diff --git a/README.md b/README.md
index 7cc5a356..b1aee474 100644
--- a/README.md
+++ b/README.md
@@ -77,21 +77,33 @@ See the demo of running [*Text-Generation-WebUI*](https://ipex-llm.readthedocs.i
[^1]: Performance varies by use, configuration and other factors. `ipex-llm` may not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex.
## `ipex-llm` Quickstart
-### Install `ipex-llm`
-- [Windows GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_windows_gpu.html): installing `ipex-llm` on Windows with Intel GPU
-- [Linux GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html): installing `ipex-llm` on Linux with Intel GPU
-- [Docker](docker/llm): using `ipex-llm` dockers on Intel CPU and GPU
-- *For more details, please refer to the [installation guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install.html)*
-### Run `ipex-llm`
+### Docker
+- [GPU Inference in C++](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/DockerGuides/docker_cpp_xpu_quickstart.html): running `llama.cpp`, `ollama`, `OpenWebUI`, etc., with `ipex-llm` on Intel GPU
+- [GPU Inference in Python](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/DockerGuides/docker_pytorch_inference_gpu.html#) : running HuggingFace `transformers`, `LangChain`, `LlamaIndex`, `ModelScope`, etc. with `ipex-llm` on Intel GPU
+- [GPU Dev in Visual Studio Code](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/DockerGuides/docker_run_pytorch_inference_in_vscode.html): LLM development in python using `ipex-llm` on Intel GPU in VSCode
+- [vLLM on GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/DockerGuides/fastchat_docker_quickstart.html): serving with `ipex-llm` accelerated `vLLM` on Intel GPU
+- [FastChat on GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/DockerGuides/fastchat_docker_quickstart.html): serving with `ipex-llm` accelerated `FastChat`on Intel GPU
+
+### Use
- [llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html): running **llama.cpp** (*using C++ interface of `ipex-llm` as an accelerated backend for `llama.cpp`*) on Intel GPU
- [ollama](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html): running **ollama** (*using C++ interface of `ipex-llm` as an accelerated backend for `ollama`*) on Intel GPU
- [vLLM](python/llm/example/GPU/vLLM-Serving): running `ipex-llm` in `vLLM` on both Intel [GPU](python/llm/example/GPU/vLLM-Serving) and [CPU](python/llm/example/CPU/vLLM-Serving)
- [FastChat](python/llm/src/ipex_llm/serving/fastchat): running `ipex-llm` in `FastChat` serving on on both Intel GPU and CPU
- [LangChain-Chatchat RAG](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/chatchat_quickstart.html): running `ipex-llm` in `LangChain-Chatchat` (*Knowledge Base QA using **RAG** pipeline*)
- [Text-Generation-WebUI](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html): running `ipex-llm` in `oobabooga` **WebUI**
+- [Dify](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/dify_quickstart.html): running `ipex-llm` in `Dify`(*production-ready LLM app development platform*)
+- [Continue](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/continue_quickstart.html): using `Continue` (a coding copilot in VSCode) backed by `ipex-llm`
- [Benchmarking](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/benchmark_quickstart.html): running (latency and throughput) benchmarks for `ipex-llm` on Intel CPU and GPU
+
+### Install
+- [Windows GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_windows_gpu.html): installing `ipex-llm` on Windows with Intel GPU
+- [Linux GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html): installing `ipex-llm` on Linux with Intel GPU
+- *For more details, please refer to the [installation guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install.html)*
+
+
+
### Code Examples
- Low bit inference
- [INT4 inference](python/llm/example/GPU/HF-Transformers-AutoModels/Model): **INT4** LLM inference on Intel [GPU](python/llm/example/GPU/HF-Transformers-AutoModels/Model) and [CPU](python/llm/example/CPU/HF-Transformers-AutoModels/Model)
diff --git a/docs/readthedocs/source/_templates/sidebar_quicklinks.html b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
index 87d2fe47..d1a58980 100644
--- a/docs/readthedocs/source/_templates/sidebar_quicklinks.html
+++ b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
@@ -78,22 +78,22 @@
diff --git a/docs/readthedocs/source/doc/LLM/DockerGuides/docker_pytorch_inference_gpu.md b/docs/readthedocs/source/doc/LLM/DockerGuides/docker_pytorch_inference_gpu.md
index 7a3d3550..0c69a5a4 100644
--- a/docs/readthedocs/source/doc/LLM/DockerGuides/docker_pytorch_inference_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/DockerGuides/docker_pytorch_inference_gpu.md
@@ -1,4 +1,4 @@
-# Run PyTorch Inference on an Intel GPU via Docker
+# Python Inference using IPEX-LLM on Intel GPU
We can run PyTorch Inference Benchmark, Chat Service and PyTorch Examples on Intel GPUs within Docker (on Linux or WSL).
diff --git a/docs/readthedocs/source/doc/LLM/DockerGuides/docker_windows_gpu.md b/docs/readthedocs/source/doc/LLM/DockerGuides/docker_windows_gpu.md
index f0b2d6e4..ce536f9b 100644
--- a/docs/readthedocs/source/doc/LLM/DockerGuides/docker_windows_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/DockerGuides/docker_windows_gpu.md
@@ -108,8 +108,4 @@ Command: python chat.py --model-path /llm/llm-models/chatglm2-6b/
Uptime: 29.349235 s
Aborted
```
-To resolve this problem, you can disabling the iGPU in Device Manager on Windows as follows:
-
-
- 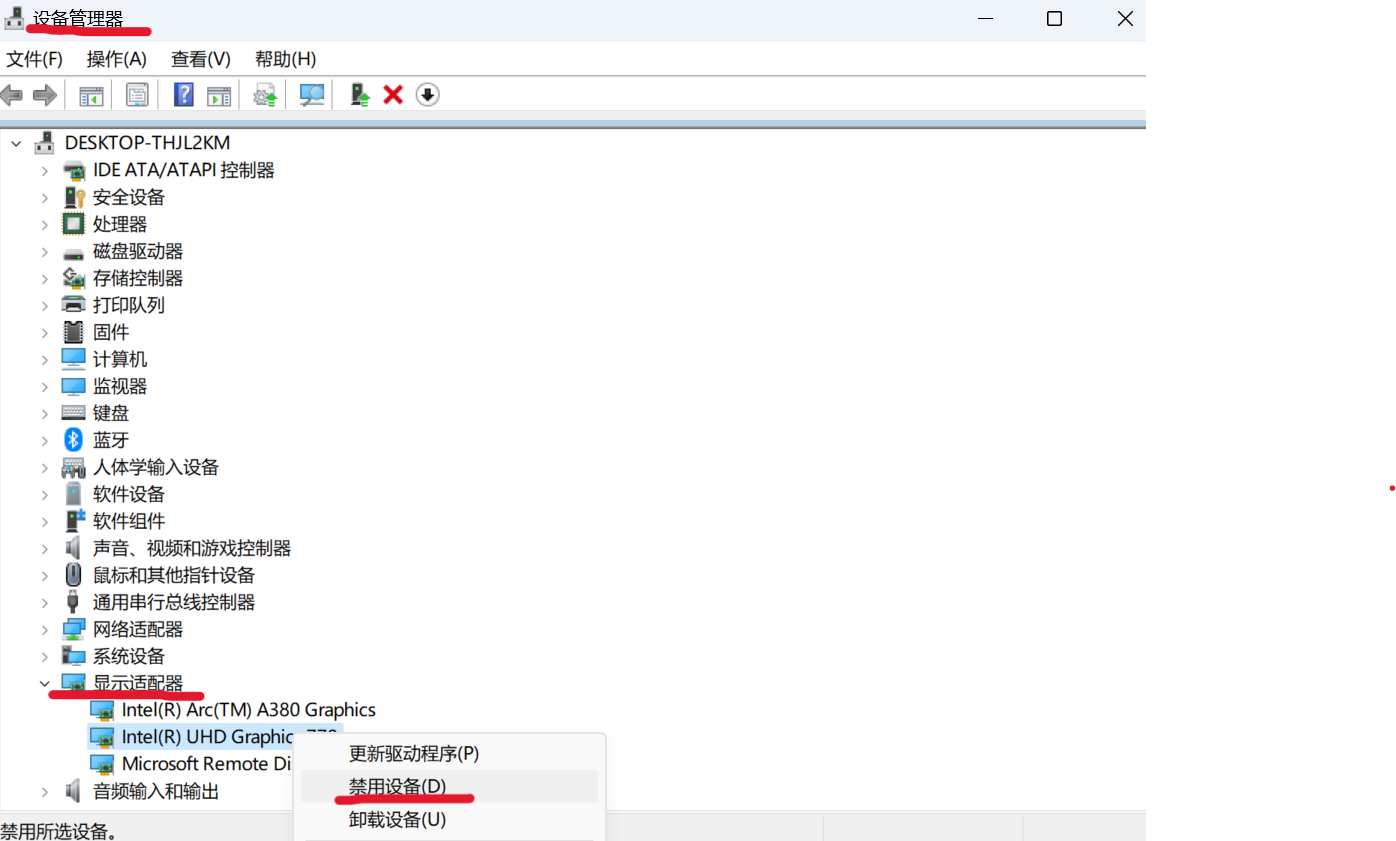 -
+To resolve this problem, you can disable the iGPU in Device Manager on Windows. For details, refer to [this guide](https://www.elevenforum.com/t/enable-or-disable-integrated-graphics-igpu-in-windows-11.18616/)
diff --git a/docs/readthedocs/source/doc/LLM/DockerGuides/index.rst b/docs/readthedocs/source/doc/LLM/DockerGuides/index.rst
index 2dccefbb..0e6cb976 100644
--- a/docs/readthedocs/source/doc/LLM/DockerGuides/index.rst
+++ b/docs/readthedocs/source/doc/LLM/DockerGuides/index.rst
@@ -3,10 +3,12 @@ IPEX-LLM Docker Container User Guides
In this section, you will find guides related to using IPEX-LLM with Docker, covering how to:
+* `Overview of IPEX-LLM Containers <./docker_windows_gpu.html>`_
-* `Overview of IPEX-LLM Containers for Intel GPU <./docker_windows_gpu.html>`_
-* `Run PyTorch Inference on an Intel GPU via Docker <./docker_pytorch_inference_gpu.html>`_
-* `Run/Develop PyTorch in VSCode with Docker on Intel GPU <./docker_pytorch_inference_gpu.html>`_
-* `Run llama.cpp/Ollama/open-webui with Docker on Intel GPU <./docker_cpp_xpu_quickstart.html>`_
-* `Run IPEX-LLM integrated FastChat with Docker on Intel GPU <./fastchat_docker_quickstart.html>`_
-* `Run IPEX-LLM integrated vLLM with Docker on Intel GPU <./vllm_docker_quickstart.html>`_
+* Inference in Python/C++
+ * `GPU Inference in Python with IPEX-LLM <./docker_pytorch_inference_gpu.html>`_
+ * `VSCode LLM Development with IPEX-LLM on Intel GPU <./docker_pytorch_inference_gpu.html>`_
+ * `llama.cpp/Ollama/Open-WebUI with IPEX-LLM on Intel GPU <./docker_cpp_xpu_quickstart.html>`_
+* Serving
+ * `FastChat with IPEX-LLM on Intel GPU <./fastchat_docker_quickstart.html>`_
+ * `vLLM with IPEX-LLM on Intel GPU <./vllm_docker_quickstart.html>`_
-
+To resolve this problem, you can disable the iGPU in Device Manager on Windows. For details, refer to [this guide](https://www.elevenforum.com/t/enable-or-disable-integrated-graphics-igpu-in-windows-11.18616/)
diff --git a/docs/readthedocs/source/doc/LLM/DockerGuides/index.rst b/docs/readthedocs/source/doc/LLM/DockerGuides/index.rst
index 2dccefbb..0e6cb976 100644
--- a/docs/readthedocs/source/doc/LLM/DockerGuides/index.rst
+++ b/docs/readthedocs/source/doc/LLM/DockerGuides/index.rst
@@ -3,10 +3,12 @@ IPEX-LLM Docker Container User Guides
In this section, you will find guides related to using IPEX-LLM with Docker, covering how to:
+* `Overview of IPEX-LLM Containers <./docker_windows_gpu.html>`_
-* `Overview of IPEX-LLM Containers for Intel GPU <./docker_windows_gpu.html>`_
-* `Run PyTorch Inference on an Intel GPU via Docker <./docker_pytorch_inference_gpu.html>`_
-* `Run/Develop PyTorch in VSCode with Docker on Intel GPU <./docker_pytorch_inference_gpu.html>`_
-* `Run llama.cpp/Ollama/open-webui with Docker on Intel GPU <./docker_cpp_xpu_quickstart.html>`_
-* `Run IPEX-LLM integrated FastChat with Docker on Intel GPU <./fastchat_docker_quickstart.html>`_
-* `Run IPEX-LLM integrated vLLM with Docker on Intel GPU <./vllm_docker_quickstart.html>`_
+* Inference in Python/C++
+ * `GPU Inference in Python with IPEX-LLM <./docker_pytorch_inference_gpu.html>`_
+ * `VSCode LLM Development with IPEX-LLM on Intel GPU <./docker_pytorch_inference_gpu.html>`_
+ * `llama.cpp/Ollama/Open-WebUI with IPEX-LLM on Intel GPU <./docker_cpp_xpu_quickstart.html>`_
+* Serving
+ * `FastChat with IPEX-LLM on Intel GPU <./fastchat_docker_quickstart.html>`_
+ * `vLLM with IPEX-LLM on Intel GPU <./vllm_docker_quickstart.html>`_