 +
+
+
+
+#### Pull models from ollama to serve
+
+```bash
+cd /llm/ollama
+./ollama pull llama2
+```
+
+Use the Curl to Test:
+```bash
+curl http://localhost:11434/api/generate -d '
+{
+ "model": "llama2",
+ "prompt": "What is AI?",
+ "stream": false
+}'
+```
+
+Sample output:
+```bash
+{"model":"llama2","created_at":"2024-05-16T02:52:18.972296097Z","response":"\nArtificial intelligence (AI) refers to the development of computer systems that can perform tasks that typically require human intelligence, such as learning, problem-solving, and decision-making. AI systems use algorithms and data to mimic human behavior and perform tasks such as:\n\n1. Image recognition: AI can identify objects in images and classify them into different categories.\n2. Natural Language Processing (NLP): AI can understand and generate human language, allowing it to interact with humans through voice assistants or chatbots.\n3. Predictive analytics: AI can analyze data to make predictions about future events, such as stock prices or weather patterns.\n4. Robotics: AI can control robots that perform tasks such as assembly, maintenance, and logistics.\n5. Recommendation systems: AI can suggest products or services based on a user's past behavior or preferences.\n6. Autonomous vehicles: AI can control self-driving cars that can navigate through roads and traffic without human intervention.\n7. Fraud detection: AI can identify and flag fraudulent transactions, such as credit card purchases or insurance claims.\n8. Personalized medicine: AI can analyze genetic data to provide personalized medical recommendations, such as drug dosages or treatment plans.\n9. Virtual assistants: AI can interact with users through voice or text interfaces, providing information or completing tasks.\n10. Sentiment analysis: AI can analyze text or speech to determine the sentiment or emotional tone of a message.\n\nThese are just a few examples of what AI can do. As the technology continues to evolve, we can expect to see even more innovative applications of AI in various industries and aspects of our lives.","done":true,"context":[xxx,xxx],"total_duration":12831317190,"load_duration":6453932096,"prompt_eval_count":25,"prompt_eval_duration":254970000,"eval_count":390,"eval_duration":6079077000}
+```
+
+
+Please refer to this [documentation](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html#pull-model) for more details.
+
+
+### Running Open WebUI with Intel GPU
+
+Start the ollama and load the model first, then use the open-webui to chat.
+If you have difficulty accessing the huggingface repositories, you may use a mirror, e.g. add export HF_ENDPOINT=https://hf-mirror.com before running bash start.sh.
+```bash
+cd /llm/scripts/
+bash start-open-webui.sh
+```
+
+Sample output:
+```bash
+INFO: Started server process [1055]
+INFO: Waiting for application startup.
+INFO: Application startup complete.
+INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
+```
+
+
+
+
+
+
+
+#### Pull models from ollama to serve
+
+```bash
+cd /llm/ollama
+./ollama pull llama2
+```
+
+Use the Curl to Test:
+```bash
+curl http://localhost:11434/api/generate -d '
+{
+ "model": "llama2",
+ "prompt": "What is AI?",
+ "stream": false
+}'
+```
+
+Sample output:
+```bash
+{"model":"llama2","created_at":"2024-05-16T02:52:18.972296097Z","response":"\nArtificial intelligence (AI) refers to the development of computer systems that can perform tasks that typically require human intelligence, such as learning, problem-solving, and decision-making. AI systems use algorithms and data to mimic human behavior and perform tasks such as:\n\n1. Image recognition: AI can identify objects in images and classify them into different categories.\n2. Natural Language Processing (NLP): AI can understand and generate human language, allowing it to interact with humans through voice assistants or chatbots.\n3. Predictive analytics: AI can analyze data to make predictions about future events, such as stock prices or weather patterns.\n4. Robotics: AI can control robots that perform tasks such as assembly, maintenance, and logistics.\n5. Recommendation systems: AI can suggest products or services based on a user's past behavior or preferences.\n6. Autonomous vehicles: AI can control self-driving cars that can navigate through roads and traffic without human intervention.\n7. Fraud detection: AI can identify and flag fraudulent transactions, such as credit card purchases or insurance claims.\n8. Personalized medicine: AI can analyze genetic data to provide personalized medical recommendations, such as drug dosages or treatment plans.\n9. Virtual assistants: AI can interact with users through voice or text interfaces, providing information or completing tasks.\n10. Sentiment analysis: AI can analyze text or speech to determine the sentiment or emotional tone of a message.\n\nThese are just a few examples of what AI can do. As the technology continues to evolve, we can expect to see even more innovative applications of AI in various industries and aspects of our lives.","done":true,"context":[xxx,xxx],"total_duration":12831317190,"load_duration":6453932096,"prompt_eval_count":25,"prompt_eval_duration":254970000,"eval_count":390,"eval_duration":6079077000}
+```
+
+
+Please refer to this [documentation](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html#pull-model) for more details.
+
+
+### Running Open WebUI with Intel GPU
+
+Start the ollama and load the model first, then use the open-webui to chat.
+If you have difficulty accessing the huggingface repositories, you may use a mirror, e.g. add export HF_ENDPOINT=https://hf-mirror.com before running bash start.sh.
+```bash
+cd /llm/scripts/
+bash start-open-webui.sh
+```
+
+Sample output:
+```bash
+INFO: Started server process [1055]
+INFO: Waiting for application startup.
+INFO: Application startup complete.
+INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
+```
+
+
+ 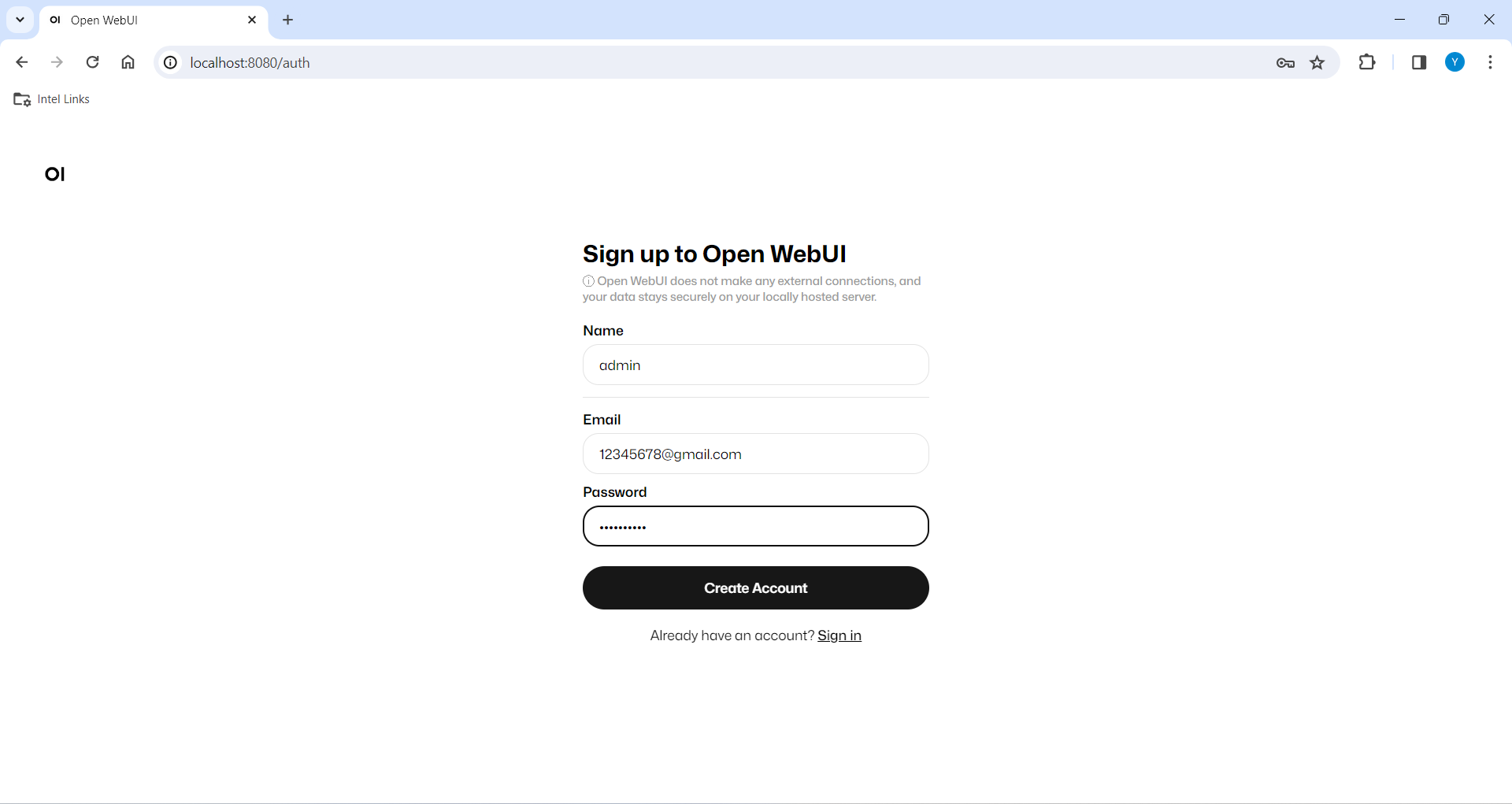 +
+
+For how to log-in or other guide, Please refer to this [documentation](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.html) for more details.
diff --git a/docs/mddocs/DockerGuides/docker_pytorch_inference_gpu.md b/docs/mddocs/DockerGuides/docker_pytorch_inference_gpu.md
new file mode 100644
index 00000000..76409384
--- /dev/null
+++ b/docs/mddocs/DockerGuides/docker_pytorch_inference_gpu.md
@@ -0,0 +1,171 @@
+# Python Inference using IPEX-LLM on Intel GPU
+
+We can run PyTorch Inference Benchmark, Chat Service and PyTorch Examples on Intel GPUs within Docker (on Linux or WSL).
+
+```eval_rst
+.. note::
+
+ The current Windows + WSL + Docker solution only supports Arc series dGPU. For Windows users with MTL iGPU, it is recommended to install directly via pip install in Miniforge Prompt. Refer to `this guide
+
+
+For how to log-in or other guide, Please refer to this [documentation](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.html) for more details.
diff --git a/docs/mddocs/DockerGuides/docker_pytorch_inference_gpu.md b/docs/mddocs/DockerGuides/docker_pytorch_inference_gpu.md
new file mode 100644
index 00000000..76409384
--- /dev/null
+++ b/docs/mddocs/DockerGuides/docker_pytorch_inference_gpu.md
@@ -0,0 +1,171 @@
+# Python Inference using IPEX-LLM on Intel GPU
+
+We can run PyTorch Inference Benchmark, Chat Service and PyTorch Examples on Intel GPUs within Docker (on Linux or WSL).
+
+```eval_rst
+.. note::
+
+ The current Windows + WSL + Docker solution only supports Arc series dGPU. For Windows users with MTL iGPU, it is recommended to install directly via pip install in Miniforge Prompt. Refer to `this guide  +
+
+
+ +
+
+
+#### Install WSL Extension for Windows
+
+For Windows, you will need to install wsl extension to to the WSL environment. Open the Extensions view in VSCode (you can use the shortcut `Ctrl+Shift+X`), then search for and install the `WSL` extension.
+
+Press F1 to bring up the Command Palette and type in `WSL: Connect to WSL Using Distro...` and select it and then select a specific WSL distro `Ubuntu`
+
+
+
+
+
+
+
+#### Install WSL Extension for Windows
+
+For Windows, you will need to install wsl extension to to the WSL environment. Open the Extensions view in VSCode (you can use the shortcut `Ctrl+Shift+X`), then search for and install the `WSL` extension.
+
+Press F1 to bring up the Command Palette and type in `WSL: Connect to WSL Using Distro...` and select it and then select a specific WSL distro `Ubuntu`
+
+
+
+  +
+
+
+## Launch Container
+
+Open the Terminal in VSCode (you can use the shortcut `` Ctrl+Shift+` ``), then pull ipex-llm-xpu Docker Image:
+
+```bash
+docker pull intelanalytics/ipex-llm-xpu:latest
+```
+
+Start ipex-llm-xpu Docker Container:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export DOCKER_IMAGE=intelanalytics/ipex-llm-xpu:latest
+ export CONTAINER_NAME=my_container
+ export MODEL_PATH=/llm/models[change to your model path]
+
+ docker run -itd \
+ --net=host \
+ --device=/dev/dri \
+ --memory="32G" \
+ --name=$CONTAINER_NAME \
+ --shm-size="16g" \
+ -v $MODEL_PATH:/llm/models \
+ $DOCKER_IMAGE
+
+ .. tab:: Windows WSL
+
+ .. code-block:: bash
+
+ #/bin/bash
+ export DOCKER_IMAGE=intelanalytics/ipex-llm-xpu:latest
+ export CONTAINER_NAME=my_container
+ export MODEL_PATH=/llm/models[change to your model path]
+
+ sudo docker run -itd \
+ --net=host \
+ --privileged \
+ --device /dev/dri \
+ --memory="32G" \
+ --name=$CONTAINER_NAME \
+ --shm-size="16g" \
+ -v $MODEL_PATH:/llm/llm-models \
+ -v /usr/lib/wsl:/usr/lib/wsl \
+ $DOCKER_IMAGE
+```
+
+
+## Run/Develop Pytorch Examples
+
+Press F1 to bring up the Command Palette and type in `Dev Containers: Attach to Running Container...` and select it and then select `my_container`
+
+Now you are in a running Docker Container, Open folder `/ipex-llm/python/llm/example/GPU/HF-Transformers-AutoModels/Model/`.
+
+
+
+
+
+
+## Launch Container
+
+Open the Terminal in VSCode (you can use the shortcut `` Ctrl+Shift+` ``), then pull ipex-llm-xpu Docker Image:
+
+```bash
+docker pull intelanalytics/ipex-llm-xpu:latest
+```
+
+Start ipex-llm-xpu Docker Container:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export DOCKER_IMAGE=intelanalytics/ipex-llm-xpu:latest
+ export CONTAINER_NAME=my_container
+ export MODEL_PATH=/llm/models[change to your model path]
+
+ docker run -itd \
+ --net=host \
+ --device=/dev/dri \
+ --memory="32G" \
+ --name=$CONTAINER_NAME \
+ --shm-size="16g" \
+ -v $MODEL_PATH:/llm/models \
+ $DOCKER_IMAGE
+
+ .. tab:: Windows WSL
+
+ .. code-block:: bash
+
+ #/bin/bash
+ export DOCKER_IMAGE=intelanalytics/ipex-llm-xpu:latest
+ export CONTAINER_NAME=my_container
+ export MODEL_PATH=/llm/models[change to your model path]
+
+ sudo docker run -itd \
+ --net=host \
+ --privileged \
+ --device /dev/dri \
+ --memory="32G" \
+ --name=$CONTAINER_NAME \
+ --shm-size="16g" \
+ -v $MODEL_PATH:/llm/llm-models \
+ -v /usr/lib/wsl:/usr/lib/wsl \
+ $DOCKER_IMAGE
+```
+
+
+## Run/Develop Pytorch Examples
+
+Press F1 to bring up the Command Palette and type in `Dev Containers: Attach to Running Container...` and select it and then select `my_container`
+
+Now you are in a running Docker Container, Open folder `/ipex-llm/python/llm/example/GPU/HF-Transformers-AutoModels/Model/`.
+
+
+  +
+
+In this folder, we provide several PyTorch examples that you could apply IPEX-LLM INT4 optimizations on models on Intel GPUs.
+
+For example, if your model is Llama-2-7b-chat-hf and mounted on /llm/models, you can navigate to llama2 directory, excute the following command to run example:
+ ```bash
+ cd
+
+
+In this folder, we provide several PyTorch examples that you could apply IPEX-LLM INT4 optimizations on models on Intel GPUs.
+
+For example, if your model is Llama-2-7b-chat-hf and mounted on /llm/models, you can navigate to llama2 directory, excute the following command to run example:
+ ```bash
+ cd  +
+
+```eval_rst
+.. tip::
+
+ If you encounter **Docker Engine stopped** when opening Docker Desktop, you can reopen it in administrator mode.
+```
+
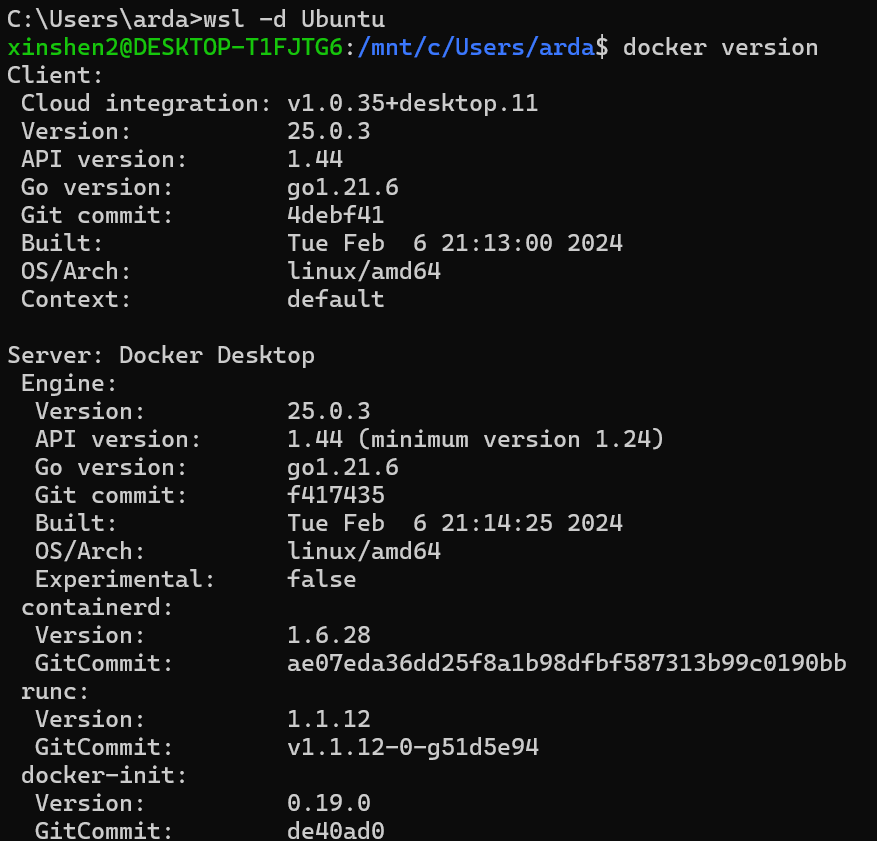
+ #### Verify Docker is enabled in WSL2
+
+ Execute the following commands in PowerShell or Command Prompt to verify that Docker is enabled in WSL2:
+ ```bash
+ wsl -d Ubuntu # Run Ubuntu WSL distribution
+ docker version # Check if Docker is enabled in WSL
+ ```
+
+You can see the output similar to the following:
+
+
+
+
+
+```eval_rst
+.. tip::
+
+ If you encounter **Docker Engine stopped** when opening Docker Desktop, you can reopen it in administrator mode.
+```
+
+ #### Verify Docker is enabled in WSL2
+
+ Execute the following commands in PowerShell or Command Prompt to verify that Docker is enabled in WSL2:
+ ```bash
+ wsl -d Ubuntu # Run Ubuntu WSL distribution
+ docker version # Check if Docker is enabled in WSL
+ ```
+
+You can see the output similar to the following:
+
+
+  +
+
+```eval_rst
+.. tip::
+
+ During the use of Docker in WSL, Docker Desktop needs to be kept open all the time.
+```
+
+
+## IPEX-LLM Docker Containers
+
+We have several docker images available for running LLMs on Intel GPUs. The following table lists the available images and their uses:
+
+| Image Name | Description | Use Case |
+|------------|-------------|----------|
+| intelanalytics/ipex-llm-cpu:latest | CPU Inference |For development and running LLMs using llama.cpp, Ollama and Python|
+| intelanalytics/ipex-llm-xpu:latest | GPU Inference |For development and running LLMs using llama.cpp, Ollama and Python|
+| intelanalytics/ipex-llm-serving-cpu:latest | CPU Serving|For serving multiple users/requests through REST APIs using vLLM/FastChat|
+| intelanalytics/ipex-llm-serving-xpu:latest | GPU Serving|For serving multiple users/requests through REST APIs using vLLM/FastChat|
+| intelanalytics/ipex-llm-finetune-qlora-cpu-standalone:latest | CPU Finetuning via Docker|For fine-tuning LLMs using QLora/Lora, etc. |
+|intelanalytics/ipex-llm-finetune-qlora-cpu-k8s:latest|CPU Finetuning via Kubernetes|For fine-tuning LLMs using QLora/Lora, etc. |
+| intelanalytics/ipex-llm-finetune-qlora-xpu:latest| GPU Finetuning|For fine-tuning LLMs using QLora/Lora, etc.|
+
+We have also provided several quickstarts for various usage scenarios:
+- [Run and develop LLM applications in PyTorch](./docker_pytorch_inference_gpu.html)
+
+... to be added soon.
+
+## Troubleshooting
+
+
+If your machine has both an integrated GPU (iGPU) and a dedicated GPU (dGPU) like ARC, you may encounter the following issue:
+
+```bash
+Abort was called at 62 line in file:
+./shared/source/os_interface/os_interface.h
+LIBXSMM_VERSION: main_stable-1.17-3651 (25693763)
+LIBXSMM_TARGET: adl [Intel(R) Core(TM) i7-14700K]
+Registry and code: 13 MB
+Command: python chat.py --model-path /llm/llm-models/chatglm2-6b/
+Uptime: 29.349235 s
+Aborted
+```
+To resolve this problem, you can disable the iGPU in Device Manager on Windows. For details, refer to [this guide](https://www.elevenforum.com/t/enable-or-disable-integrated-graphics-igpu-in-windows-11.18616/)
diff --git a/docs/mddocs/DockerGuides/fastchat_docker_quickstart.md b/docs/mddocs/DockerGuides/fastchat_docker_quickstart.md
new file mode 100644
index 00000000..786316fd
--- /dev/null
+++ b/docs/mddocs/DockerGuides/fastchat_docker_quickstart.md
@@ -0,0 +1,117 @@
+# FastChat Serving with IPEX-LLM on Intel GPUs via docker
+
+This guide demonstrates how to run `FastChat` serving with `IPEX-LLM` on Intel GPUs via Docker.
+
+## Install docker
+
+Follow the instructions in this [guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/DockerGuides/docker_windows_gpu.html#linux) to install Docker on Linux.
+
+## Pull the latest image
+
+```bash
+# This image will be updated every day
+docker pull intelanalytics/ipex-llm-serving-xpu:latest
+```
+
+## Start Docker Container
+
+ To map the `xpu` into the container, you need to specify `--device=/dev/dri` when booting the container. Change the `/path/to/models` to mount the models.
+
+```
+#/bin/bash
+export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-xpu:latest
+export CONTAINER_NAME=ipex-llm-serving-xpu-container
+sudo docker run -itd \
+ --net=host \
+ --device=/dev/dri \
+ -v /path/to/models:/llm/models \
+ -e no_proxy=localhost,127.0.0.1 \
+ --memory="32G" \
+ --name=$CONTAINER_NAME \
+ --shm-size="16g" \
+ $DOCKER_IMAGE
+```
+
+After the container is booted, you could get into the container through `docker exec`.
+
+```bash
+docker exec -it ipex-llm-serving-xpu-container /bin/bash
+```
+
+
+To verify the device is successfully mapped into the container, run `sycl-ls` to check the result. In a machine with Arc A770, the sampled output is:
+
+```bash
+root@arda-arc12:/# sycl-ls
+[opencl:acc:0] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device 1.2 [2023.16.7.0.21_160000]
+[opencl:cpu:1] Intel(R) OpenCL, 13th Gen Intel(R) Core(TM) i9-13900K 3.0 [2023.16.7.0.21_160000]
+[opencl:gpu:2] Intel(R) OpenCL Graphics, Intel(R) Arc(TM) A770 Graphics 3.0 [23.17.26241.33]
+[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) A770 Graphics 1.3 [1.3.26241]
+```
+
+
+## Running FastChat serving with IPEX-LLM on Intel GPU in Docker
+
+For convenience, we have provided a script named `/llm/start-fastchat-service.sh` for you to start the service.
+
+However, the script only provide instructions for the most common scenarios. If this script doesn't meet your needs, you can always find the complete guidance for FastChat at [Serving using IPEX-LLM and FastChat](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/fastchat_quickstart.html#start-the-service).
+
+Before starting the service, you can refer to this [section](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html#runtime-configurations) to setup our recommended runtime configurations.
+
+Now we can start the FastChat service, you can use our provided script `/llm/start-fastchat-service.sh` like the following way:
+
+```bash
+# Only the MODEL_PATH needs to be set, other parameters have default values
+export MODEL_PATH=YOUR_SELECTED_MODEL_PATH
+export LOW_BIT_FORMAT=sym_int4
+export CONTROLLER_HOST=localhost
+export CONTROLLER_PORT=21001
+export WORKER_HOST=localhost
+export WORKER_PORT=21002
+export API_HOST=localhost
+export API_PORT=8000
+
+# Use the default model_worker
+bash /llm/start-fastchat-service.sh -w model_worker
+```
+
+If everything goes smoothly, the result should be similar to the following figure:
+
+
+
+
+
+```eval_rst
+.. tip::
+
+ During the use of Docker in WSL, Docker Desktop needs to be kept open all the time.
+```
+
+
+## IPEX-LLM Docker Containers
+
+We have several docker images available for running LLMs on Intel GPUs. The following table lists the available images and their uses:
+
+| Image Name | Description | Use Case |
+|------------|-------------|----------|
+| intelanalytics/ipex-llm-cpu:latest | CPU Inference |For development and running LLMs using llama.cpp, Ollama and Python|
+| intelanalytics/ipex-llm-xpu:latest | GPU Inference |For development and running LLMs using llama.cpp, Ollama and Python|
+| intelanalytics/ipex-llm-serving-cpu:latest | CPU Serving|For serving multiple users/requests through REST APIs using vLLM/FastChat|
+| intelanalytics/ipex-llm-serving-xpu:latest | GPU Serving|For serving multiple users/requests through REST APIs using vLLM/FastChat|
+| intelanalytics/ipex-llm-finetune-qlora-cpu-standalone:latest | CPU Finetuning via Docker|For fine-tuning LLMs using QLora/Lora, etc. |
+|intelanalytics/ipex-llm-finetune-qlora-cpu-k8s:latest|CPU Finetuning via Kubernetes|For fine-tuning LLMs using QLora/Lora, etc. |
+| intelanalytics/ipex-llm-finetune-qlora-xpu:latest| GPU Finetuning|For fine-tuning LLMs using QLora/Lora, etc.|
+
+We have also provided several quickstarts for various usage scenarios:
+- [Run and develop LLM applications in PyTorch](./docker_pytorch_inference_gpu.html)
+
+... to be added soon.
+
+## Troubleshooting
+
+
+If your machine has both an integrated GPU (iGPU) and a dedicated GPU (dGPU) like ARC, you may encounter the following issue:
+
+```bash
+Abort was called at 62 line in file:
+./shared/source/os_interface/os_interface.h
+LIBXSMM_VERSION: main_stable-1.17-3651 (25693763)
+LIBXSMM_TARGET: adl [Intel(R) Core(TM) i7-14700K]
+Registry and code: 13 MB
+Command: python chat.py --model-path /llm/llm-models/chatglm2-6b/
+Uptime: 29.349235 s
+Aborted
+```
+To resolve this problem, you can disable the iGPU in Device Manager on Windows. For details, refer to [this guide](https://www.elevenforum.com/t/enable-or-disable-integrated-graphics-igpu-in-windows-11.18616/)
diff --git a/docs/mddocs/DockerGuides/fastchat_docker_quickstart.md b/docs/mddocs/DockerGuides/fastchat_docker_quickstart.md
new file mode 100644
index 00000000..786316fd
--- /dev/null
+++ b/docs/mddocs/DockerGuides/fastchat_docker_quickstart.md
@@ -0,0 +1,117 @@
+# FastChat Serving with IPEX-LLM on Intel GPUs via docker
+
+This guide demonstrates how to run `FastChat` serving with `IPEX-LLM` on Intel GPUs via Docker.
+
+## Install docker
+
+Follow the instructions in this [guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/DockerGuides/docker_windows_gpu.html#linux) to install Docker on Linux.
+
+## Pull the latest image
+
+```bash
+# This image will be updated every day
+docker pull intelanalytics/ipex-llm-serving-xpu:latest
+```
+
+## Start Docker Container
+
+ To map the `xpu` into the container, you need to specify `--device=/dev/dri` when booting the container. Change the `/path/to/models` to mount the models.
+
+```
+#/bin/bash
+export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-xpu:latest
+export CONTAINER_NAME=ipex-llm-serving-xpu-container
+sudo docker run -itd \
+ --net=host \
+ --device=/dev/dri \
+ -v /path/to/models:/llm/models \
+ -e no_proxy=localhost,127.0.0.1 \
+ --memory="32G" \
+ --name=$CONTAINER_NAME \
+ --shm-size="16g" \
+ $DOCKER_IMAGE
+```
+
+After the container is booted, you could get into the container through `docker exec`.
+
+```bash
+docker exec -it ipex-llm-serving-xpu-container /bin/bash
+```
+
+
+To verify the device is successfully mapped into the container, run `sycl-ls` to check the result. In a machine with Arc A770, the sampled output is:
+
+```bash
+root@arda-arc12:/# sycl-ls
+[opencl:acc:0] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device 1.2 [2023.16.7.0.21_160000]
+[opencl:cpu:1] Intel(R) OpenCL, 13th Gen Intel(R) Core(TM) i9-13900K 3.0 [2023.16.7.0.21_160000]
+[opencl:gpu:2] Intel(R) OpenCL Graphics, Intel(R) Arc(TM) A770 Graphics 3.0 [23.17.26241.33]
+[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) A770 Graphics 1.3 [1.3.26241]
+```
+
+
+## Running FastChat serving with IPEX-LLM on Intel GPU in Docker
+
+For convenience, we have provided a script named `/llm/start-fastchat-service.sh` for you to start the service.
+
+However, the script only provide instructions for the most common scenarios. If this script doesn't meet your needs, you can always find the complete guidance for FastChat at [Serving using IPEX-LLM and FastChat](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/fastchat_quickstart.html#start-the-service).
+
+Before starting the service, you can refer to this [section](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html#runtime-configurations) to setup our recommended runtime configurations.
+
+Now we can start the FastChat service, you can use our provided script `/llm/start-fastchat-service.sh` like the following way:
+
+```bash
+# Only the MODEL_PATH needs to be set, other parameters have default values
+export MODEL_PATH=YOUR_SELECTED_MODEL_PATH
+export LOW_BIT_FORMAT=sym_int4
+export CONTROLLER_HOST=localhost
+export CONTROLLER_PORT=21001
+export WORKER_HOST=localhost
+export WORKER_PORT=21002
+export API_HOST=localhost
+export API_PORT=8000
+
+# Use the default model_worker
+bash /llm/start-fastchat-service.sh -w model_worker
+```
+
+If everything goes smoothly, the result should be similar to the following figure:
+
+
+  +
+
+By default, we are using the `ipex_llm_worker` as the backend engine. You can also use `vLLM` as the backend engine. Try the following examples:
+
+```bash
+# Only the MODEL_PATH needs to be set, other parameters have default values
+export MODEL_PATH=YOUR_SELECTED_MODEL_PATH
+export LOW_BIT_FORMAT=sym_int4
+export CONTROLLER_HOST=localhost
+export CONTROLLER_PORT=21001
+export WORKER_HOST=localhost
+export WORKER_PORT=21002
+export API_HOST=localhost
+export API_PORT=8000
+
+# Use the default model_worker
+bash /llm/start-fastchat-service.sh -w vllm_worker
+```
+
+The `vllm_worker` may start slowly than normal `ipex_llm_worker`. The booted service should be similar to the following figure:
+
+
+
+
+
+By default, we are using the `ipex_llm_worker` as the backend engine. You can also use `vLLM` as the backend engine. Try the following examples:
+
+```bash
+# Only the MODEL_PATH needs to be set, other parameters have default values
+export MODEL_PATH=YOUR_SELECTED_MODEL_PATH
+export LOW_BIT_FORMAT=sym_int4
+export CONTROLLER_HOST=localhost
+export CONTROLLER_PORT=21001
+export WORKER_HOST=localhost
+export WORKER_PORT=21002
+export API_HOST=localhost
+export API_PORT=8000
+
+# Use the default model_worker
+bash /llm/start-fastchat-service.sh -w vllm_worker
+```
+
+The `vllm_worker` may start slowly than normal `ipex_llm_worker`. The booted service should be similar to the following figure:
+
+
+  +
+
+
+```eval_rst
+.. note::
+ To verify/use the service booted by the script, follow the instructions in `this guide
+
+
+
+```eval_rst
+.. note::
+ To verify/use the service booted by the script, follow the instructions in `this guide  +
diff --git a/docs/mddocs/DockerGuides/index.rst b/docs/mddocs/DockerGuides/index.rst
new file mode 100644
index 00000000..29781e52
--- /dev/null
+++ b/docs/mddocs/DockerGuides/index.rst
@@ -0,0 +1,15 @@
+IPEX-LLM Docker Container User Guides
+=====================================
+
+In this section, you will find guides related to using IPEX-LLM with Docker, covering how to:
+
+* `Overview of IPEX-LLM Containers <./docker_windows_gpu.html>`_
+
+* Inference in Python/C++
+ * `GPU Inference in Python with IPEX-LLM <./docker_pytorch_inference_gpu.html>`_
+ * `VSCode LLM Development with IPEX-LLM on Intel GPU <./docker_pytorch_inference_gpu.html>`_
+ * `llama.cpp/Ollama/Open-WebUI with IPEX-LLM on Intel GPU <./docker_cpp_xpu_quickstart.html>`_
+* Serving
+ * `FastChat with IPEX-LLM on Intel GPU <./fastchat_docker_quickstart.html>`_
+ * `vLLM with IPEX-LLM on Intel GPU <./vllm_docker_quickstart.html>`_
+ * `vLLM with IPEX-LLM on Intel CPU <./vllm_cpu_docker_quickstart.html>`_
diff --git a/docs/mddocs/DockerGuides/vllm_cpu_docker_quickstart.md b/docs/mddocs/DockerGuides/vllm_cpu_docker_quickstart.md
new file mode 100644
index 00000000..36b39ed5
--- /dev/null
+++ b/docs/mddocs/DockerGuides/vllm_cpu_docker_quickstart.md
@@ -0,0 +1,118 @@
+# vLLM Serving with IPEX-LLM on Intel CPU via Docker
+
+This guide demonstrates how to run `vLLM` serving with `ipex-llm` on Intel CPU via Docker.
+
+## Install docker
+
+Follow the instructions in this [guide](https://www.docker.com/get-started/) to install Docker on Linux.
+
+## Pull the latest image
+
+*Note: For running vLLM serving on Intel CPUs, you can currently use either the `intelanalytics/ipex-llm-serving-cpu:latest` or `intelanalytics/ipex-llm-serving-vllm-cpu:latest` Docker image.*
+
+```bash
+# This image will be updated every day
+docker pull intelanalytics/ipex-llm-serving-cpu:latest
+```
+
+## Start Docker Container
+
+To fully use your Intel CPU to run vLLM inference and serving, you should
+```
+#/bin/bash
+export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-cpu:latest
+export CONTAINER_NAME=ipex-llm-serving-cpu-container
+sudo docker run -itd \
+ --net=host \
+ --cpuset-cpus="0-47" \
+ --cpuset-mems="0" \
+ -v /path/to/models:/llm/models \
+ -e no_proxy=localhost,127.0.0.1 \
+ --memory="64G" \
+ --name=$CONTAINER_NAME \
+ --shm-size="16g" \
+ $DOCKER_IMAGE
+```
+
+After the container is booted, you could get into the container through `docker exec`.
+
+```bash
+docker exec -it ipex-llm-serving-cpu-container /bin/bash
+```
+
+## Running vLLM serving with IPEX-LLM on Intel CPU in Docker
+
+We have included multiple vLLM-related files in `/llm/`:
+1. `vllm_offline_inference.py`: Used for vLLM offline inference example
+2. `benchmark_vllm_throughput.py`: Used for benchmarking throughput
+3. `payload-1024.lua`: Used for testing request per second using 1k-128 request
+4. `start-vllm-service.sh`: Used for template for starting vLLM service
+
+Before performing benchmark or starting the service, you can refer to this [section](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_cpu.html#environment-setup) to setup our recommended runtime configurations.
+
+### Service
+
+A script named `/llm/start-vllm-service.sh` have been included in the image for starting the service conveniently.
+
+Modify the `model` and `served_model_name` in the script so that it fits your requirement. The `served_model_name` indicates the model name used in the API.
+
+Then start the service using `bash /llm/start-vllm-service.sh`, the following message should be print if the service started successfully.
+
+If the service have booted successfully, you should see the output similar to the following figure:
+
+
+
+
diff --git a/docs/mddocs/DockerGuides/index.rst b/docs/mddocs/DockerGuides/index.rst
new file mode 100644
index 00000000..29781e52
--- /dev/null
+++ b/docs/mddocs/DockerGuides/index.rst
@@ -0,0 +1,15 @@
+IPEX-LLM Docker Container User Guides
+=====================================
+
+In this section, you will find guides related to using IPEX-LLM with Docker, covering how to:
+
+* `Overview of IPEX-LLM Containers <./docker_windows_gpu.html>`_
+
+* Inference in Python/C++
+ * `GPU Inference in Python with IPEX-LLM <./docker_pytorch_inference_gpu.html>`_
+ * `VSCode LLM Development with IPEX-LLM on Intel GPU <./docker_pytorch_inference_gpu.html>`_
+ * `llama.cpp/Ollama/Open-WebUI with IPEX-LLM on Intel GPU <./docker_cpp_xpu_quickstart.html>`_
+* Serving
+ * `FastChat with IPEX-LLM on Intel GPU <./fastchat_docker_quickstart.html>`_
+ * `vLLM with IPEX-LLM on Intel GPU <./vllm_docker_quickstart.html>`_
+ * `vLLM with IPEX-LLM on Intel CPU <./vllm_cpu_docker_quickstart.html>`_
diff --git a/docs/mddocs/DockerGuides/vllm_cpu_docker_quickstart.md b/docs/mddocs/DockerGuides/vllm_cpu_docker_quickstart.md
new file mode 100644
index 00000000..36b39ed5
--- /dev/null
+++ b/docs/mddocs/DockerGuides/vllm_cpu_docker_quickstart.md
@@ -0,0 +1,118 @@
+# vLLM Serving with IPEX-LLM on Intel CPU via Docker
+
+This guide demonstrates how to run `vLLM` serving with `ipex-llm` on Intel CPU via Docker.
+
+## Install docker
+
+Follow the instructions in this [guide](https://www.docker.com/get-started/) to install Docker on Linux.
+
+## Pull the latest image
+
+*Note: For running vLLM serving on Intel CPUs, you can currently use either the `intelanalytics/ipex-llm-serving-cpu:latest` or `intelanalytics/ipex-llm-serving-vllm-cpu:latest` Docker image.*
+
+```bash
+# This image will be updated every day
+docker pull intelanalytics/ipex-llm-serving-cpu:latest
+```
+
+## Start Docker Container
+
+To fully use your Intel CPU to run vLLM inference and serving, you should
+```
+#/bin/bash
+export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-cpu:latest
+export CONTAINER_NAME=ipex-llm-serving-cpu-container
+sudo docker run -itd \
+ --net=host \
+ --cpuset-cpus="0-47" \
+ --cpuset-mems="0" \
+ -v /path/to/models:/llm/models \
+ -e no_proxy=localhost,127.0.0.1 \
+ --memory="64G" \
+ --name=$CONTAINER_NAME \
+ --shm-size="16g" \
+ $DOCKER_IMAGE
+```
+
+After the container is booted, you could get into the container through `docker exec`.
+
+```bash
+docker exec -it ipex-llm-serving-cpu-container /bin/bash
+```
+
+## Running vLLM serving with IPEX-LLM on Intel CPU in Docker
+
+We have included multiple vLLM-related files in `/llm/`:
+1. `vllm_offline_inference.py`: Used for vLLM offline inference example
+2. `benchmark_vllm_throughput.py`: Used for benchmarking throughput
+3. `payload-1024.lua`: Used for testing request per second using 1k-128 request
+4. `start-vllm-service.sh`: Used for template for starting vLLM service
+
+Before performing benchmark or starting the service, you can refer to this [section](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_cpu.html#environment-setup) to setup our recommended runtime configurations.
+
+### Service
+
+A script named `/llm/start-vllm-service.sh` have been included in the image for starting the service conveniently.
+
+Modify the `model` and `served_model_name` in the script so that it fits your requirement. The `served_model_name` indicates the model name used in the API.
+
+Then start the service using `bash /llm/start-vllm-service.sh`, the following message should be print if the service started successfully.
+
+If the service have booted successfully, you should see the output similar to the following figure:
+
+
+  +
+
+
+#### Verify
+After the service has been booted successfully, you can send a test request using `curl`. Here, `YOUR_MODEL` should be set equal to `served_model_name` in your booting script, e.g. `Qwen1.5`.
+
+```bash
+curl http://localhost:8000/v1/completions \
+-H "Content-Type: application/json" \
+-d '{
+ "model": "YOUR_MODEL",
+ "prompt": "San Francisco is a",
+ "max_tokens": 128,
+ "temperature": 0
+}' | jq '.choices[0].text'
+```
+
+Below shows an example output using `Qwen1.5-7B-Chat` with low-bit format `sym_int4`:
+
+
+
+
+
+
+#### Verify
+After the service has been booted successfully, you can send a test request using `curl`. Here, `YOUR_MODEL` should be set equal to `served_model_name` in your booting script, e.g. `Qwen1.5`.
+
+```bash
+curl http://localhost:8000/v1/completions \
+-H "Content-Type: application/json" \
+-d '{
+ "model": "YOUR_MODEL",
+ "prompt": "San Francisco is a",
+ "max_tokens": 128,
+ "temperature": 0
+}' | jq '.choices[0].text'
+```
+
+Below shows an example output using `Qwen1.5-7B-Chat` with low-bit format `sym_int4`:
+
+
+  +
+
+#### Tuning
+
+You can tune the service using these four arguments:
+- `--max-model-len`
+- `--max-num-batched-token`
+- `--max-num-seq`
+
+You can refer to this [doc](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/vLLM_quickstart.html#service) for a detailed explaination on these parameters.
+
+### Benchmark
+
+#### Online benchmark throurgh api_server
+
+We can benchmark the api_server to get an estimation about TPS (transactions per second). To do so, you need to start the service first according to the instructions mentioned above.
+
+Then in the container, do the following:
+1. modify the `/llm/payload-1024.lua` so that the "model" attribute is correct. By default, we use a prompt that is roughly 1024 token long, you can change it if needed.
+2. Start the benchmark using `wrk` using the script below:
+
+```bash
+cd /llm
+# warmup
+wrk -t4 -c4 -d3m -s payload-1024.lua http://localhost:8000/v1/completions --timeout 1h
+# You can change -t and -c to control the concurrency.
+# By default, we use 8 connections to benchmark the service.
+wrk -t8 -c8 -d15m -s payload-1024.lua http://localhost:8000/v1/completions --timeout 1h
+```
+
+#### Offline benchmark through benchmark_vllm_throughput.py
+
+Please refer to this [section](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/vLLM_quickstart.html#performing-benchmark) on how to use `benchmark_vllm_throughput.py` for benchmarking.
diff --git a/docs/mddocs/DockerGuides/vllm_docker_quickstart.md b/docs/mddocs/DockerGuides/vllm_docker_quickstart.md
new file mode 100644
index 00000000..eb7fff3e
--- /dev/null
+++ b/docs/mddocs/DockerGuides/vllm_docker_quickstart.md
@@ -0,0 +1,146 @@
+# vLLM Serving with IPEX-LLM on Intel GPUs via Docker
+
+This guide demonstrates how to run `vLLM` serving with `IPEX-LLM` on Intel GPUs via Docker.
+
+## Install docker
+
+Follow the instructions in this [guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/DockerGuides/docker_windows_gpu.html#linux) to install Docker on Linux.
+
+## Pull the latest image
+
+*Note: For running vLLM serving on Intel GPUs, you can currently use either the `intelanalytics/ipex-llm-serving-xpu:latest` or `intelanalytics/ipex-llm-serving-vllm-xpu:latest` Docker image.*
+```bash
+# This image will be updated every day
+docker pull intelanalytics/ipex-llm-serving-xpu:latest
+```
+
+## Start Docker Container
+
+ To map the `xpu` into the container, you need to specify `--device=/dev/dri` when booting the container. Change the `/path/to/models` to mount the models.
+
+```
+#/bin/bash
+export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-xpu:latest
+export CONTAINER_NAME=ipex-llm-serving-xpu-container
+sudo docker run -itd \
+ --net=host \
+ --device=/dev/dri \
+ -v /path/to/models:/llm/models \
+ -e no_proxy=localhost,127.0.0.1 \
+ --memory="32G" \
+ --name=$CONTAINER_NAME \
+ --shm-size="16g" \
+ $DOCKER_IMAGE
+```
+
+After the container is booted, you could get into the container through `docker exec`.
+
+```bash
+docker exec -it ipex-llm-serving-xpu-container /bin/bash
+```
+
+
+To verify the device is successfully mapped into the container, run `sycl-ls` to check the result. In a machine with Arc A770, the sampled output is:
+
+```bash
+root@arda-arc12:/# sycl-ls
+[opencl:acc:0] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device 1.2 [2023.16.7.0.21_160000]
+[opencl:cpu:1] Intel(R) OpenCL, 13th Gen Intel(R) Core(TM) i9-13900K 3.0 [2023.16.7.0.21_160000]
+[opencl:gpu:2] Intel(R) OpenCL Graphics, Intel(R) Arc(TM) A770 Graphics 3.0 [23.17.26241.33]
+[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) A770 Graphics 1.3 [1.3.26241]
+```
+
+## Running vLLM serving with IPEX-LLM on Intel GPU in Docker
+
+We have included multiple vLLM-related files in `/llm/`:
+1. `vllm_offline_inference.py`: Used for vLLM offline inference example
+2. `benchmark_vllm_throughput.py`: Used for benchmarking throughput
+3. `payload-1024.lua`: Used for testing request per second using 1k-128 request
+4. `start-vllm-service.sh`: Used for template for starting vLLM service
+
+Before performing benchmark or starting the service, you can refer to this [section](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html#runtime-configurations) to setup our recommended runtime configurations.
+
+
+### Service
+
+#### Single card serving
+
+A script named `/llm/start-vllm-service.sh` have been included in the image for starting the service conveniently.
+
+Modify the `model` and `served_model_name` in the script so that it fits your requirement. The `served_model_name` indicates the model name used in the API.
+
+Then start the service using `bash /llm/start-vllm-service.sh`, the following message should be print if the service started successfully.
+
+If the service have booted successfully, you should see the output similar to the following figure:
+
+
+
+
+
+
+#### Multi-card serving
+
+vLLM supports to utilize multiple cards through tensor parallel.
+
+You can refer to this [documentation](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/vLLM_quickstart.html#about-tensor-parallel) on how to utilize the `tensor-parallel` feature and start the service.
+
+#### Verify
+After the service has been booted successfully, you can send a test request using `curl`. Here, `YOUR_MODEL` should be set equal to `served_model_name` in your booting script, e.g. `Qwen1.5`.
+
+
+```bash
+curl http://localhost:8000/v1/completions \
+-H "Content-Type: application/json" \
+-d '{
+ "model": "YOUR_MODEL",
+ "prompt": "San Francisco is a",
+ "max_tokens": 128,
+ "temperature": 0
+}' | jq '.choices[0].text'
+```
+
+Below shows an example output using `Qwen1.5-7B-Chat` with low-bit format `sym_int4`:
+
+
+
+
+
+#### Tuning
+
+You can tune the service using these four arguments:
+- `--gpu-memory-utilization`
+- `--max-model-len`
+- `--max-num-batched-token`
+- `--max-num-seq`
+
+You can refer to this [doc](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/vLLM_quickstart.html#service) for a detailed explaination on these parameters.
+
+### Benchmark
+
+#### Online benchmark throurgh api_server
+
+We can benchmark the api_server to get an estimation about TPS (transactions per second). To do so, you need to start the service first according to the instructions mentioned above.
+
+Then in the container, do the following:
+1. modify the `/llm/payload-1024.lua` so that the "model" attribute is correct. By default, we use a prompt that is roughly 1024 token long, you can change it if needed.
+2. Start the benchmark using `wrk` using the script below:
+
+```bash
+cd /llm
+# warmup due to JIT compliation
+wrk -t4 -c4 -d3m -s payload-1024.lua http://localhost:8000/v1/completions --timeout 1h
+# You can change -t and -c to control the concurrency.
+# By default, we use 12 connections to benchmark the service.
+wrk -t12 -c12 -d15m -s payload-1024.lua http://localhost:8000/v1/completions --timeout 1h
+```
+
+The following figure shows performing benchmark on `Llama-2-7b-chat-hf` using the above script:
+
+
+
+
+
+#### Tuning
+
+You can tune the service using these four arguments:
+- `--max-model-len`
+- `--max-num-batched-token`
+- `--max-num-seq`
+
+You can refer to this [doc](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/vLLM_quickstart.html#service) for a detailed explaination on these parameters.
+
+### Benchmark
+
+#### Online benchmark throurgh api_server
+
+We can benchmark the api_server to get an estimation about TPS (transactions per second). To do so, you need to start the service first according to the instructions mentioned above.
+
+Then in the container, do the following:
+1. modify the `/llm/payload-1024.lua` so that the "model" attribute is correct. By default, we use a prompt that is roughly 1024 token long, you can change it if needed.
+2. Start the benchmark using `wrk` using the script below:
+
+```bash
+cd /llm
+# warmup
+wrk -t4 -c4 -d3m -s payload-1024.lua http://localhost:8000/v1/completions --timeout 1h
+# You can change -t and -c to control the concurrency.
+# By default, we use 8 connections to benchmark the service.
+wrk -t8 -c8 -d15m -s payload-1024.lua http://localhost:8000/v1/completions --timeout 1h
+```
+
+#### Offline benchmark through benchmark_vllm_throughput.py
+
+Please refer to this [section](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/vLLM_quickstart.html#performing-benchmark) on how to use `benchmark_vllm_throughput.py` for benchmarking.
diff --git a/docs/mddocs/DockerGuides/vllm_docker_quickstart.md b/docs/mddocs/DockerGuides/vllm_docker_quickstart.md
new file mode 100644
index 00000000..eb7fff3e
--- /dev/null
+++ b/docs/mddocs/DockerGuides/vllm_docker_quickstart.md
@@ -0,0 +1,146 @@
+# vLLM Serving with IPEX-LLM on Intel GPUs via Docker
+
+This guide demonstrates how to run `vLLM` serving with `IPEX-LLM` on Intel GPUs via Docker.
+
+## Install docker
+
+Follow the instructions in this [guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/DockerGuides/docker_windows_gpu.html#linux) to install Docker on Linux.
+
+## Pull the latest image
+
+*Note: For running vLLM serving on Intel GPUs, you can currently use either the `intelanalytics/ipex-llm-serving-xpu:latest` or `intelanalytics/ipex-llm-serving-vllm-xpu:latest` Docker image.*
+```bash
+# This image will be updated every day
+docker pull intelanalytics/ipex-llm-serving-xpu:latest
+```
+
+## Start Docker Container
+
+ To map the `xpu` into the container, you need to specify `--device=/dev/dri` when booting the container. Change the `/path/to/models` to mount the models.
+
+```
+#/bin/bash
+export DOCKER_IMAGE=intelanalytics/ipex-llm-serving-xpu:latest
+export CONTAINER_NAME=ipex-llm-serving-xpu-container
+sudo docker run -itd \
+ --net=host \
+ --device=/dev/dri \
+ -v /path/to/models:/llm/models \
+ -e no_proxy=localhost,127.0.0.1 \
+ --memory="32G" \
+ --name=$CONTAINER_NAME \
+ --shm-size="16g" \
+ $DOCKER_IMAGE
+```
+
+After the container is booted, you could get into the container through `docker exec`.
+
+```bash
+docker exec -it ipex-llm-serving-xpu-container /bin/bash
+```
+
+
+To verify the device is successfully mapped into the container, run `sycl-ls` to check the result. In a machine with Arc A770, the sampled output is:
+
+```bash
+root@arda-arc12:/# sycl-ls
+[opencl:acc:0] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device 1.2 [2023.16.7.0.21_160000]
+[opencl:cpu:1] Intel(R) OpenCL, 13th Gen Intel(R) Core(TM) i9-13900K 3.0 [2023.16.7.0.21_160000]
+[opencl:gpu:2] Intel(R) OpenCL Graphics, Intel(R) Arc(TM) A770 Graphics 3.0 [23.17.26241.33]
+[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) A770 Graphics 1.3 [1.3.26241]
+```
+
+## Running vLLM serving with IPEX-LLM on Intel GPU in Docker
+
+We have included multiple vLLM-related files in `/llm/`:
+1. `vllm_offline_inference.py`: Used for vLLM offline inference example
+2. `benchmark_vllm_throughput.py`: Used for benchmarking throughput
+3. `payload-1024.lua`: Used for testing request per second using 1k-128 request
+4. `start-vllm-service.sh`: Used for template for starting vLLM service
+
+Before performing benchmark or starting the service, you can refer to this [section](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html#runtime-configurations) to setup our recommended runtime configurations.
+
+
+### Service
+
+#### Single card serving
+
+A script named `/llm/start-vllm-service.sh` have been included in the image for starting the service conveniently.
+
+Modify the `model` and `served_model_name` in the script so that it fits your requirement. The `served_model_name` indicates the model name used in the API.
+
+Then start the service using `bash /llm/start-vllm-service.sh`, the following message should be print if the service started successfully.
+
+If the service have booted successfully, you should see the output similar to the following figure:
+
+
+
+
+
+
+#### Multi-card serving
+
+vLLM supports to utilize multiple cards through tensor parallel.
+
+You can refer to this [documentation](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/vLLM_quickstart.html#about-tensor-parallel) on how to utilize the `tensor-parallel` feature and start the service.
+
+#### Verify
+After the service has been booted successfully, you can send a test request using `curl`. Here, `YOUR_MODEL` should be set equal to `served_model_name` in your booting script, e.g. `Qwen1.5`.
+
+
+```bash
+curl http://localhost:8000/v1/completions \
+-H "Content-Type: application/json" \
+-d '{
+ "model": "YOUR_MODEL",
+ "prompt": "San Francisco is a",
+ "max_tokens": 128,
+ "temperature": 0
+}' | jq '.choices[0].text'
+```
+
+Below shows an example output using `Qwen1.5-7B-Chat` with low-bit format `sym_int4`:
+
+
+
+
+
+#### Tuning
+
+You can tune the service using these four arguments:
+- `--gpu-memory-utilization`
+- `--max-model-len`
+- `--max-num-batched-token`
+- `--max-num-seq`
+
+You can refer to this [doc](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/vLLM_quickstart.html#service) for a detailed explaination on these parameters.
+
+### Benchmark
+
+#### Online benchmark throurgh api_server
+
+We can benchmark the api_server to get an estimation about TPS (transactions per second). To do so, you need to start the service first according to the instructions mentioned above.
+
+Then in the container, do the following:
+1. modify the `/llm/payload-1024.lua` so that the "model" attribute is correct. By default, we use a prompt that is roughly 1024 token long, you can change it if needed.
+2. Start the benchmark using `wrk` using the script below:
+
+```bash
+cd /llm
+# warmup due to JIT compliation
+wrk -t4 -c4 -d3m -s payload-1024.lua http://localhost:8000/v1/completions --timeout 1h
+# You can change -t and -c to control the concurrency.
+# By default, we use 12 connections to benchmark the service.
+wrk -t12 -c12 -d15m -s payload-1024.lua http://localhost:8000/v1/completions --timeout 1h
+```
+
+The following figure shows performing benchmark on `Llama-2-7b-chat-hf` using the above script:
+
+
+  +
+
+
+#### Offline benchmark through benchmark_vllm_throughput.py
+
+Please refer to this [section](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/vLLM_quickstart.html#performing-benchmark) on how to use `benchmark_vllm_throughput.py` for benchmarking.
diff --git a/docs/mddocs/Inference/Self_Speculative_Decoding.md b/docs/mddocs/Inference/Self_Speculative_Decoding.md
new file mode 100644
index 00000000..99179194
--- /dev/null
+++ b/docs/mddocs/Inference/Self_Speculative_Decoding.md
@@ -0,0 +1,23 @@
+# Self-Speculative Decoding
+
+### Speculative Decoding in Practice
+In [speculative](https://arxiv.org/abs/2302.01318) [decoding](https://arxiv.org/abs/2211.17192), a small (draft) model quickly generates multiple draft tokens, which are then verified in parallel by the large (target) model. While speculative decoding can effectively speed up the target model, ***in practice it is difficult to maintain or even obtain a proper draft model***, especially when the target model is finetuned with customized data.
+
+### Self-Speculative Decoding
+Built on top of the concept of “[self-speculative decoding](https://arxiv.org/abs/2309.08168)”, IPEX-LLM can now accelerate the original FP16 or BF16 model ***without the need of a separate draft model or model finetuning***; instead, it automatically converts the original model to INT4, and uses the INT4 model as the draft model behind the scene. In practice, this brings ***~30% speedup*** for FP16 and BF16 LLM inference latency on Intel GPU and CPU respectively.
+
+### Using IPEX-LLM Self-Speculative Decoding
+Please refer to IPEX-LLM self-speculative decoding code snippets below, and the detailed [GPU](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/GPU/Speculative-Decoding) and [CPU](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/CPU/Speculative-Decoding) examples in the project repo.
+
+```python
+model = AutoModelForCausalLM.from_pretrained(model_path,
+ optimize_model=True,
+ torch_dtype=torch.float16, #use bfloat16 on cpu
+ load_in_low_bit="fp16", #use bf16 on cpu
+ speculative=True, #set speculative to true
+ trust_remote_code=True,
+ use_cache=True)
+output = model.generate(input_ids,
+ max_new_tokens=args.n_predict,
+ do_sample=False)
+```
diff --git a/docs/mddocs/Overview/FAQ/faq.md b/docs/mddocs/Overview/FAQ/faq.md
new file mode 100644
index 00000000..caf8bd51
--- /dev/null
+++ b/docs/mddocs/Overview/FAQ/faq.md
@@ -0,0 +1,79 @@
+# Frequently Asked Questions (FAQ)
+
+## General Info & Concepts
+
+### GGUF format usage with IPEX-LLM?
+
+IPEX-LLM supports running GGUF/AWQ/GPTQ models on both [CPU](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations) and [GPU](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations).
+Please also refer to [here](https://github.com/intel-analytics/ipex-llm?tab=readme-ov-file#latest-update-) for our latest support.
+
+## How to Resolve Errors
+
+### Fail to install `ipex-llm` through `pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/` or `pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/`
+
+You could try to install IPEX-LLM dependencies for Intel XPU from source archives:
+- For Windows system, refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#install-ipex-llm-from-wheel) for the steps.
+- For Linux system, refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#id3) for the steps.
+
+### PyTorch is not linked with support for xpu devices
+
+1. Before running on Intel GPUs, please make sure you've prepared environment follwing [installation instruction](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html).
+2. If you are using an older version of `ipex-llm` (specifically, older than 2.5.0b20240104), you need to manually add `import intel_extension_for_pytorch as ipex` at the beginning of your code.
+3. After optimizing the model with IPEX-LLM, you need to move model to GPU through `model = model.to('xpu')`.
+4. If you have mutil GPUs, you could refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/KeyFeatures/multi_gpus_selection.html) for details about GPU selection.
+5. If you do inference using the optimized model on Intel GPUs, you also need to set `to('xpu')` for input tensors.
+
+### Import `intel_extension_for_pytorch` error on Windows GPU
+
+Please refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#error-loading-intel-extension-for-pytorch) for detailed guide. We list the possible missing requirements in environment which could lead to this error.
+
+### XPU device count is zero
+
+It's recommended to reinstall driver:
+- For Windows system, refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#prerequisites) for the steps.
+- For Linux system, refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#id1) for the steps.
+
+### Error such as `The size of tensor a (33) must match the size of tensor b (17) at non-singleton dimension 2` duing attention forward function
+
+If you are using IPEX-LLM PyTorch API, please try to set `optimize_llm=False` manually when call `optimize_model` function to work around. As for IPEX-LLM `transformers`-style API, you could try to set `optimize_model=False` manually when call `from_pretrained` function to work around.
+
+### ValueError: Unrecognized configuration class
+
+This error is not quite relevant to IPEX-LLM. It could be that you're using the incorrect AutoClass, or the transformers version is not updated, or transformers does not support using AutoClasses to load this model. You need to refer to the model card in huggingface to confirm these information. Besides, if you load the model from local path, please also make sure you download the complete model files.
+
+### `mixed dtype (CPU): expect input to have scalar type of BFloat16` during inference
+
+You could solve this error by converting the optimized model to `bf16` through `model.to(torch.bfloat16)` before inference.
+
+### Native API failed. Native API returns: -5 (PI_ERROR_OUT_OF_RESOURCES) -5 (PI_ERROR_OUT_OF_RESOURCES)
+
+This error is caused by out of GPU memory. Some possible solutions to decrease GPU memory uage:
+1. If you run several models continuously, please make sure you have released GPU memory of previous model through `del model` timely.
+2. You could try `model = model.float16()` or `model = model.bfloat16()` before moving model to GPU to use less GPU memory.
+3. You could try set `cpu_embedding=True` when call `from_pretrained` of AutoClass or `optimize_model` function.
+
+### Failed to enable AMX
+
+You could use `export BIGDL_LLM_AMX_DISABLED=1` to disable AMX manually and solve this error.
+
+### oneCCL: comm_selector.cpp:57 create_comm_impl: EXCEPTION: ze_data was not initialized
+
+You may encounter this error during finetuning on multi GPUs. Please try `sudo apt install level-zero-dev` to fix it.
+
+### Random and unreadable output of Gemma-7b-it on Arc770 ubuntu 22.04 due to driver and OneAPI missmatching.
+
+If driver and OneAPI missmatching, it will lead to some error when IPEX-LLM uses XMX(short prompts) for speeding up.
+The output of `What's AI?` may like below:
+```
+wiedzy Artificial Intelligence meliti: Artificial Intelligence undenti beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng
+```
+If you meet this error. Please check your driver version and OneAPI version. Commnad is `sudo apt list --installed | egrep "intel-basekit|intel-level-zero-gpu"`.
+Make sure intel-basekit>=2024.0.1-43 and intel-level-zero-gpu>=1.3.27191.42-775~22.04.
+
+### Too many open files
+
+You may encounter this error during finetuning, expecially when run 70B model. Please raise the system open file limit using `ulimit -n 1048576`.
+
+### `RuntimeError: could not create a primitive` on Windows
+
+This error may happen when multiple GPUs exists for Windows Users. To solve this error, you can open Device Manager (search "Device Manager" in your start menu). Then click the "Display adapter" option, and disable all the GPU device you do not want to use. Restart your computer and try again. IPEX-LLM should work fine this time.
\ No newline at end of file
diff --git a/docs/mddocs/Overview/KeyFeatures/cli.md b/docs/mddocs/Overview/KeyFeatures/cli.md
new file mode 100644
index 00000000..ab162594
--- /dev/null
+++ b/docs/mddocs/Overview/KeyFeatures/cli.md
@@ -0,0 +1,40 @@
+# CLI (Command Line Interface) Tool
+
+```eval_rst
+
+.. note::
+
+ Currently ``ipex-llm`` CLI supports *LLaMA* (e.g., vicuna), *GPT-NeoX* (e.g., redpajama), *BLOOM* (e.g., pheonix) and *GPT2* (e.g., starcoder) model architecture; for other models, you may use the ``transformers``-style or LangChain APIs.
+```
+
+## Convert Model
+
+You may convert the downloaded model into native INT4 format using `llm-convert`.
+
+```bash
+# convert PyTorch (fp16 or fp32) model;
+# llama/bloom/gptneox/starcoder model family is currently supported
+llm-convert "/path/to/model/" --model-format pth --model-family "bloom" --outfile "/path/to/output/"
+
+# convert GPTQ-4bit model
+# only llama model family is currently supported
+llm-convert "/path/to/model/" --model-format gptq --model-family "llama" --outfile "/path/to/output/"
+```
+
+## Run Model
+
+You may run the converted model using `llm-cli` or `llm-chat` (built on top of `main.cpp` in [`llama.cpp`](https://github.com/ggerganov/llama.cpp))
+
+```bash
+# help
+# llama/bloom/gptneox/starcoder model family is currently supported
+llm-cli -x gptneox -h
+
+# text completion
+# llama/bloom/gptneox/starcoder model family is currently supported
+llm-cli -t 16 -x gptneox -m "/path/to/output/model.bin" -p 'Once upon a time,'
+
+# chat mode
+# llama/gptneox model family is currently supported
+llm-chat -m "/path/to/output/model.bin" -x llama
+```
\ No newline at end of file
diff --git a/docs/mddocs/Overview/KeyFeatures/finetune.md b/docs/mddocs/Overview/KeyFeatures/finetune.md
new file mode 100644
index 00000000..b895b89f
--- /dev/null
+++ b/docs/mddocs/Overview/KeyFeatures/finetune.md
@@ -0,0 +1,64 @@
+# Finetune (QLoRA)
+
+We also support finetuning LLMs (large language models) using QLoRA with IPEX-LLM 4bit optimizations on Intel GPUs.
+
+```eval_rst
+.. note::
+
+ Currently, only Hugging Face Transformers models are supported running QLoRA finetuning.
+```
+
+To help you better understand the finetuning process, here we use model [Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) as an example.
+
+**Make sure you have prepared environment following instructions [here](../install_gpu.html).**
+
+```eval_rst
+.. note::
+
+ If you are using an older version of ``ipex-llm`` (specifically, older than 2.5.0b20240104), you need to manually add ``import intel_extension_for_pytorch as ipex`` at the beginning of your code.
+```
+
+First, load model using `transformers`-style API and **set it to `to('xpu')`**. We specify `load_in_low_bit="nf4"` here to apply 4-bit NormalFloat optimization. According to the [QLoRA paper](https://arxiv.org/pdf/2305.14314.pdf), using `"nf4"` could yield better model quality than `"int4"`.
+
+```python
+from ipex_llm.transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf",
+ load_in_low_bit="nf4",
+ optimize_model=False,
+ torch_dtype=torch.float16,
+ modules_to_not_convert=["lm_head"],)
+model = model.to('xpu')
+```
+
+Then, we have to apply some preprocessing to the model to prepare it for training.
+```python
+from ipex_llm.transformers.qlora import prepare_model_for_kbit_training
+model.gradient_checkpointing_enable()
+model = prepare_model_for_kbit_training(model)
+```
+
+Next, we can obtain a Peft model from the optimized model and a configuration object containing the parameters as follows:
+```python
+from ipex_llm.transformers.qlora import get_peft_model
+from peft import LoraConfig
+config = LoraConfig(r=8,
+ lora_alpha=32,
+ target_modules=["q_proj", "k_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM")
+model = get_peft_model(model, config)
+```
+
+```eval_rst
+.. important::
+
+ Instead of ``from peft import prepare_model_for_kbit_training, get_peft_model`` as we did for regular QLoRA using bitandbytes and cuda, we import them from ``ipex_llm.transformers.qlora`` here to get a IPEX-LLM compatible Peft model. And the rest is just the same as regular LoRA finetuning process using ``peft``.
+```
+
+```eval_rst
+.. seealso::
+
+ See the complete examples `here
+
+
+
+#### Offline benchmark through benchmark_vllm_throughput.py
+
+Please refer to this [section](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/vLLM_quickstart.html#performing-benchmark) on how to use `benchmark_vllm_throughput.py` for benchmarking.
diff --git a/docs/mddocs/Inference/Self_Speculative_Decoding.md b/docs/mddocs/Inference/Self_Speculative_Decoding.md
new file mode 100644
index 00000000..99179194
--- /dev/null
+++ b/docs/mddocs/Inference/Self_Speculative_Decoding.md
@@ -0,0 +1,23 @@
+# Self-Speculative Decoding
+
+### Speculative Decoding in Practice
+In [speculative](https://arxiv.org/abs/2302.01318) [decoding](https://arxiv.org/abs/2211.17192), a small (draft) model quickly generates multiple draft tokens, which are then verified in parallel by the large (target) model. While speculative decoding can effectively speed up the target model, ***in practice it is difficult to maintain or even obtain a proper draft model***, especially when the target model is finetuned with customized data.
+
+### Self-Speculative Decoding
+Built on top of the concept of “[self-speculative decoding](https://arxiv.org/abs/2309.08168)”, IPEX-LLM can now accelerate the original FP16 or BF16 model ***without the need of a separate draft model or model finetuning***; instead, it automatically converts the original model to INT4, and uses the INT4 model as the draft model behind the scene. In practice, this brings ***~30% speedup*** for FP16 and BF16 LLM inference latency on Intel GPU and CPU respectively.
+
+### Using IPEX-LLM Self-Speculative Decoding
+Please refer to IPEX-LLM self-speculative decoding code snippets below, and the detailed [GPU](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/GPU/Speculative-Decoding) and [CPU](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/CPU/Speculative-Decoding) examples in the project repo.
+
+```python
+model = AutoModelForCausalLM.from_pretrained(model_path,
+ optimize_model=True,
+ torch_dtype=torch.float16, #use bfloat16 on cpu
+ load_in_low_bit="fp16", #use bf16 on cpu
+ speculative=True, #set speculative to true
+ trust_remote_code=True,
+ use_cache=True)
+output = model.generate(input_ids,
+ max_new_tokens=args.n_predict,
+ do_sample=False)
+```
diff --git a/docs/mddocs/Overview/FAQ/faq.md b/docs/mddocs/Overview/FAQ/faq.md
new file mode 100644
index 00000000..caf8bd51
--- /dev/null
+++ b/docs/mddocs/Overview/FAQ/faq.md
@@ -0,0 +1,79 @@
+# Frequently Asked Questions (FAQ)
+
+## General Info & Concepts
+
+### GGUF format usage with IPEX-LLM?
+
+IPEX-LLM supports running GGUF/AWQ/GPTQ models on both [CPU](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations) and [GPU](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations).
+Please also refer to [here](https://github.com/intel-analytics/ipex-llm?tab=readme-ov-file#latest-update-) for our latest support.
+
+## How to Resolve Errors
+
+### Fail to install `ipex-llm` through `pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/` or `pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/`
+
+You could try to install IPEX-LLM dependencies for Intel XPU from source archives:
+- For Windows system, refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#install-ipex-llm-from-wheel) for the steps.
+- For Linux system, refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#id3) for the steps.
+
+### PyTorch is not linked with support for xpu devices
+
+1. Before running on Intel GPUs, please make sure you've prepared environment follwing [installation instruction](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html).
+2. If you are using an older version of `ipex-llm` (specifically, older than 2.5.0b20240104), you need to manually add `import intel_extension_for_pytorch as ipex` at the beginning of your code.
+3. After optimizing the model with IPEX-LLM, you need to move model to GPU through `model = model.to('xpu')`.
+4. If you have mutil GPUs, you could refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/KeyFeatures/multi_gpus_selection.html) for details about GPU selection.
+5. If you do inference using the optimized model on Intel GPUs, you also need to set `to('xpu')` for input tensors.
+
+### Import `intel_extension_for_pytorch` error on Windows GPU
+
+Please refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#error-loading-intel-extension-for-pytorch) for detailed guide. We list the possible missing requirements in environment which could lead to this error.
+
+### XPU device count is zero
+
+It's recommended to reinstall driver:
+- For Windows system, refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#prerequisites) for the steps.
+- For Linux system, refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install_gpu.html#id1) for the steps.
+
+### Error such as `The size of tensor a (33) must match the size of tensor b (17) at non-singleton dimension 2` duing attention forward function
+
+If you are using IPEX-LLM PyTorch API, please try to set `optimize_llm=False` manually when call `optimize_model` function to work around. As for IPEX-LLM `transformers`-style API, you could try to set `optimize_model=False` manually when call `from_pretrained` function to work around.
+
+### ValueError: Unrecognized configuration class
+
+This error is not quite relevant to IPEX-LLM. It could be that you're using the incorrect AutoClass, or the transformers version is not updated, or transformers does not support using AutoClasses to load this model. You need to refer to the model card in huggingface to confirm these information. Besides, if you load the model from local path, please also make sure you download the complete model files.
+
+### `mixed dtype (CPU): expect input to have scalar type of BFloat16` during inference
+
+You could solve this error by converting the optimized model to `bf16` through `model.to(torch.bfloat16)` before inference.
+
+### Native API failed. Native API returns: -5 (PI_ERROR_OUT_OF_RESOURCES) -5 (PI_ERROR_OUT_OF_RESOURCES)
+
+This error is caused by out of GPU memory. Some possible solutions to decrease GPU memory uage:
+1. If you run several models continuously, please make sure you have released GPU memory of previous model through `del model` timely.
+2. You could try `model = model.float16()` or `model = model.bfloat16()` before moving model to GPU to use less GPU memory.
+3. You could try set `cpu_embedding=True` when call `from_pretrained` of AutoClass or `optimize_model` function.
+
+### Failed to enable AMX
+
+You could use `export BIGDL_LLM_AMX_DISABLED=1` to disable AMX manually and solve this error.
+
+### oneCCL: comm_selector.cpp:57 create_comm_impl: EXCEPTION: ze_data was not initialized
+
+You may encounter this error during finetuning on multi GPUs. Please try `sudo apt install level-zero-dev` to fix it.
+
+### Random and unreadable output of Gemma-7b-it on Arc770 ubuntu 22.04 due to driver and OneAPI missmatching.
+
+If driver and OneAPI missmatching, it will lead to some error when IPEX-LLM uses XMX(short prompts) for speeding up.
+The output of `What's AI?` may like below:
+```
+wiedzy Artificial Intelligence meliti: Artificial Intelligence undenti beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng beng
+```
+If you meet this error. Please check your driver version and OneAPI version. Commnad is `sudo apt list --installed | egrep "intel-basekit|intel-level-zero-gpu"`.
+Make sure intel-basekit>=2024.0.1-43 and intel-level-zero-gpu>=1.3.27191.42-775~22.04.
+
+### Too many open files
+
+You may encounter this error during finetuning, expecially when run 70B model. Please raise the system open file limit using `ulimit -n 1048576`.
+
+### `RuntimeError: could not create a primitive` on Windows
+
+This error may happen when multiple GPUs exists for Windows Users. To solve this error, you can open Device Manager (search "Device Manager" in your start menu). Then click the "Display adapter" option, and disable all the GPU device you do not want to use. Restart your computer and try again. IPEX-LLM should work fine this time.
\ No newline at end of file
diff --git a/docs/mddocs/Overview/KeyFeatures/cli.md b/docs/mddocs/Overview/KeyFeatures/cli.md
new file mode 100644
index 00000000..ab162594
--- /dev/null
+++ b/docs/mddocs/Overview/KeyFeatures/cli.md
@@ -0,0 +1,40 @@
+# CLI (Command Line Interface) Tool
+
+```eval_rst
+
+.. note::
+
+ Currently ``ipex-llm`` CLI supports *LLaMA* (e.g., vicuna), *GPT-NeoX* (e.g., redpajama), *BLOOM* (e.g., pheonix) and *GPT2* (e.g., starcoder) model architecture; for other models, you may use the ``transformers``-style or LangChain APIs.
+```
+
+## Convert Model
+
+You may convert the downloaded model into native INT4 format using `llm-convert`.
+
+```bash
+# convert PyTorch (fp16 or fp32) model;
+# llama/bloom/gptneox/starcoder model family is currently supported
+llm-convert "/path/to/model/" --model-format pth --model-family "bloom" --outfile "/path/to/output/"
+
+# convert GPTQ-4bit model
+# only llama model family is currently supported
+llm-convert "/path/to/model/" --model-format gptq --model-family "llama" --outfile "/path/to/output/"
+```
+
+## Run Model
+
+You may run the converted model using `llm-cli` or `llm-chat` (built on top of `main.cpp` in [`llama.cpp`](https://github.com/ggerganov/llama.cpp))
+
+```bash
+# help
+# llama/bloom/gptneox/starcoder model family is currently supported
+llm-cli -x gptneox -h
+
+# text completion
+# llama/bloom/gptneox/starcoder model family is currently supported
+llm-cli -t 16 -x gptneox -m "/path/to/output/model.bin" -p 'Once upon a time,'
+
+# chat mode
+# llama/gptneox model family is currently supported
+llm-chat -m "/path/to/output/model.bin" -x llama
+```
\ No newline at end of file
diff --git a/docs/mddocs/Overview/KeyFeatures/finetune.md b/docs/mddocs/Overview/KeyFeatures/finetune.md
new file mode 100644
index 00000000..b895b89f
--- /dev/null
+++ b/docs/mddocs/Overview/KeyFeatures/finetune.md
@@ -0,0 +1,64 @@
+# Finetune (QLoRA)
+
+We also support finetuning LLMs (large language models) using QLoRA with IPEX-LLM 4bit optimizations on Intel GPUs.
+
+```eval_rst
+.. note::
+
+ Currently, only Hugging Face Transformers models are supported running QLoRA finetuning.
+```
+
+To help you better understand the finetuning process, here we use model [Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) as an example.
+
+**Make sure you have prepared environment following instructions [here](../install_gpu.html).**
+
+```eval_rst
+.. note::
+
+ If you are using an older version of ``ipex-llm`` (specifically, older than 2.5.0b20240104), you need to manually add ``import intel_extension_for_pytorch as ipex`` at the beginning of your code.
+```
+
+First, load model using `transformers`-style API and **set it to `to('xpu')`**. We specify `load_in_low_bit="nf4"` here to apply 4-bit NormalFloat optimization. According to the [QLoRA paper](https://arxiv.org/pdf/2305.14314.pdf), using `"nf4"` could yield better model quality than `"int4"`.
+
+```python
+from ipex_llm.transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf",
+ load_in_low_bit="nf4",
+ optimize_model=False,
+ torch_dtype=torch.float16,
+ modules_to_not_convert=["lm_head"],)
+model = model.to('xpu')
+```
+
+Then, we have to apply some preprocessing to the model to prepare it for training.
+```python
+from ipex_llm.transformers.qlora import prepare_model_for_kbit_training
+model.gradient_checkpointing_enable()
+model = prepare_model_for_kbit_training(model)
+```
+
+Next, we can obtain a Peft model from the optimized model and a configuration object containing the parameters as follows:
+```python
+from ipex_llm.transformers.qlora import get_peft_model
+from peft import LoraConfig
+config = LoraConfig(r=8,
+ lora_alpha=32,
+ target_modules=["q_proj", "k_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM")
+model = get_peft_model(model, config)
+```
+
+```eval_rst
+.. important::
+
+ Instead of ``from peft import prepare_model_for_kbit_training, get_peft_model`` as we did for regular QLoRA using bitandbytes and cuda, we import them from ``ipex_llm.transformers.qlora`` here to get a IPEX-LLM compatible Peft model. And the rest is just the same as regular LoRA finetuning process using ``peft``.
+```
+
+```eval_rst
+.. seealso::
+
+ See the complete examples `here
+ [1]
+ Performance varies by use, configuration and other factors. ipex-llm may not optimize to the same degree for non-Intel products. Learn more at www.Intel.com/PerformanceIndex.
+
+
| English | +简体中文 | +
| + | + |
 +
+## Quickstart
+
+### Install and Run
+
+Follow the guide that corresponds to your specific system and device from the links provided below:
+
+- For systems with Intel Core Ultra integrated GPU: [Windows Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_win_mtl.md#) | [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_mtl.md#)
+- For systems with Intel Arc A-Series GPU: [Windows Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_win_arc.md#) | [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_arc.md#)
+- For systems with Intel Data Center Max Series GPU: [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_max.md#)
+- For systems with Xeon-Series CPU: [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_xeon.md#)
+
+### How to use RAG
+
+#### Step 1: Create Knowledge Base
+
+- Select `Manage Knowledge Base` from the menu on the left, then choose `New Knowledge Base` from the dropdown menu on the right side.
+
+
+
+
+## Quickstart
+
+### Install and Run
+
+Follow the guide that corresponds to your specific system and device from the links provided below:
+
+- For systems with Intel Core Ultra integrated GPU: [Windows Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_win_mtl.md#) | [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_mtl.md#)
+- For systems with Intel Arc A-Series GPU: [Windows Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_win_arc.md#) | [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_arc.md#)
+- For systems with Intel Data Center Max Series GPU: [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_max.md#)
+- For systems with Xeon-Series CPU: [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_xeon.md#)
+
+### How to use RAG
+
+#### Step 1: Create Knowledge Base
+
+- Select `Manage Knowledge Base` from the menu on the left, then choose `New Knowledge Base` from the dropdown menu on the right side.
+
+
+ 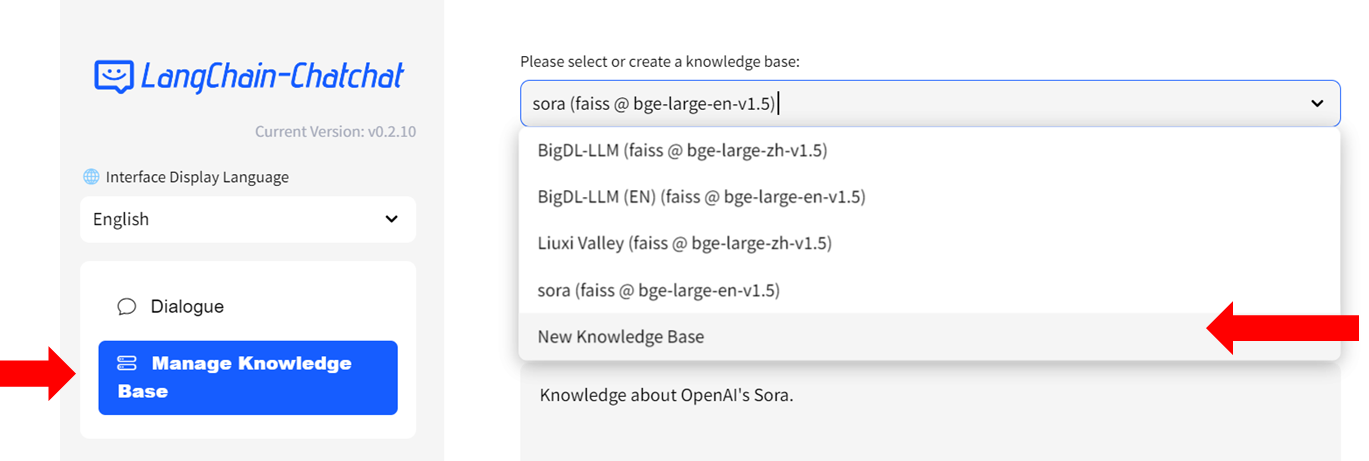 +
+
+- Fill in the name of your new knowledge base (example: "test") and press the `Create` button. Adjust any other settings as needed.
+
+
+
+
+
+- Fill in the name of your new knowledge base (example: "test") and press the `Create` button. Adjust any other settings as needed.
+
+
+ 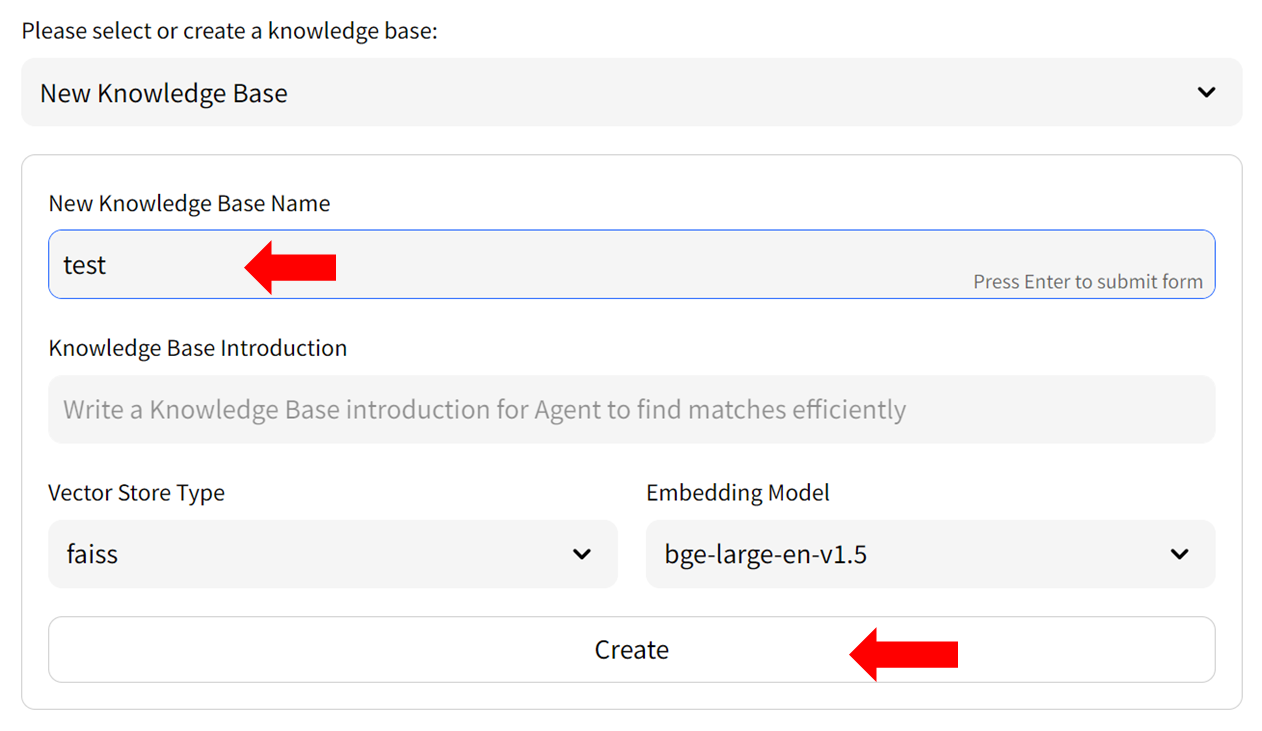 +
+
+- Upload knowledge files from your computer and allow some time for the upload to complete. Once finished, click on `Add files to Knowledge Base` button to build the vector store. Note: this process may take several minutes.
+
+
+
+
+
+- Upload knowledge files from your computer and allow some time for the upload to complete. Once finished, click on `Add files to Knowledge Base` button to build the vector store. Note: this process may take several minutes.
+
+
+ 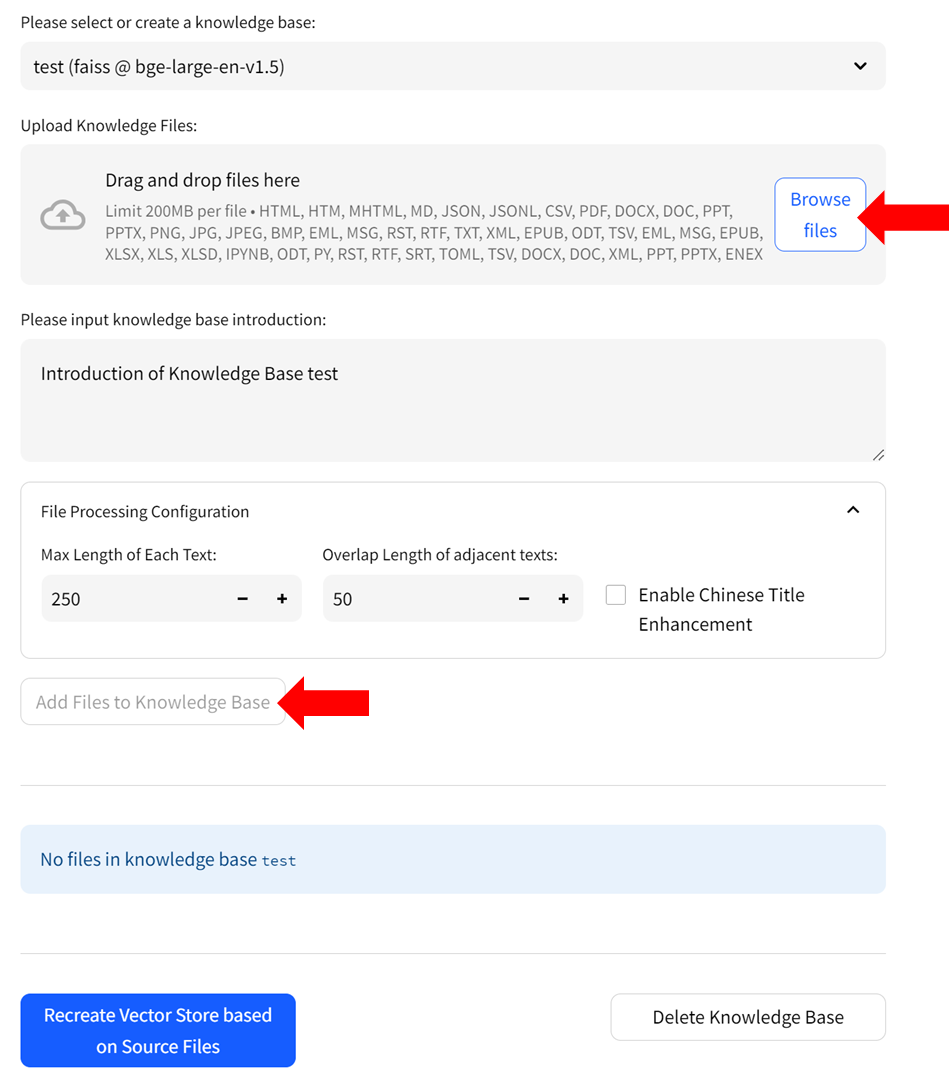 +
+
+#### Step 2: Chat with RAG
+
+You can now click `Dialogue` on the left-side menu to return to the chat UI. Then in `Knowledge base settings` menu, choose the Knowledge Base you just created, e.g, "test". Now you can start chatting.
+
+
+
+
+
+#### Step 2: Chat with RAG
+
+You can now click `Dialogue` on the left-side menu to return to the chat UI. Then in `Knowledge base settings` menu, choose the Knowledge Base you just created, e.g, "test". Now you can start chatting.
+
+
+ 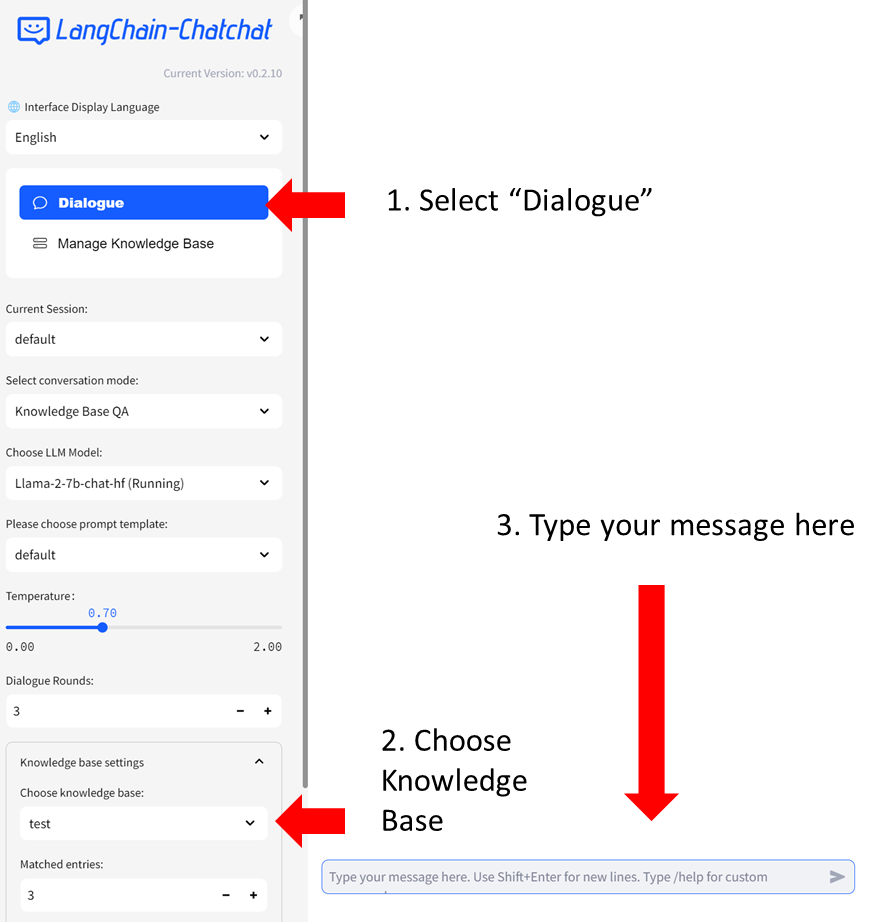 +
+
+
+
+
+ +
+
+
+
+
+ +
+
+
+
+
+ +
+
+
+
+
+ +
+
+When you see the screen below, your plug-in is ready to use.
+
+
+
+
+
+When you see the screen below, your plug-in is ready to use.
+
+
+  +
+
+### 4. `Continue` Configuration
+
+Once `Continue` is installed and ready, simply select the model "`Ollama - codeqwen:latest-continue`" from the bottom of the `Continue` view (all models in `ollama list` will appear in the format `Ollama-xxx`).
+
+Now you can start using `Continue`.
+
+#### Connecting to Remote Ollama Service
+
+You can configure `Continue` by clicking the small gear icon located at the bottom right of the `Continue` view to open `config.json`. In `config.json`, you will find all necessary configuration settings.
+
+If you are running Ollama on the same machine as `Continue`, no changes are necessary. If Ollama is running on a different machine, you'll need to update the `apiBase` key in `Ollama` item in `config.json` to point to the remote Ollama URL, as shown in the example below and in the figure.
+
+```json
+ {
+ "title": "Ollama",
+ "provider": "ollama",
+ "model": "AUTODETECT",
+ "apiBase": "http://your-ollama-service-ip:11434"
+ }
+```
+
+
+
+
+
+### 4. `Continue` Configuration
+
+Once `Continue` is installed and ready, simply select the model "`Ollama - codeqwen:latest-continue`" from the bottom of the `Continue` view (all models in `ollama list` will appear in the format `Ollama-xxx`).
+
+Now you can start using `Continue`.
+
+#### Connecting to Remote Ollama Service
+
+You can configure `Continue` by clicking the small gear icon located at the bottom right of the `Continue` view to open `config.json`. In `config.json`, you will find all necessary configuration settings.
+
+If you are running Ollama on the same machine as `Continue`, no changes are necessary. If Ollama is running on a different machine, you'll need to update the `apiBase` key in `Ollama` item in `config.json` to point to the remote Ollama URL, as shown in the example below and in the figure.
+
+```json
+ {
+ "title": "Ollama",
+ "provider": "ollama",
+ "model": "AUTODETECT",
+ "apiBase": "http://your-ollama-service-ip:11434"
+ }
+```
+
+
+  +
+
+
+
+### 5. How to Use `Continue`
+For detailed tutorials please refer to [this link](https://continue.dev/docs/how-to-use-continue). Here we are only showing the most common scenarios.
+
+#### Q&A over specific code
+If you don't understand how some code works, highlight(press `Ctrl+Shift+L`) it and ask "how does this code work?"
+
+
+
+
+
+
+
+### 5. How to Use `Continue`
+For detailed tutorials please refer to [this link](https://continue.dev/docs/how-to-use-continue). Here we are only showing the most common scenarios.
+
+#### Q&A over specific code
+If you don't understand how some code works, highlight(press `Ctrl+Shift+L`) it and ask "how does this code work?"
+
+
+  +
+
+#### Editing code
+You can ask Continue to edit your highlighted code with the command `/edit`.
+
+
+
+
+
+#### Editing code
+You can ask Continue to edit your highlighted code with the command `/edit`.
+
+
+  +
+
diff --git a/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md b/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md
new file mode 100644
index 00000000..f99c6731
--- /dev/null
+++ b/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md
@@ -0,0 +1,102 @@
+# Run IPEX-LLM serving on Multiple Intel GPUs using DeepSpeed AutoTP and FastApi
+
+This example demonstrates how to run IPEX-LLM serving on multiple [Intel GPUs](../README.md) by leveraging DeepSpeed AutoTP.
+
+## Requirements
+
+To run this example with IPEX-LLM on Intel GPUs, we have some recommended requirements for your machine, please refer to [here](../README.md#recommended-requirements) for more information. For this particular example, you will need at least two GPUs on your machine.
+
+## Example
+
+### 1. Install
+
+```bash
+conda create -n llm python=3.11
+conda activate llm
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+pip install oneccl_bind_pt==2.1.100 --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+# configures OneAPI environment variables
+source /opt/intel/oneapi/setvars.sh
+pip install git+https://github.com/microsoft/DeepSpeed.git@ed8aed5
+pip install git+https://github.com/intel/intel-extension-for-deepspeed.git@0eb734b
+pip install mpi4py fastapi uvicorn
+conda install -c conda-forge -y gperftools=2.10 # to enable tcmalloc
+```
+
+> **Important**: IPEX 2.1.10+xpu requires Intel® oneAPI Base Toolkit's version == 2024.0. Please make sure you have installed the correct version.
+
+### 2. Run tensor parallel inference on multiple GPUs
+
+When we run the model in a distributed manner across two GPUs, the memory consumption of each GPU is only half of what it was originally, and the GPUs can work simultaneously during inference computation.
+
+We provide example usage for `Llama-2-7b-chat-hf` model running on Arc A770
+
+Run Llama-2-7b-chat-hf on two Intel Arc A770:
+
+```bash
+
+# Before run this script, you should adjust the YOUR_REPO_ID_OR_MODEL_PATH in last line
+# If you want to change server port, you can set port parameter in last line
+
+# To avoid GPU OOM, you could adjust --max-num-seqs and --max-num-batched-tokens parameters in below script
+bash run_llama2_7b_chat_hf_arc_2_card.sh
+```
+
+If you successfully run the serving, you can get output like this:
+
+```bash
+[0] INFO: Started server process [120071]
+[0] INFO: Waiting for application startup.
+[0] INFO: Application startup complete.
+[0] INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
+```
+
+> **Note**: You could change `NUM_GPUS` to the number of GPUs you have on your machine. And you could also specify other low bit optimizations through `--low-bit`.
+
+### 3. Sample Input and Output
+
+We can use `curl` to test serving api
+
+```bash
+# Set http_proxy and https_proxy to null to ensure that requests are not forwarded by a proxy.
+export http_proxy=
+export https_proxy=
+
+curl -X 'POST' \
+ 'http://127.0.0.1:8000/generate/' \
+ -H 'accept: application/json' \
+ -H 'Content-Type: application/json' \
+ -d '{
+ "prompt": "What is AI?",
+ "n_predict": 32
+}'
+```
+
+And you should get output like this:
+
+```json
+{
+ "generated_text": "What is AI? Artificial intelligence (AI) refers to the development of computer systems able to perform tasks that would normally require human intelligence, such as visual perception, speech",
+ "generate_time": "0.45149803161621094s"
+}
+
+```
+
+**Important**: The first token latency is much larger than rest token latency, you could use [our benchmark tool](https://github.com/intel-analytics/ipex-llm/blob/main/python/llm/dev/benchmark/README.md) to obtain more details about first and rest token latency.
+
+### 4. Benchmark with wrk
+
+We use wrk for testing end-to-end throughput, check [here](https://github.com/wg/wrk).
+
+You can install by:
+```bash
+sudo apt install wrk
+```
+
+Please change the test url accordingly.
+
+```bash
+# set t/c to the number of concurrencies to test full throughput.
+wrk -t1 -c1 -d5m -s ./wrk_script_1024.lua http://127.0.0.1:8000/generate/ --timeout 1m
+```
\ No newline at end of file
diff --git a/docs/mddocs/Quickstart/dify_quickstart.md b/docs/mddocs/Quickstart/dify_quickstart.md
new file mode 100644
index 00000000..97e4ae2d
--- /dev/null
+++ b/docs/mddocs/Quickstart/dify_quickstart.md
@@ -0,0 +1,150 @@
+# Run Dify on Intel GPU
+
+
+[**Dify**](https://dify.ai/) is an open-source production-ready LLM app development platform; by integrating it with [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily leverage local LLMs running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) for building complex AI workflows (e.g. RAG).
+
+
+*See the demo of a RAG workflow in Dify running LLaMA2-7B on Intel A770 GPU below.*
+
+
+
+
+## Quickstart
+
+### 1. Install and Start `Ollama` Service on Intel GPU
+
+Follow the steps in [Run Ollama on Intel GPU Guide](./ollama_quickstart.md) to install and run Ollama on Intel GPU. Ensure that `ollama serve` is running correctly and can be accessed through a local URL (e.g., `https://127.0.0.1:11434`) or a remote URL (e.g., `http://your_ip:11434`).
+
+We recommend pulling the desired model before proceeding with Dify. For instance, to pull the LLaMA2-7B model, you can use the following command:
+
+```bash
+ollama pull llama2:7b
+```
+
+### 2. Install and Start `Dify`
+
+
+#### 2.1 Download `Dify`
+
+You can either clone the repository or download the source zip from [github](https://github.com/langgenius/dify/archive/refs/heads/main.zip):
+```bash
+git clone https://github.com/langgenius/dify.git
+```
+
+#### 2.2 Setup Redis and PostgreSQL
+
+Next, deploy PostgreSQL and Redis. You can choose to utilize Docker, following the steps in the [Local Source Code Start Guide](https://docs.dify.ai/getting-started/install-self-hosted/local-source-code#clone-dify), or proceed without Docker using the following instructions:
+
+
+- Install Redis by executing `sudo apt-get install redis-server`. Refer to [this guide](https://www.hostinger.com/tutorials/how-to-install-and-setup-redis-on-ubuntu/) for Redis environment setup, including password configuration and daemon settings.
+
+- Install PostgreSQL by following either [the Official PostgreSQL Tutorial](https://www.postgresql.org/docs/current/tutorial.html) or [a PostgreSQL Quickstart Guide](https://www.digitalocean.com/community/tutorials/how-to-install-postgresql-on-ubuntu-20-04-quickstart). After installation, proceed with the following PostgreSQL commands for setting up Dify. These commands create a username/password for Dify (e.g., `dify_user`, change `'your_password'` as desired), create a new database named `dify`, and grant privileges:
+ ```sql
+ CREATE USER dify_user WITH PASSWORD 'your_password';
+ CREATE DATABASE dify;
+ GRANT ALL PRIVILEGES ON DATABASE dify TO dify_user;
+ ```
+
+Configure Redis and PostgreSQL settings in the `.env` file located under dify source folder `dify/api/`:
+
+```bash dify/api/.env
+### Example dify/api/.env
+## Redis settings
+REDIS_HOST=localhost
+REDIS_PORT=6379
+REDIS_USERNAME=your_redis_user_name # change if needed
+REDIS_PASSWORD=your_redis_password # change if needed
+REDIS_DB=0
+
+## postgreSQL settings
+DB_USERNAME=dify_user # change if needed
+DB_PASSWORD=your_dify_password # change if needed
+DB_HOST=localhost
+DB_PORT=5432
+DB_DATABASE=dify # change if needed
+```
+
+#### 2.3 Server Deployment
+
+Follow the steps in the [`Server Deployment` section in Local Source Code Start Guide](https://docs.dify.ai/getting-started/install-self-hosted/local-source-code#server-deployment) to deploy and start the Dify Server.
+
+Upon successful deployment, you will see logs in the terminal similar to the following:
+
+
+```bash
+INFO:werkzeug:
+* Running on all addresses (0.0.0.0)
+* Running on http://127.0.0.1:5001
+* Running on http://10.239.44.83:5001
+INFO:werkzeug:Press CTRL+C to quit
+INFO:werkzeug: * Restarting with stat
+WARNING:werkzeug: * Debugger is active!
+INFO:werkzeug: * Debugger PIN: 227-697-894
+```
+
+
+#### 2.4 Deploy the frontend page
+
+Refer to the instructions provided in the [`Deploy the frontend page` section in Local Source Code Start Guide](https://docs.dify.ai/getting-started/install-self-hosted/local-source-code#deploy-the-frontend-page) to deploy the frontend page.
+
+Below is an example of environment variable configuration found in `dify/web/.env.local`:
+
+
+```bash
+# For production release, change this to PRODUCTION
+NEXT_PUBLIC_DEPLOY_ENV=DEVELOPMENT
+NEXT_PUBLIC_EDITION=SELF_HOSTED
+NEXT_PUBLIC_API_PREFIX=http://localhost:5001/console/api
+NEXT_PUBLIC_PUBLIC_API_PREFIX=http://localhost:5001/api
+NEXT_PUBLIC_SENTRY_DSN=
+```
+
+```eval_rst
+
+.. note::
+
+ If you encounter connection problems, you may run `export no_proxy=localhost,127.0.0.1` before starting API servcie, Worker service and frontend.
+
+```
+
+
+### 3. How to Use `Dify`
+
+For comprehensive usage instructions of Dify, please refer to the [Dify Documentation](https://docs.dify.ai/). In this section, we'll only highlight a few key steps for local LLM setup.
+
+
+#### Setup Ollama
+
+Open your browser and access the Dify UI at `http://localhost:3000`.
+
+
+Configure the Ollama URL in `Settings > Model Providers > Ollama`. For detailed instructions on how to do this, see the [Ollama Guide in the Dify Documentation](https://docs.dify.ai/tutorials/model-configuration/ollama).
+
+
+
+
+
diff --git a/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md b/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md
new file mode 100644
index 00000000..f99c6731
--- /dev/null
+++ b/docs/mddocs/Quickstart/deepspeed_autotp_fastapi_quickstart.md
@@ -0,0 +1,102 @@
+# Run IPEX-LLM serving on Multiple Intel GPUs using DeepSpeed AutoTP and FastApi
+
+This example demonstrates how to run IPEX-LLM serving on multiple [Intel GPUs](../README.md) by leveraging DeepSpeed AutoTP.
+
+## Requirements
+
+To run this example with IPEX-LLM on Intel GPUs, we have some recommended requirements for your machine, please refer to [here](../README.md#recommended-requirements) for more information. For this particular example, you will need at least two GPUs on your machine.
+
+## Example
+
+### 1. Install
+
+```bash
+conda create -n llm python=3.11
+conda activate llm
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+pip install oneccl_bind_pt==2.1.100 --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+# configures OneAPI environment variables
+source /opt/intel/oneapi/setvars.sh
+pip install git+https://github.com/microsoft/DeepSpeed.git@ed8aed5
+pip install git+https://github.com/intel/intel-extension-for-deepspeed.git@0eb734b
+pip install mpi4py fastapi uvicorn
+conda install -c conda-forge -y gperftools=2.10 # to enable tcmalloc
+```
+
+> **Important**: IPEX 2.1.10+xpu requires Intel® oneAPI Base Toolkit's version == 2024.0. Please make sure you have installed the correct version.
+
+### 2. Run tensor parallel inference on multiple GPUs
+
+When we run the model in a distributed manner across two GPUs, the memory consumption of each GPU is only half of what it was originally, and the GPUs can work simultaneously during inference computation.
+
+We provide example usage for `Llama-2-7b-chat-hf` model running on Arc A770
+
+Run Llama-2-7b-chat-hf on two Intel Arc A770:
+
+```bash
+
+# Before run this script, you should adjust the YOUR_REPO_ID_OR_MODEL_PATH in last line
+# If you want to change server port, you can set port parameter in last line
+
+# To avoid GPU OOM, you could adjust --max-num-seqs and --max-num-batched-tokens parameters in below script
+bash run_llama2_7b_chat_hf_arc_2_card.sh
+```
+
+If you successfully run the serving, you can get output like this:
+
+```bash
+[0] INFO: Started server process [120071]
+[0] INFO: Waiting for application startup.
+[0] INFO: Application startup complete.
+[0] INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
+```
+
+> **Note**: You could change `NUM_GPUS` to the number of GPUs you have on your machine. And you could also specify other low bit optimizations through `--low-bit`.
+
+### 3. Sample Input and Output
+
+We can use `curl` to test serving api
+
+```bash
+# Set http_proxy and https_proxy to null to ensure that requests are not forwarded by a proxy.
+export http_proxy=
+export https_proxy=
+
+curl -X 'POST' \
+ 'http://127.0.0.1:8000/generate/' \
+ -H 'accept: application/json' \
+ -H 'Content-Type: application/json' \
+ -d '{
+ "prompt": "What is AI?",
+ "n_predict": 32
+}'
+```
+
+And you should get output like this:
+
+```json
+{
+ "generated_text": "What is AI? Artificial intelligence (AI) refers to the development of computer systems able to perform tasks that would normally require human intelligence, such as visual perception, speech",
+ "generate_time": "0.45149803161621094s"
+}
+
+```
+
+**Important**: The first token latency is much larger than rest token latency, you could use [our benchmark tool](https://github.com/intel-analytics/ipex-llm/blob/main/python/llm/dev/benchmark/README.md) to obtain more details about first and rest token latency.
+
+### 4. Benchmark with wrk
+
+We use wrk for testing end-to-end throughput, check [here](https://github.com/wg/wrk).
+
+You can install by:
+```bash
+sudo apt install wrk
+```
+
+Please change the test url accordingly.
+
+```bash
+# set t/c to the number of concurrencies to test full throughput.
+wrk -t1 -c1 -d5m -s ./wrk_script_1024.lua http://127.0.0.1:8000/generate/ --timeout 1m
+```
\ No newline at end of file
diff --git a/docs/mddocs/Quickstart/dify_quickstart.md b/docs/mddocs/Quickstart/dify_quickstart.md
new file mode 100644
index 00000000..97e4ae2d
--- /dev/null
+++ b/docs/mddocs/Quickstart/dify_quickstart.md
@@ -0,0 +1,150 @@
+# Run Dify on Intel GPU
+
+
+[**Dify**](https://dify.ai/) is an open-source production-ready LLM app development platform; by integrating it with [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily leverage local LLMs running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) for building complex AI workflows (e.g. RAG).
+
+
+*See the demo of a RAG workflow in Dify running LLaMA2-7B on Intel A770 GPU below.*
+
+
+
+
+## Quickstart
+
+### 1. Install and Start `Ollama` Service on Intel GPU
+
+Follow the steps in [Run Ollama on Intel GPU Guide](./ollama_quickstart.md) to install and run Ollama on Intel GPU. Ensure that `ollama serve` is running correctly and can be accessed through a local URL (e.g., `https://127.0.0.1:11434`) or a remote URL (e.g., `http://your_ip:11434`).
+
+We recommend pulling the desired model before proceeding with Dify. For instance, to pull the LLaMA2-7B model, you can use the following command:
+
+```bash
+ollama pull llama2:7b
+```
+
+### 2. Install and Start `Dify`
+
+
+#### 2.1 Download `Dify`
+
+You can either clone the repository or download the source zip from [github](https://github.com/langgenius/dify/archive/refs/heads/main.zip):
+```bash
+git clone https://github.com/langgenius/dify.git
+```
+
+#### 2.2 Setup Redis and PostgreSQL
+
+Next, deploy PostgreSQL and Redis. You can choose to utilize Docker, following the steps in the [Local Source Code Start Guide](https://docs.dify.ai/getting-started/install-self-hosted/local-source-code#clone-dify), or proceed without Docker using the following instructions:
+
+
+- Install Redis by executing `sudo apt-get install redis-server`. Refer to [this guide](https://www.hostinger.com/tutorials/how-to-install-and-setup-redis-on-ubuntu/) for Redis environment setup, including password configuration and daemon settings.
+
+- Install PostgreSQL by following either [the Official PostgreSQL Tutorial](https://www.postgresql.org/docs/current/tutorial.html) or [a PostgreSQL Quickstart Guide](https://www.digitalocean.com/community/tutorials/how-to-install-postgresql-on-ubuntu-20-04-quickstart). After installation, proceed with the following PostgreSQL commands for setting up Dify. These commands create a username/password for Dify (e.g., `dify_user`, change `'your_password'` as desired), create a new database named `dify`, and grant privileges:
+ ```sql
+ CREATE USER dify_user WITH PASSWORD 'your_password';
+ CREATE DATABASE dify;
+ GRANT ALL PRIVILEGES ON DATABASE dify TO dify_user;
+ ```
+
+Configure Redis and PostgreSQL settings in the `.env` file located under dify source folder `dify/api/`:
+
+```bash dify/api/.env
+### Example dify/api/.env
+## Redis settings
+REDIS_HOST=localhost
+REDIS_PORT=6379
+REDIS_USERNAME=your_redis_user_name # change if needed
+REDIS_PASSWORD=your_redis_password # change if needed
+REDIS_DB=0
+
+## postgreSQL settings
+DB_USERNAME=dify_user # change if needed
+DB_PASSWORD=your_dify_password # change if needed
+DB_HOST=localhost
+DB_PORT=5432
+DB_DATABASE=dify # change if needed
+```
+
+#### 2.3 Server Deployment
+
+Follow the steps in the [`Server Deployment` section in Local Source Code Start Guide](https://docs.dify.ai/getting-started/install-self-hosted/local-source-code#server-deployment) to deploy and start the Dify Server.
+
+Upon successful deployment, you will see logs in the terminal similar to the following:
+
+
+```bash
+INFO:werkzeug:
+* Running on all addresses (0.0.0.0)
+* Running on http://127.0.0.1:5001
+* Running on http://10.239.44.83:5001
+INFO:werkzeug:Press CTRL+C to quit
+INFO:werkzeug: * Restarting with stat
+WARNING:werkzeug: * Debugger is active!
+INFO:werkzeug: * Debugger PIN: 227-697-894
+```
+
+
+#### 2.4 Deploy the frontend page
+
+Refer to the instructions provided in the [`Deploy the frontend page` section in Local Source Code Start Guide](https://docs.dify.ai/getting-started/install-self-hosted/local-source-code#deploy-the-frontend-page) to deploy the frontend page.
+
+Below is an example of environment variable configuration found in `dify/web/.env.local`:
+
+
+```bash
+# For production release, change this to PRODUCTION
+NEXT_PUBLIC_DEPLOY_ENV=DEVELOPMENT
+NEXT_PUBLIC_EDITION=SELF_HOSTED
+NEXT_PUBLIC_API_PREFIX=http://localhost:5001/console/api
+NEXT_PUBLIC_PUBLIC_API_PREFIX=http://localhost:5001/api
+NEXT_PUBLIC_SENTRY_DSN=
+```
+
+```eval_rst
+
+.. note::
+
+ If you encounter connection problems, you may run `export no_proxy=localhost,127.0.0.1` before starting API servcie, Worker service and frontend.
+
+```
+
+
+### 3. How to Use `Dify`
+
+For comprehensive usage instructions of Dify, please refer to the [Dify Documentation](https://docs.dify.ai/). In this section, we'll only highlight a few key steps for local LLM setup.
+
+
+#### Setup Ollama
+
+Open your browser and access the Dify UI at `http://localhost:3000`.
+
+
+Configure the Ollama URL in `Settings > Model Providers > Ollama`. For detailed instructions on how to do this, see the [Ollama Guide in the Dify Documentation](https://docs.dify.ai/tutorials/model-configuration/ollama).
+
+
+
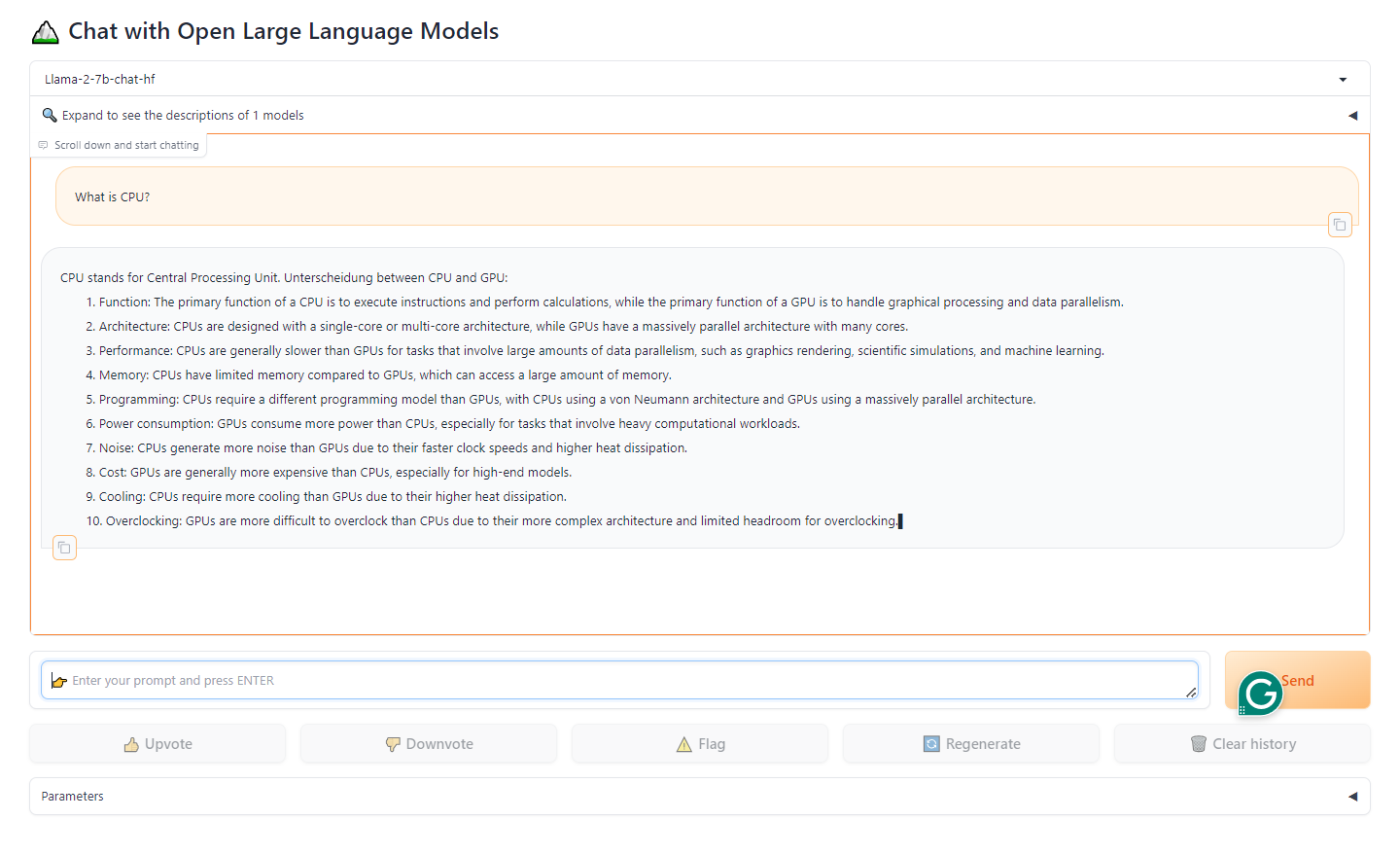 +
+
+By following these steps, you will be able to serve your models using the web UI with IPEX-LLM as the backend. You can open your browser and chat with a model now.
+
+### Launch TGI Style API server
+
+When you have started the controller and the worker, you can start TGI Style API server as follows:
+
+```bash
+python3 -m ipex_llm.serving.fastchat.tgi_api_server --host localhost --port 8000
+```
+You can use `curl` for observing the output of the api
+
+#### Using /generate API
+
+This is to send a sentence as inputs in the request, and is expected to receive a response containing model-generated answer.
+
+```bash
+curl -X POST -H "Content-Type: application/json" -d '{
+ "inputs": "What is AI?",
+ "parameters": {
+ "best_of": 1,
+ "decoder_input_details": true,
+ "details": true,
+ "do_sample": true,
+ "frequency_penalty": 0.1,
+ "grammar": {
+ "type": "json",
+ "value": "string"
+ },
+ "max_new_tokens": 32,
+ "repetition_penalty": 1.03,
+ "return_full_text": false,
+ "seed": 0.1,
+ "stop": [
+ "photographer"
+ ],
+ "temperature": 0.5,
+ "top_k": 10,
+ "top_n_tokens": 5,
+ "top_p": 0.95,
+ "truncate": true,
+ "typical_p": 0.95,
+ "watermark": true
+ }
+}' http://localhost:8000/generate
+```
+
+Sample output:
+```bash
+{
+ "details": {
+ "best_of_sequences": [
+ {
+ "index": 0,
+ "message": {
+ "role": "assistant",
+ "content": "\nArtificial Intelligence (AI) is a branch of computer science that attempts to simulate the way that the human brain works. It is a branch of computer "
+ },
+ "finish_reason": "length",
+ "generated_text": "\nArtificial Intelligence (AI) is a branch of computer science that attempts to simulate the way that the human brain works. It is a branch of computer ",
+ "generated_tokens": 31
+ }
+ ]
+ },
+ "generated_text": "\nArtificial Intelligence (AI) is a branch of computer science that attempts to simulate the way that the human brain works. It is a branch of computer ",
+ "usage": {
+ "prompt_tokens": 4,
+ "total_tokens": 35,
+ "completion_tokens": 31
+ }
+}
+```
+
+#### Using /generate_stream API
+
+This is to send a sentence as inputs in the request, and a long connection will be opened to continuously receive multiple responses containing model-generated answer.
+
+```bash
+curl -X POST -H "Content-Type: application/json" -d '{
+ "inputs": "What is AI?",
+ "parameters": {
+ "best_of": 1,
+ "decoder_input_details": true,
+ "details": true,
+ "do_sample": true,
+ "frequency_penalty": 0.1,
+ "grammar": {
+ "type": "json",
+ "value": "string"
+ },
+ "max_new_tokens": 32,
+ "repetition_penalty": 1.03,
+ "return_full_text": false,
+ "seed": 0.1,
+ "stop": [
+ "photographer"
+ ],
+ "temperature": 0.5,
+ "top_k": 10,
+ "top_n_tokens": 5,
+ "top_p": 0.95,
+ "truncate": true,
+ "typical_p": 0.95,
+ "watermark": true
+ }
+}' http://localhost:8000/generate_stream
+```
+
+Sample output:
+```bash
+data: {"token": {"id": 663359, "text": "", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 300560, "text": "\n", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 725120, "text": "Artificial Intelligence ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 734609, "text": "(AI) is ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 362235, "text": "a branch of computer ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 380983, "text": "science that attempts to ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 249979, "text": "simulate the way that ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 972663, "text": "the human brain ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 793301, "text": "works. It is a ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 501380, "text": "branch of computer ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 673232, "text": "", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 2, "text": "
+
+
+By following these steps, you will be able to serve your models using the web UI with IPEX-LLM as the backend. You can open your browser and chat with a model now.
+
+### Launch TGI Style API server
+
+When you have started the controller and the worker, you can start TGI Style API server as follows:
+
+```bash
+python3 -m ipex_llm.serving.fastchat.tgi_api_server --host localhost --port 8000
+```
+You can use `curl` for observing the output of the api
+
+#### Using /generate API
+
+This is to send a sentence as inputs in the request, and is expected to receive a response containing model-generated answer.
+
+```bash
+curl -X POST -H "Content-Type: application/json" -d '{
+ "inputs": "What is AI?",
+ "parameters": {
+ "best_of": 1,
+ "decoder_input_details": true,
+ "details": true,
+ "do_sample": true,
+ "frequency_penalty": 0.1,
+ "grammar": {
+ "type": "json",
+ "value": "string"
+ },
+ "max_new_tokens": 32,
+ "repetition_penalty": 1.03,
+ "return_full_text": false,
+ "seed": 0.1,
+ "stop": [
+ "photographer"
+ ],
+ "temperature": 0.5,
+ "top_k": 10,
+ "top_n_tokens": 5,
+ "top_p": 0.95,
+ "truncate": true,
+ "typical_p": 0.95,
+ "watermark": true
+ }
+}' http://localhost:8000/generate
+```
+
+Sample output:
+```bash
+{
+ "details": {
+ "best_of_sequences": [
+ {
+ "index": 0,
+ "message": {
+ "role": "assistant",
+ "content": "\nArtificial Intelligence (AI) is a branch of computer science that attempts to simulate the way that the human brain works. It is a branch of computer "
+ },
+ "finish_reason": "length",
+ "generated_text": "\nArtificial Intelligence (AI) is a branch of computer science that attempts to simulate the way that the human brain works. It is a branch of computer ",
+ "generated_tokens": 31
+ }
+ ]
+ },
+ "generated_text": "\nArtificial Intelligence (AI) is a branch of computer science that attempts to simulate the way that the human brain works. It is a branch of computer ",
+ "usage": {
+ "prompt_tokens": 4,
+ "total_tokens": 35,
+ "completion_tokens": 31
+ }
+}
+```
+
+#### Using /generate_stream API
+
+This is to send a sentence as inputs in the request, and a long connection will be opened to continuously receive multiple responses containing model-generated answer.
+
+```bash
+curl -X POST -H "Content-Type: application/json" -d '{
+ "inputs": "What is AI?",
+ "parameters": {
+ "best_of": 1,
+ "decoder_input_details": true,
+ "details": true,
+ "do_sample": true,
+ "frequency_penalty": 0.1,
+ "grammar": {
+ "type": "json",
+ "value": "string"
+ },
+ "max_new_tokens": 32,
+ "repetition_penalty": 1.03,
+ "return_full_text": false,
+ "seed": 0.1,
+ "stop": [
+ "photographer"
+ ],
+ "temperature": 0.5,
+ "top_k": 10,
+ "top_n_tokens": 5,
+ "top_p": 0.95,
+ "truncate": true,
+ "typical_p": 0.95,
+ "watermark": true
+ }
+}' http://localhost:8000/generate_stream
+```
+
+Sample output:
+```bash
+data: {"token": {"id": 663359, "text": "", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 300560, "text": "\n", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 725120, "text": "Artificial Intelligence ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 734609, "text": "(AI) is ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 362235, "text": "a branch of computer ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 380983, "text": "science that attempts to ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 249979, "text": "simulate the way that ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 972663, "text": "the human brain ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 793301, "text": "works. It is a ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 501380, "text": "branch of computer ", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 673232, "text": "", "logprob": 0.0, "special": false}, "generated_text": null, "details": null, "special_ret": null}
+
+data: {"token": {"id": 2, "text": " +
+* Install drivers
+
+ ```bash
+ sudo apt-get update
+ sudo apt-get -y install \
+ gawk \
+ dkms \
+ linux-headers-$(uname -r) \
+ libc6-dev
+ sudo apt install intel-i915-dkms intel-fw-gpu
+ sudo apt-get install -y gawk libc6-dev udev\
+ intel-opencl-icd intel-level-zero-gpu level-zero \
+ intel-media-va-driver-non-free libmfx1 libmfxgen1 libvpl2 \
+ libegl-mesa0 libegl1-mesa libegl1-mesa-dev libgbm1 libgl1-mesa-dev libgl1-mesa-dri \
+ libglapi-mesa libgles2-mesa-dev libglx-mesa0 libigdgmm12 libxatracker2 mesa-va-drivers \
+ mesa-vdpau-drivers mesa-vulkan-drivers va-driver-all vainfo
+
+ sudo reboot
+ ```
+
+
+
+* Install drivers
+
+ ```bash
+ sudo apt-get update
+ sudo apt-get -y install \
+ gawk \
+ dkms \
+ linux-headers-$(uname -r) \
+ libc6-dev
+ sudo apt install intel-i915-dkms intel-fw-gpu
+ sudo apt-get install -y gawk libc6-dev udev\
+ intel-opencl-icd intel-level-zero-gpu level-zero \
+ intel-media-va-driver-non-free libmfx1 libmfxgen1 libvpl2 \
+ libegl-mesa0 libegl1-mesa libegl1-mesa-dev libgbm1 libgl1-mesa-dev libgl1-mesa-dri \
+ libglapi-mesa libgles2-mesa-dev libglx-mesa0 libigdgmm12 libxatracker2 mesa-va-drivers \
+ mesa-vdpau-drivers mesa-vulkan-drivers va-driver-all vainfo
+
+ sudo reboot
+ ```
+
+  +
+
+
+  +
+
+* Configure permissions
+ ```bash
+ sudo gpasswd -a ${USER} render
+ newgrp render
+
+ # Verify the device is working with i915 driver
+ sudo apt-get install -y hwinfo
+ hwinfo --display
+ ```
+
+#### For Linux kernel 6.5
+
+* Install wget, gpg-agent
+ ```bash
+ sudo apt-get install -y gpg-agent wget
+ wget -qO - https://repositories.intel.com/gpu/intel-graphics.key | \
+ sudo gpg --dearmor --output /usr/share/keyrings/intel-graphics.gpg
+ echo "deb [arch=amd64,i386 signed-by=/usr/share/keyrings/intel-graphics.gpg] https://repositories.intel.com/gpu/ubuntu jammy client" | \
+ sudo tee /etc/apt/sources.list.d/intel-gpu-jammy.list
+ ```
+
+
+
+* Install drivers
+
+ ```bash
+ sudo apt-get update
+ sudo apt-get -y install \
+ gawk \
+ dkms \
+ linux-headers-$(uname -r) \
+ libc6-dev
+
+ sudo apt-get install -y gawk libc6-dev udev\
+ intel-opencl-icd intel-level-zero-gpu level-zero \
+ intel-media-va-driver-non-free libmfx1 libmfxgen1 libvpl2 \
+ libegl-mesa0 libegl1-mesa libegl1-mesa-dev libgbm1 libgl1-mesa-dev libgl1-mesa-dri \
+ libglapi-mesa libgles2-mesa-dev libglx-mesa0 libigdgmm12 libxatracker2 mesa-va-drivers \
+ mesa-vdpau-drivers mesa-vulkan-drivers va-driver-all vainfo
+
+ sudo apt install -y intel-i915-dkms intel-fw-gpu
+
+ sudo reboot
+ ```
+
+
+
+
+#### (Optional) Update Level Zero on Intel Core™ Ultra iGPU
+For Intel Core™ Ultra integrated GPU, please make sure level_zero version >= 1.3.28717. The level_zero version can be checked with `sycl-ls`, and verison will be tagged behind `[ext_oneapi_level_zero:gpu]`.
+
+Here are the sample output of `sycl-ls`:
+```
+[opencl:acc:0] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device OpenCL 1.2 [2023.16.12.0.12_195853.xmain-hotfix]
+[opencl:cpu:1] Intel(R) OpenCL, Intel(R) Core(TM) Ultra 5 125H OpenCL 3.0 (Build 0) [2023.16.12.0.12_195853.xmain-hotfix]
+[opencl:gpu:2] Intel(R) OpenCL Graphics, Intel(R) Arc(TM) Graphics OpenCL 3.0 NEO [24.09.28717.12]
+[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) Graphics 1.3 [1.3.28717]
+```
+
+If you have level_zero version < 1.3.28717, you could update as follows:
+```bash
+wget https://github.com/intel/intel-graphics-compiler/releases/download/igc-1.0.16238.4/intel-igc-core_1.0.16238.4_amd64.deb
+wget https://github.com/intel/intel-graphics-compiler/releases/download/igc-1.0.16238.4/intel-igc-opencl_1.0.16238.4_amd64.deb
+wget https://github.com/intel/compute-runtime/releases/download/24.09.28717.12/intel-level-zero-gpu-dbgsym_1.3.28717.12_amd64.ddeb
+wget https://github.com/intel/compute-runtime/releases/download/24.09.28717.12/intel-level-zero-gpu_1.3.28717.12_amd64.deb
+wget https://github.com/intel/compute-runtime/releases/download/24.09.28717.12/intel-opencl-icd-dbgsym_24.09.28717.12_amd64.ddeb
+wget https://github.com/intel/compute-runtime/releases/download/24.09.28717.12/intel-opencl-icd_24.09.28717.12_amd64.deb
+wget https://github.com/intel/compute-runtime/releases/download/24.09.28717.12/libigdgmm12_22.3.17_amd64.deb
+sudo dpkg -i *.deb
+```
+
+### Install oneAPI
+ ```
+ wget -O- https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB | gpg --dearmor | sudo tee /usr/share/keyrings/oneapi-archive-keyring.gpg > /dev/null
+
+ echo "deb [signed-by=/usr/share/keyrings/oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main" | sudo tee /etc/apt/sources.list.d/oneAPI.list
+
+ sudo apt update
+
+ sudo apt install intel-oneapi-common-vars=2024.0.0-49406 \
+ intel-oneapi-common-oneapi-vars=2024.0.0-49406 \
+ intel-oneapi-diagnostics-utility=2024.0.0-49093 \
+ intel-oneapi-compiler-dpcpp-cpp=2024.0.2-49895 \
+ intel-oneapi-dpcpp-ct=2024.0.0-49381 \
+ intel-oneapi-mkl=2024.0.0-49656 \
+ intel-oneapi-mkl-devel=2024.0.0-49656 \
+ intel-oneapi-mpi=2021.11.0-49493 \
+ intel-oneapi-mpi-devel=2021.11.0-49493 \
+ intel-oneapi-dal=2024.0.1-25 \
+ intel-oneapi-dal-devel=2024.0.1-25 \
+ intel-oneapi-ippcp=2021.9.1-5 \
+ intel-oneapi-ippcp-devel=2021.9.1-5 \
+ intel-oneapi-ipp=2021.10.1-13 \
+ intel-oneapi-ipp-devel=2021.10.1-13 \
+ intel-oneapi-tlt=2024.0.0-352 \
+ intel-oneapi-ccl=2021.11.2-5 \
+ intel-oneapi-ccl-devel=2021.11.2-5 \
+ intel-oneapi-dnnl-devel=2024.0.0-49521 \
+ intel-oneapi-dnnl=2024.0.0-49521 \
+ intel-oneapi-tcm-1.0=1.0.0-435
+ ```
+
+
+
+* Configure permissions
+ ```bash
+ sudo gpasswd -a ${USER} render
+ newgrp render
+
+ # Verify the device is working with i915 driver
+ sudo apt-get install -y hwinfo
+ hwinfo --display
+ ```
+
+#### For Linux kernel 6.5
+
+* Install wget, gpg-agent
+ ```bash
+ sudo apt-get install -y gpg-agent wget
+ wget -qO - https://repositories.intel.com/gpu/intel-graphics.key | \
+ sudo gpg --dearmor --output /usr/share/keyrings/intel-graphics.gpg
+ echo "deb [arch=amd64,i386 signed-by=/usr/share/keyrings/intel-graphics.gpg] https://repositories.intel.com/gpu/ubuntu jammy client" | \
+ sudo tee /etc/apt/sources.list.d/intel-gpu-jammy.list
+ ```
+
+
+
+* Install drivers
+
+ ```bash
+ sudo apt-get update
+ sudo apt-get -y install \
+ gawk \
+ dkms \
+ linux-headers-$(uname -r) \
+ libc6-dev
+
+ sudo apt-get install -y gawk libc6-dev udev\
+ intel-opencl-icd intel-level-zero-gpu level-zero \
+ intel-media-va-driver-non-free libmfx1 libmfxgen1 libvpl2 \
+ libegl-mesa0 libegl1-mesa libegl1-mesa-dev libgbm1 libgl1-mesa-dev libgl1-mesa-dri \
+ libglapi-mesa libgles2-mesa-dev libglx-mesa0 libigdgmm12 libxatracker2 mesa-va-drivers \
+ mesa-vdpau-drivers mesa-vulkan-drivers va-driver-all vainfo
+
+ sudo apt install -y intel-i915-dkms intel-fw-gpu
+
+ sudo reboot
+ ```
+
+
+
+
+#### (Optional) Update Level Zero on Intel Core™ Ultra iGPU
+For Intel Core™ Ultra integrated GPU, please make sure level_zero version >= 1.3.28717. The level_zero version can be checked with `sycl-ls`, and verison will be tagged behind `[ext_oneapi_level_zero:gpu]`.
+
+Here are the sample output of `sycl-ls`:
+```
+[opencl:acc:0] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device OpenCL 1.2 [2023.16.12.0.12_195853.xmain-hotfix]
+[opencl:cpu:1] Intel(R) OpenCL, Intel(R) Core(TM) Ultra 5 125H OpenCL 3.0 (Build 0) [2023.16.12.0.12_195853.xmain-hotfix]
+[opencl:gpu:2] Intel(R) OpenCL Graphics, Intel(R) Arc(TM) Graphics OpenCL 3.0 NEO [24.09.28717.12]
+[ext_oneapi_level_zero:gpu:0] Intel(R) Level-Zero, Intel(R) Arc(TM) Graphics 1.3 [1.3.28717]
+```
+
+If you have level_zero version < 1.3.28717, you could update as follows:
+```bash
+wget https://github.com/intel/intel-graphics-compiler/releases/download/igc-1.0.16238.4/intel-igc-core_1.0.16238.4_amd64.deb
+wget https://github.com/intel/intel-graphics-compiler/releases/download/igc-1.0.16238.4/intel-igc-opencl_1.0.16238.4_amd64.deb
+wget https://github.com/intel/compute-runtime/releases/download/24.09.28717.12/intel-level-zero-gpu-dbgsym_1.3.28717.12_amd64.ddeb
+wget https://github.com/intel/compute-runtime/releases/download/24.09.28717.12/intel-level-zero-gpu_1.3.28717.12_amd64.deb
+wget https://github.com/intel/compute-runtime/releases/download/24.09.28717.12/intel-opencl-icd-dbgsym_24.09.28717.12_amd64.ddeb
+wget https://github.com/intel/compute-runtime/releases/download/24.09.28717.12/intel-opencl-icd_24.09.28717.12_amd64.deb
+wget https://github.com/intel/compute-runtime/releases/download/24.09.28717.12/libigdgmm12_22.3.17_amd64.deb
+sudo dpkg -i *.deb
+```
+
+### Install oneAPI
+ ```
+ wget -O- https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB | gpg --dearmor | sudo tee /usr/share/keyrings/oneapi-archive-keyring.gpg > /dev/null
+
+ echo "deb [signed-by=/usr/share/keyrings/oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main" | sudo tee /etc/apt/sources.list.d/oneAPI.list
+
+ sudo apt update
+
+ sudo apt install intel-oneapi-common-vars=2024.0.0-49406 \
+ intel-oneapi-common-oneapi-vars=2024.0.0-49406 \
+ intel-oneapi-diagnostics-utility=2024.0.0-49093 \
+ intel-oneapi-compiler-dpcpp-cpp=2024.0.2-49895 \
+ intel-oneapi-dpcpp-ct=2024.0.0-49381 \
+ intel-oneapi-mkl=2024.0.0-49656 \
+ intel-oneapi-mkl-devel=2024.0.0-49656 \
+ intel-oneapi-mpi=2021.11.0-49493 \
+ intel-oneapi-mpi-devel=2021.11.0-49493 \
+ intel-oneapi-dal=2024.0.1-25 \
+ intel-oneapi-dal-devel=2024.0.1-25 \
+ intel-oneapi-ippcp=2021.9.1-5 \
+ intel-oneapi-ippcp-devel=2021.9.1-5 \
+ intel-oneapi-ipp=2021.10.1-13 \
+ intel-oneapi-ipp-devel=2021.10.1-13 \
+ intel-oneapi-tlt=2024.0.0-352 \
+ intel-oneapi-ccl=2021.11.2-5 \
+ intel-oneapi-ccl-devel=2021.11.2-5 \
+ intel-oneapi-dnnl-devel=2024.0.0-49521 \
+ intel-oneapi-dnnl=2024.0.0-49521 \
+ intel-oneapi-tcm-1.0=1.0.0-435
+ ```
+ 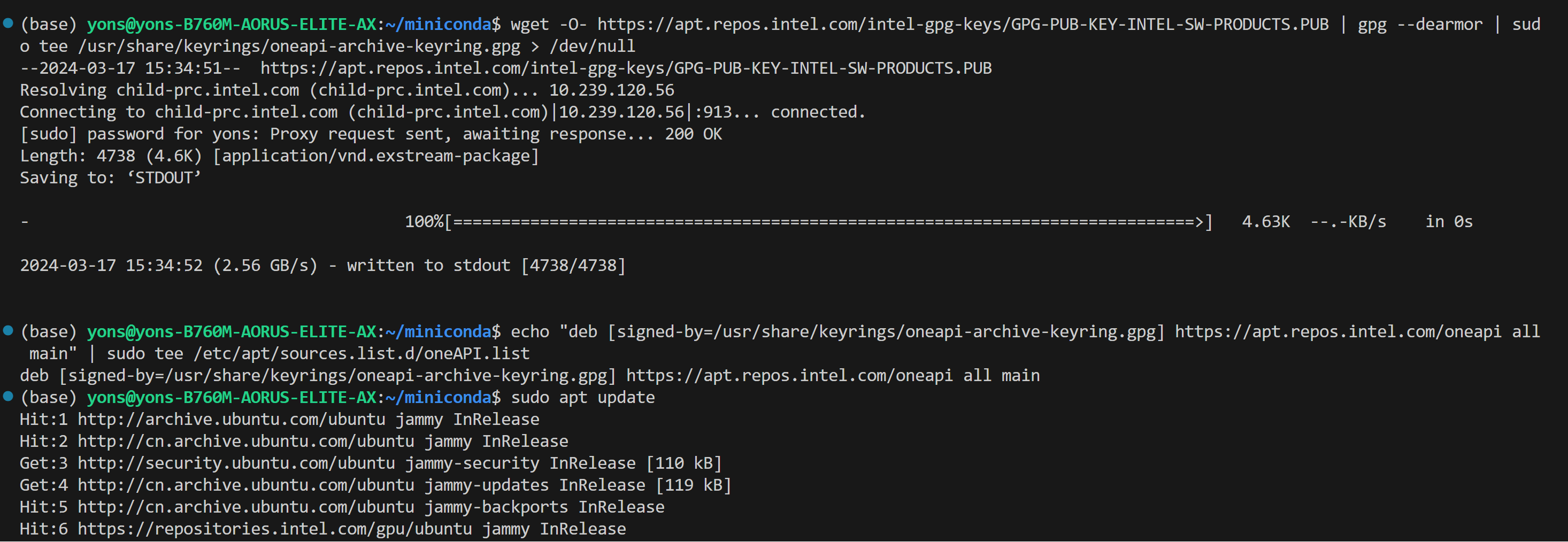 +
+
+
+  +
+### Setup Python Environment
+
+Download and install the Miniforge as follows if you don't have conda installed on your machine:
+ ```bash
+ wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-Linux-x86_64.sh
+ bash Miniforge3-Linux-x86_64.sh
+ source ~/.bashrc
+ ```
+
+You can use `conda --version` to verify you conda installation.
+
+After installation, create a new python environment `llm`:
+```cmd
+conda create -n llm python=3.11
+```
+Activate the newly created environment `llm`:
+```cmd
+conda activate llm
+```
+
+
+## Install `ipex-llm`
+
+With the `llm` environment active, use `pip` to install `ipex-llm` for GPU.
+Choose either US or CN website for `extra-index-url`:
+
+```eval_rst
+.. tabs::
+ .. tab:: US
+
+ .. code-block:: cmd
+
+ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+
+ .. tab:: CN
+
+ .. code-block:: cmd
+
+ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/
+```
+
+```eval_rst
+.. note::
+
+ If you encounter network issues while installing IPEX, refer to `this guide
+
+### Setup Python Environment
+
+Download and install the Miniforge as follows if you don't have conda installed on your machine:
+ ```bash
+ wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-Linux-x86_64.sh
+ bash Miniforge3-Linux-x86_64.sh
+ source ~/.bashrc
+ ```
+
+You can use `conda --version` to verify you conda installation.
+
+After installation, create a new python environment `llm`:
+```cmd
+conda create -n llm python=3.11
+```
+Activate the newly created environment `llm`:
+```cmd
+conda activate llm
+```
+
+
+## Install `ipex-llm`
+
+With the `llm` environment active, use `pip` to install `ipex-llm` for GPU.
+Choose either US or CN website for `extra-index-url`:
+
+```eval_rst
+.. tabs::
+ .. tab:: US
+
+ .. code-block:: cmd
+
+ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+
+ .. tab:: CN
+
+ .. code-block:: cmd
+
+ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/
+```
+
+```eval_rst
+.. note::
+
+ If you encounter network issues while installing IPEX, refer to `this guide  +
+
+
+
+
+
+### Setup Python Environment
+
+Visit [Miniforge installation page](https://conda-forge.org/download/), download the **Miniforge installer for Windows**, and follow the instructions to complete the installation.
+
+
+
+
+
+
+
+
+### Setup Python Environment
+
+Visit [Miniforge installation page](https://conda-forge.org/download/), download the **Miniforge installer for Windows**, and follow the instructions to complete the installation.
+
+ +
+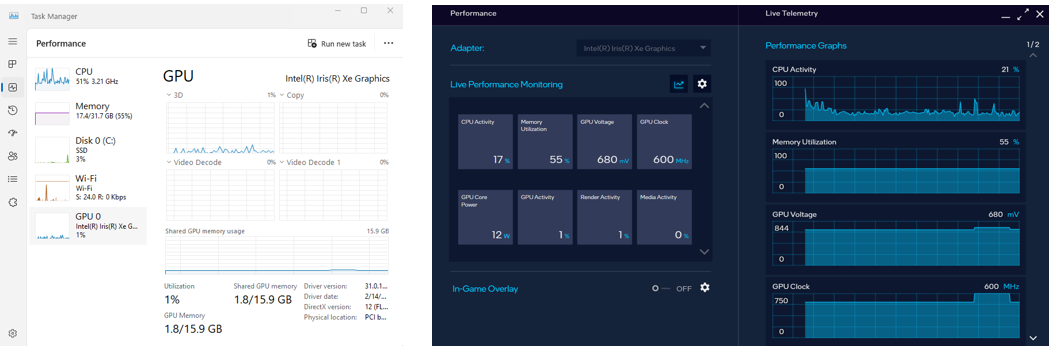 +
+## A Quick Example
+
+Now let's play with a real LLM. We'll be using the [Qwen-1.8B-Chat](https://huggingface.co/Qwen/Qwen-1_8B-Chat) model, a 1.8 billion parameter LLM for this demonstration. Follow the steps below to setup and run the model, and observe how it responds to a prompt "What is AI?".
+
+* Step 1: Follow [Runtime Configurations Section](#step-1-runtime-configurations) above to prepare your runtime environment.
+* Step 2: Install additional package required for Qwen-1.8B-Chat to conduct:
+ ```cmd
+ pip install tiktoken transformers_stream_generator einops
+ ```
+* Step 3: Create code file. IPEX-LLM supports loading model from Hugging Face or ModelScope. Please choose according to your requirements.
+ ```eval_rst
+ .. tabs::
+ .. tab:: Hugging Face
+ Create a new file named ``demo.py`` and insert the code snippet below to run `Qwen-1.8B-Chat
+
+## A Quick Example
+
+Now let's play with a real LLM. We'll be using the [Qwen-1.8B-Chat](https://huggingface.co/Qwen/Qwen-1_8B-Chat) model, a 1.8 billion parameter LLM for this demonstration. Follow the steps below to setup and run the model, and observe how it responds to a prompt "What is AI?".
+
+* Step 1: Follow [Runtime Configurations Section](#step-1-runtime-configurations) above to prepare your runtime environment.
+* Step 2: Install additional package required for Qwen-1.8B-Chat to conduct:
+ ```cmd
+ pip install tiktoken transformers_stream_generator einops
+ ```
+* Step 3: Create code file. IPEX-LLM supports loading model from Hugging Face or ModelScope. Please choose according to your requirements.
+ ```eval_rst
+ .. tabs::
+ .. tab:: Hugging Face
+ Create a new file named ``demo.py`` and insert the code snippet below to run `Qwen-1.8B-Chat  +
+### 2. Run Llama3 using Ollama
+
+#### 2.1 Install IPEX-LLM for Ollama and Initialize
+
+Visit [Run Ollama with IPEX-LLM on Intel GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html), and follow the instructions in section [Install IPEX-LLM for llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#install-ipex-llm-for-llama-cpp) to install the IPEX-LLM with Ollama binary, then follow the instructions in section [Initialize Ollama](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html#initialize-ollama) to initialize.
+
+**After above steps, you should have created a conda environment, named `llm-cpp` for instance and have ollama binary file in your current directory.**
+
+**Now you can use this executable file by standard Ollama usage.**
+
+#### 2.2 Run Llama3 on Intel GPU using Ollama
+
+[ollama/ollama](https://github.com/ollama/ollama) has alreadly added [Llama3](https://ollama.com/library/llama3) into its library, so it's really easy to run Llama3 using ollama now.
+
+##### 2.2.1 Run Ollama Serve
+
+Launch the Ollama service:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ export ZES_ENABLE_SYSMAN=1
+ export OLLAMA_NUM_GPU=999
+ source /opt/intel/oneapi/setvars.sh
+ export SYCL_CACHE_PERSISTENT=1
+
+ ./ollama serve
+
+ .. tab:: Windows
+
+ Please run the following command in Miniforge Prompt.
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ set ZES_ENABLE_SYSMAN=1
+ set OLLAMA_NUM_GPU=999
+ set SYCL_CACHE_PERSISTENT=1
+
+ ollama serve
+
+```
+
+```eval_rst
+.. tip::
+
+ If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS (Kernel 6.2), it is recommended to additionaly set the following environment variable for optimal performance before executing `ollama serve`:
+
+ .. code-block:: bash
+
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+
+```
+
+```eval_rst
+.. note::
+
+ To allow the service to accept connections from all IP addresses, use `OLLAMA_HOST=0.0.0.0 ./ollama serve` instead of just `./ollama serve`.
+```
+
+##### 2.2.2 Using Ollama Run Llama3
+
+Keep the Ollama service on and open another terminal and run llama3 with `ollama run`:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ ./ollama run llama3:8b-instruct-q4_K_M
+
+ .. tab:: Windows
+
+ Please run the following command in Miniforge Prompt.
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ ollama run llama3:8b-instruct-q4_K_M
+```
+
+```eval_rst
+.. note::
+
+ Here we just take `llama3:8b-instruct-q4_K_M` for example, you can replace it with any other Llama3 model you want.
+```
+
+Below is a sample output on Intel Arc GPU :
+
+
+### 2. Run Llama3 using Ollama
+
+#### 2.1 Install IPEX-LLM for Ollama and Initialize
+
+Visit [Run Ollama with IPEX-LLM on Intel GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html), and follow the instructions in section [Install IPEX-LLM for llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html#install-ipex-llm-for-llama-cpp) to install the IPEX-LLM with Ollama binary, then follow the instructions in section [Initialize Ollama](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/ollama_quickstart.html#initialize-ollama) to initialize.
+
+**After above steps, you should have created a conda environment, named `llm-cpp` for instance and have ollama binary file in your current directory.**
+
+**Now you can use this executable file by standard Ollama usage.**
+
+#### 2.2 Run Llama3 on Intel GPU using Ollama
+
+[ollama/ollama](https://github.com/ollama/ollama) has alreadly added [Llama3](https://ollama.com/library/llama3) into its library, so it's really easy to run Llama3 using ollama now.
+
+##### 2.2.1 Run Ollama Serve
+
+Launch the Ollama service:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ export ZES_ENABLE_SYSMAN=1
+ export OLLAMA_NUM_GPU=999
+ source /opt/intel/oneapi/setvars.sh
+ export SYCL_CACHE_PERSISTENT=1
+
+ ./ollama serve
+
+ .. tab:: Windows
+
+ Please run the following command in Miniforge Prompt.
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ set ZES_ENABLE_SYSMAN=1
+ set OLLAMA_NUM_GPU=999
+ set SYCL_CACHE_PERSISTENT=1
+
+ ollama serve
+
+```
+
+```eval_rst
+.. tip::
+
+ If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS (Kernel 6.2), it is recommended to additionaly set the following environment variable for optimal performance before executing `ollama serve`:
+
+ .. code-block:: bash
+
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+
+```
+
+```eval_rst
+.. note::
+
+ To allow the service to accept connections from all IP addresses, use `OLLAMA_HOST=0.0.0.0 ./ollama serve` instead of just `./ollama serve`.
+```
+
+##### 2.2.2 Using Ollama Run Llama3
+
+Keep the Ollama service on and open another terminal and run llama3 with `ollama run`:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ ./ollama run llama3:8b-instruct-q4_K_M
+
+ .. tab:: Windows
+
+ Please run the following command in Miniforge Prompt.
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ ollama run llama3:8b-instruct-q4_K_M
+```
+
+```eval_rst
+.. note::
+
+ Here we just take `llama3:8b-instruct-q4_K_M` for example, you can replace it with any other Llama3 model you want.
+```
+
+Below is a sample output on Intel Arc GPU :
+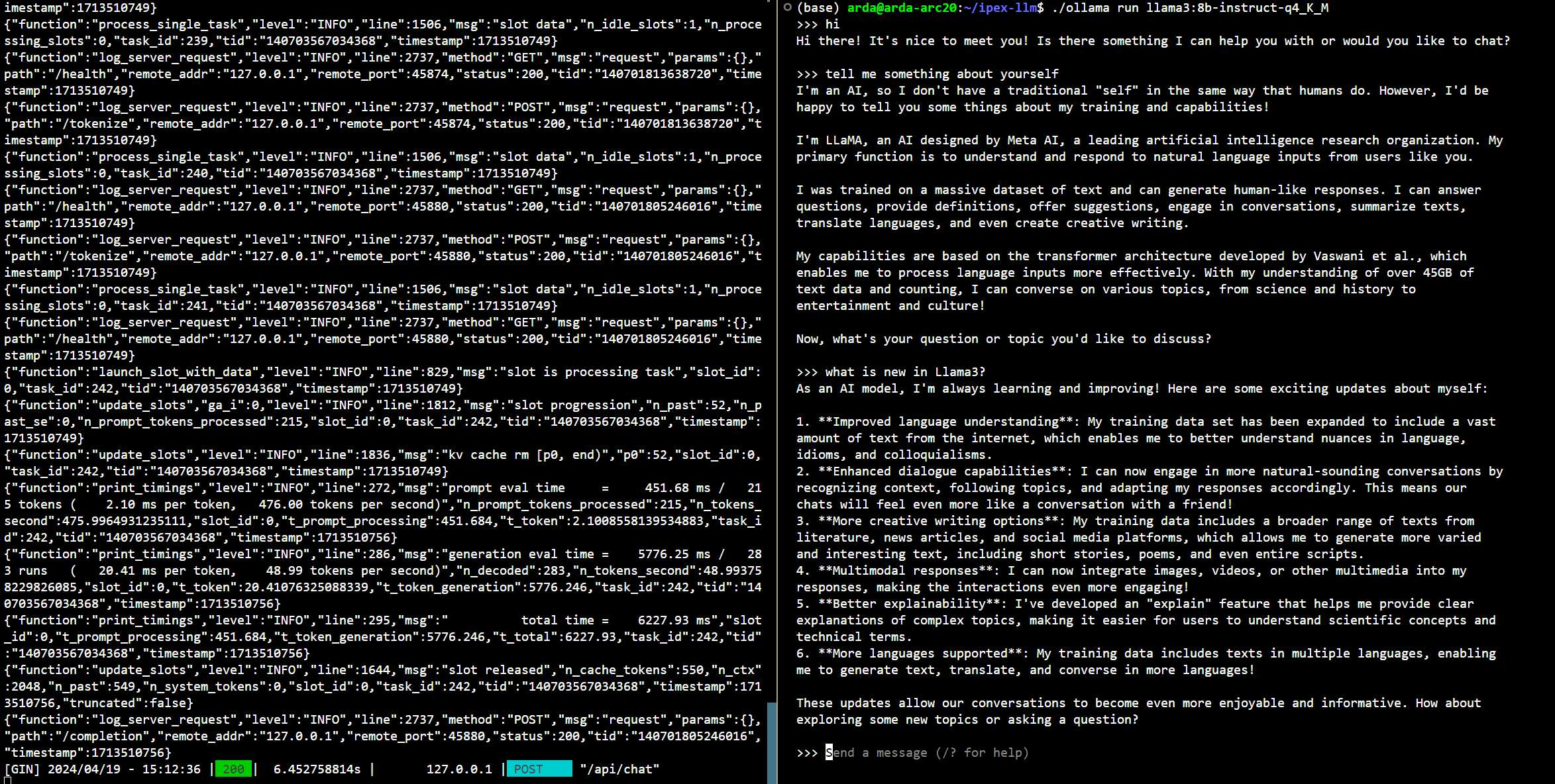 diff --git a/docs/mddocs/Quickstart/llama_cpp_quickstart.md b/docs/mddocs/Quickstart/llama_cpp_quickstart.md
new file mode 100644
index 00000000..1373a781
--- /dev/null
+++ b/docs/mddocs/Quickstart/llama_cpp_quickstart.md
@@ -0,0 +1,333 @@
+# Run llama.cpp with IPEX-LLM on Intel GPU
+
+[ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp) prvoides fast LLM inference in in pure C++ across a variety of hardware; you can now use the C++ interface of [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) as an accelerated backend for `llama.cpp` running on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
+
+See the demo of running LLaMA2-7B on Intel Arc GPU below.
+
+
+
+```eval_rst
+.. note::
+
+ `ipex-llm[cpp]==2.5.0b20240527` is consistent with `c780e75
diff --git a/docs/mddocs/Quickstart/llama_cpp_quickstart.md b/docs/mddocs/Quickstart/llama_cpp_quickstart.md
new file mode 100644
index 00000000..1373a781
--- /dev/null
+++ b/docs/mddocs/Quickstart/llama_cpp_quickstart.md
@@ -0,0 +1,333 @@
+# Run llama.cpp with IPEX-LLM on Intel GPU
+
+[ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp) prvoides fast LLM inference in in pure C++ across a variety of hardware; you can now use the C++ interface of [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) as an accelerated backend for `llama.cpp` running on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
+
+See the demo of running LLaMA2-7B on Intel Arc GPU below.
+
+
+
+```eval_rst
+.. note::
+
+ `ipex-llm[cpp]==2.5.0b20240527` is consistent with `c780e75  +
+
+
+### 4 Pull Model
+Keep the Ollama service on and open another terminal and run `./ollama pull
+
+
+
+### 4 Pull Model
+Keep the Ollama service on and open another terminal and run `./ollama pull  +
+
+
+### 5 Using Ollama
+
+#### Using Curl
+
+Using `curl` is the easiest way to verify the API service and model. Execute the following commands in a terminal. **Replace the
+
diff --git a/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md b/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md
new file mode 100644
index 00000000..1eb2ec05
--- /dev/null
+++ b/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md
@@ -0,0 +1,208 @@
+# Run Open WebUI with Intel GPU
+
+[Open WebUI](https://github.com/open-webui/open-webui) is a user friendly GUI for running LLM locally; by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily run LLM in [Open WebUI](https://github.com/open-webui/open-webui) on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
+
+*See the demo of running Mistral:7B on Intel Arc A770 below.*
+
+
+
+## Quickstart
+
+This quickstart guide walks you through setting up and using [Open WebUI](https://github.com/open-webui/open-webui) with Ollama (using the C++ interface of [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) as an accelerated backend).
+
+
+### 1 Run Ollama with Intel GPU
+
+Follow the instructions on the [Run Ollama with Intel GPU](ollama_quickstart.html) to install and run "Ollama Serve". Please ensure that the Ollama server continues to run while you're using the Open WebUI.
+
+### 2 Install the Open-Webui
+
+#### Install Node.js & npm
+
+```eval_rst
+.. note::
+
+ Package version requirements for running Open WebUI: Node.js (>= 20.10) or Bun (>= 1.0.21), Python (>= 3.11)
+```
+
+Please install Node.js & npm as below:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ Run below commands to install Node.js & npm. Once the installation is complete, verify the installation by running ```node -v``` and ```npm -v``` to check the versions of Node.js and npm, respectively.
+
+ .. code-block:: bash
+
+ sudo apt update
+ sudo apt install nodejs
+ sudo apt install npm
+
+ .. tab:: Windows
+
+ You may download Node.js installation package from https://nodejs.org/dist/v20.12.2/node-v20.12.2-x64.msi, which will install both Node.js & npm on your system.
+
+ Once the installation is complete, verify the installation by running ```node -v``` and ```npm -v``` to check the versions of Node.js and npm, respectively.
+```
+
+
+#### Download the Open-Webui
+
+Use `git` to clone the [open-webui repo](https://github.com/open-webui/open-webui.git), or download the open-webui source code zip from [this link](https://github.com/open-webui/open-webui/archive/refs/heads/main.zip) and unzip it to a directory, e.g. `~/open-webui`.
+
+
+#### Install Dependencies
+
+You may run below commands to install Open WebUI dependencies:
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ cd ~/open-webui/
+ cp -RPp .env.example .env # Copy required .env file
+
+ # Build frontend
+ npm i
+ npm run build
+
+ # Install Dependencies
+ cd ./backend
+ pip install -r requirements.txt -U
+
+ .. tab:: Windows
+
+ .. code-block:: bash
+
+ cd ~\open-webui\
+ copy .env.example .env
+
+ # Build frontend
+ npm install
+ npm run build
+
+ # Install Dependencies
+ cd .\backend
+ pip install -r requirements.txt -U
+```
+
+### 3. Start the Open-WebUI
+
+#### Start the service
+
+Run below commands to start the service:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ bash start.sh
+
+ .. note:
+
+ If you have difficulty accessing the huggingface repositories, you may use a mirror, e.g. add `export HF_ENDPOINT=https://hf-mirror.com` before running `bash start.sh`.
+
+
+ .. tab:: Windows
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ start_windows.bat
+
+ .. note:
+
+ If you have difficulty accessing the huggingface repositories, you may use a mirror, e.g. add `set HF_ENDPOINT=https://hf-mirror.com` before running `start_windows.bat`.
+```
+
+
+#### Access the WebUI
+Upon successful launch, URLs to access the WebUI will be displayed in the terminal. Open the provided local URL in your browser to interact with the WebUI, e.g. http://localhost:8080/.
+
+
+
+### 4. Using the Open-Webui
+
+```eval_rst
+.. note::
+
+ For detailed information about how to use Open WebUI, visit the README of `open-webui official repository
+
+
+
+
+
+
+
+
+### 5 Using Ollama
+
+#### Using Curl
+
+Using `curl` is the easiest way to verify the API service and model. Execute the following commands in a terminal. **Replace the
+
diff --git a/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md b/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md
new file mode 100644
index 00000000..1eb2ec05
--- /dev/null
+++ b/docs/mddocs/Quickstart/open_webui_with_ollama_quickstart.md
@@ -0,0 +1,208 @@
+# Run Open WebUI with Intel GPU
+
+[Open WebUI](https://github.com/open-webui/open-webui) is a user friendly GUI for running LLM locally; by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily run LLM in [Open WebUI](https://github.com/open-webui/open-webui) on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
+
+*See the demo of running Mistral:7B on Intel Arc A770 below.*
+
+
+
+## Quickstart
+
+This quickstart guide walks you through setting up and using [Open WebUI](https://github.com/open-webui/open-webui) with Ollama (using the C++ interface of [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) as an accelerated backend).
+
+
+### 1 Run Ollama with Intel GPU
+
+Follow the instructions on the [Run Ollama with Intel GPU](ollama_quickstart.html) to install and run "Ollama Serve". Please ensure that the Ollama server continues to run while you're using the Open WebUI.
+
+### 2 Install the Open-Webui
+
+#### Install Node.js & npm
+
+```eval_rst
+.. note::
+
+ Package version requirements for running Open WebUI: Node.js (>= 20.10) or Bun (>= 1.0.21), Python (>= 3.11)
+```
+
+Please install Node.js & npm as below:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ Run below commands to install Node.js & npm. Once the installation is complete, verify the installation by running ```node -v``` and ```npm -v``` to check the versions of Node.js and npm, respectively.
+
+ .. code-block:: bash
+
+ sudo apt update
+ sudo apt install nodejs
+ sudo apt install npm
+
+ .. tab:: Windows
+
+ You may download Node.js installation package from https://nodejs.org/dist/v20.12.2/node-v20.12.2-x64.msi, which will install both Node.js & npm on your system.
+
+ Once the installation is complete, verify the installation by running ```node -v``` and ```npm -v``` to check the versions of Node.js and npm, respectively.
+```
+
+
+#### Download the Open-Webui
+
+Use `git` to clone the [open-webui repo](https://github.com/open-webui/open-webui.git), or download the open-webui source code zip from [this link](https://github.com/open-webui/open-webui/archive/refs/heads/main.zip) and unzip it to a directory, e.g. `~/open-webui`.
+
+
+#### Install Dependencies
+
+You may run below commands to install Open WebUI dependencies:
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ cd ~/open-webui/
+ cp -RPp .env.example .env # Copy required .env file
+
+ # Build frontend
+ npm i
+ npm run build
+
+ # Install Dependencies
+ cd ./backend
+ pip install -r requirements.txt -U
+
+ .. tab:: Windows
+
+ .. code-block:: bash
+
+ cd ~\open-webui\
+ copy .env.example .env
+
+ # Build frontend
+ npm install
+ npm run build
+
+ # Install Dependencies
+ cd .\backend
+ pip install -r requirements.txt -U
+```
+
+### 3. Start the Open-WebUI
+
+#### Start the service
+
+Run below commands to start the service:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ bash start.sh
+
+ .. note:
+
+ If you have difficulty accessing the huggingface repositories, you may use a mirror, e.g. add `export HF_ENDPOINT=https://hf-mirror.com` before running `bash start.sh`.
+
+
+ .. tab:: Windows
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ start_windows.bat
+
+ .. note:
+
+ If you have difficulty accessing the huggingface repositories, you may use a mirror, e.g. add `set HF_ENDPOINT=https://hf-mirror.com` before running `start_windows.bat`.
+```
+
+
+#### Access the WebUI
+Upon successful launch, URLs to access the WebUI will be displayed in the terminal. Open the provided local URL in your browser to interact with the WebUI, e.g. http://localhost:8080/.
+
+
+
+### 4. Using the Open-Webui
+
+```eval_rst
+.. note::
+
+ For detailed information about how to use Open WebUI, visit the README of `open-webui official repository
+
+
+
+
+ 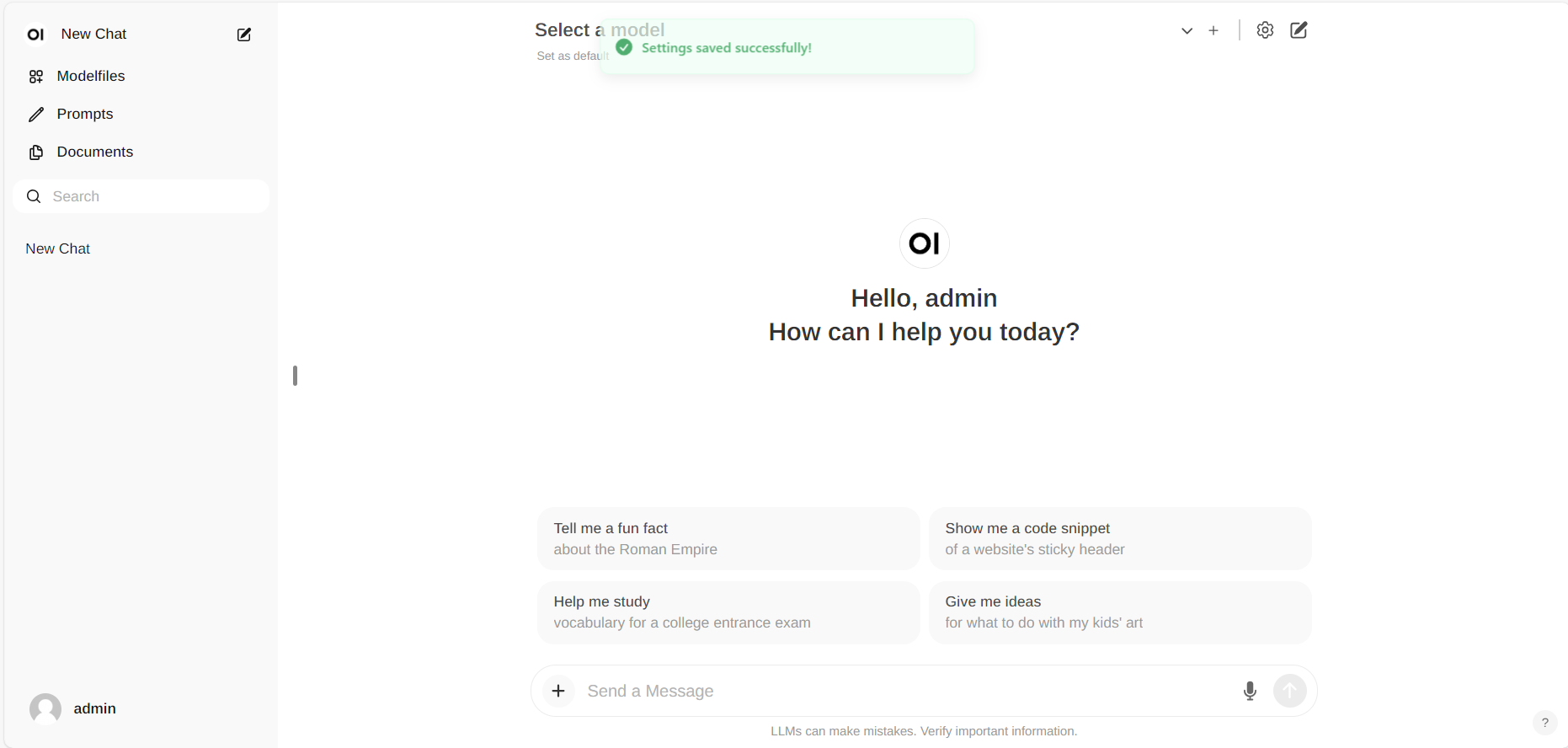 +
+
+#### Configure `Ollama` service URL
+
+Access the Ollama settings through **Settings -> Connections** in the menu. By default, the **Ollama Base URL** is preset to https://localhost:11434, as illustrated in the snapshot below. To verify the status of the Ollama service connection, click the **Refresh button** located next to the textbox. If the WebUI is unable to establish a connection with the Ollama server, you will see an error message stating, `WebUI could not connect to Ollama`.
+
+
+
+
+
+
+#### Configure `Ollama` service URL
+
+Access the Ollama settings through **Settings -> Connections** in the menu. By default, the **Ollama Base URL** is preset to https://localhost:11434, as illustrated in the snapshot below. To verify the status of the Ollama service connection, click the **Refresh button** located next to the textbox. If the WebUI is unable to establish a connection with the Ollama server, you will see an error message stating, `WebUI could not connect to Ollama`.
+
+
+
+  +
+
+If the connection is successful, you will see a message stating `Service Connection Verified`, as illustrated below.
+
+
+
+
+
+If the connection is successful, you will see a message stating `Service Connection Verified`, as illustrated below.
+
+
+  +
+
+```eval_rst
+.. note::
+
+ If you want to use an Ollama server hosted at a different URL, simply update the **Ollama Base URL** to the new URL and press the **Refresh** button to re-confirm the connection to Ollama.
+```
+
+#### Pull Model
+
+Go to **Settings -> Models** in the menu, choose a model under **Pull a model from Ollama.com** using the drop-down menu, and then hit the **Download** button on the right. Ollama will automatically download the selected model for you.
+
+
+
+
+
+```eval_rst
+.. note::
+
+ If you want to use an Ollama server hosted at a different URL, simply update the **Ollama Base URL** to the new URL and press the **Refresh** button to re-confirm the connection to Ollama.
+```
+
+#### Pull Model
+
+Go to **Settings -> Models** in the menu, choose a model under **Pull a model from Ollama.com** using the drop-down menu, and then hit the **Download** button on the right. Ollama will automatically download the selected model for you.
+
+
+ 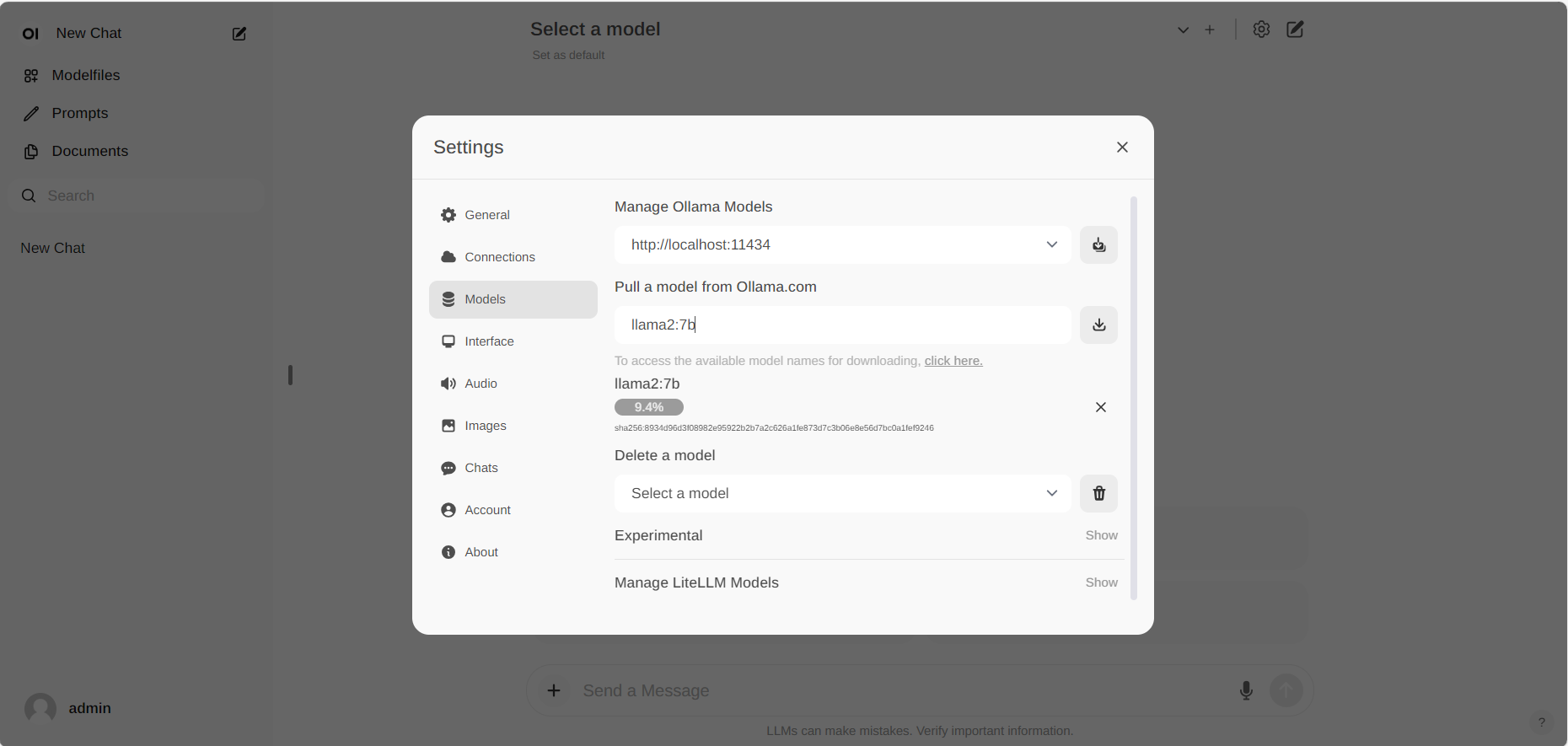 +
+
+
+#### Chat with the Model
+
+Start new conversations with **New chat** in the left-side menu.
+
+On the right-side, choose a downloaded model from the **Select a model** drop-down menu at the top, input your questions into the **Send a Message** textbox at the bottom, and click the button on the right to get responses.
+
+
+
+
+
+
+#### Chat with the Model
+
+Start new conversations with **New chat** in the left-side menu.
+
+On the right-side, choose a downloaded model from the **Select a model** drop-down menu at the top, input your questions into the **Send a Message** textbox at the bottom, and click the button on the right to get responses.
+
+
+ 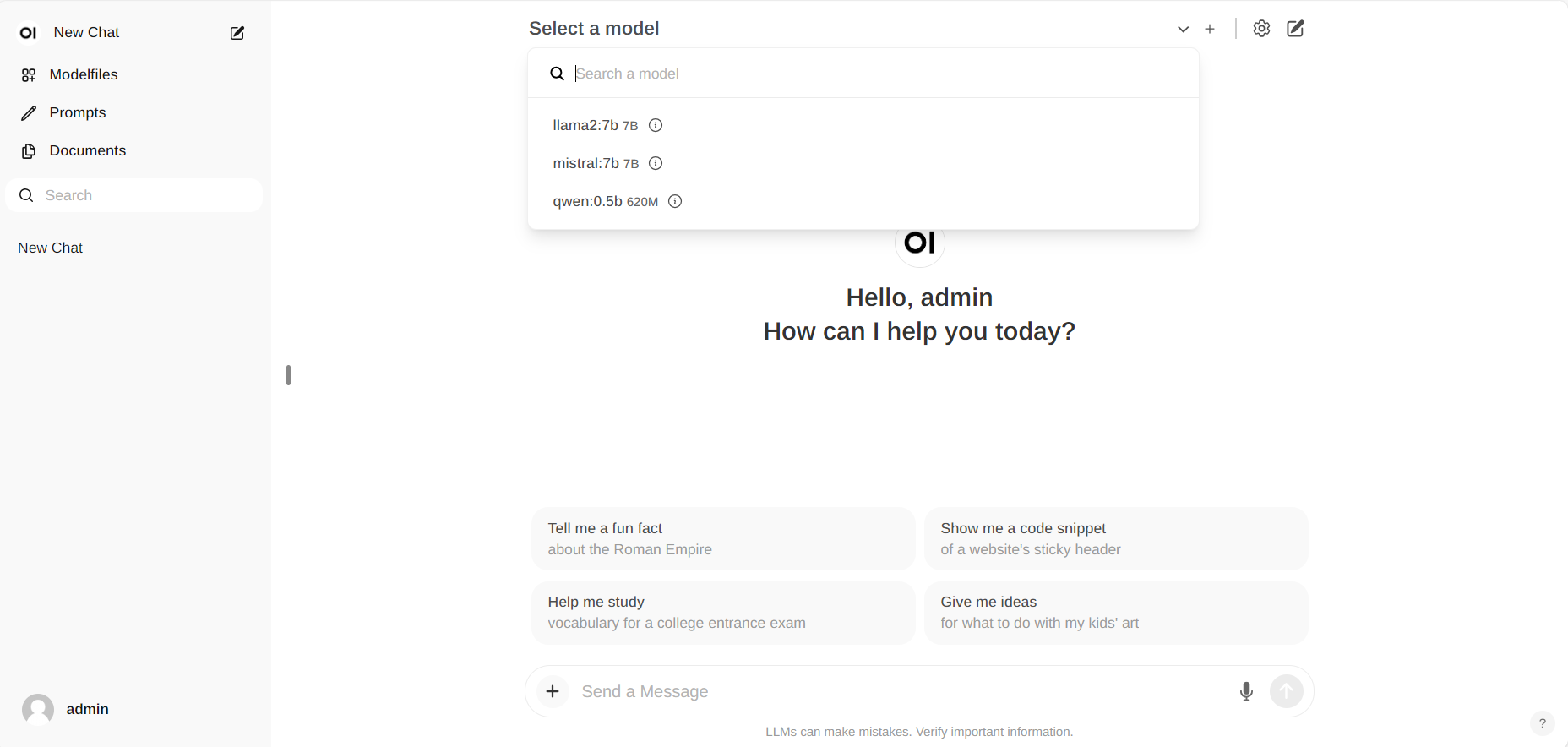 +
+
+
+
+
+
+
+ +
+
+#### Exit Open-Webui
+
+To shut down the open-webui server, use **Ctrl+C** in the terminal where the open-webui server is runing, then close your browser tab.
+
+
+### 5. Troubleshooting
+
+##### Error `No module named 'torch._C`
+
+When you encounter the error ``ModuleNotFoundError: No module named 'torch._C'`` after executing ```bash start.sh```, you can resolve it by reinstalling PyTorch. First, use ```pip uninstall torch``` to remove the existing PyTorch installation, and then reinstall it along with its dependencies by running ```pip install torch torchvision torchaudio```.
diff --git a/docs/mddocs/Quickstart/privateGPT_quickstart.md b/docs/mddocs/Quickstart/privateGPT_quickstart.md
new file mode 100644
index 00000000..0d605068
--- /dev/null
+++ b/docs/mddocs/Quickstart/privateGPT_quickstart.md
@@ -0,0 +1,129 @@
+# Run PrivateGPT with IPEX-LLM on Intel GPU
+
+[PrivateGPT](https://github.com/zylon-ai/private-gpt) is a production-ready AI project that allows users to chat over documents, etc.; by integrating it with [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily leverage local LLMs running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max).
+
+*See the demo of privateGPT running Mistral:7B on Intel Arc A770 below.*
+
+
+
+
+## Quickstart
+
+
+### 1. Install and Start `Ollama` Service on Intel GPU
+
+Follow the steps in [Run Ollama on Intel GPU Guide](./ollama_quickstart.md) to install and run Ollama on Intel GPU. Ensure that `ollama serve` is running correctly and can be accessed through a local URL (e.g., `https://127.0.0.1:11434`) or a remote URL (e.g., `http://your_ip:11434`).
+
+We recommend pulling the desired model before proceeding with PrivateGPT. For instance, to pull the Mistral:7B model, you can use the following command:
+
+```bash
+ollama pull mistral:7b
+```
+
+### 2. Install PrivateGPT
+
+#### Download PrivateGPT
+
+You can either clone the repository or download the source zip from [github](https://github.com/zylon-ai/private-gpt/archive/refs/heads/main.zip):
+```bash
+git clone https://github.com/zylon-ai/private-gpt
+```
+
+#### Install Dependencies
+
+Execute the following commands in a terminal to install the dependencies of PrivateGPT:
+
+```cmd
+cd private-gpt
+pip install poetry
+pip install ffmpy==0.3.1
+poetry install --extras "ui llms-ollama embeddings-ollama vector-stores-qdrant"
+```
+For more details, refer to the [PrivateGPT installation Guide](https://docs.privategpt.dev/installation/getting-started/main-concepts).
+
+
+### 3. Start PrivateGPT
+
+#### Configure PrivateGPT
+
+To configure PrivateGPT to use Ollama for running local LLMs, you should edit the `private-gpt/settings-ollama.yaml` file. Modify the `ollama` section by setting the `llm_model` and `embedding_model` you wish to use, and updating the `api_base` and `embedding_api_base` to direct to your Ollama URL.
+
+Below is an example of how `settings-ollama.yaml` should look.
+
+
+
+
+
+```eval_rst
+
+.. note::
+
+ `settings-ollama.yaml` is loaded when the Ollama profile is specified in the PGPT_PROFILES environment variable. This can override configurations from the default `settings.yaml`.
+
+```
+
+For more information on configuring PrivateGPT, please visit the [PrivateGPT Main Concepts](https://docs.privategpt.dev/installation/getting-started/main-concepts) page.
+
+
+#### Start the service
+Please ensure that the Ollama server continues to run in a terminal while you're using the PrivateGPT.
+
+Run below commands to start the service in another terminal:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ PGPT_PROFILES=ollama make run
+
+ .. note:
+
+ Setting ``PGPT_PROFILES=ollama`` will load the configuration from ``settings.yaml`` and ``settings-ollama.yaml``.
+
+ .. tab:: Windows
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ set PGPT_PROFILES=ollama
+ make run
+
+ .. note:
+
+ Setting ``PGPT_PROFILES=ollama`` will load the configuration from ``settings.yaml`` and ``settings-ollama.yaml``.
+```
+
+Upon successful deployment, you will see logs in the terminal similar to the following:
+
+
+
+Open a browser (if it doesn't open automatically) and navigate to the URL displayed in the terminal. If it shows http://0.0.0.0:8001, you can access it locally via `http://127.0.0.1:8001` or remotely via `http://your_ip:8001`.
+
+
+### 4. Using PrivateGPT
+
+#### Chat with the Model
+
+To chat with the LLM, select the "LLM Chat" option located in the upper left corner of the page. Type your messages at the bottom of the page and click the "Submit" button to receive responses from the model.
+
+
+
+
+
+
+#### Chat over Documents (RAG)
+
+To interact with documents, select the "Query Files" option in the upper left corner of the page. Click the "Upload File(s)" button to upload documents. After the documents have been vectorized, you can type your messages at the bottom of the page and click the "Submit" button to receive responses from the model based on the uploaded content.
+
+
+
+
+
+#### Exit Open-Webui
+
+To shut down the open-webui server, use **Ctrl+C** in the terminal where the open-webui server is runing, then close your browser tab.
+
+
+### 5. Troubleshooting
+
+##### Error `No module named 'torch._C`
+
+When you encounter the error ``ModuleNotFoundError: No module named 'torch._C'`` after executing ```bash start.sh```, you can resolve it by reinstalling PyTorch. First, use ```pip uninstall torch``` to remove the existing PyTorch installation, and then reinstall it along with its dependencies by running ```pip install torch torchvision torchaudio```.
diff --git a/docs/mddocs/Quickstart/privateGPT_quickstart.md b/docs/mddocs/Quickstart/privateGPT_quickstart.md
new file mode 100644
index 00000000..0d605068
--- /dev/null
+++ b/docs/mddocs/Quickstart/privateGPT_quickstart.md
@@ -0,0 +1,129 @@
+# Run PrivateGPT with IPEX-LLM on Intel GPU
+
+[PrivateGPT](https://github.com/zylon-ai/private-gpt) is a production-ready AI project that allows users to chat over documents, etc.; by integrating it with [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily leverage local LLMs running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max).
+
+*See the demo of privateGPT running Mistral:7B on Intel Arc A770 below.*
+
+
+
+
+## Quickstart
+
+
+### 1. Install and Start `Ollama` Service on Intel GPU
+
+Follow the steps in [Run Ollama on Intel GPU Guide](./ollama_quickstart.md) to install and run Ollama on Intel GPU. Ensure that `ollama serve` is running correctly and can be accessed through a local URL (e.g., `https://127.0.0.1:11434`) or a remote URL (e.g., `http://your_ip:11434`).
+
+We recommend pulling the desired model before proceeding with PrivateGPT. For instance, to pull the Mistral:7B model, you can use the following command:
+
+```bash
+ollama pull mistral:7b
+```
+
+### 2. Install PrivateGPT
+
+#### Download PrivateGPT
+
+You can either clone the repository or download the source zip from [github](https://github.com/zylon-ai/private-gpt/archive/refs/heads/main.zip):
+```bash
+git clone https://github.com/zylon-ai/private-gpt
+```
+
+#### Install Dependencies
+
+Execute the following commands in a terminal to install the dependencies of PrivateGPT:
+
+```cmd
+cd private-gpt
+pip install poetry
+pip install ffmpy==0.3.1
+poetry install --extras "ui llms-ollama embeddings-ollama vector-stores-qdrant"
+```
+For more details, refer to the [PrivateGPT installation Guide](https://docs.privategpt.dev/installation/getting-started/main-concepts).
+
+
+### 3. Start PrivateGPT
+
+#### Configure PrivateGPT
+
+To configure PrivateGPT to use Ollama for running local LLMs, you should edit the `private-gpt/settings-ollama.yaml` file. Modify the `ollama` section by setting the `llm_model` and `embedding_model` you wish to use, and updating the `api_base` and `embedding_api_base` to direct to your Ollama URL.
+
+Below is an example of how `settings-ollama.yaml` should look.
+
+
+
+
+
+```eval_rst
+
+.. note::
+
+ `settings-ollama.yaml` is loaded when the Ollama profile is specified in the PGPT_PROFILES environment variable. This can override configurations from the default `settings.yaml`.
+
+```
+
+For more information on configuring PrivateGPT, please visit the [PrivateGPT Main Concepts](https://docs.privategpt.dev/installation/getting-started/main-concepts) page.
+
+
+#### Start the service
+Please ensure that the Ollama server continues to run in a terminal while you're using the PrivateGPT.
+
+Run below commands to start the service in another terminal:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ PGPT_PROFILES=ollama make run
+
+ .. note:
+
+ Setting ``PGPT_PROFILES=ollama`` will load the configuration from ``settings.yaml`` and ``settings-ollama.yaml``.
+
+ .. tab:: Windows
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ set PGPT_PROFILES=ollama
+ make run
+
+ .. note:
+
+ Setting ``PGPT_PROFILES=ollama`` will load the configuration from ``settings.yaml`` and ``settings-ollama.yaml``.
+```
+
+Upon successful deployment, you will see logs in the terminal similar to the following:
+
+
+
+Open a browser (if it doesn't open automatically) and navigate to the URL displayed in the terminal. If it shows http://0.0.0.0:8001, you can access it locally via `http://127.0.0.1:8001` or remotely via `http://your_ip:8001`.
+
+
+### 4. Using PrivateGPT
+
+#### Chat with the Model
+
+To chat with the LLM, select the "LLM Chat" option located in the upper left corner of the page. Type your messages at the bottom of the page and click the "Submit" button to receive responses from the model.
+
+
+
+
+
+
+#### Chat over Documents (RAG)
+
+To interact with documents, select the "Query Files" option in the upper left corner of the page. Click the "Upload File(s)" button to upload documents. After the documents have been vectorized, you can type your messages at the bottom of the page and click the "Submit" button to receive responses from the model based on the uploaded content.
+
+
+  +
diff --git a/docs/mddocs/Quickstart/vLLM_quickstart.md b/docs/mddocs/Quickstart/vLLM_quickstart.md
new file mode 100644
index 00000000..71e34834
--- /dev/null
+++ b/docs/mddocs/Quickstart/vLLM_quickstart.md
@@ -0,0 +1,276 @@
+# Serving using IPEX-LLM and vLLM on Intel GPU
+
+vLLM is a fast and easy-to-use library for LLM inference and serving. You can find the detailed information at their [homepage](https://github.com/vllm-project/vllm).
+
+IPEX-LLM can be integrated into vLLM so that user can use `IPEX-LLM` to boost the performance of vLLM engine on Intel **GPUs** *(e.g., local PC with descrete GPU such as Arc, Flex and Max)*.
+
+Currently, IPEX-LLM integrated vLLM only supports the following models:
+
+- Qwen series models
+- Llama series models
+- ChatGLM series models
+- Baichuan series models
+
+
+## Quick Start
+
+This quickstart guide walks you through installing and running `vLLM` with `ipex-llm`.
+
+### 1. Install IPEX-LLM for vLLM
+
+IPEX-LLM's support for `vLLM` now is available for only Linux system.
+
+Visit [Install IPEX-LLM on Linux with Intel GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html) and follow the instructions in section [Install Prerequisites](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html#install-prerequisites) to isntall prerequisites that are needed for running code on Intel GPUs.
+
+Then,follow instructions in section [Install ipex-llm](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html#install-ipex-llm) to install `ipex-llm[xpu]` and setup the recommended runtime configurations.
+
+**After the installation, you should have created a conda environment, named `ipex-vllm` for instance, for running `vLLM` commands with IPEX-LLM.**
+
+### 2. Install vLLM
+
+Currently, we maintain a specific branch of vLLM, which only works on Intel GPUs.
+
+Activate the `ipex-vllm` conda environment and install vLLM by execcuting the commands below.
+
+```bash
+conda activate ipex-vllm
+source /opt/intel/oneapi/setvars.sh
+git clone -b sycl_xpu https://github.com/analytics-zoo/vllm.git
+cd vllm
+pip install -r requirements-xpu.txt
+pip install --no-deps xformers
+VLLM_BUILD_XPU_OPS=1 pip install --no-build-isolation -v -e .
+pip install outlines==0.0.34 --no-deps
+pip install interegular cloudpickle diskcache joblib lark nest-asyncio numba scipy
+# For Qwen model support
+pip install transformers_stream_generator einops tiktoken
+```
+
+**Now you are all set to use vLLM with IPEX-LLM**
+
+## 3. Offline inference/Service
+
+### Offline inference
+
+To run offline inference using vLLM for a quick impression, use the following example.
+
+```eval_rst
+.. note::
+
+ Please modify the MODEL_PATH in offline_inference.py to use your chosen model.
+ You can try modify load_in_low_bit to different values in **[sym_int4, fp6, fp8, fp8_e4m3, fp16]** to use different quantization dtype.
+```
+
+```bash
+#!/bin/bash
+wget https://raw.githubusercontent.com/intel-analytics/ipex-llm/main/python/llm/example/GPU/vLLM-Serving/offline_inference.py
+python offline_inference.py
+```
+
+For instructions on how to change the `load_in_low_bit` value in `offline_inference.py`, check the following example:
+
+```bash
+llm = LLM(model="YOUR_MODEL",
+ device="xpu",
+ dtype="float16",
+ enforce_eager=True,
+ # Simply change here for the desired load_in_low_bit value
+ load_in_low_bit="sym_int4",
+ tensor_parallel_size=1,
+ trust_remote_code=True)
+```
+
+The result of executing `Baichuan2-7B-Chat` model with `sym_int4` low-bit format is shown as follows:
+
+```
+Prompt: 'Hello, my name is', Generated text: ' [Your Name] and I am a [Your Job Title] at [Your'
+Prompt: 'The president of the United States is', Generated text: ' the head of state and head of government in the United States. The president leads'
+Prompt: 'The capital of France is', Generated text: ' Paris.\nThe capital of France is Paris.'
+Prompt: 'The future of AI is', Generated text: " bright, but it's not without challenges. As AI continues to evolve,"
+```
+
+### Service
+
+```eval_rst
+.. note::
+
+ Because of using JIT compilation for kernels. We recommend to send a few requests for warmup before using the service for the best performance.
+```
+
+To fully utilize the continuous batching feature of the `vLLM`, you can send requests to the service using `curl` or other similar methods. The requests sent to the engine will be batched at token level. Queries will be executed in the same `forward` step of the LLM and be removed when they are finished instead of waiting for all sequences to be finished.
+
+
+For vLLM, you can start the service using the following command:
+
+```bash
+#!/bin/bash
+model="YOUR_MODEL_PATH"
+served_model_name="YOUR_MODEL_NAME"
+
+ # You may need to adjust the value of
+ # --max-model-len, --max-num-batched-tokens, --max-num-seqs
+ # to acquire the best performance
+
+ # Change value --load-in-low-bit to [fp6, fp8, fp8_e4m3, fp16] to use different low-bit formats
+python -m ipex_llm.vllm.xpu.entrypoints.openai.api_server \
+ --served-model-name $served_model_name \
+ --port 8000 \
+ --model $model \
+ --trust-remote-code \
+ --gpu-memory-utilization 0.75 \
+ --device xpu \
+ --dtype float16 \
+ --enforce-eager \
+ --load-in-low-bit sym_int4 \
+ --max-model-len 4096 \
+ --max-num-batched-tokens 10240 \
+ --max-num-seqs 12 \
+ --tensor-parallel-size 1
+```
+
+You can tune the service using these four arguments:
+
+1. `--gpu-memory-utilization`: The fraction of GPU memory to be used for the model executor, which can range from 0 to 1. For example, a value of 0.5 would imply 50% GPU memory utilization. If unspecified, will use the default value of 0.9.
+2. `--max-model-len`: Model context length. If unspecified, will be automatically derived from the model config.
+3. `--max-num-batched-token`: Maximum number of batched tokens per iteration.
+4. `--max-num-seq`: Maximum number of sequences per iteration. Default: 256
+
+For longer input prompt, we would suggest to use `--max-num-batched-token` to restrict the service. The reason behind this logic is that the `peak GPU memory usage` will appear when generating first token. By using `--max-num-batched-token`, we can restrict the input size when generating first token.
+
+`--max-num-seqs` will restrict the generation for both first token and rest token. It will restrict the maximum batch size to the value set by `--max-num-seqs`.
+
+When out-of-memory error occurs, the most obvious solution is to reduce the `gpu-memory-utilization`. Other ways to resolve this error is to set `--max-num-batched-token` if peak memory occurs when generating first token or using `--max-num-seq` if peak memory occurs when generating rest tokens.
+
+If the service have been booted successfully, the console will display messages similar to the following:
+
+
+
+
+
+
+After the service has been booted successfully, you can send a test request using `curl`. Here, `YOUR_MODEL` should be set equal to `$served_model_name` in your booting script, e.g. `Qwen1.5`.
+
+
+```bash
+curl http://localhost:8000/v1/completions \
+-H "Content-Type: application/json" \
+-d '{
+ "model": "YOUR_MODEL",
+ "prompt": "San Francisco is a",
+ "max_tokens": 128,
+ "temperature": 0
+}' | jq '.choices[0].text'
+```
+
+Below shows an example output using `Qwen1.5-7B-Chat` with low-bit format `sym_int4`:
+
+
+
+
+
+```eval_rst
+.. tip::
+
+ If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS (Kernel 6.2), it is recommended to additionaly set the following environment variable for optimal performance before starting the service:
+
+ .. code-block:: bash
+
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+
+```
+
+## 4. About Tensor parallel
+
+> Note: We recommend to use docker for tensor parallel deployment. Check our serving docker image `intelanalytics/ipex-llm-serving-xpu`.
+
+We have also supported tensor parallel by using multiple Intel GPU cards. To enable tensor parallel, you will need to install `libfabric-dev` in your environment. In ubuntu, you can install it by:
+
+```bash
+sudo apt-get install libfabric-dev
+```
+
+To deploy your model across multiple cards, simplely change the value of `--tensor-parallel-size` to the desired value.
+
+
+For instance, if you have two Arc A770 cards in your environment, then you can set this value to 2. Some OneCCL environment variable settings are also needed, check the following example:
+
+```bash
+#!/bin/bash
+model="YOUR_MODEL_PATH"
+served_model_name="YOUR_MODEL_NAME"
+
+# CCL needed environment variables
+export CCL_WORKER_COUNT=2
+export FI_PROVIDER=shm
+export CCL_ATL_TRANSPORT=ofi
+export CCL_ZE_IPC_EXCHANGE=sockets
+export CCL_ATL_SHM=1
+ # You may need to adjust the value of
+ # --max-model-len, --max-num-batched-tokens, --max-num-seqs
+ # to acquire the best performance
+
+python -m ipex_llm.vllm.xpu.entrypoints.openai.api_server \
+ --served-model-name $served_model_name \
+ --port 8000 \
+ --model $model \
+ --trust-remote-code \
+ --gpu-memory-utilization 0.75 \
+ --device xpu \
+ --dtype float16 \
+ --enforce-eager \
+ --load-in-low-bit sym_int4 \
+ --max-model-len 4096 \
+ --max-num-batched-tokens 10240 \
+ --max-num-seqs 12 \
+ --tensor-parallel-size 2
+```
+
+If the service have booted successfully, you should see the output similar to the following figure:
+
+
+
+
+
+## 5.Performing benchmark
+
+To perform benchmark, you can use the **benchmark_throughput** script that is originally provided by vLLM repo.
+
+```bash
+conda activate ipex-vllm
+
+source /opt/intel/oneapi/setvars.sh
+
+wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
+
+wget https://raw.githubusercontent.com/intel-analytics/ipex-llm/main/docker/llm/serving/xpu/docker/benchmark_vllm_throughput.py -O benchmark_throughput.py
+
+export MODEL="YOUR_MODEL"
+
+# You can change load-in-low-bit from values in [sym_int4, fp6, fp8, fp8_e4m3, fp16]
+
+python3 ./benchmark_throughput.py \
+ --backend vllm \
+ --dataset ./ShareGPT_V3_unfiltered_cleaned_split.json \
+ --model $MODEL \
+ --num-prompts 1000 \
+ --seed 42 \
+ --trust-remote-code \
+ --enforce-eager \
+ --dtype float16 \
+ --device xpu \
+ --load-in-low-bit sym_int4 \
+ --gpu-memory-utilization 0.85
+```
+
+The following figure shows the result of benchmarking `Llama-2-7b-chat-hf` using 50 prompts:
+
+
+
+
diff --git a/docs/mddocs/Quickstart/vLLM_quickstart.md b/docs/mddocs/Quickstart/vLLM_quickstart.md
new file mode 100644
index 00000000..71e34834
--- /dev/null
+++ b/docs/mddocs/Quickstart/vLLM_quickstart.md
@@ -0,0 +1,276 @@
+# Serving using IPEX-LLM and vLLM on Intel GPU
+
+vLLM is a fast and easy-to-use library for LLM inference and serving. You can find the detailed information at their [homepage](https://github.com/vllm-project/vllm).
+
+IPEX-LLM can be integrated into vLLM so that user can use `IPEX-LLM` to boost the performance of vLLM engine on Intel **GPUs** *(e.g., local PC with descrete GPU such as Arc, Flex and Max)*.
+
+Currently, IPEX-LLM integrated vLLM only supports the following models:
+
+- Qwen series models
+- Llama series models
+- ChatGLM series models
+- Baichuan series models
+
+
+## Quick Start
+
+This quickstart guide walks you through installing and running `vLLM` with `ipex-llm`.
+
+### 1. Install IPEX-LLM for vLLM
+
+IPEX-LLM's support for `vLLM` now is available for only Linux system.
+
+Visit [Install IPEX-LLM on Linux with Intel GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html) and follow the instructions in section [Install Prerequisites](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html#install-prerequisites) to isntall prerequisites that are needed for running code on Intel GPUs.
+
+Then,follow instructions in section [Install ipex-llm](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html#install-ipex-llm) to install `ipex-llm[xpu]` and setup the recommended runtime configurations.
+
+**After the installation, you should have created a conda environment, named `ipex-vllm` for instance, for running `vLLM` commands with IPEX-LLM.**
+
+### 2. Install vLLM
+
+Currently, we maintain a specific branch of vLLM, which only works on Intel GPUs.
+
+Activate the `ipex-vllm` conda environment and install vLLM by execcuting the commands below.
+
+```bash
+conda activate ipex-vllm
+source /opt/intel/oneapi/setvars.sh
+git clone -b sycl_xpu https://github.com/analytics-zoo/vllm.git
+cd vllm
+pip install -r requirements-xpu.txt
+pip install --no-deps xformers
+VLLM_BUILD_XPU_OPS=1 pip install --no-build-isolation -v -e .
+pip install outlines==0.0.34 --no-deps
+pip install interegular cloudpickle diskcache joblib lark nest-asyncio numba scipy
+# For Qwen model support
+pip install transformers_stream_generator einops tiktoken
+```
+
+**Now you are all set to use vLLM with IPEX-LLM**
+
+## 3. Offline inference/Service
+
+### Offline inference
+
+To run offline inference using vLLM for a quick impression, use the following example.
+
+```eval_rst
+.. note::
+
+ Please modify the MODEL_PATH in offline_inference.py to use your chosen model.
+ You can try modify load_in_low_bit to different values in **[sym_int4, fp6, fp8, fp8_e4m3, fp16]** to use different quantization dtype.
+```
+
+```bash
+#!/bin/bash
+wget https://raw.githubusercontent.com/intel-analytics/ipex-llm/main/python/llm/example/GPU/vLLM-Serving/offline_inference.py
+python offline_inference.py
+```
+
+For instructions on how to change the `load_in_low_bit` value in `offline_inference.py`, check the following example:
+
+```bash
+llm = LLM(model="YOUR_MODEL",
+ device="xpu",
+ dtype="float16",
+ enforce_eager=True,
+ # Simply change here for the desired load_in_low_bit value
+ load_in_low_bit="sym_int4",
+ tensor_parallel_size=1,
+ trust_remote_code=True)
+```
+
+The result of executing `Baichuan2-7B-Chat` model with `sym_int4` low-bit format is shown as follows:
+
+```
+Prompt: 'Hello, my name is', Generated text: ' [Your Name] and I am a [Your Job Title] at [Your'
+Prompt: 'The president of the United States is', Generated text: ' the head of state and head of government in the United States. The president leads'
+Prompt: 'The capital of France is', Generated text: ' Paris.\nThe capital of France is Paris.'
+Prompt: 'The future of AI is', Generated text: " bright, but it's not without challenges. As AI continues to evolve,"
+```
+
+### Service
+
+```eval_rst
+.. note::
+
+ Because of using JIT compilation for kernels. We recommend to send a few requests for warmup before using the service for the best performance.
+```
+
+To fully utilize the continuous batching feature of the `vLLM`, you can send requests to the service using `curl` or other similar methods. The requests sent to the engine will be batched at token level. Queries will be executed in the same `forward` step of the LLM and be removed when they are finished instead of waiting for all sequences to be finished.
+
+
+For vLLM, you can start the service using the following command:
+
+```bash
+#!/bin/bash
+model="YOUR_MODEL_PATH"
+served_model_name="YOUR_MODEL_NAME"
+
+ # You may need to adjust the value of
+ # --max-model-len, --max-num-batched-tokens, --max-num-seqs
+ # to acquire the best performance
+
+ # Change value --load-in-low-bit to [fp6, fp8, fp8_e4m3, fp16] to use different low-bit formats
+python -m ipex_llm.vllm.xpu.entrypoints.openai.api_server \
+ --served-model-name $served_model_name \
+ --port 8000 \
+ --model $model \
+ --trust-remote-code \
+ --gpu-memory-utilization 0.75 \
+ --device xpu \
+ --dtype float16 \
+ --enforce-eager \
+ --load-in-low-bit sym_int4 \
+ --max-model-len 4096 \
+ --max-num-batched-tokens 10240 \
+ --max-num-seqs 12 \
+ --tensor-parallel-size 1
+```
+
+You can tune the service using these four arguments:
+
+1. `--gpu-memory-utilization`: The fraction of GPU memory to be used for the model executor, which can range from 0 to 1. For example, a value of 0.5 would imply 50% GPU memory utilization. If unspecified, will use the default value of 0.9.
+2. `--max-model-len`: Model context length. If unspecified, will be automatically derived from the model config.
+3. `--max-num-batched-token`: Maximum number of batched tokens per iteration.
+4. `--max-num-seq`: Maximum number of sequences per iteration. Default: 256
+
+For longer input prompt, we would suggest to use `--max-num-batched-token` to restrict the service. The reason behind this logic is that the `peak GPU memory usage` will appear when generating first token. By using `--max-num-batched-token`, we can restrict the input size when generating first token.
+
+`--max-num-seqs` will restrict the generation for both first token and rest token. It will restrict the maximum batch size to the value set by `--max-num-seqs`.
+
+When out-of-memory error occurs, the most obvious solution is to reduce the `gpu-memory-utilization`. Other ways to resolve this error is to set `--max-num-batched-token` if peak memory occurs when generating first token or using `--max-num-seq` if peak memory occurs when generating rest tokens.
+
+If the service have been booted successfully, the console will display messages similar to the following:
+
+
+
+
+
+
+After the service has been booted successfully, you can send a test request using `curl`. Here, `YOUR_MODEL` should be set equal to `$served_model_name` in your booting script, e.g. `Qwen1.5`.
+
+
+```bash
+curl http://localhost:8000/v1/completions \
+-H "Content-Type: application/json" \
+-d '{
+ "model": "YOUR_MODEL",
+ "prompt": "San Francisco is a",
+ "max_tokens": 128,
+ "temperature": 0
+}' | jq '.choices[0].text'
+```
+
+Below shows an example output using `Qwen1.5-7B-Chat` with low-bit format `sym_int4`:
+
+
+
+
+
+```eval_rst
+.. tip::
+
+ If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS (Kernel 6.2), it is recommended to additionaly set the following environment variable for optimal performance before starting the service:
+
+ .. code-block:: bash
+
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+
+```
+
+## 4. About Tensor parallel
+
+> Note: We recommend to use docker for tensor parallel deployment. Check our serving docker image `intelanalytics/ipex-llm-serving-xpu`.
+
+We have also supported tensor parallel by using multiple Intel GPU cards. To enable tensor parallel, you will need to install `libfabric-dev` in your environment. In ubuntu, you can install it by:
+
+```bash
+sudo apt-get install libfabric-dev
+```
+
+To deploy your model across multiple cards, simplely change the value of `--tensor-parallel-size` to the desired value.
+
+
+For instance, if you have two Arc A770 cards in your environment, then you can set this value to 2. Some OneCCL environment variable settings are also needed, check the following example:
+
+```bash
+#!/bin/bash
+model="YOUR_MODEL_PATH"
+served_model_name="YOUR_MODEL_NAME"
+
+# CCL needed environment variables
+export CCL_WORKER_COUNT=2
+export FI_PROVIDER=shm
+export CCL_ATL_TRANSPORT=ofi
+export CCL_ZE_IPC_EXCHANGE=sockets
+export CCL_ATL_SHM=1
+ # You may need to adjust the value of
+ # --max-model-len, --max-num-batched-tokens, --max-num-seqs
+ # to acquire the best performance
+
+python -m ipex_llm.vllm.xpu.entrypoints.openai.api_server \
+ --served-model-name $served_model_name \
+ --port 8000 \
+ --model $model \
+ --trust-remote-code \
+ --gpu-memory-utilization 0.75 \
+ --device xpu \
+ --dtype float16 \
+ --enforce-eager \
+ --load-in-low-bit sym_int4 \
+ --max-model-len 4096 \
+ --max-num-batched-tokens 10240 \
+ --max-num-seqs 12 \
+ --tensor-parallel-size 2
+```
+
+If the service have booted successfully, you should see the output similar to the following figure:
+
+
+
+
+
+## 5.Performing benchmark
+
+To perform benchmark, you can use the **benchmark_throughput** script that is originally provided by vLLM repo.
+
+```bash
+conda activate ipex-vllm
+
+source /opt/intel/oneapi/setvars.sh
+
+wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
+
+wget https://raw.githubusercontent.com/intel-analytics/ipex-llm/main/docker/llm/serving/xpu/docker/benchmark_vllm_throughput.py -O benchmark_throughput.py
+
+export MODEL="YOUR_MODEL"
+
+# You can change load-in-low-bit from values in [sym_int4, fp6, fp8, fp8_e4m3, fp16]
+
+python3 ./benchmark_throughput.py \
+ --backend vllm \
+ --dataset ./ShareGPT_V3_unfiltered_cleaned_split.json \
+ --model $MODEL \
+ --num-prompts 1000 \
+ --seed 42 \
+ --trust-remote-code \
+ --enforce-eager \
+ --dtype float16 \
+ --device xpu \
+ --load-in-low-bit sym_int4 \
+ --gpu-memory-utilization 0.85
+```
+
+The following figure shows the result of benchmarking `Llama-2-7b-chat-hf` using 50 prompts:
+
+
+  +
+
+
+```eval_rst
+.. tip::
+
+ To find the best config that fits your workload, you may need to start the service and use tools like `wrk` or `jmeter` to perform a stress tests.
+```
diff --git a/docs/mddocs/Quickstart/webui_quickstart.md b/docs/mddocs/Quickstart/webui_quickstart.md
new file mode 100644
index 00000000..3aab9589
--- /dev/null
+++ b/docs/mddocs/Quickstart/webui_quickstart.md
@@ -0,0 +1,217 @@
+# Run Text Generation WebUI on Intel GPU
+
+The [oobabooga/text-generation-webui](https://github.com/oobabooga/text-generation-webui) provides a user friendly GUI for anyone to run LLM locally; by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily run LLM in [Text Generation WebUI](https://github.com/intel-analytics/text-generation-webui) on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
+
+See the demo of running LLaMA2-7B on an Intel Core Ultra laptop below.
+
+
+
+## Quickstart
+This quickstart guide walks you through setting up and using the [Text Generation WebUI](https://github.com/intel-analytics/text-generation-webui) with `ipex-llm`.
+
+A preview of the WebUI in action is shown below:
+
+
+
+
+
+
+```eval_rst
+.. tip::
+
+ To find the best config that fits your workload, you may need to start the service and use tools like `wrk` or `jmeter` to perform a stress tests.
+```
diff --git a/docs/mddocs/Quickstart/webui_quickstart.md b/docs/mddocs/Quickstart/webui_quickstart.md
new file mode 100644
index 00000000..3aab9589
--- /dev/null
+++ b/docs/mddocs/Quickstart/webui_quickstart.md
@@ -0,0 +1,217 @@
+# Run Text Generation WebUI on Intel GPU
+
+The [oobabooga/text-generation-webui](https://github.com/oobabooga/text-generation-webui) provides a user friendly GUI for anyone to run LLM locally; by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily run LLM in [Text Generation WebUI](https://github.com/intel-analytics/text-generation-webui) on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
+
+See the demo of running LLaMA2-7B on an Intel Core Ultra laptop below.
+
+
+
+## Quickstart
+This quickstart guide walks you through setting up and using the [Text Generation WebUI](https://github.com/intel-analytics/text-generation-webui) with `ipex-llm`.
+
+A preview of the WebUI in action is shown below:
+
+
+  +
+
+
+### 1 Install IPEX-LLM
+
+To use the WebUI, first ensure that IPEX-LLM is installed. Follow the instructions on the [IPEX-LLM Installation Quickstart for Windows with Intel GPU](install_windows_gpu.html).
+
+**After the installation, you should have created a conda environment, named `llm` for instance, for running `ipex-llm` applications.**
+
+### 2 Install the WebUI
+
+
+#### Download the WebUI
+Download the `text-generation-webui` with IPEX-LLM integrations from [this link](https://github.com/intel-analytics/text-generation-webui/archive/refs/heads/ipex-llm.zip). Unzip the content into a directory, e.g.,`C:\text-generation-webui`.
+
+#### Install Dependencies
+
+Open **Miniforge Prompt** and activate the conda environment you have created in [section 1](#1-install-ipex-llm), e.g., `llm`.
+```
+conda activate llm
+```
+Then, change to the directory of WebUI (e.g.,`C:\text-generation-webui`) and install the necessary dependencies:
+```cmd
+cd C:\text-generation-webui
+pip install -r requirements_cpu_only.txt
+pip install -r extensions/openai/requirements.txt
+```
+
+```eval_rst
+.. note::
+
+ `extensions/openai/requirements.txt` is for API service. If you don't need the API service, you can omit this command.
+```
+
+### 3 Start the WebUI Server
+
+#### Set Environment Variables
+Configure oneAPI variables by running the following command in **Miniforge Prompt**:
+
+```eval_rst
+.. note::
+
+ For more details about runtime configurations, refer to `this guide
+
+
+
+### 1 Install IPEX-LLM
+
+To use the WebUI, first ensure that IPEX-LLM is installed. Follow the instructions on the [IPEX-LLM Installation Quickstart for Windows with Intel GPU](install_windows_gpu.html).
+
+**After the installation, you should have created a conda environment, named `llm` for instance, for running `ipex-llm` applications.**
+
+### 2 Install the WebUI
+
+
+#### Download the WebUI
+Download the `text-generation-webui` with IPEX-LLM integrations from [this link](https://github.com/intel-analytics/text-generation-webui/archive/refs/heads/ipex-llm.zip). Unzip the content into a directory, e.g.,`C:\text-generation-webui`.
+
+#### Install Dependencies
+
+Open **Miniforge Prompt** and activate the conda environment you have created in [section 1](#1-install-ipex-llm), e.g., `llm`.
+```
+conda activate llm
+```
+Then, change to the directory of WebUI (e.g.,`C:\text-generation-webui`) and install the necessary dependencies:
+```cmd
+cd C:\text-generation-webui
+pip install -r requirements_cpu_only.txt
+pip install -r extensions/openai/requirements.txt
+```
+
+```eval_rst
+.. note::
+
+ `extensions/openai/requirements.txt` is for API service. If you don't need the API service, you can omit this command.
+```
+
+### 3 Start the WebUI Server
+
+#### Set Environment Variables
+Configure oneAPI variables by running the following command in **Miniforge Prompt**:
+
+```eval_rst
+.. note::
+
+ For more details about runtime configurations, refer to `this guide 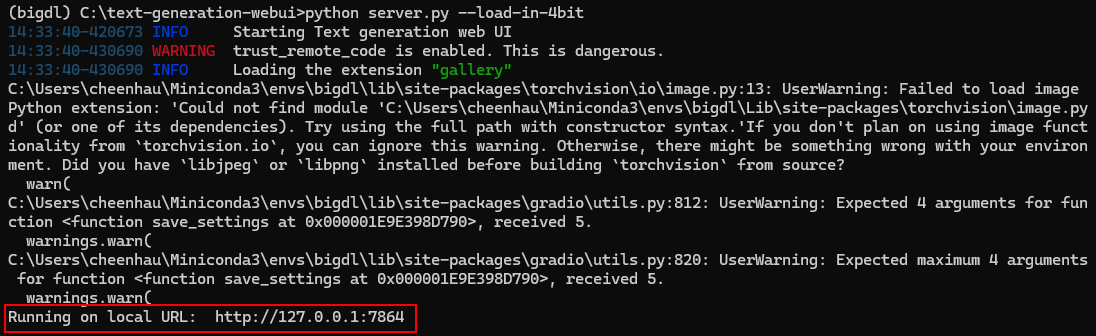 +
+
+### 4. Using the WebUI
+
+#### Model Download
+
+Place Huggingface models in `C:\text-generation-webui\models` by either copying locally or downloading via the WebUI. To download, navigate to the **Model** tab, enter the model's huggingface id (for instance, `microsoft/phi-1_5`) in the **Download model or LoRA** section, and click **Download**, as illustrated below.
+
+
+
+
+
+### 4. Using the WebUI
+
+#### Model Download
+
+Place Huggingface models in `C:\text-generation-webui\models` by either copying locally or downloading via the WebUI. To download, navigate to the **Model** tab, enter the model's huggingface id (for instance, `microsoft/phi-1_5`) in the **Download model or LoRA** section, and click **Download**, as illustrated below.
+
+
+ 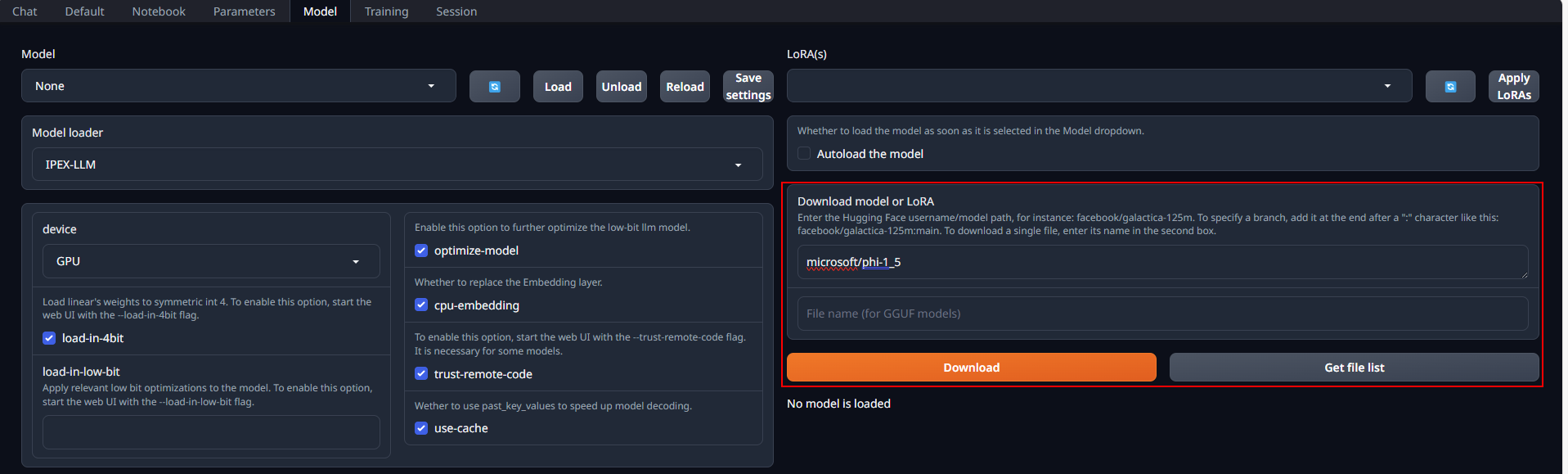 +
+
+After copying or downloading the models, click on the blue **refresh** button to update the **Model** drop-down menu. Then, choose your desired model from the newly updated list.
+
+
+
+
+
+After copying or downloading the models, click on the blue **refresh** button to update the **Model** drop-down menu. Then, choose your desired model from the newly updated list.
+
+
+ 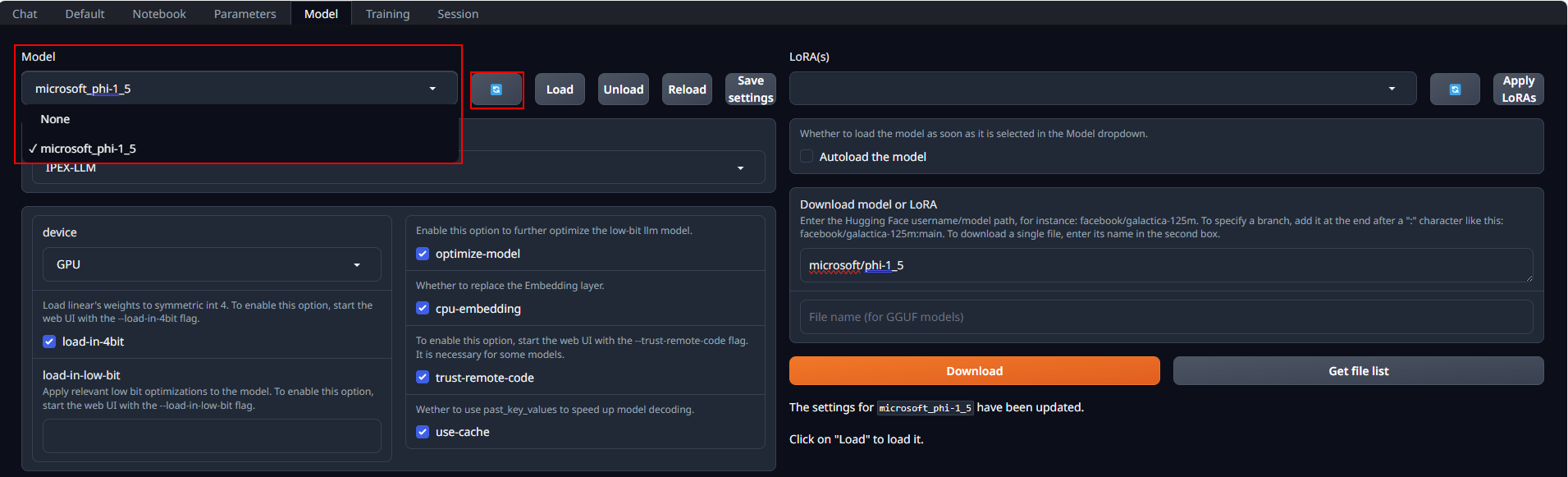 +
+
+#### Load Model
+
+Default settings are recommended for most users. Click **Load** to activate the model. Address any errors by installing missing packages as prompted, and ensure compatibility with your version of the transformers package. Refer to [troubleshooting section](#troubleshooting) for more details.
+
+If everything goes well, you will get a message as shown below.
+
+
+
+
+
+#### Load Model
+
+Default settings are recommended for most users. Click **Load** to activate the model. Address any errors by installing missing packages as prompted, and ensure compatibility with your version of the transformers package. Refer to [troubleshooting section](#troubleshooting) for more details.
+
+If everything goes well, you will get a message as shown below.
+
+
+ 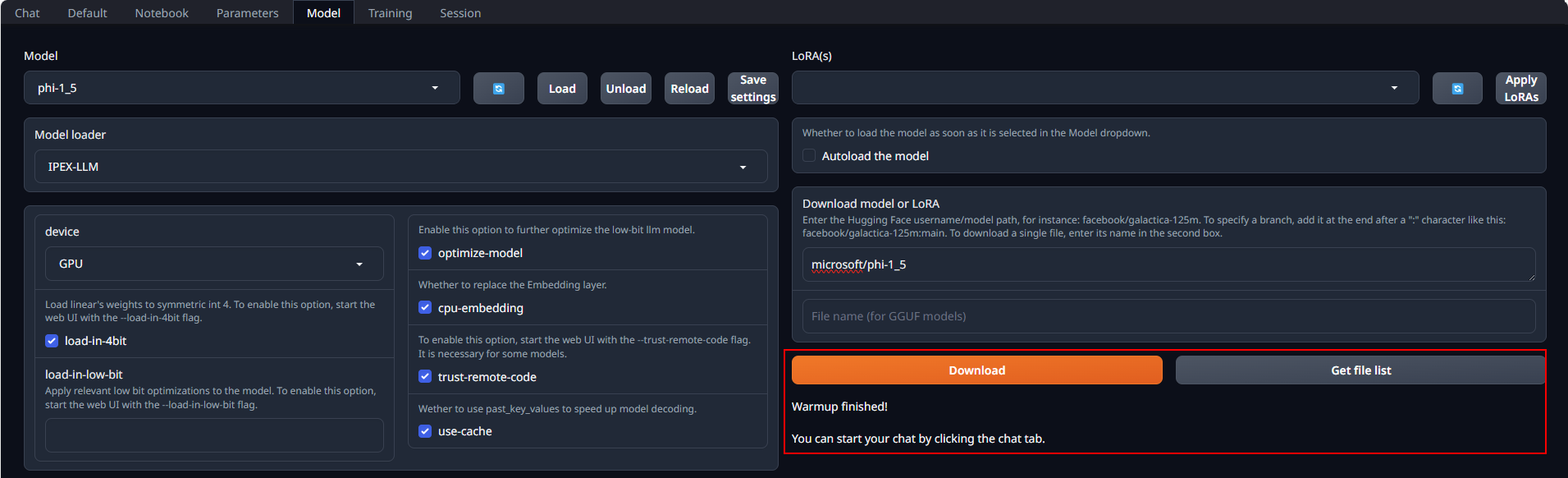 +
+
+```eval_rst
+.. note::
+
+ Model loading might take a few minutes as it includes a **warm-up** phase. This `warm-up` step is used to improve the speed of subsequent model uses.
+```
+
+#### Chat with the Model
+
+In the **Chat** tab, start new conversations with **New chat**.
+
+Enter prompts into the textbox at the bottom and press the **Generate** button to receive responses.
+
+
+
+
+
+
+
+#### Exit the WebUI
+
+To shut down the WebUI server, use **Ctrl+C** in the **Miniforge Prompt** terminal where the WebUI Server is runing, then close your browser tab.
+
+
+### 5. Advanced Usage
+#### Using Instruct mode
+Instruction-following models are models that are fine-tuned with specific prompt formats.
+For these models, you should ideally use the `instruct` chat mode.
+Under this mode, the model receives user prompts that are formatted according to prompt formats it was trained with.
+
+To use `instruct` chat mode, select `chat` tab, scroll down the page, and then select `instruct` under `Mode`.
+
+
+
+
+
+```eval_rst
+.. note::
+
+ Model loading might take a few minutes as it includes a **warm-up** phase. This `warm-up` step is used to improve the speed of subsequent model uses.
+```
+
+#### Chat with the Model
+
+In the **Chat** tab, start new conversations with **New chat**.
+
+Enter prompts into the textbox at the bottom and press the **Generate** button to receive responses.
+
+
+
+
+
+
+
+#### Exit the WebUI
+
+To shut down the WebUI server, use **Ctrl+C** in the **Miniforge Prompt** terminal where the WebUI Server is runing, then close your browser tab.
+
+
+### 5. Advanced Usage
+#### Using Instruct mode
+Instruction-following models are models that are fine-tuned with specific prompt formats.
+For these models, you should ideally use the `instruct` chat mode.
+Under this mode, the model receives user prompts that are formatted according to prompt formats it was trained with.
+
+To use `instruct` chat mode, select `chat` tab, scroll down the page, and then select `instruct` under `Mode`.
+
+
+  +
+
+When a model is loaded, its corresponding instruction template, which contains prompt formatting, is automatically loaded.
+If chat responses are poor, the loaded instruction template might be incorrect.
+In this case, go to `Parameters` tab and then `Instruction template` tab.
+
+
+
+
+
+When a model is loaded, its corresponding instruction template, which contains prompt formatting, is automatically loaded.
+If chat responses are poor, the loaded instruction template might be incorrect.
+In this case, go to `Parameters` tab and then `Instruction template` tab.
+
+
+  +
+
+You can verify and edit the loaded instruction template in the `Instruction template` field.
+You can also manually select an instruction template from `Saved instruction templates` and click `load` to load it into `Instruction template`.
+You can add custom template files to this list in `/instruction-templates/` [folder](https://github.com/intel-analytics/text-generation-webui/tree/ipex-llm/instruction-templates).
+
+
+#### Tested models
+We have tested the following models with `ipex-llm` using Text Generation WebUI.
+
+| Model | Notes |
+|-------|-------|
+| llama-2-7b-chat-hf | |
+| chatglm3-6b | Manually load ChatGLM3 template for Instruct chat mode |
+| Mistral-7B-v0.1 | |
+| qwen-7B-Chat | |
+
+
+### Troubleshooting
+
+### Potentially slower first response
+
+The first response to user prompt might be slower than expected, with delays of up to several minutes before the response is generated. This delay occurs because the GPU kernels require compilation and initialization, which varies across different GPU types.
+
+#### Missing Required Dependencies
+
+During model loading, you may encounter an **ImportError** like `ImportError: This modeling file requires the following packages that were not found in your environment`. This indicates certain packages required by the model are absent from your environment. Detailed instructions for installing these necessary packages can be found at the bottom of the error messages. Take the following steps to fix these errors:
+
+- Exit the WebUI Server by pressing **Ctrl+C** in the **Miniforge Prompt** terminal.
+- Install the missing pip packages as specified in the error message
+- Restart the WebUI Server.
+
+If there are still errors on missing packages, repeat the installation process for any additional required packages.
+
+#### Compatiblity issues
+If you encounter **AttributeError** errors like `AttributeError: 'BaichuanTokenizer' object has no attribute 'sp_model'`, it may be due to some models being incompatible with the current version of the transformers package because the models are outdated. In such instances, using a more recent model is recommended.
+
+
+
+You can verify and edit the loaded instruction template in the `Instruction template` field.
+You can also manually select an instruction template from `Saved instruction templates` and click `load` to load it into `Instruction template`.
+You can add custom template files to this list in `/instruction-templates/` [folder](https://github.com/intel-analytics/text-generation-webui/tree/ipex-llm/instruction-templates).
+
+
+#### Tested models
+We have tested the following models with `ipex-llm` using Text Generation WebUI.
+
+| Model | Notes |
+|-------|-------|
+| llama-2-7b-chat-hf | |
+| chatglm3-6b | Manually load ChatGLM3 template for Instruct chat mode |
+| Mistral-7B-v0.1 | |
+| qwen-7B-Chat | |
+
+
+### Troubleshooting
+
+### Potentially slower first response
+
+The first response to user prompt might be slower than expected, with delays of up to several minutes before the response is generated. This delay occurs because the GPU kernels require compilation and initialization, which varies across different GPU types.
+
+#### Missing Required Dependencies
+
+During model loading, you may encounter an **ImportError** like `ImportError: This modeling file requires the following packages that were not found in your environment`. This indicates certain packages required by the model are absent from your environment. Detailed instructions for installing these necessary packages can be found at the bottom of the error messages. Take the following steps to fix these errors:
+
+- Exit the WebUI Server by pressing **Ctrl+C** in the **Miniforge Prompt** terminal.
+- Install the missing pip packages as specified in the error message
+- Restart the WebUI Server.
+
+If there are still errors on missing packages, repeat the installation process for any additional required packages.
+
+#### Compatiblity issues
+If you encounter **AttributeError** errors like `AttributeError: 'BaichuanTokenizer' object has no attribute 'sp_model'`, it may be due to some models being incompatible with the current version of the transformers package because the models are outdated. In such instances, using a more recent model is recommended.
+
 +
+ +
+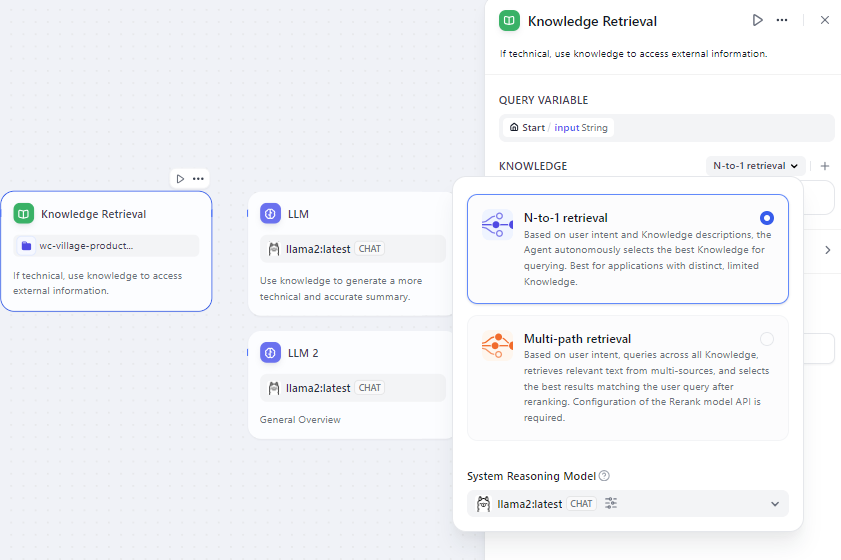 +
+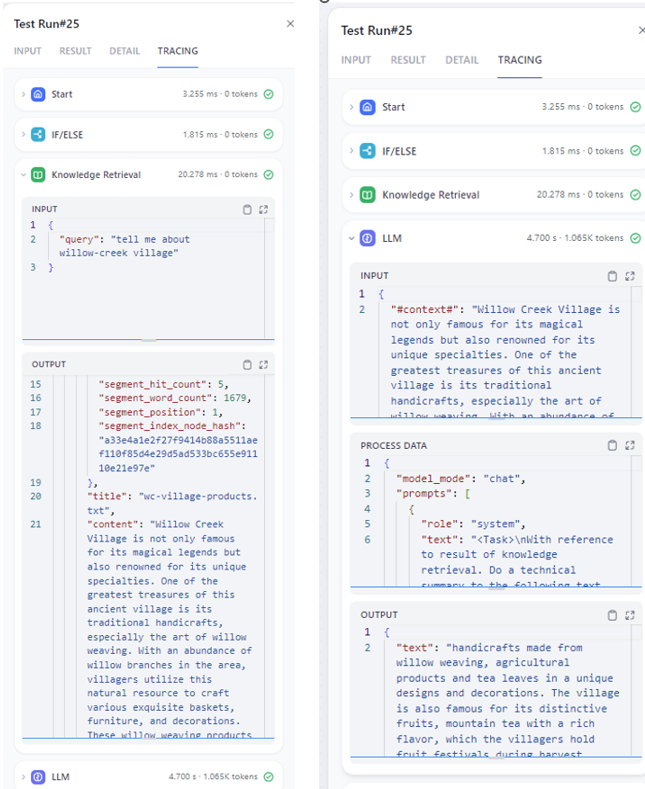 +
+ +
+ +
+ +
+