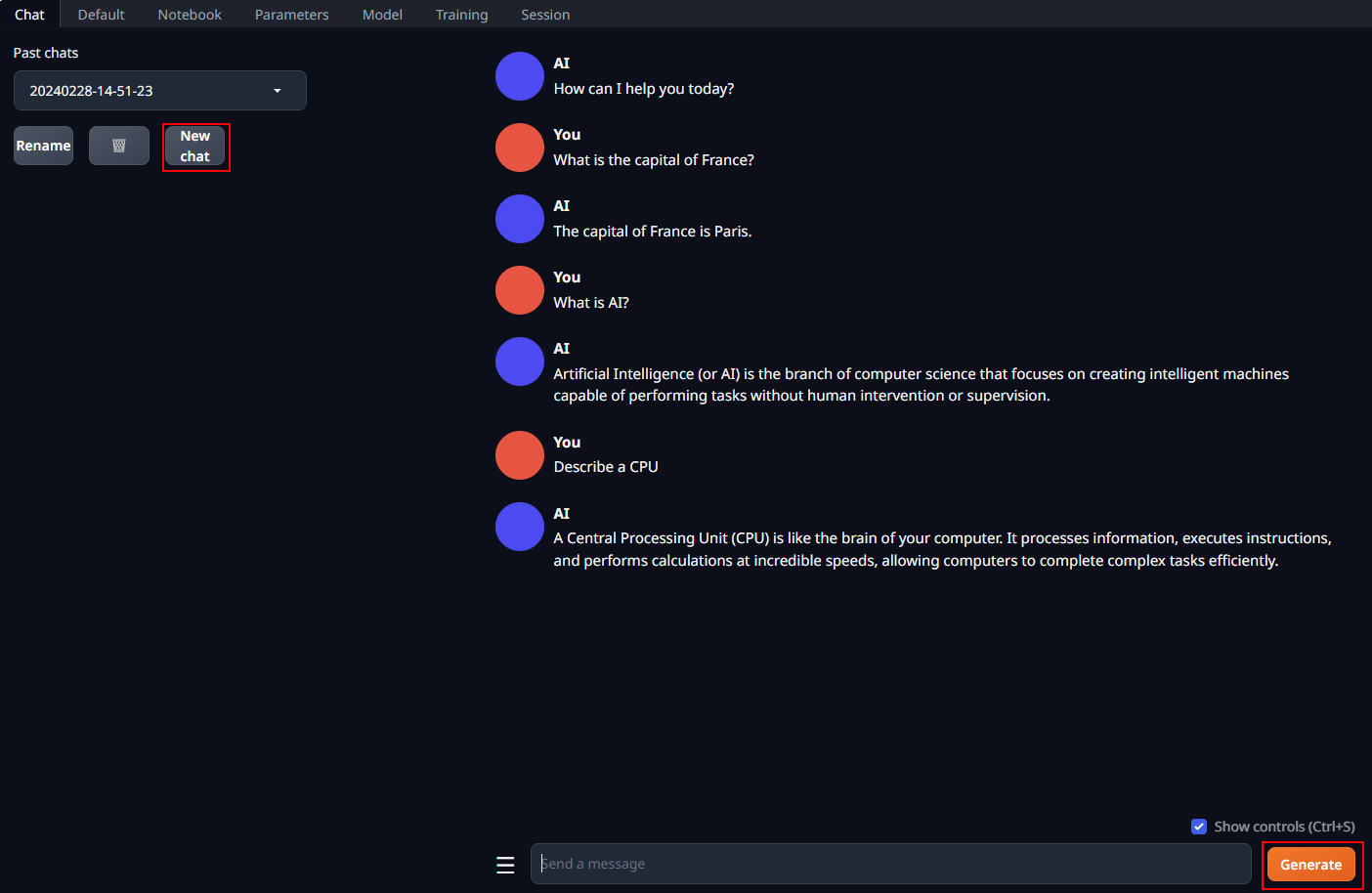
@@ -104,7 +107,9 @@ In the **Chat** tab, start new conversations with **New chat**.
Enter prompts into the textbox at the bottom and press the **Generate** button to receive responses.
-
+
+
+
-
-
+
+
+
### Chat with the Model
@@ -104,7 +107,9 @@ In the **Chat** tab, start new conversations with **New chat**.
Enter prompts into the textbox at the bottom and press the **Generate** button to receive responses.
-
+
+
+