diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
index fbec9cb2..78e606d0 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
@@ -1,5 +1,5 @@
-# Run Coding Copilot on Windows with Intel GPU
+# Run Coding Copilot in VSCode with Intel GPU
[**Continue**](https://marketplace.visualstudio.com/items?itemName=Continue.continue) is a coding copilot extension in [Microsoft Visual Studio Code](https://code.visualstudio.com/); by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily leverage local LLMs running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) for code explanation, code generation/completion, etc.
@@ -18,42 +18,111 @@ See the demos of using Continue with [Mistral-7B-Instruct-v0.1](https://huggingf
## Quickstart
-This guide walks you through setting up and running **Continue** within _Visual Studio Code_, empowered by local large language models served via [Text Generation WebUI](https://github.com/intel-analytics/text-generation-webui/) with `ipex-llm` optimizations.
+This guide walks you through setting up and running **Continue** within _Visual Studio Code_, empowered by local large language models served via [Ollama](./ollama_quickstart.html) with `ipex-llm` optimizations.
-### 1. Install and Run Text Generation WebUI
+### 1. Install and Run Ollama Serve
-Visit [Run Text Generation WebUI Quickstart Guide](webui_quickstart.html), and follow the steps 1) [Install IPEX-LLM](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#install-ipex-llm), 2) [Install WebUI](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#install-the-webui) and 3) [Start the Server](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#start-the-webui-server) to install and start the Text Generation WebUI API Service. **Please pay attention to below items during installation:**
-
-- The Text Generation WebUI API service requires Python version 3.10 or higher. We recommend use Python 3.11 as below:
- ```bash
- conda create -n llm python=3.11 libuv
- ```
-- Remember to launch the server **with API service** as specified in [Launch the Server](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#launch-the-server)
-
-### 2. Use WebUI to Load Model
-
-#### Access the WebUI
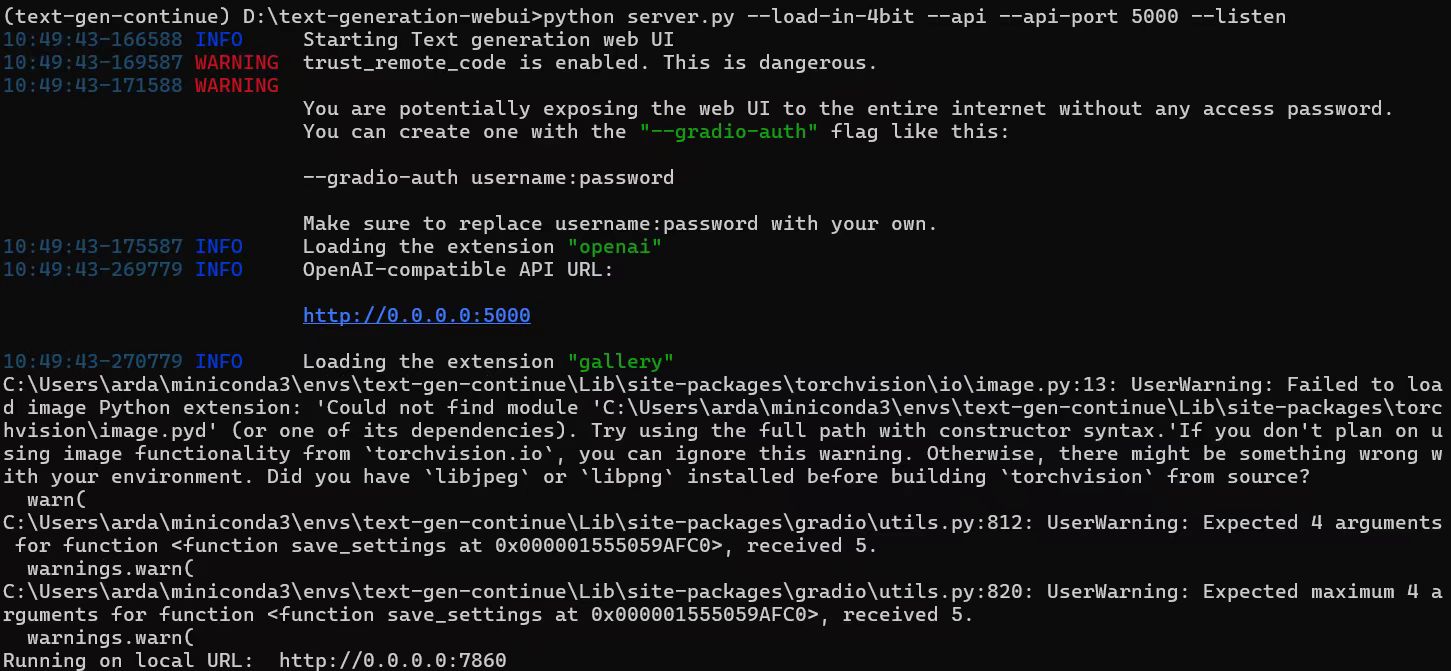
-Upon successful launch, URLs to access the WebUI will be displayed in the terminal as shown below. Open the provided local URL in your browser to interact with the WebUI.
-
-
-  -
-
-#### Model Download and Loading
-
-Here's a list of models that can be used for coding copilot on local PC.
-- Code Llama:
-- WizardCoder
-- Mistral
-- StarCoder
-- DeepSeek Coder
-
-Follow the steps in [Model Download](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#model-download) and [Load Model](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#load-model) to download and load your coding model.
+Visit [Run Ollama with IPEX-LLM on Intel GPU](./ollama_quickstart.html), and follow the steps 1) [Install IPEX-LLM for Ollama](./ollama_quickstart.html#install-ipex-llm-for-ollama), 2) [Initialize Ollama](./ollama_quickstart.html#initialize-ollama) and 3) [Run Ollama Serve](./ollama_quickstart.html#run-ollama-serve) to install and initialize and start the Ollama Service.
```eval_rst
-.. note::
+.. important::
- If you don't need to use the API service anymore, you can follow the instructions in refer to `Exit WebUI `_ to stop the service.
+ Please make sure you have set ``OLLAMA_HOST=0.0.0.0`` before starting the Ollama service, so that connections from all IP addresses can be accepted.
+
+.. tip::
+
+ If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS, it is recommended to additionaly set the following environment variable for optimal performance before the Ollama service is started:
+
+ .. code-block:: bash
+
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+```
+
+### 2. Prepare and Run Model
+
+#### Pull [`codeqwen:latest`](https://ollama.com/library/codeqwen)
+
+In a new terminal window:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ ./ollama pull codeqwen:latest
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: cmd
+
+ set no_proxy=localhost,127.0.0.1
+ ollama pull codeqwen:latest
+
+.. seealso::
+
+ Here's a list of models that can be used for coding copilot on local PC:
+
+ - Code Llama:
+ - WizardCoder
+ - Mistral
+ - StarCoder
+ - DeepSeek Coder
+
+ You could find them in the `Ollama model library `_ and have a try.
+```
+
+
+#### Create and Run Model
+
+First, create a `Modelfile` file with contents:
+
+```
+FROM codeqwen:latest
+PARAMETER num_ctx 4096
+```
+
+then:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ ./ollama create codeqwen:latest-continue -f Modelfile
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: cmd
+
+ ollama create codeqwen:latest-continue -f Modelfile
+```
+
+You can now find `codeqwen:latest-continue` in `ollama list`.
+
+Finially, run the `codeqwen:latest-continue`:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ ./ollama run codeqwen:latest-continue
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: cmd
+
+ ollama run codeqwen:latest-continue
```
### 3. Install `Continue` Extension
-
-
-#### Model Download and Loading
-
-Here's a list of models that can be used for coding copilot on local PC.
-- Code Llama:
-- WizardCoder
-- Mistral
-- StarCoder
-- DeepSeek Coder
-
-Follow the steps in [Model Download](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#model-download) and [Load Model](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#load-model) to download and load your coding model.
+Visit [Run Ollama with IPEX-LLM on Intel GPU](./ollama_quickstart.html), and follow the steps 1) [Install IPEX-LLM for Ollama](./ollama_quickstart.html#install-ipex-llm-for-ollama), 2) [Initialize Ollama](./ollama_quickstart.html#initialize-ollama) and 3) [Run Ollama Serve](./ollama_quickstart.html#run-ollama-serve) to install and initialize and start the Ollama Service.
```eval_rst
-.. note::
+.. important::
- If you don't need to use the API service anymore, you can follow the instructions in refer to `Exit WebUI `_ to stop the service.
+ Please make sure you have set ``OLLAMA_HOST=0.0.0.0`` before starting the Ollama service, so that connections from all IP addresses can be accepted.
+
+.. tip::
+
+ If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS, it is recommended to additionaly set the following environment variable for optimal performance before the Ollama service is started:
+
+ .. code-block:: bash
+
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+```
+
+### 2. Prepare and Run Model
+
+#### Pull [`codeqwen:latest`](https://ollama.com/library/codeqwen)
+
+In a new terminal window:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ ./ollama pull codeqwen:latest
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: cmd
+
+ set no_proxy=localhost,127.0.0.1
+ ollama pull codeqwen:latest
+
+.. seealso::
+
+ Here's a list of models that can be used for coding copilot on local PC:
+
+ - Code Llama:
+ - WizardCoder
+ - Mistral
+ - StarCoder
+ - DeepSeek Coder
+
+ You could find them in the `Ollama model library `_ and have a try.
+```
+
+
+#### Create and Run Model
+
+First, create a `Modelfile` file with contents:
+
+```
+FROM codeqwen:latest
+PARAMETER num_ctx 4096
+```
+
+then:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ ./ollama create codeqwen:latest-continue -f Modelfile
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: cmd
+
+ ollama create codeqwen:latest-continue -f Modelfile
+```
+
+You can now find `codeqwen:latest-continue` in `ollama list`.
+
+Finially, run the `codeqwen:latest-continue`:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ ./ollama run codeqwen:latest-continue
+
+ .. tab:: Windows
+
+ Please run the following command in Anaconda Prompt.
+
+ .. code-block:: cmd
+
+ ollama run codeqwen:latest-continue
```
### 3. Install `Continue` Extension