From 86b81c09d90fe90f005afe931330d4c0fff33491 Mon Sep 17 00:00:00 2001
From: SichengStevenLi <144295301+SichengStevenLi@users.noreply.github.com>
Date: Fri, 28 Jun 2024 10:41:00 +0800
Subject: [PATCH] Table of Contents in Quickstart Files (#11437)
* fixed a minor grammar mistake
* added table of contents
* added table of contents
* changed table of contents indexing
* added table of contents
* added table of contents, changed grammar
* added table of contents
* added table of contents
* added table of contents
* added table of contents
* added table of contents
* added table of contents, modified chapter numbering
* fixed troubleshooting section redirection path
* added table of contents
* added table of contents, modified section numbering
* added table of contents, modified section numbering
* added table of contents
* added table of contents, changed title size, modified numbering
* added table of contents, changed section title size and capitalization
* added table of contents, modified section numbering
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents syntax
* changed table of contents capitalization issue
* changed table of contents capitalization issue
* changed table of contents location
* changed table of contents
* changed table of contents
* changed section capitalization
* removed comments
* removed comments
* removed comments
---
docs/mddocs/Quickstart/README.md | 2 +-
docs/mddocs/Quickstart/axolotl_quickstart.md | 9 +++++++++
docs/mddocs/Quickstart/benchmark_quickstart.md | 13 ++++++++++---
docs/mddocs/Quickstart/bigdl_llm_migration.md | 5 +++++
docs/mddocs/Quickstart/chatchat_quickstart.md | 10 +++++++++-
docs/mddocs/Quickstart/continue_quickstart.md | 7 +++++++
.../deepspeed_autotp_fastapi_quickstart.md | 5 +++++
docs/mddocs/Quickstart/dify_quickstart.md | 7 +++++++
docs/mddocs/Quickstart/fastchat_quickstart.md | 5 +++++
docs/mddocs/Quickstart/install_linux_gpu.md | 9 +++++++++
docs/mddocs/Quickstart/install_windows_gpu.md | 8 ++++++++
.../llama3_llamacpp_ollama_quickstart.md | 6 ++++++
docs/mddocs/Quickstart/llama_cpp_quickstart.md | 15 ++++++++++++---
docs/mddocs/Quickstart/ollama_quickstart.md | 15 +++++++++++----
.../open_webui_with_ollama_quickstart.md | 11 +++++++++--
docs/mddocs/Quickstart/privateGPT_quickstart.md | 6 ++++++
docs/mddocs/Quickstart/ragflow_quickstart.md | 12 ++++++++++--
docs/mddocs/Quickstart/vLLM_quickstart.md | 17 ++++++++++++-----
docs/mddocs/Quickstart/webui_quickstart.md | 14 +++++++++++---
19 files changed, 152 insertions(+), 24 deletions(-)
diff --git a/docs/mddocs/Quickstart/README.md b/docs/mddocs/Quickstart/README.md
index 3294761c..2f76c59b 100644
--- a/docs/mddocs/Quickstart/README.md
+++ b/docs/mddocs/Quickstart/README.md
@@ -1,7 +1,7 @@
# IPEX-LLM Quickstart
> [!NOTE]
-> We are adding more Quickstart guide.
+> We are adding more Quickstart guides.
This section includes efficient guide to show you how to:
diff --git a/docs/mddocs/Quickstart/axolotl_quickstart.md b/docs/mddocs/Quickstart/axolotl_quickstart.md
index c0654cd2..e50b9f8e 100644
--- a/docs/mddocs/Quickstart/axolotl_quickstart.md
+++ b/docs/mddocs/Quickstart/axolotl_quickstart.md
@@ -13,6 +13,15 @@ See the demo of finetuning LLaMA2-7B on Intel Arc GPU below.
+## Table of Contents
+- [Prerequisites](./axolotl_quickstart.md#0-prerequisites)
+- [Install IPEX-LLM for Axolotl](./axolotl_quickstart.md#1-install-ipex-llm-for-axolotl)
+- [Example: Finetune Llama-2-7B with Axolotl](./axolotl_quickstart.md#2-example-finetune-llama-2-7b-with-axolotl)
+- [Finetune Llama-3-8B (Experimental)](./axolotl_quickstart.md#3-finetune-llama-3-8b-experimental)
+- [Troubleshooting](./axolotl_quickstart.md#troubleshooting)
+
+
+
## Quickstart
### 0. Prerequisites
diff --git a/docs/mddocs/Quickstart/benchmark_quickstart.md b/docs/mddocs/Quickstart/benchmark_quickstart.md
index a677398e..fc5ce949 100644
--- a/docs/mddocs/Quickstart/benchmark_quickstart.md
+++ b/docs/mddocs/Quickstart/benchmark_quickstart.md
@@ -2,7 +2,14 @@
We can perform benchmarking for IPEX-LLM on Intel CPUs and GPUs using the benchmark scripts we provide.
-## Prepare The Environment
+## Table of Contents
+- [Prepare the Environment](./benchmark_quickstart.md#prepare-the-environment)
+- [Prepare the Scripts](./benchmark_quickstart.md#prepare-the-scripts)
+- [Run on Windows](./benchmark_quickstart.md#run-on-windows)
+- [Run on Linux](./benchmark_quickstart.md#run-on-linux)
+- [Result](./benchmark_quickstart.md#result)
+
+## Prepare the Environment
You can refer to [here](../Overview/install.md) to install IPEX-LLM in your environment. The following dependencies are also needed to run the benchmark scripts.
@@ -11,7 +18,7 @@ pip install pandas
pip install omegaconf
```
-## Prepare The Scripts
+## Prepare the Scripts
Navigate to your local workspace and then download IPEX-LLM from GitHub. Modify the `config.yaml` under `all-in-one` folder for your benchmark configurations.
@@ -21,7 +28,7 @@ git clone https://github.com/intel-analytics/ipex-llm.git
cd ipex-llm/python/llm/dev/benchmark/all-in-one/
```
-## config.yaml
+### config.yaml
```yaml
diff --git a/docs/mddocs/Quickstart/bigdl_llm_migration.md b/docs/mddocs/Quickstart/bigdl_llm_migration.md
index 0b7643e1..f6a76f34 100644
--- a/docs/mddocs/Quickstart/bigdl_llm_migration.md
+++ b/docs/mddocs/Quickstart/bigdl_llm_migration.md
@@ -2,6 +2,11 @@
This guide helps you migrate your `bigdl-llm` application to use `ipex-llm`.
+## Table of Contents
+- [Upgrade `bigdl-llm` package to `ipex-llm`](./bigdl_llm_migration.md#1-upgrade-bigdl-llm-code-to-ipex-llm)
+- [Migrate `bigdl-llm` code to `ipex-llm`](./bigdl_llm_migration.md#migrate-bigdl-llm-code-to-ipex-llm)
+
+
## Upgrade `bigdl-llm` package to `ipex-llm`
> [!NOTE]
diff --git a/docs/mddocs/Quickstart/chatchat_quickstart.md b/docs/mddocs/Quickstart/chatchat_quickstart.md
index 217d199c..8aaa4307 100644
--- a/docs/mddocs/Quickstart/chatchat_quickstart.md
+++ b/docs/mddocs/Quickstart/chatchat_quickstart.md
@@ -21,12 +21,20 @@
> [!NOTE]
> You can change the UI language in the left-side menu. We currently support **English** and **简体中文** (see video demos below).
+## Table of Contents
+- [Langchain-Chatchat Architecture](./chatchat_quickstart.md#langchain-chatchat-architecture)
+- [Install and Run](./chatchat_quickstart.md#install-and-run)
+- [How to Use RAG](./chatchat_quickstart.md#how-to-use-rag)
+- [Troubleshooting & Tips](./chatchat_quickstart.md#troubleshooting--tips)
+
+
## Langchain-Chatchat Architecture
See the Langchain-Chatchat architecture below ([source](https://github.com/chatchat-space/Langchain-Chatchat/blob/master/docs/img/langchain%2Bchatglm.png)).
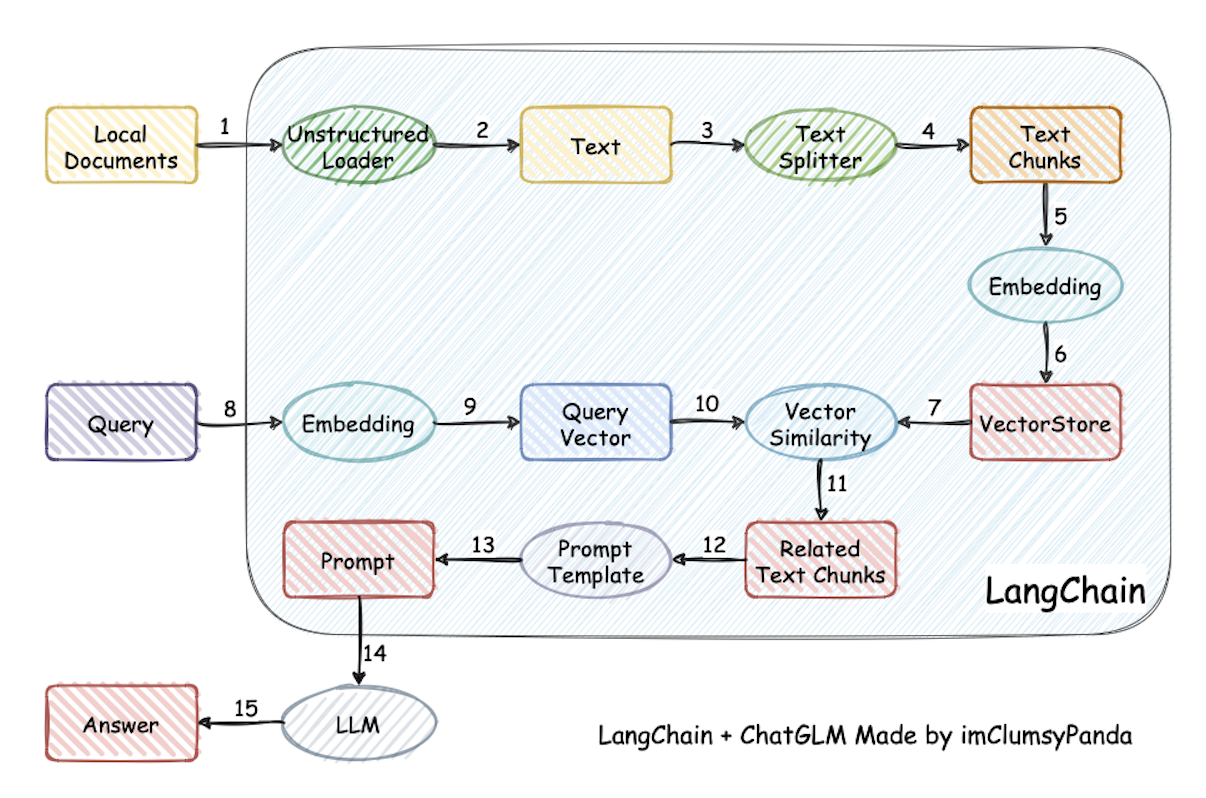 +
## Quickstart
### Install and Run
@@ -72,7 +80,7 @@ You can now click `Dialogue` on the left-side menu to return to the chat UI. The
For more information about how to use Langchain-Chatchat, refer to Official Quickstart guide in [English](https://github.com/chatchat-space/Langchain-Chatchat/blob/master/README_en.md#), [Chinese](https://github.com/chatchat-space/Langchain-Chatchat/blob/master/README.md#), or the [Wiki](https://github.com/chatchat-space/Langchain-Chatchat/wiki/).
-### Trouble Shooting & Tips
+### Troubleshooting & Tips
#### 1. Version Compatibility
diff --git a/docs/mddocs/Quickstart/continue_quickstart.md b/docs/mddocs/Quickstart/continue_quickstart.md
index 9bfbd1b1..d3feb289 100644
--- a/docs/mddocs/Quickstart/continue_quickstart.md
+++ b/docs/mddocs/Quickstart/continue_quickstart.md
@@ -14,6 +14,13 @@ Below is a demo of using `Continue` with [CodeQWen1.5-7B](https://huggingface.co
+## Table of Contents
+- [Install and Run Ollama Serve](./continue_quickstart.md#1-install-and-run-ollama-serve)
+- [Pull and Prepare the Model](./continue_quickstart.md#2-pull-and-prepare-the-model)
+- [Install `Continue` Extension](./continue_quickstart.md#3-install-continue-extension)
+- [`Continue` Configuration](./continue_quickstart.md#4-continue-configuration)
+- [How to Use `Continue`](./continue_quickstart.md#5-how-to-use-continue)
+
## Quickstart
This guide walks you through setting up and running **Continue** within _Visual Studio Code_, empowered by local large language models served via [Ollama](./ollama_quickstart.md) with `ipex-llm` optimizations.
diff --git a/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md b/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md
index 17e51dca..0fa9888b 100644
--- a/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md
+++ b/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md
@@ -2,6 +2,11 @@
This example demonstrates how to run IPEX-LLM serving on multiple [Intel GPUs](../../../python/llm/example/GPU/README.md) by leveraging DeepSpeed AutoTP.
+## Table of Contents
+- [Requirements](./deepspeed_autotp_fastapi_quickstart.md#requirements)
+- [Example](./deepspeed_autotp_fastapi_quickstart.md#example)
+
+
## Requirements
To run this example with IPEX-LLM on Intel GPUs, we have some recommended requirements for your machine, please refer to [here](../../../python/llm/example/GPU/README.md#requirements) for more information. For this particular example, you will need at least two GPUs on your machine.
diff --git a/docs/mddocs/Quickstart/dify_quickstart.md b/docs/mddocs/Quickstart/dify_quickstart.md
index d507f9bd..68c6544d 100644
--- a/docs/mddocs/Quickstart/dify_quickstart.md
+++ b/docs/mddocs/Quickstart/dify_quickstart.md
@@ -15,6 +15,13 @@
+## Table of Contents
+- [Install and Start Ollama Service on Intel GPU](./dify_quickstart.md#1-install-and-start-ollama-service-on-intel-gpu)
+- [Install and Start Dify](./dify_quickstart.md#2-install-and-start-dify)
+- [How to Use Dify](./dify_quickstart.md#3-how-to-use-dify)
+
+
+
## Quickstart
### 1. Install and Start `Ollama` Service on Intel GPU
diff --git a/docs/mddocs/Quickstart/fastchat_quickstart.md b/docs/mddocs/Quickstart/fastchat_quickstart.md
index e89c64f6..43145739 100644
--- a/docs/mddocs/Quickstart/fastchat_quickstart.md
+++ b/docs/mddocs/Quickstart/fastchat_quickstart.md
@@ -4,6 +4,11 @@ FastChat is an open platform for training, serving, and evaluating large languag
IPEX-LLM can be easily integrated into FastChat so that user can use `IPEX-LLM` as a serving backend in the deployment.
+## Table of Contents
+- [Install IPEX-LLM with FastChat](./fastchat_quickstart.md#1-install-ipex-llm-with-fastchat)
+- [Start the Service](./fastchat_quickstart.md#2-start-the-service)
+
+
## Quick Start
This quickstart guide walks you through installing and running `FastChat` with `ipex-llm`.
diff --git a/docs/mddocs/Quickstart/install_linux_gpu.md b/docs/mddocs/Quickstart/install_linux_gpu.md
index afb64e6f..8fc0c8ff 100644
--- a/docs/mddocs/Quickstart/install_linux_gpu.md
+++ b/docs/mddocs/Quickstart/install_linux_gpu.md
@@ -4,6 +4,15 @@ This guide demonstrates how to install IPEX-LLM on Linux with Intel GPUs. It app
IPEX-LLM currently supports the Ubuntu 20.04 operating system and later, and supports PyTorch 2.0 and PyTorch 2.1 on Linux. This page demonstrates IPEX-LLM with PyTorch 2.1. Check the [Installation](../Overview/install_gpu.md#linux) page for more details.
+
+## Table of Contents
+- [Install Prerequisites](./install_linux_gpu.md#install-prerequisites)
+- [Install ipex-llm](./install_linux_gpu.md#install-ipex-llm)
+- [Verify Installation](./install_linux_gpu.md#verify-installation)
+- [Runtime Configurations](./install_linux_gpu.md#runtime-configurations)
+- [A Quick Example](./install_linux_gpu.md#a-quick-example)
+- [Tips & Troubleshooting](./install_linux_gpu.md#tips--troubleshooting)
+
## Install Prerequisites
### Install GPU Driver
diff --git a/docs/mddocs/Quickstart/install_windows_gpu.md b/docs/mddocs/Quickstart/install_windows_gpu.md
index eb7fa9f9..a77d855b 100644
--- a/docs/mddocs/Quickstart/install_windows_gpu.md
+++ b/docs/mddocs/Quickstart/install_windows_gpu.md
@@ -4,6 +4,14 @@ This guide demonstrates how to install IPEX-LLM on Windows with Intel GPUs.
It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU.
+## Table of Contents
+- [Install Prerequisites](./install_windows_gpu.md#install-prerequisites)
+- [Install ipex-llm](./install_windows_gpu.md#install-ipex-llm)
+- [Verify Installation](./install_windows_gpu.md#verify-installation)
+- [Monitor GPU Status](./install_windows_gpu.md#monitor-gpu-status)
+- [A Quick Example](./install_windows_gpu.md#a-quick-example)
+- [Tips & Troubleshooting](./install_windows_gpu.md#tips--troubleshooting)
+
## Install Prerequisites
### (Optional) Update GPU Driver
diff --git a/docs/mddocs/Quickstart/llama3_llamacpp_ollama_quickstart.md b/docs/mddocs/Quickstart/llama3_llamacpp_ollama_quickstart.md
index 8ab22500..5f2dabe7 100644
--- a/docs/mddocs/Quickstart/llama3_llamacpp_ollama_quickstart.md
+++ b/docs/mddocs/Quickstart/llama3_llamacpp_ollama_quickstart.md
@@ -15,6 +15,12 @@ See the demo of running Llama-3-8B-Instruct on Intel Arc GPU using `Ollama` belo
+## Table of Contents
+- [Run Llama 3 using llama.cpp](./llama3_llamacpp_ollama_quickstart.md#1-run-llama-3-using-llamacpp)
+- [Run Llama3 using Ollama](./llama3_llamacpp_ollama_quickstart.md#2-run-llama3-using-ollama)
+
+
+
## Quick Start
This quickstart guide walks you through how to run Llama 3 on Intel GPU using `llama.cpp` / `Ollama` with IPEX-LLM.
diff --git a/docs/mddocs/Quickstart/llama_cpp_quickstart.md b/docs/mddocs/Quickstart/llama_cpp_quickstart.md
index 1297f474..adcccd39 100644
--- a/docs/mddocs/Quickstart/llama_cpp_quickstart.md
+++ b/docs/mddocs/Quickstart/llama_cpp_quickstart.md
@@ -18,6 +18,15 @@ See the demo of running LLaMA2-7B on Intel Arc GPU below.
>
> Our latest version is consistent with [62bfef5](https://github.com/ggerganov/llama.cpp/commit/62bfef5194d5582486d62da3db59bf44981b7912) of llama.cpp.
+## Table of Contents
+- [Prerequisites](./llama_cpp_quickstart.md#0-prerequisites)
+- [Install IPEX-LLM for llama.cpp](./llama_cpp_quickstart.md#1-install-ipex-llm-for-llamacpp)
+- [Setup for running llama.cpp](./llama_cpp_quickstart.md#2-setup-for-running-llamacpp)
+- [Example: Running community GGUF models with IPEX-LLM](./llama_cpp_quickstart.md#3-example-running-community-gguf-models-with-ipex-llm)
+- [Troubleshooting](./llama_cpp_quickstart.md#troubleshooting)
+
+
+
## Quick Start
This quickstart guide walks you through installing and running `llama.cpp` with `ipex-llm`.
@@ -35,7 +44,7 @@ IPEX-LLM backend for llama.cpp only supports the more recent GPU drivers. Please
If you have lower GPU driver version, visit the [Install IPEX-LLM on Windows with Intel GPU Guide](./install_windows_gpu.md), and follow [Update GPU driver](./install_windows_gpu.md#optional-update-gpu-driver).
-### 1 Install IPEX-LLM for llama.cpp
+### 1. Install IPEX-LLM for llama.cpp
To use `llama.cpp` with IPEX-LLM, first ensure that `ipex-llm[cpp]` is installed.
@@ -59,7 +68,7 @@ To use `llama.cpp` with IPEX-LLM, first ensure that `ipex-llm[cpp]` is installed
**After the installation, you should have created a conda environment, named `llm-cpp` for instance, for running `llama.cpp` commands with IPEX-LLM.**
-### 2 Setup for running llama.cpp
+### 2. Setup for running llama.cpp
First you should create a directory to use `llama.cpp`, for instance, use following command to create a `llama-cpp` directory and enter it.
```cmd
@@ -127,7 +136,7 @@ To use GPU acceleration, several environment variables are required or recommend
> export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
> ```
-### 3 Example: Running community GGUF models with IPEX-LLM
+### 3. Example: Running community GGUF models with IPEX-LLM
Here we provide a simple example to show how to run a community GGUF model with IPEX-LLM.
diff --git a/docs/mddocs/Quickstart/ollama_quickstart.md b/docs/mddocs/Quickstart/ollama_quickstart.md
index 98a8be98..4846f82c 100644
--- a/docs/mddocs/Quickstart/ollama_quickstart.md
+++ b/docs/mddocs/Quickstart/ollama_quickstart.md
@@ -18,9 +18,16 @@ See the demo of running LLaMA2-7B on Intel Arc GPU below.
>
> Our current version is consistent with [v0.1.39](https://github.com/ollama/ollama/releases/tag/v0.1.39) of ollama.
+## Table of Contents
+- [Install IPEX-LLM for Ollama](./ollama_quickstart.md#1-install-ipex-llm-for-ollama)
+- [Initialize Ollama](./ollama_quickstart.md#2-initialize-ollama)
+- [Run Ollama Serve](./ollama_quickstart.md#3-run-ollama-serve)
+- [Pull Model](./ollama_quickstart.md#4-pull-model)
+- [Using Ollama](./ollama_quickstart.md#5-using-ollama)
+
## Quickstart
-### 1 Install IPEX-LLM for Ollama
+### 1. Install IPEX-LLM for Ollama
IPEX-LLM's support for `ollama` now is available for Linux system and Windows system.
@@ -53,7 +60,7 @@ Activate the `llm-cpp` conda environment and initialize Ollama by executing the
**Now you can use this executable file by standard ollama's usage.**
-### 3 Run Ollama Serve
+### 3. Run Ollama Serve
You may launch the Ollama service as below:
@@ -102,7 +109,7 @@ The console will display messages similar to the following:
-### 4 Pull Model
+### 4. Pull Model
Keep the Ollama service on and open another terminal and run `./ollama pull ` in Linux (`ollama.exe pull ` in Windows) to automatically pull a model. e.g. `dolphin-phi:latest`:
@@ -110,7 +117,7 @@ Keep the Ollama service on and open another terminal and run `./ollama pull
-### 5 Using Ollama
+### 5. Using Ollama
#### Using Curl
diff --git a/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md b/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md
index 6981b464..be975a4b 100644
--- a/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md
+++ b/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md
@@ -13,16 +13,23 @@
+## Table of Contents
+- [Run Ollama with Intel GPU](./open_webui_with_ollama_quickstart.md#1-run-ollama-with-intel-gpu)
+- [Install the Open-Webui](./open_webui_with_ollama_quickstart.md#2-install-the-open-webui)
+- [Start the Open-WebUI](./open_webui_with_ollama_quickstart.md#3-start-the-open-webui)
+- [Using the Open-Webui](./open_webui_with_ollama_quickstart.md#4-using-the-open-webui)
+- [Troubleshooting](./open_webui_with_ollama_quickstart.md#5-troubleshooting)
+
## Quickstart
This quickstart guide walks you through setting up and using [Open WebUI](https://github.com/open-webui/open-webui) with Ollama (using the C++ interface of [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) as an accelerated backend).
-### 1 Run Ollama with Intel GPU
+### 1. Run Ollama with Intel GPU
Follow the instructions on the [Run Ollama with Intel GPU](./ollama_quickstart.md) to install and run "Ollama Serve". Please ensure that the Ollama server continues to run while you're using the Open WebUI.
-### 2 Install the Open-Webui
+### 2. Install the Open-Webui
#### Install Node.js & npm
diff --git a/docs/mddocs/Quickstart/privateGPT_quickstart.md b/docs/mddocs/Quickstart/privateGPT_quickstart.md
index b95599d5..b7a53fc3 100644
--- a/docs/mddocs/Quickstart/privateGPT_quickstart.md
+++ b/docs/mddocs/Quickstart/privateGPT_quickstart.md
@@ -13,6 +13,12 @@
+## Table of Contents
+- [Install and Start `Ollama` Service on Intel GPU](./privateGPT_quickstart.md#1-install-and-start-ollama-service-on-intel-gpu)
+- [Install PrivateGPT](./privateGPT_quickstart.md#2-install-privategpt)
+- [Start PrivateGPT](./privateGPT_quickstart.md#3-start-privategpt)
+- [Using PrivateGPT](./privateGPT_quickstart.md#4-using-privategpt)
+
## Quickstart
### 1. Install and Start `Ollama` Service on Intel GPU
diff --git a/docs/mddocs/Quickstart/ragflow_quickstart.md b/docs/mddocs/Quickstart/ragflow_quickstart.md
index 254aa372..22251831 100644
--- a/docs/mddocs/Quickstart/ragflow_quickstart.md
+++ b/docs/mddocs/Quickstart/ragflow_quickstart.md
@@ -14,9 +14,17 @@
+
+## Table of Contents
+- [Prerequisites](./ragflow_quickstart.md#0-prerequisites)
+- [Install and Start Ollama Service on Intel GPU](./ragflow_quickstart.md#1-install-and-start-ollama-service-on-intel-gpu)
+- [Pull Model](./ragflow_quickstart.md#2-pull-model)
+- [Start `RAGFlow` Service](./ragflow_quickstart.md#3-start-ragflow-service)
+- [Using `RAGFlow`](./ragflow_quickstart.md#4-using-ragflow)
+
## Quickstart
-### 0 Prerequisites
+### 0. Prerequisites
- CPU >= 4 cores
- RAM >= 16 GB
@@ -95,7 +103,7 @@ To make the change permanent and ensure it persists after a reboot, add or updat
vm.max_map_count=262144
```
-### 3.3 Start the `RAGFlow` server using Docker
+#### 3.3 Start the `RAGFlow` server using Docker
Build the pre-built Docker images and start up the server:
diff --git a/docs/mddocs/Quickstart/vLLM_quickstart.md b/docs/mddocs/Quickstart/vLLM_quickstart.md
index 155fd321..764b35c1 100644
--- a/docs/mddocs/Quickstart/vLLM_quickstart.md
+++ b/docs/mddocs/Quickstart/vLLM_quickstart.md
@@ -11,6 +11,13 @@ Currently, IPEX-LLM integrated vLLM only supports the following models:
- ChatGLM series models
- Baichuan series models
+## Table of Contents
+- [Install IPEX-LLM for vLLM](./vLLM_quickstart.md#1-install-ipex-llm-for-vllm)
+- [Install vLLM](./vLLM_quickstart.md#2-install-vllm)
+- [Offline Inference/Service](./vLLM_quickstart.md#3-offline-inferenceservice)
+- [About Tensor Parallel](./vLLM_quickstart.md#4-about-tensor-parallel)
+- [Performing Benchmark](./vLLM_quickstart.md#5-performing-benchmark)
+
## Quick Start
@@ -48,9 +55,9 @@ pip install transformers_stream_generator einops tiktoken
**Now you are all set to use vLLM with IPEX-LLM**
-## 3. Offline inference/Service
+### 3. Offline Inference/Service
-### Offline inference
+#### Offline inference
To run offline inference using vLLM for a quick impression, use the following example.
@@ -87,7 +94,7 @@ Prompt: 'The capital of France is', Generated text: ' Paris.\nThe capital of Fra
Prompt: 'The future of AI is', Generated text: " bright, but it's not without challenges. As AI continues to evolve,"
```
-### Service
+#### Service
> [!NOTE]
> Because of using JIT compilation for kernels. We recommend to send a few requests for warmup before using the service for the best performance.
@@ -170,7 +177,7 @@ Below shows an example output using `Qwen1.5-7B-Chat` with low-bit format `sym_i
> export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
> ```
-## 4. About Tensor parallel
+### 4. About Tensor Parallel
> [!NOTE]
> We recommend to use docker for tensor parallel deployment. Check our serving docker image `intelanalytics/ipex-llm-serving-xpu`.
@@ -223,7 +230,7 @@ If the service have booted successfully, you should see the output similar to th
+
## Quickstart
### Install and Run
@@ -72,7 +80,7 @@ You can now click `Dialogue` on the left-side menu to return to the chat UI. The
For more information about how to use Langchain-Chatchat, refer to Official Quickstart guide in [English](https://github.com/chatchat-space/Langchain-Chatchat/blob/master/README_en.md#), [Chinese](https://github.com/chatchat-space/Langchain-Chatchat/blob/master/README.md#), or the [Wiki](https://github.com/chatchat-space/Langchain-Chatchat/wiki/).
-### Trouble Shooting & Tips
+### Troubleshooting & Tips
#### 1. Version Compatibility
diff --git a/docs/mddocs/Quickstart/continue_quickstart.md b/docs/mddocs/Quickstart/continue_quickstart.md
index 9bfbd1b1..d3feb289 100644
--- a/docs/mddocs/Quickstart/continue_quickstart.md
+++ b/docs/mddocs/Quickstart/continue_quickstart.md
@@ -14,6 +14,13 @@ Below is a demo of using `Continue` with [CodeQWen1.5-7B](https://huggingface.co
+## Table of Contents
+- [Install and Run Ollama Serve](./continue_quickstart.md#1-install-and-run-ollama-serve)
+- [Pull and Prepare the Model](./continue_quickstart.md#2-pull-and-prepare-the-model)
+- [Install `Continue` Extension](./continue_quickstart.md#3-install-continue-extension)
+- [`Continue` Configuration](./continue_quickstart.md#4-continue-configuration)
+- [How to Use `Continue`](./continue_quickstart.md#5-how-to-use-continue)
+
## Quickstart
This guide walks you through setting up and running **Continue** within _Visual Studio Code_, empowered by local large language models served via [Ollama](./ollama_quickstart.md) with `ipex-llm` optimizations.
diff --git a/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md b/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md
index 17e51dca..0fa9888b 100644
--- a/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md
+++ b/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md
@@ -2,6 +2,11 @@
This example demonstrates how to run IPEX-LLM serving on multiple [Intel GPUs](../../../python/llm/example/GPU/README.md) by leveraging DeepSpeed AutoTP.
+## Table of Contents
+- [Requirements](./deepspeed_autotp_fastapi_quickstart.md#requirements)
+- [Example](./deepspeed_autotp_fastapi_quickstart.md#example)
+
+
## Requirements
To run this example with IPEX-LLM on Intel GPUs, we have some recommended requirements for your machine, please refer to [here](../../../python/llm/example/GPU/README.md#requirements) for more information. For this particular example, you will need at least two GPUs on your machine.
diff --git a/docs/mddocs/Quickstart/dify_quickstart.md b/docs/mddocs/Quickstart/dify_quickstart.md
index d507f9bd..68c6544d 100644
--- a/docs/mddocs/Quickstart/dify_quickstart.md
+++ b/docs/mddocs/Quickstart/dify_quickstart.md
@@ -15,6 +15,13 @@
+## Table of Contents
+- [Install and Start Ollama Service on Intel GPU](./dify_quickstart.md#1-install-and-start-ollama-service-on-intel-gpu)
+- [Install and Start Dify](./dify_quickstart.md#2-install-and-start-dify)
+- [How to Use Dify](./dify_quickstart.md#3-how-to-use-dify)
+
+
+
## Quickstart
### 1. Install and Start `Ollama` Service on Intel GPU
diff --git a/docs/mddocs/Quickstart/fastchat_quickstart.md b/docs/mddocs/Quickstart/fastchat_quickstart.md
index e89c64f6..43145739 100644
--- a/docs/mddocs/Quickstart/fastchat_quickstart.md
+++ b/docs/mddocs/Quickstart/fastchat_quickstart.md
@@ -4,6 +4,11 @@ FastChat is an open platform for training, serving, and evaluating large languag
IPEX-LLM can be easily integrated into FastChat so that user can use `IPEX-LLM` as a serving backend in the deployment.
+## Table of Contents
+- [Install IPEX-LLM with FastChat](./fastchat_quickstart.md#1-install-ipex-llm-with-fastchat)
+- [Start the Service](./fastchat_quickstart.md#2-start-the-service)
+
+
## Quick Start
This quickstart guide walks you through installing and running `FastChat` with `ipex-llm`.
diff --git a/docs/mddocs/Quickstart/install_linux_gpu.md b/docs/mddocs/Quickstart/install_linux_gpu.md
index afb64e6f..8fc0c8ff 100644
--- a/docs/mddocs/Quickstart/install_linux_gpu.md
+++ b/docs/mddocs/Quickstart/install_linux_gpu.md
@@ -4,6 +4,15 @@ This guide demonstrates how to install IPEX-LLM on Linux with Intel GPUs. It app
IPEX-LLM currently supports the Ubuntu 20.04 operating system and later, and supports PyTorch 2.0 and PyTorch 2.1 on Linux. This page demonstrates IPEX-LLM with PyTorch 2.1. Check the [Installation](../Overview/install_gpu.md#linux) page for more details.
+
+## Table of Contents
+- [Install Prerequisites](./install_linux_gpu.md#install-prerequisites)
+- [Install ipex-llm](./install_linux_gpu.md#install-ipex-llm)
+- [Verify Installation](./install_linux_gpu.md#verify-installation)
+- [Runtime Configurations](./install_linux_gpu.md#runtime-configurations)
+- [A Quick Example](./install_linux_gpu.md#a-quick-example)
+- [Tips & Troubleshooting](./install_linux_gpu.md#tips--troubleshooting)
+
## Install Prerequisites
### Install GPU Driver
diff --git a/docs/mddocs/Quickstart/install_windows_gpu.md b/docs/mddocs/Quickstart/install_windows_gpu.md
index eb7fa9f9..a77d855b 100644
--- a/docs/mddocs/Quickstart/install_windows_gpu.md
+++ b/docs/mddocs/Quickstart/install_windows_gpu.md
@@ -4,6 +4,14 @@ This guide demonstrates how to install IPEX-LLM on Windows with Intel GPUs.
It applies to Intel Core Ultra and Core 11 - 14 gen integrated GPUs (iGPUs), as well as Intel Arc Series GPU.
+## Table of Contents
+- [Install Prerequisites](./install_windows_gpu.md#install-prerequisites)
+- [Install ipex-llm](./install_windows_gpu.md#install-ipex-llm)
+- [Verify Installation](./install_windows_gpu.md#verify-installation)
+- [Monitor GPU Status](./install_windows_gpu.md#monitor-gpu-status)
+- [A Quick Example](./install_windows_gpu.md#a-quick-example)
+- [Tips & Troubleshooting](./install_windows_gpu.md#tips--troubleshooting)
+
## Install Prerequisites
### (Optional) Update GPU Driver
diff --git a/docs/mddocs/Quickstart/llama3_llamacpp_ollama_quickstart.md b/docs/mddocs/Quickstart/llama3_llamacpp_ollama_quickstart.md
index 8ab22500..5f2dabe7 100644
--- a/docs/mddocs/Quickstart/llama3_llamacpp_ollama_quickstart.md
+++ b/docs/mddocs/Quickstart/llama3_llamacpp_ollama_quickstart.md
@@ -15,6 +15,12 @@ See the demo of running Llama-3-8B-Instruct on Intel Arc GPU using `Ollama` belo
+## Table of Contents
+- [Run Llama 3 using llama.cpp](./llama3_llamacpp_ollama_quickstart.md#1-run-llama-3-using-llamacpp)
+- [Run Llama3 using Ollama](./llama3_llamacpp_ollama_quickstart.md#2-run-llama3-using-ollama)
+
+
+
## Quick Start
This quickstart guide walks you through how to run Llama 3 on Intel GPU using `llama.cpp` / `Ollama` with IPEX-LLM.
diff --git a/docs/mddocs/Quickstart/llama_cpp_quickstart.md b/docs/mddocs/Quickstart/llama_cpp_quickstart.md
index 1297f474..adcccd39 100644
--- a/docs/mddocs/Quickstart/llama_cpp_quickstart.md
+++ b/docs/mddocs/Quickstart/llama_cpp_quickstart.md
@@ -18,6 +18,15 @@ See the demo of running LLaMA2-7B on Intel Arc GPU below.
>
> Our latest version is consistent with [62bfef5](https://github.com/ggerganov/llama.cpp/commit/62bfef5194d5582486d62da3db59bf44981b7912) of llama.cpp.
+## Table of Contents
+- [Prerequisites](./llama_cpp_quickstart.md#0-prerequisites)
+- [Install IPEX-LLM for llama.cpp](./llama_cpp_quickstart.md#1-install-ipex-llm-for-llamacpp)
+- [Setup for running llama.cpp](./llama_cpp_quickstart.md#2-setup-for-running-llamacpp)
+- [Example: Running community GGUF models with IPEX-LLM](./llama_cpp_quickstart.md#3-example-running-community-gguf-models-with-ipex-llm)
+- [Troubleshooting](./llama_cpp_quickstart.md#troubleshooting)
+
+
+
## Quick Start
This quickstart guide walks you through installing and running `llama.cpp` with `ipex-llm`.
@@ -35,7 +44,7 @@ IPEX-LLM backend for llama.cpp only supports the more recent GPU drivers. Please
If you have lower GPU driver version, visit the [Install IPEX-LLM on Windows with Intel GPU Guide](./install_windows_gpu.md), and follow [Update GPU driver](./install_windows_gpu.md#optional-update-gpu-driver).
-### 1 Install IPEX-LLM for llama.cpp
+### 1. Install IPEX-LLM for llama.cpp
To use `llama.cpp` with IPEX-LLM, first ensure that `ipex-llm[cpp]` is installed.
@@ -59,7 +68,7 @@ To use `llama.cpp` with IPEX-LLM, first ensure that `ipex-llm[cpp]` is installed
**After the installation, you should have created a conda environment, named `llm-cpp` for instance, for running `llama.cpp` commands with IPEX-LLM.**
-### 2 Setup for running llama.cpp
+### 2. Setup for running llama.cpp
First you should create a directory to use `llama.cpp`, for instance, use following command to create a `llama-cpp` directory and enter it.
```cmd
@@ -127,7 +136,7 @@ To use GPU acceleration, several environment variables are required or recommend
> export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
> ```
-### 3 Example: Running community GGUF models with IPEX-LLM
+### 3. Example: Running community GGUF models with IPEX-LLM
Here we provide a simple example to show how to run a community GGUF model with IPEX-LLM.
diff --git a/docs/mddocs/Quickstart/ollama_quickstart.md b/docs/mddocs/Quickstart/ollama_quickstart.md
index 98a8be98..4846f82c 100644
--- a/docs/mddocs/Quickstart/ollama_quickstart.md
+++ b/docs/mddocs/Quickstart/ollama_quickstart.md
@@ -18,9 +18,16 @@ See the demo of running LLaMA2-7B on Intel Arc GPU below.
>
> Our current version is consistent with [v0.1.39](https://github.com/ollama/ollama/releases/tag/v0.1.39) of ollama.
+## Table of Contents
+- [Install IPEX-LLM for Ollama](./ollama_quickstart.md#1-install-ipex-llm-for-ollama)
+- [Initialize Ollama](./ollama_quickstart.md#2-initialize-ollama)
+- [Run Ollama Serve](./ollama_quickstart.md#3-run-ollama-serve)
+- [Pull Model](./ollama_quickstart.md#4-pull-model)
+- [Using Ollama](./ollama_quickstart.md#5-using-ollama)
+
## Quickstart
-### 1 Install IPEX-LLM for Ollama
+### 1. Install IPEX-LLM for Ollama
IPEX-LLM's support for `ollama` now is available for Linux system and Windows system.
@@ -53,7 +60,7 @@ Activate the `llm-cpp` conda environment and initialize Ollama by executing the
**Now you can use this executable file by standard ollama's usage.**
-### 3 Run Ollama Serve
+### 3. Run Ollama Serve
You may launch the Ollama service as below:
@@ -102,7 +109,7 @@ The console will display messages similar to the following:
-### 4 Pull Model
+### 4. Pull Model
Keep the Ollama service on and open another terminal and run `./ollama pull ` in Linux (`ollama.exe pull ` in Windows) to automatically pull a model. e.g. `dolphin-phi:latest`:
@@ -110,7 +117,7 @@ Keep the Ollama service on and open another terminal and run `./ollama pull
-### 5 Using Ollama
+### 5. Using Ollama
#### Using Curl
diff --git a/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md b/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md
index 6981b464..be975a4b 100644
--- a/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md
+++ b/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md
@@ -13,16 +13,23 @@
+## Table of Contents
+- [Run Ollama with Intel GPU](./open_webui_with_ollama_quickstart.md#1-run-ollama-with-intel-gpu)
+- [Install the Open-Webui](./open_webui_with_ollama_quickstart.md#2-install-the-open-webui)
+- [Start the Open-WebUI](./open_webui_with_ollama_quickstart.md#3-start-the-open-webui)
+- [Using the Open-Webui](./open_webui_with_ollama_quickstart.md#4-using-the-open-webui)
+- [Troubleshooting](./open_webui_with_ollama_quickstart.md#5-troubleshooting)
+
## Quickstart
This quickstart guide walks you through setting up and using [Open WebUI](https://github.com/open-webui/open-webui) with Ollama (using the C++ interface of [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) as an accelerated backend).
-### 1 Run Ollama with Intel GPU
+### 1. Run Ollama with Intel GPU
Follow the instructions on the [Run Ollama with Intel GPU](./ollama_quickstart.md) to install and run "Ollama Serve". Please ensure that the Ollama server continues to run while you're using the Open WebUI.
-### 2 Install the Open-Webui
+### 2. Install the Open-Webui
#### Install Node.js & npm
diff --git a/docs/mddocs/Quickstart/privateGPT_quickstart.md b/docs/mddocs/Quickstart/privateGPT_quickstart.md
index b95599d5..b7a53fc3 100644
--- a/docs/mddocs/Quickstart/privateGPT_quickstart.md
+++ b/docs/mddocs/Quickstart/privateGPT_quickstart.md
@@ -13,6 +13,12 @@
+## Table of Contents
+- [Install and Start `Ollama` Service on Intel GPU](./privateGPT_quickstart.md#1-install-and-start-ollama-service-on-intel-gpu)
+- [Install PrivateGPT](./privateGPT_quickstart.md#2-install-privategpt)
+- [Start PrivateGPT](./privateGPT_quickstart.md#3-start-privategpt)
+- [Using PrivateGPT](./privateGPT_quickstart.md#4-using-privategpt)
+
## Quickstart
### 1. Install and Start `Ollama` Service on Intel GPU
diff --git a/docs/mddocs/Quickstart/ragflow_quickstart.md b/docs/mddocs/Quickstart/ragflow_quickstart.md
index 254aa372..22251831 100644
--- a/docs/mddocs/Quickstart/ragflow_quickstart.md
+++ b/docs/mddocs/Quickstart/ragflow_quickstart.md
@@ -14,9 +14,17 @@
+
+## Table of Contents
+- [Prerequisites](./ragflow_quickstart.md#0-prerequisites)
+- [Install and Start Ollama Service on Intel GPU](./ragflow_quickstart.md#1-install-and-start-ollama-service-on-intel-gpu)
+- [Pull Model](./ragflow_quickstart.md#2-pull-model)
+- [Start `RAGFlow` Service](./ragflow_quickstart.md#3-start-ragflow-service)
+- [Using `RAGFlow`](./ragflow_quickstart.md#4-using-ragflow)
+
## Quickstart
-### 0 Prerequisites
+### 0. Prerequisites
- CPU >= 4 cores
- RAM >= 16 GB
@@ -95,7 +103,7 @@ To make the change permanent and ensure it persists after a reboot, add or updat
vm.max_map_count=262144
```
-### 3.3 Start the `RAGFlow` server using Docker
+#### 3.3 Start the `RAGFlow` server using Docker
Build the pre-built Docker images and start up the server:
diff --git a/docs/mddocs/Quickstart/vLLM_quickstart.md b/docs/mddocs/Quickstart/vLLM_quickstart.md
index 155fd321..764b35c1 100644
--- a/docs/mddocs/Quickstart/vLLM_quickstart.md
+++ b/docs/mddocs/Quickstart/vLLM_quickstart.md
@@ -11,6 +11,13 @@ Currently, IPEX-LLM integrated vLLM only supports the following models:
- ChatGLM series models
- Baichuan series models
+## Table of Contents
+- [Install IPEX-LLM for vLLM](./vLLM_quickstart.md#1-install-ipex-llm-for-vllm)
+- [Install vLLM](./vLLM_quickstart.md#2-install-vllm)
+- [Offline Inference/Service](./vLLM_quickstart.md#3-offline-inferenceservice)
+- [About Tensor Parallel](./vLLM_quickstart.md#4-about-tensor-parallel)
+- [Performing Benchmark](./vLLM_quickstart.md#5-performing-benchmark)
+
## Quick Start
@@ -48,9 +55,9 @@ pip install transformers_stream_generator einops tiktoken
**Now you are all set to use vLLM with IPEX-LLM**
-## 3. Offline inference/Service
+### 3. Offline Inference/Service
-### Offline inference
+#### Offline inference
To run offline inference using vLLM for a quick impression, use the following example.
@@ -87,7 +94,7 @@ Prompt: 'The capital of France is', Generated text: ' Paris.\nThe capital of Fra
Prompt: 'The future of AI is', Generated text: " bright, but it's not without challenges. As AI continues to evolve,"
```
-### Service
+#### Service
> [!NOTE]
> Because of using JIT compilation for kernels. We recommend to send a few requests for warmup before using the service for the best performance.
@@ -170,7 +177,7 @@ Below shows an example output using `Qwen1.5-7B-Chat` with low-bit format `sym_i
> export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
> ```
-## 4. About Tensor parallel
+### 4. About Tensor Parallel
> [!NOTE]
> We recommend to use docker for tensor parallel deployment. Check our serving docker image `intelanalytics/ipex-llm-serving-xpu`.
@@ -223,7 +230,7 @@ If the service have booted successfully, you should see the output similar to th
 -## 5.Performing benchmark
+### 5. Performing Benchmark
To perform benchmark, you can use the **benchmark_throughput** script that is originally provided by vLLM repo.
diff --git a/docs/mddocs/Quickstart/webui_quickstart.md b/docs/mddocs/Quickstart/webui_quickstart.md
index 2775605f..6600c6c0 100644
--- a/docs/mddocs/Quickstart/webui_quickstart.md
+++ b/docs/mddocs/Quickstart/webui_quickstart.md
@@ -13,6 +13,14 @@ See the demo of running LLaMA2-7B on an Intel Core Ultra laptop below.
+## Table of Contents
+- [Install IPEX-LLM](./webui_quickstart.md#1-install-ipex-llm)
+- [Install the WebUI](./webui_quickstart.md#2-install-the-webui)
+- [Start the WebUI Server](./webui_quickstart.md#3-start-the-webui-server)
+- [Using the WebUI](./webui_quickstart.md#4-using-the-webui)
+- [Advanced Usage](./webui_quickstart.md#5-advanced-usage)
+- [Troubleshooting](./webui_quickstart.md#troubleshooting)
+
## Quickstart
This quickstart guide walks you through setting up and using the [Text Generation WebUI](https://github.com/intel-analytics/text-generation-webui) with `ipex-llm`.
@@ -23,13 +31,13 @@ A preview of the WebUI in action is shown below:
-### 1 Install IPEX-LLM
+### 1. Install IPEX-LLM
To use the WebUI, first ensure that IPEX-LLM is installed. Follow the instructions on the [IPEX-LLM Installation Quickstart for Windows with Intel GPU](./install_windows_gpu.md).
**After the installation, you should have created a conda environment, named `llm` for instance, for running `ipex-llm` applications.**
-### 2 Install the WebUI
+### 2. Install the WebUI
#### Download the WebUI
Download the `text-generation-webui` with IPEX-LLM integrations from [this link](https://github.com/intel-analytics/text-generation-webui/archive/refs/heads/ipex-llm.zip). Unzip the content into a directory, e.g.,`C:\text-generation-webui`.
@@ -50,7 +58,7 @@ pip install -r extensions/openai/requirements.txt
> [!NOTE]
> `extensions/openai/requirements.txt` is for API service. If you don't need the API service, you can omit this command.
-### 3 Start the WebUI Server
+### 3. Start the WebUI Server
#### Set Environment Variables
Configure oneAPI variables by running the following command in **Miniforge Prompt**:
-## 5.Performing benchmark
+### 5. Performing Benchmark
To perform benchmark, you can use the **benchmark_throughput** script that is originally provided by vLLM repo.
diff --git a/docs/mddocs/Quickstart/webui_quickstart.md b/docs/mddocs/Quickstart/webui_quickstart.md
index 2775605f..6600c6c0 100644
--- a/docs/mddocs/Quickstart/webui_quickstart.md
+++ b/docs/mddocs/Quickstart/webui_quickstart.md
@@ -13,6 +13,14 @@ See the demo of running LLaMA2-7B on an Intel Core Ultra laptop below.
+## Table of Contents
+- [Install IPEX-LLM](./webui_quickstart.md#1-install-ipex-llm)
+- [Install the WebUI](./webui_quickstart.md#2-install-the-webui)
+- [Start the WebUI Server](./webui_quickstart.md#3-start-the-webui-server)
+- [Using the WebUI](./webui_quickstart.md#4-using-the-webui)
+- [Advanced Usage](./webui_quickstart.md#5-advanced-usage)
+- [Troubleshooting](./webui_quickstart.md#troubleshooting)
+
## Quickstart
This quickstart guide walks you through setting up and using the [Text Generation WebUI](https://github.com/intel-analytics/text-generation-webui) with `ipex-llm`.
@@ -23,13 +31,13 @@ A preview of the WebUI in action is shown below:
-### 1 Install IPEX-LLM
+### 1. Install IPEX-LLM
To use the WebUI, first ensure that IPEX-LLM is installed. Follow the instructions on the [IPEX-LLM Installation Quickstart for Windows with Intel GPU](./install_windows_gpu.md).
**After the installation, you should have created a conda environment, named `llm` for instance, for running `ipex-llm` applications.**
-### 2 Install the WebUI
+### 2. Install the WebUI
#### Download the WebUI
Download the `text-generation-webui` with IPEX-LLM integrations from [this link](https://github.com/intel-analytics/text-generation-webui/archive/refs/heads/ipex-llm.zip). Unzip the content into a directory, e.g.,`C:\text-generation-webui`.
@@ -50,7 +58,7 @@ pip install -r extensions/openai/requirements.txt
> [!NOTE]
> `extensions/openai/requirements.txt` is for API service. If you don't need the API service, you can omit this command.
-### 3 Start the WebUI Server
+### 3. Start the WebUI Server
#### Set Environment Variables
Configure oneAPI variables by running the following command in **Miniforge Prompt**:
