diff --git a/docs/readthedocs/source/_templates/sidebar_quicklinks.html b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
index 4dea56b9..3b5a36b0 100644
--- a/docs/readthedocs/source/_templates/sidebar_quicklinks.html
+++ b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
@@ -9,9 +9,15 @@
+ -
+ Install BigDL-LLM on Linux with Intel GPU
+
-
Install BigDL-LLM on Windows with Intel GPU
+ -
+ Install BigDL-LLM in Docker on Windows with Intel GPU
+
-
Use Text Generation WebUI on Windows with Intel GPU
diff --git a/docs/readthedocs/source/_toc.yml b/docs/readthedocs/source/_toc.yml
index 27afa518..a02e0a42 100644
--- a/docs/readthedocs/source/_toc.yml
+++ b/docs/readthedocs/source/_toc.yml
@@ -38,7 +38,9 @@ subtrees:
title: "Quickstart"
subtrees:
- entries:
+ - file: doc/LLM/Quickstart/install_linux_gpu
- file: doc/LLM/Quickstart/install_windows_gpu
+ - file: doc/LLM/Quickstart/docker_windows_gpu
- file: doc/LLM/Quickstart/webui_quickstart
- file: doc/LLM/Quickstart/benchmark_quickstart
- file: doc/LLM/Quickstart/llama_cpp_quickstart
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/Install_BigDL-LLM_in_Docker_on_Windows_with_Intel_GPU.md b/docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
similarity index 100%
rename from docs/readthedocs/source/doc/LLM/Quickstart/Install_BigDL-LLM_in_Docker_on_Windows_with_Intel_GPU.md
rename to docs/readthedocs/source/doc/LLM/Quickstart/docker_windows_gpu.md
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/index.rst b/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
index 9d3c94d3..5eb8328f 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
@@ -7,7 +7,9 @@ BigDL-LLM Quickstart
This section includes efficient guide to show you how to:
+* `Install BigDL-LLM on Linux with Intel GPU <./install_linux_gpu.html>`_
* `Install BigDL-LLM on Windows with Intel GPU <./install_windows_gpu.html>`_
+* `Install BigDL-LLM in Docker on Windows with Intel GPU <./docker_windows_gpu.html>`_
* `Use Text Generation WebUI on Windows with Intel GPU <./webui_quickstart.html>`_
* `Conduct Performance Benchmarking with BigDL-LLM <./benchmark_quickstart.html>`_
* `Use llama.cpp with BigDL-LLM on Intel GPU <./llama_cpp_quickstart.html>`_
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/install_linux_gpu.md b/docs/readthedocs/source/doc/LLM/Quickstart/install_linux_gpu.md
index f1d5f16f..96a5b4b3 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/install_linux_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/install_linux_gpu.md
@@ -2,14 +2,12 @@
This guide demonstrates how to install BigDL-LLM on Linux with Intel GPUs. It applies to Intel Data Center GPU Flex Series and Max Series, as well as Intel Arc Series GPU.
-BigDL-LLM currently supports the Ubuntu 20.04 operating system and later, and supports PyTorch 2.0 and PyTorch 2.1 on Linux. This example installs BigDL-LLM with PyTorch 2.1 using `pip`. For more details and other options like installing with wheel, please refer to the [Installation Webpage](https://bigdl.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#linux).
+BigDL-LLM currently supports the Ubuntu 20.04 operating system and later, and supports PyTorch 2.0 and PyTorch 2.1 on Linux. This page demonstrates BigDL-LLM with PyTorch 2.1. Check the [Installation](https://bigdl.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#linux) page for more details.
## Install Intel GPU Driver
-This guide demonstrates how to install driver on linux with **kernel version 6.2** on Intel GPU.
-We assume that you have the 6.2 kernel on your linux machine.
-
+### For Linux kernel 6.2
* Install arc driver
```bash
@@ -20,7 +18,7 @@ We assume that you have the 6.2 kernel on your linux machine.
sudo tee /etc/apt/sources.list.d/intel-gpu-jammy.list
```
- >  + >
+ > 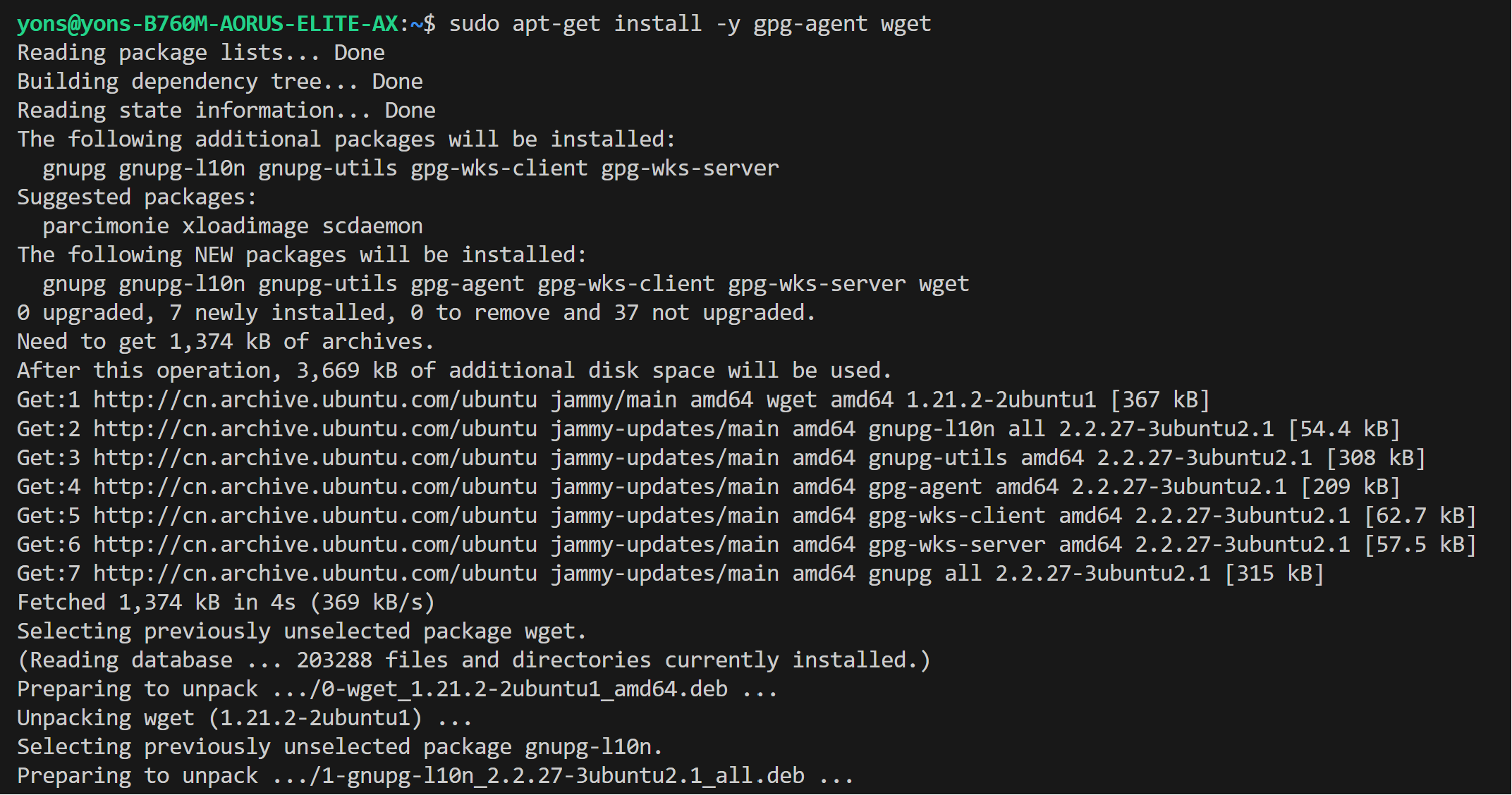 * Install drivers
@@ -45,9 +43,9 @@ We assume that you have the 6.2 kernel on your linux machine.
sudo reboot
```
- >
* Install drivers
@@ -45,9 +43,9 @@ We assume that you have the 6.2 kernel on your linux machine.
sudo reboot
```
- >  + >
+ > 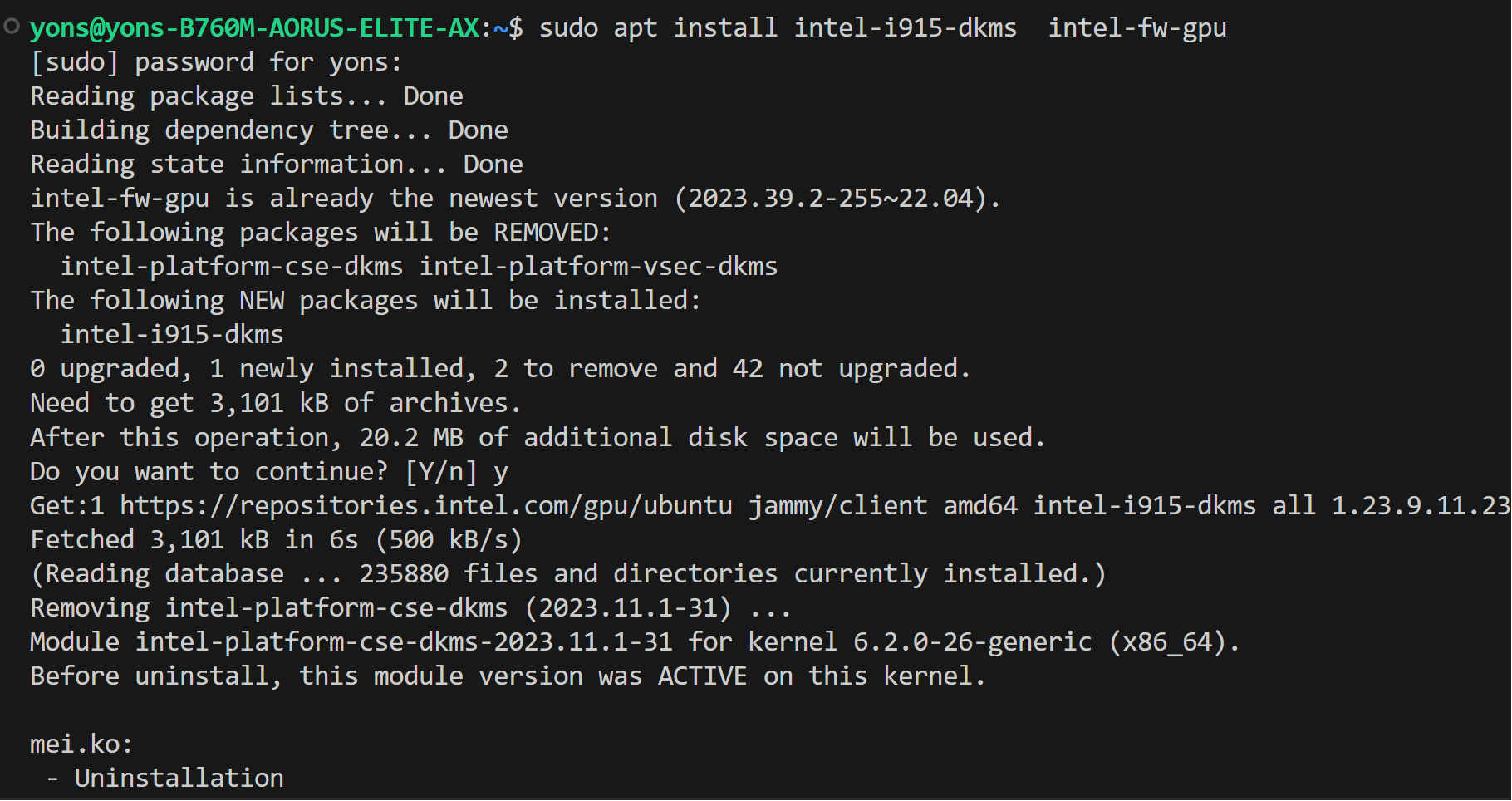 - >
- >  + >
+ > 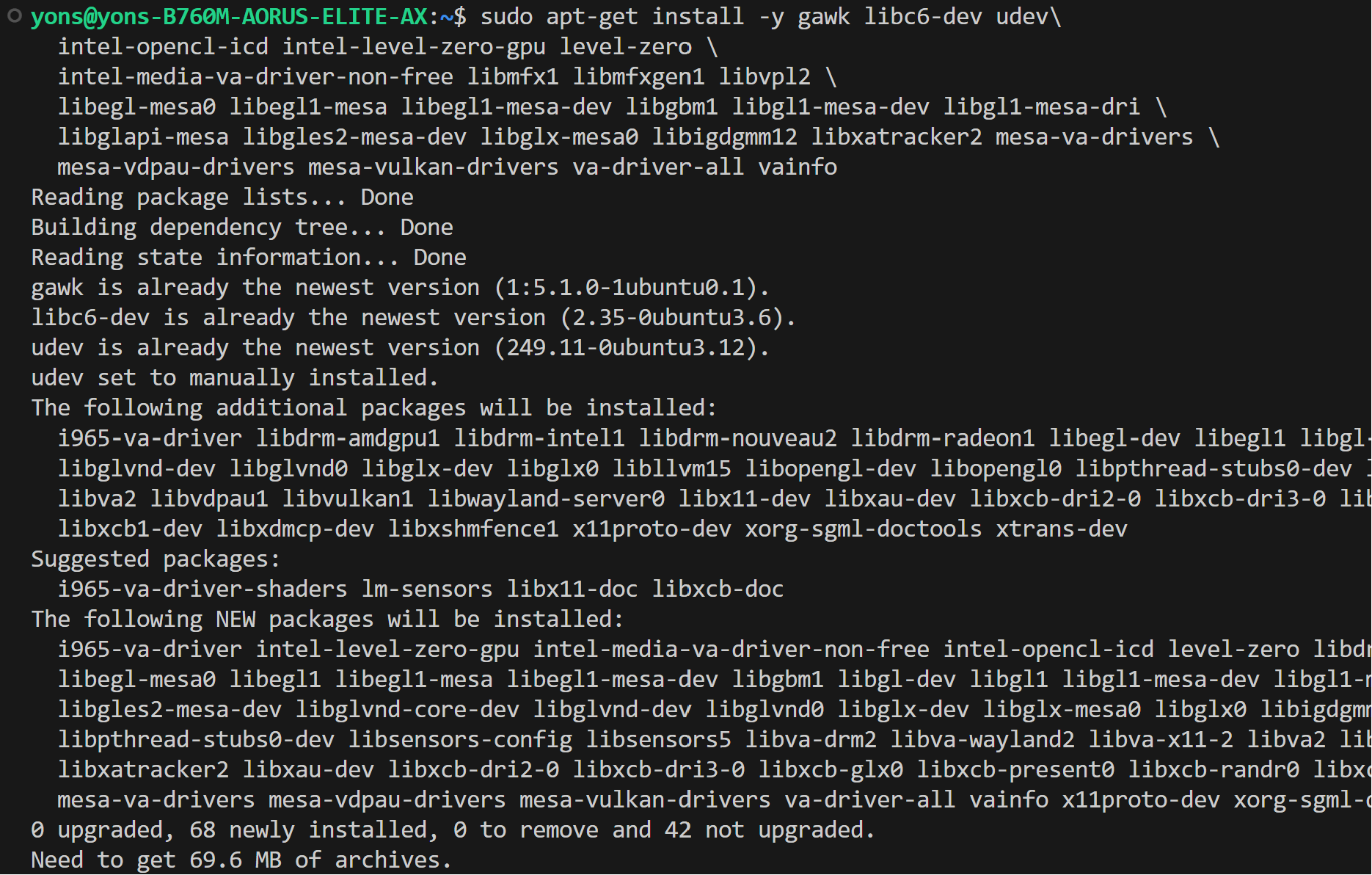 * Configure permissions
@@ -63,7 +61,7 @@ We assume that you have the 6.2 kernel on your linux machine.
## Setup Python Environment
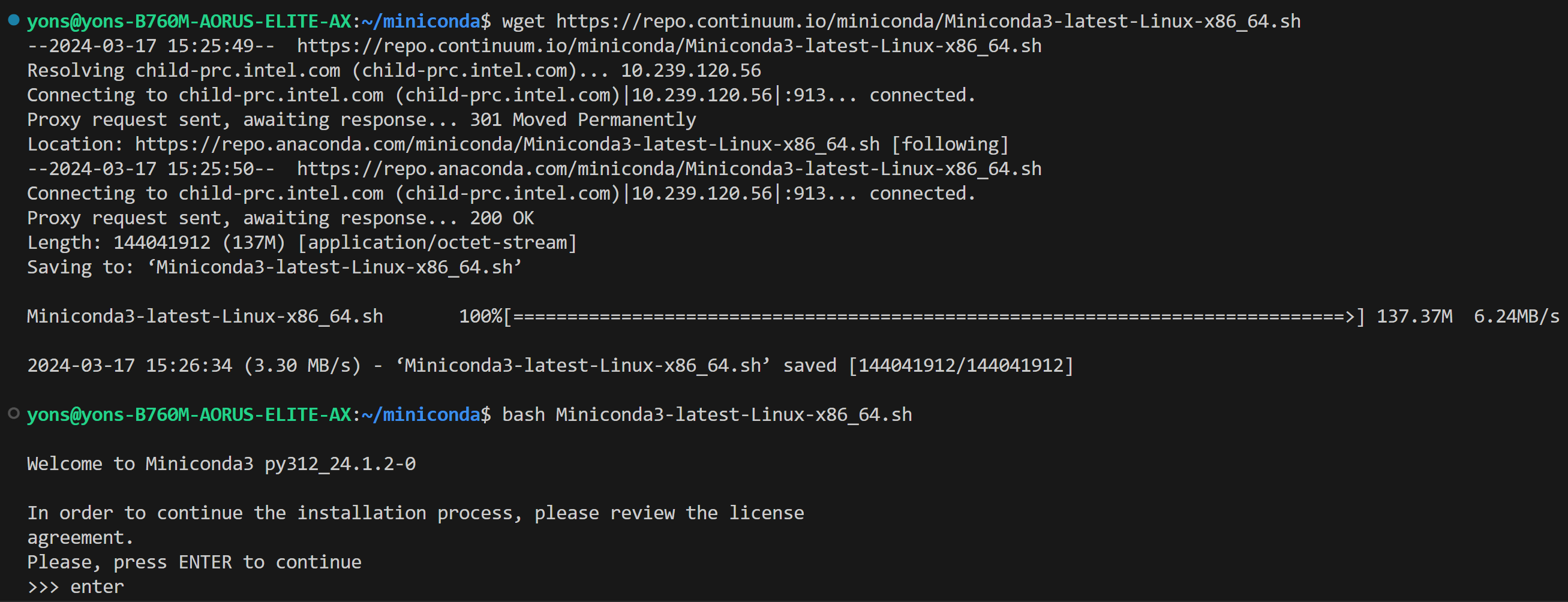
-* Install the Miniconda as follows
+Install the Miniconda as follows if you don't have conda installed on your machine:
```bash
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
@@ -75,7 +73,7 @@ We assume that you have the 6.2 kernel on your linux machine.
conda --version
# rm Miniconda3-latest-Linux-x86_64.sh # if you don't need this file any longer
```
- >
* Configure permissions
@@ -63,7 +61,7 @@ We assume that you have the 6.2 kernel on your linux machine.
## Setup Python Environment
-* Install the Miniconda as follows
+Install the Miniconda as follows if you don't have conda installed on your machine:
```bash
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
@@ -75,7 +73,7 @@ We assume that you have the 6.2 kernel on your linux machine.
conda --version
# rm Miniconda3-latest-Linux-x86_64.sh # if you don't need this file any longer
```
- >  + >
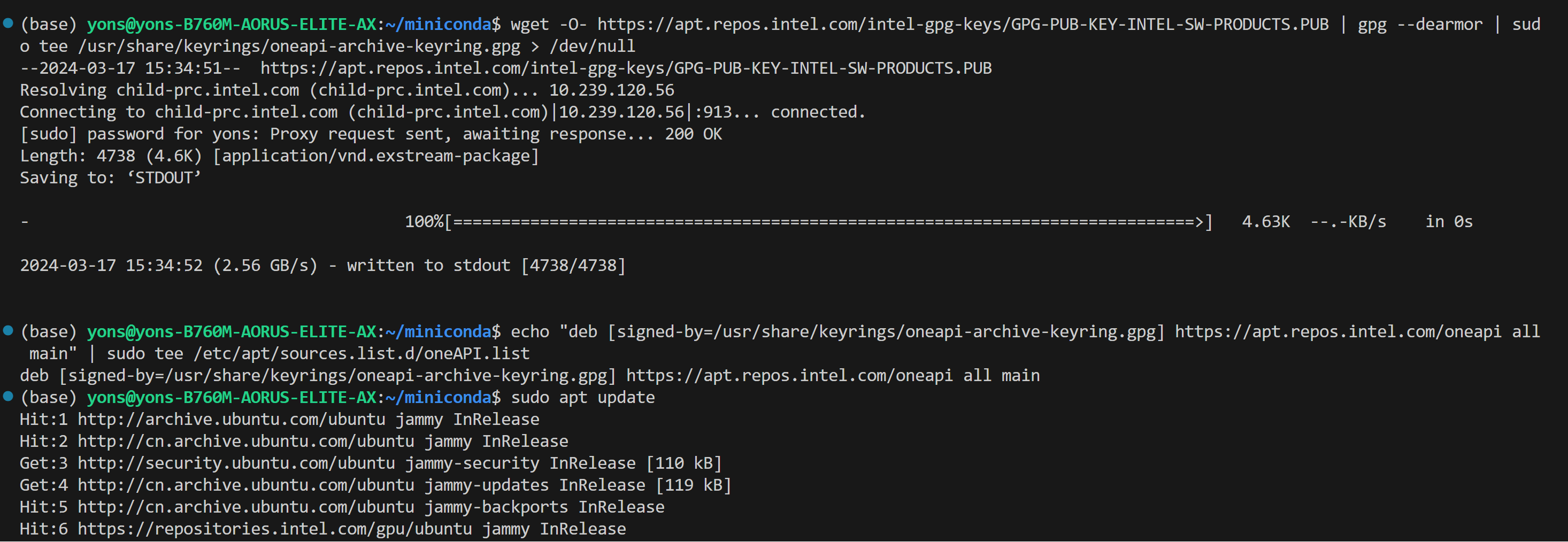
+ >  ## Install oneAPI
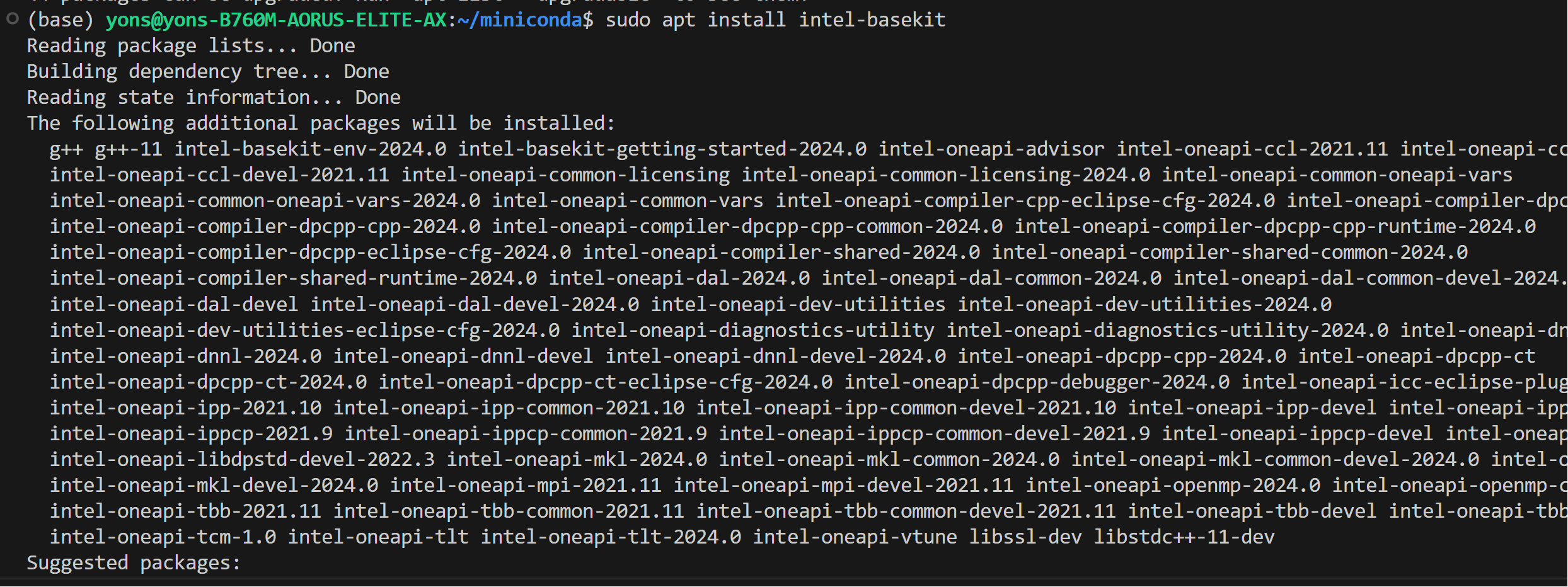
@@ -88,9 +86,9 @@ We assume that you have the 6.2 kernel on your linux machine.
sudo apt install intel-basekit
```
- >
## Install oneAPI
@@ -88,9 +86,9 @@ We assume that you have the 6.2 kernel on your linux machine.
sudo apt install intel-basekit
```
- >  + >
+ >  - >
- >  + >
+ >  ## Install `bigdl-llm`
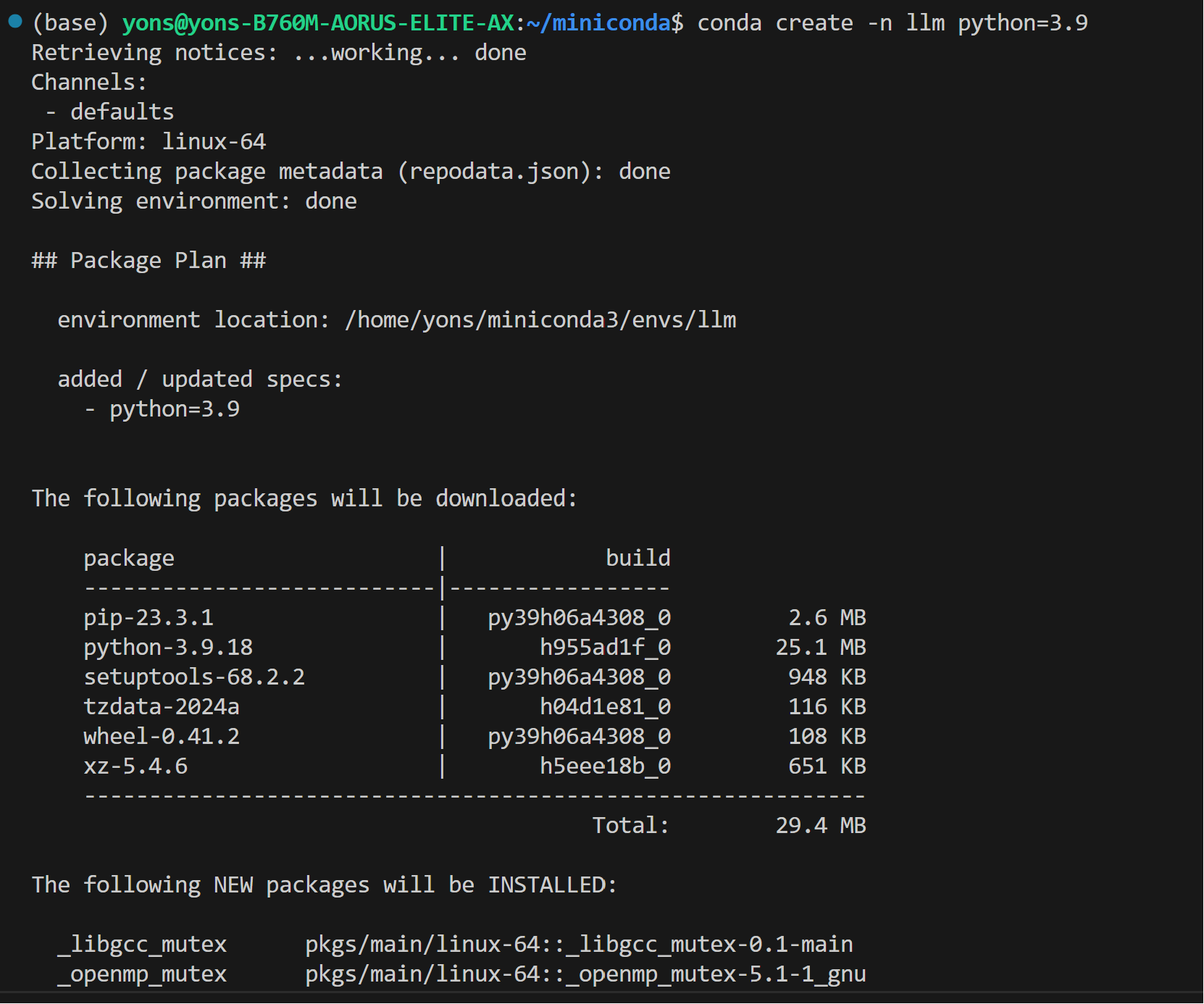
@@ -103,24 +101,24 @@ We assume that you have the 6.2 kernel on your linux machine.
pip install --pre --upgrade bigdl-llm[xpu] --extra-index-url https://developer.intel.com/ipex-whl-stable-xpu
```
- >
## Install `bigdl-llm`
@@ -103,24 +101,24 @@ We assume that you have the 6.2 kernel on your linux machine.
pip install --pre --upgrade bigdl-llm[xpu] --extra-index-url https://developer.intel.com/ipex-whl-stable-xpu
```
- >  + >
+ >  - >
- >  + >
-* You can verfy if bigdl-llm is successfully by simply importing a few classes from the library. For example, execute the following import command in terminal:
+* You can verify if bigdl-llm is successfully installed by simply importing a few classes from the library. For example, execute the following import command in the terminal:
```bash
source /opt/intel/oneapi/setvars.sh
python
- > from bigdl.llm.transformers import AutoModel,AutoModelForCausalLM
+ > from bigdl.llm.transformers import AutoModel, AutoModelForCausalLM
```
- >
+ >
-* You can verfy if bigdl-llm is successfully by simply importing a few classes from the library. For example, execute the following import command in terminal:
+* You can verify if bigdl-llm is successfully installed by simply importing a few classes from the library. For example, execute the following import command in the terminal:
```bash
source /opt/intel/oneapi/setvars.sh
python
- > from bigdl.llm.transformers import AutoModel,AutoModelForCausalLM
+ > from bigdl.llm.transformers import AutoModel, AutoModelForCausalLM
```
- >  + >
+ >  -## Runtime Configuration
+## Runtime Configurations
To use GPU acceleration on Linux, several environment variables are required or recommended before running a GPU example.
@@ -147,7 +145,7 @@ To use GPU acceleration on Linux, several environment variables are required or
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
export ENABLE_SDP_FUSION=1
```
- Please note that libtcmalloc.so can be installed by conda install -c conda-forge -y gperftools=2.10
+ Please note that `libtcmalloc.so` can be installed by ```conda install -c conda-forge -y gperftools=2.10```.
## A Quick Example
@@ -213,5 +211,5 @@ Now let's play with a real LLM. We'll be using the [phi-1.5](https://huggingface
## Tips & Troubleshooting
### Warmup for optimial performance on first run
-When running LLMs on GPU for the first time, you might notice the performance is lower than expected, with delays up to several minutes before the first token is generated. This delay occurs because the GPU kernels require compilation and initialization, which varies across different GPU models. To achieve optimal and consistent performance, we recommend a one-time warm-up by running `model.generate(...)` an additional time before starting your actual generation tasks. If you're developing an application, you can incorporate this warmup step into start-up or loading routine to enhance the user experience.
+When running LLMs on GPU for the first time, you might notice the performance is lower than expected, with delays up to several minutes before the first token is generated. This delay occurs because the GPU kernels require compilation and initialization, which varies across different GPU types. To achieve optimal and consistent performance, we recommend a one-time warm-up by running `model.generate(...)` an additional time before starting your actual generation tasks. If you're developing an application, you can incorporate this warmup step into start-up or loading routine to enhance the user experience.
-## Runtime Configuration
+## Runtime Configurations
To use GPU acceleration on Linux, several environment variables are required or recommended before running a GPU example.
@@ -147,7 +145,7 @@ To use GPU acceleration on Linux, several environment variables are required or
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
export ENABLE_SDP_FUSION=1
```
- Please note that libtcmalloc.so can be installed by conda install -c conda-forge -y gperftools=2.10
+ Please note that `libtcmalloc.so` can be installed by ```conda install -c conda-forge -y gperftools=2.10```.
## A Quick Example
@@ -213,5 +211,5 @@ Now let's play with a real LLM. We'll be using the [phi-1.5](https://huggingface
## Tips & Troubleshooting
### Warmup for optimial performance on first run
-When running LLMs on GPU for the first time, you might notice the performance is lower than expected, with delays up to several minutes before the first token is generated. This delay occurs because the GPU kernels require compilation and initialization, which varies across different GPU models. To achieve optimal and consistent performance, we recommend a one-time warm-up by running `model.generate(...)` an additional time before starting your actual generation tasks. If you're developing an application, you can incorporate this warmup step into start-up or loading routine to enhance the user experience.
+When running LLMs on GPU for the first time, you might notice the performance is lower than expected, with delays up to several minutes before the first token is generated. This delay occurs because the GPU kernels require compilation and initialization, which varies across different GPU types. To achieve optimal and consistent performance, we recommend a one-time warm-up by running `model.generate(...)` an additional time before starting your actual generation tasks. If you're developing an application, you can incorporate this warmup step into start-up or loading routine to enhance the user experience.