diff --git a/.github/actions/llm/setup-llm-env/action.yml b/.github/actions/llm/setup-llm-env/action.yml
index 1d530972..4b25ea0c 100644
--- a/.github/actions/llm/setup-llm-env/action.yml
+++ b/.github/actions/llm/setup-llm-env/action.yml
@@ -19,7 +19,7 @@ runs:
sed -i 's/"bigdl-core-xe==" + CORE_XE_VERSION + "/"bigdl-core-xe/g' python/llm/setup.py
sed -i 's/"bigdl-core-xe-esimd==" + CORE_XE_VERSION + "/"bigdl-core-xe-esimd/g' python/llm/setup.py
sed -i 's/"bigdl-core-xe-21==" + CORE_XE_VERSION/"bigdl-core-xe-21"/g' python/llm/setup.py
- sed -i 's/"bigdl-core-xe-esimd-21==" + CORE_XE_VERSION + "/"bigdl-core-xe-esimd-21/g' python/llm/setup.py
+ sed -i 's/"bigdl-core-xe-esimd-21==" + CORE_XE_VERSION/"bigdl-core-xe-esimd-21"/g' python/llm/setup.py
pip install requests
if [[ ${{ runner.os }} == 'Linux' ]]; then
diff --git a/.github/workflows/llm-c-evaluation.yml b/.github/workflows/llm-c-evaluation.yml
index b77e622a..9ca18276 100644
--- a/.github/workflows/llm-c-evaluation.yml
+++ b/.github/workflows/llm-c-evaluation.yml
@@ -95,7 +95,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- python-version: ["3.9"]
+ python-version: ["3.11"]
model_name: ${{ fromJson(needs.set-matrix.outputs.model_name) }}
precision: ${{ fromJson(needs.set-matrix.outputs.precision) }}
device: [xpu]
@@ -193,10 +193,10 @@ jobs:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- - name: Set up Python 3.9
+ - name: Set up Python 3.11
uses: actions/setup-python@v4
with:
- python-version: 3.9
+ python-version: 3.11
- name: Install dependencies
shell: bash
run: |
@@ -230,10 +230,10 @@ jobs:
runs-on: ["self-hosted", "llm", "accuracy1", "accuracy-nightly"]
steps:
- uses: actions/checkout@f43a0e5ff2bd294095638e18286ca9a3d1956744 # actions/checkout@v3
- - name: Set up Python 3.9
+ - name: Set up Python 3.11
uses: actions/setup-python@v4
with:
- python-version: 3.9
+ python-version: 3.11
- name: Install dependencies
shell: bash
run: |
diff --git a/.github/workflows/llm-harness-evaluation.yml b/.github/workflows/llm-harness-evaluation.yml
index 11255e03..54417019 100644
--- a/.github/workflows/llm-harness-evaluation.yml
+++ b/.github/workflows/llm-harness-evaluation.yml
@@ -105,7 +105,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- python-version: ["3.9"]
+ python-version: ["3.11"]
model_name: ${{ fromJson(needs.set-matrix.outputs.model_name) }}
task: ${{ fromJson(needs.set-matrix.outputs.task) }}
precision: ${{ fromJson(needs.set-matrix.outputs.precision) }}
@@ -189,7 +189,7 @@ jobs:
fi
python run_llb.py \
- --model bigdl-llm \
+ --model ipex-llm \
--pretrained ${MODEL_PATH} \
--precision ${{ matrix.precision }} \
--device ${{ matrix.device }} \
@@ -216,10 +216,10 @@ jobs:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@f43a0e5ff2bd294095638e18286ca9a3d1956744 # actions/checkout@v3
- - name: Set up Python 3.9
+ - name: Set up Python 3.11
uses: actions/setup-python@v4
with:
- python-version: 3.9
+ python-version: 3.11
- name: Install dependencies
shell: bash
run: |
@@ -243,10 +243,10 @@ jobs:
runs-on: ["self-hosted", "llm", "accuracy1", "accuracy-nightly"]
steps:
- uses: actions/checkout@f43a0e5ff2bd294095638e18286ca9a3d1956744 # actions/checkout@v3
- - name: Set up Python 3.9
+ - name: Set up Python 3.11
uses: actions/setup-python@v4
with:
- python-version: 3.9
+ python-version: 3.11
- name: Install dependencies
shell: bash
run: |
diff --git a/.github/workflows/llm-nightly-test.yml b/.github/workflows/llm-nightly-test.yml
index 457c7a61..10bfb746 100644
--- a/.github/workflows/llm-nightly-test.yml
+++ b/.github/workflows/llm-nightly-test.yml
@@ -34,10 +34,10 @@ jobs:
include:
- os: windows
instruction: AVX-VNNI-UT
- python-version: "3.9"
+ python-version: "3.11"
- os: ubuntu-20.04-lts
instruction: avx512
- python-version: "3.9"
+ python-version: "3.11"
runs-on: [self-hosted, llm, "${{matrix.instruction}}", "${{matrix.os}}"]
env:
ANALYTICS_ZOO_ROOT: ${{ github.workspace }}
diff --git a/.github/workflows/llm-ppl-evaluation.yml b/.github/workflows/llm-ppl-evaluation.yml
index e2f0b92c..7ad621f9 100644
--- a/.github/workflows/llm-ppl-evaluation.yml
+++ b/.github/workflows/llm-ppl-evaluation.yml
@@ -104,7 +104,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- python-version: ["3.9"]
+ python-version: ["3.11"]
model_name: ${{ fromJson(needs.set-matrix.outputs.model_name) }}
precision: ${{ fromJson(needs.set-matrix.outputs.precision) }}
seq_len: ${{ fromJson(needs.set-matrix.outputs.seq_len) }}
@@ -201,10 +201,10 @@ jobs:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@f43a0e5ff2bd294095638e18286ca9a3d1956744 # actions/checkout@v3
- - name: Set up Python 3.9
+ - name: Set up Python 3.11
uses: actions/setup-python@v4
with:
- python-version: 3.9
+ python-version: 3.11
- name: Install dependencies
shell: bash
run: |
@@ -227,10 +227,10 @@ jobs:
runs-on: ["self-hosted", "llm", "accuracy1", "accuracy-nightly"]
steps:
- uses: actions/checkout@f43a0e5ff2bd294095638e18286ca9a3d1956744 # actions/checkout@v3
- - name: Set up Python 3.9
+ - name: Set up Python 3.11
uses: actions/setup-python@v4
with:
- python-version: 3.9
+ python-version: 3.11
- name: Install dependencies
shell: bash
run: |
diff --git a/.github/workflows/llm-whisper-evaluation.yml b/.github/workflows/llm-whisper-evaluation.yml
index 0a918c56..e60eadbf 100644
--- a/.github/workflows/llm-whisper-evaluation.yml
+++ b/.github/workflows/llm-whisper-evaluation.yml
@@ -81,7 +81,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- python-version: ["3.9"]
+ python-version: ["3.11"]
model_name: ${{ fromJson(needs.set-matrix.outputs.model_name) }}
task: ${{ fromJson(needs.set-matrix.outputs.task) }}
precision: ${{ fromJson(needs.set-matrix.outputs.precision) }}
@@ -158,10 +158,10 @@ jobs:
runs-on: ["self-hosted", "llm", "perf"]
steps:
- uses: actions/checkout@f43a0e5ff2bd294095638e18286ca9a3d1956744 # actions/checkout@v3
- - name: Set up Python 3.9
+ - name: Set up Python 3.11
uses: actions/setup-python@v4
with:
- python-version: 3.9
+ python-version: 3.11
- name: Set output path
shell: bash
diff --git a/.github/workflows/llm_example_tests.yml b/.github/workflows/llm_example_tests.yml
index 8338e48a..a19606a8 100644
--- a/.github/workflows/llm_example_tests.yml
+++ b/.github/workflows/llm_example_tests.yml
@@ -39,7 +39,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- python-version: ["3.9"]
+ python-version: ["3.11"]
instruction: ["AVX512"]
runs-on: [ self-hosted, llm,"${{matrix.instruction}}", ubuntu-20.04-lts ]
env:
diff --git a/.github/workflows/llm_performance_tests.yml b/.github/workflows/llm_performance_tests.yml
index b5495491..48cc7dc7 100644
--- a/.github/workflows/llm_performance_tests.yml
+++ b/.github/workflows/llm_performance_tests.yml
@@ -33,7 +33,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- python-version: ["3.9"]
+ python-version: ["3.11"]
runs-on: [self-hosted, llm, perf]
env:
OMP_NUM_THREADS: 16
@@ -163,7 +163,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- python-version: ["3.9"]
+ python-version: ["3.11"]
runs-on: [self-hosted, llm, spr-perf]
env:
OMP_NUM_THREADS: 16
@@ -238,10 +238,10 @@ jobs:
include:
- os: windows
platform: dp
- python-version: "3.9"
+ python-version: "3.11"
# - os: windows
# platform: lp
- # python-version: "3.9"
+ # python-version: "3.11"
runs-on: [self-hosted, "${{ matrix.os }}", llm, perf-core, "${{ matrix.platform }}"]
env:
ANALYTICS_ZOO_ROOT: ${{ github.workspace }}
@@ -309,7 +309,7 @@ jobs:
matrix:
include:
- os: windows
- python-version: "3.9"
+ python-version: "3.11"
runs-on: [self-hosted, "${{ matrix.os }}", llm, perf-igpu]
env:
ANALYTICS_ZOO_ROOT: ${{ github.workspace }}
@@ -380,7 +380,7 @@ jobs:
- name: Create env for html generation
shell: cmd
run: |
- call conda create -n html-gen python=3.9 -y
+ call conda create -n html-gen python=3.11 -y
call conda activate html-gen
pip install pandas==1.5.3
diff --git a/.github/workflows/llm_tests_for_stable_version_on_arc.yml b/.github/workflows/llm_tests_for_stable_version_on_arc.yml
index 8522ad2d..1b8c48d9 100644
--- a/.github/workflows/llm_tests_for_stable_version_on_arc.yml
+++ b/.github/workflows/llm_tests_for_stable_version_on_arc.yml
@@ -30,7 +30,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- python-version: ["3.9"]
+ python-version: ["3.11"]
runs-on: [self-hosted, llm, perf]
env:
OMP_NUM_THREADS: 16
@@ -154,7 +154,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- python-version: ["3.9"]
+ python-version: ["3.11"]
runs-on: [self-hosted, llm, perf]
env:
OMP_NUM_THREADS: 16
diff --git a/.github/workflows/llm_tests_for_stable_version_on_spr.yml b/.github/workflows/llm_tests_for_stable_version_on_spr.yml
index cedc1624..d852499c 100644
--- a/.github/workflows/llm_tests_for_stable_version_on_spr.yml
+++ b/.github/workflows/llm_tests_for_stable_version_on_spr.yml
@@ -29,7 +29,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- python-version: ["3.9"]
+ python-version: ["3.11"]
runs-on: [self-hosted, llm, spr01-perf]
env:
OMP_NUM_THREADS: 16
@@ -87,7 +87,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- python-version: ["3.9"]
+ python-version: ["3.11"]
runs-on: [self-hosted, llm, spr01-perf]
env:
OMP_NUM_THREADS: 16
diff --git a/.github/workflows/llm_unit_tests.yml b/.github/workflows/llm_unit_tests.yml
index f1b762d9..cf4a7312 100644
--- a/.github/workflows/llm_unit_tests.yml
+++ b/.github/workflows/llm_unit_tests.yml
@@ -51,7 +51,7 @@ jobs:
if [ ${{ github.event_name }} == 'schedule' ]; then
python_version='["3.9", "3.10", "3.11"]'
else
- python_version='["3.9"]'
+ python_version='["3.11"]'
fi
list=$(echo ${python_version} | jq -c)
echo "python-version=${list}" >> "$GITHUB_OUTPUT"
@@ -224,6 +224,7 @@ jobs:
run: |
pip install llama-index-readers-file llama-index-vector-stores-postgres llama-index-embeddings-huggingface
pip install transformers==4.31.0
+ pip install "pydantic>=2.0.0"
bash python/llm/test/run-llm-llamaindex-tests.sh
llm-unit-test-on-arc:
needs: [setup-python-version, llm-cpp-build]
@@ -398,4 +399,5 @@ jobs:
pip install --pre --upgrade ipex-llm[xpu_2.0] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/
source /home/arda/intel/oneapi/setvars.sh
fi
+ pip install "pydantic>=2.0.0"
bash python/llm/test/run-llm-llamaindex-tests-gpu.sh
\ No newline at end of file
diff --git a/README.md b/README.md
index 73d3c5ae..35ccdea6 100644
--- a/README.md
+++ b/README.md
@@ -7,7 +7,7 @@
**`IPEX-LLM`** is a PyTorch library for running **LLM** on Intel CPU and GPU *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)* with very low latency[^1].
> [!NOTE]
> - *It is built on top of **Intel Extension for PyTorch** (**`IPEX`**), as well as the excellent work of **`llama.cpp`**, **`bitsandbytes`**, **`vLLM`**, **`qlora`**, **`AutoGPTQ`**, **`AutoAWQ`**, etc.*
-> - *It provides seamless integration with [llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html), [Text-Generation-WebUI](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html), [HuggingFace transformers](python/llm/example/GPU/HF-Transformers-AutoModels), [HuggingFace PEFT](python/llm/example/GPU/LLM-Finetuning), [LangChain](python/llm/example/GPU/LangChain), [LlamaIndex](python/llm/example/GPU/LlamaIndex), [DeepSpeed-AutoTP](python/llm/example/GPU/Deepspeed-AutoTP), [vLLM](python/llm/example/GPU/vLLM-Serving), [FastChat](python/llm/src/ipex_llm/serving/fastchat), [HuggingFace TRL](python/llm/example/GPU/LLM-Finetuning/DPO), [AutoGen](python/llm/example/CPU/Applications/autogen), [ModeScope](python/llm/example/GPU/ModelScope-Models), etc.*
+> - *It provides seamless integration with [llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html), [ollama](https://ipex-llm.readthedocs.io/en/main/doc/LLM/Quickstart/ollama_quickstart.html), [Text-Generation-WebUI](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html), [HuggingFace transformers](python/llm/example/GPU/HF-Transformers-AutoModels), [HuggingFace PEFT](python/llm/example/GPU/LLM-Finetuning), [LangChain](python/llm/example/GPU/LangChain), [LlamaIndex](python/llm/example/GPU/LlamaIndex), [DeepSpeed-AutoTP](python/llm/example/GPU/Deepspeed-AutoTP), [vLLM](python/llm/example/GPU/vLLM-Serving), [FastChat](python/llm/src/ipex_llm/serving/fastchat), [HuggingFace TRL](python/llm/example/GPU/LLM-Finetuning/DPO), [AutoGen](python/llm/example/CPU/Applications/autogen), [ModeScope](python/llm/example/GPU/ModelScope-Models), etc.*
> - ***50+ models** have been optimized/verified on `ipex-llm` (including LLaMA2, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM, Baichuan, Qwen, RWKV, and more); see the complete list [here](#verified-models).*
## `ipex-llm` Demo
@@ -48,9 +48,10 @@ See the demo of running [*Text-Generation-WebUI*](https://ipex-llm.readthedocs.i
## Latest Update 🔥
+- [2024/04] `ipex-llm` now provides C++ interface, which can be used as an accelerated backend for running [llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html) and [ollama](https://ipex-llm.readthedocs.io/en/main/doc/LLM/Quickstart/ollama_quickstart.html) on Intel GPU.
- [2024/03] `bigdl-llm` has now become `ipex-llm` (see the migration guide [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/bigdl_llm_migration.html)); you may find the original `BigDL` project [here](https://github.com/intel-analytics/bigdl-2.x).
- [2024/02] `ipex-llm` now supports directly loading model from [ModelScope](python/llm/example/GPU/ModelScope-Models) ([魔搭](python/llm/example/CPU/ModelScope-Models)).
-- [2024/02] `ipex-llm` added inital **INT2** support (based on llama.cpp [IQ2](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF-IQ2) mechanism), which makes it possible to run large-size LLM (e.g., Mixtral-8x7B) on Intel GPU with 16GB VRAM.
+- [2024/02] `ipex-llm` added initial **INT2** support (based on llama.cpp [IQ2](python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF-IQ2) mechanism), which makes it possible to run large-size LLM (e.g., Mixtral-8x7B) on Intel GPU with 16GB VRAM.
- [2024/02] Users can now use `ipex-llm` through [Text-Generation-WebUI](https://github.com/intel-analytics/text-generation-webui) GUI.
- [2024/02] `ipex-llm` now supports *[Self-Speculative Decoding](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Inference/Self_Speculative_Decoding.html)*, which in practice brings **~30% speedup** for FP16 and BF16 inference latency on Intel [GPU](python/llm/example/GPU/Speculative-Decoding) and [CPU](python/llm/example/CPU/Speculative-Decoding) respectively.
- [2024/02] `ipex-llm` now supports a comprehensive list of LLM **finetuning** on Intel GPU (including [LoRA](python/llm/example/GPU/LLM-Finetuning/LoRA), [QLoRA](python/llm/example/GPU/LLM-Finetuning/QLoRA), [DPO](python/llm/example/GPU/LLM-Finetuning/DPO), [QA-LoRA](python/llm/example/GPU/LLM-Finetuning/QA-LoRA) and [ReLoRA](python/llm/example/GPU/LLM-Finetuning/ReLora)).
@@ -81,7 +82,8 @@ See the demo of running [*Text-Generation-WebUI*](https://ipex-llm.readthedocs.i
- *For more details, please refer to the [installation guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/install.html)*
### Run `ipex-llm`
-- [llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html): running **ipex-llm for llama.cpp** (*using C++ interface of `ipex-llm` as an accelerated backend for `llama.cpp` on Intel GPU*)
+- [llama.cpp](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html): running **llama.cpp** (*using C++ interface of `ipex-llm` as an accelerated backend for `llama.cpp`*) on Intel GPU
+- [ollama](https://ipex-llm.readthedocs.io/en/main/doc/LLM/Quickstart/ollama_quickstart.html): running **ollama** (*using C++ interface of `ipex-llm` as an accelerated backend for `ollama`*) on Intel GPU
- [vLLM](python/llm/example/GPU/vLLM-Serving): running `ipex-llm` in `vLLM` on both Intel [GPU](python/llm/example/GPU/vLLM-Serving) and [CPU](python/llm/example/CPU/vLLM-Serving)
- [FastChat](python/llm/src/ipex_llm/serving/fastchat): running `ipex-llm` in `FastChat` serving on on both Intel GPU and CPU
- [LangChain-Chatchat RAG](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/chatchat_quickstart.html): running `ipex-llm` in `LangChain-Chatchat` (*Knowledge Base QA using **RAG** pipeline*)
diff --git a/docker/llm/finetune/lora/cpu/docker/Dockerfile b/docker/llm/finetune/lora/cpu/docker/Dockerfile
index 4b6f51b9..8c564b03 100644
--- a/docker/llm/finetune/lora/cpu/docker/Dockerfile
+++ b/docker/llm/finetune/lora/cpu/docker/Dockerfile
@@ -21,7 +21,7 @@ RUN echo "deb [signed-by=/usr/share/keyrings/intel-oneapi-archive-keyring.gpg] h
RUN mkdir /ipex_llm/data && mkdir /ipex_llm/model && \
# install pytorch 2.0.1
apt-get update && \
- apt-get install -y python3-pip python3.9-dev python3-wheel git software-properties-common && \
+ apt-get install -y python3-pip python3.11-dev python3-wheel git software-properties-common && \
pip3 install --upgrade pip && \
export PIP_DEFAULT_TIMEOUT=100 && \
pip install --upgrade torch==2.1.0 --index-url https://download.pytorch.org/whl/cpu && \
@@ -37,9 +37,9 @@ RUN mkdir /ipex_llm/data && mkdir /ipex_llm/model && \
pip install -r /ipex_llm/requirements.txt && \
# install python
add-apt-repository ppa:deadsnakes/ppa -y && \
- apt-get install -y python3.9 && \
+ apt-get install -y python3.11 && \
rm /usr/bin/python3 && \
- ln -s /usr/bin/python3.9 /usr/bin/python3 && \
+ ln -s /usr/bin/python3.11 /usr/bin/python3 && \
ln -s /usr/bin/python3 /usr/bin/python && \
pip install --no-cache requests argparse cryptography==3.3.2 urllib3 && \
pip install --upgrade requests && \
diff --git a/docker/llm/finetune/qlora/cpu/docker/Dockerfile b/docker/llm/finetune/qlora/cpu/docker/Dockerfile
index 2aaaa08e..4f68d486 100644
--- a/docker/llm/finetune/qlora/cpu/docker/Dockerfile
+++ b/docker/llm/finetune/qlora/cpu/docker/Dockerfile
@@ -21,7 +21,7 @@ RUN echo "deb [signed-by=/usr/share/keyrings/intel-oneapi-archive-keyring.gpg] h
RUN mkdir -p /ipex_llm/data && mkdir -p /ipex_llm/model && \
# install pytorch 2.1.0
apt-get update && \
- apt-get install -y --no-install-recommends python3-pip python3.9-dev python3-wheel python3.9-distutils git software-properties-common && \
+ apt-get install -y --no-install-recommends python3-pip python3.11-dev python3-wheel python3.11-distutils git software-properties-common && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
pip3 install --upgrade pip && \
diff --git a/docker/llm/finetune/qlora/cpu/docker/Dockerfile.k8s b/docker/llm/finetune/qlora/cpu/docker/Dockerfile.k8s
index 71a8a5e1..f14e0b08 100644
--- a/docker/llm/finetune/qlora/cpu/docker/Dockerfile.k8s
+++ b/docker/llm/finetune/qlora/cpu/docker/Dockerfile.k8s
@@ -22,7 +22,7 @@ RUN echo "deb [signed-by=/usr/share/keyrings/intel-oneapi-archive-keyring.gpg] h
RUN mkdir -p /ipex_llm/data && mkdir -p /ipex_llm/model && \
apt-get update && \
apt install -y --no-install-recommends openssh-server openssh-client libcap2-bin gnupg2 ca-certificates \
- python3-pip python3.9-dev python3-wheel python3.9-distutils git software-properties-common && \
+ python3-pip python3.11-dev python3-wheel python3.11-distutils git software-properties-common && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
mkdir -p /var/run/sshd && \
diff --git a/docker/llm/finetune/qlora/xpu/docker/Dockerfile b/docker/llm/finetune/qlora/xpu/docker/Dockerfile
index ea5fe693..478ed5bc 100644
--- a/docker/llm/finetune/qlora/xpu/docker/Dockerfile
+++ b/docker/llm/finetune/qlora/xpu/docker/Dockerfile
@@ -18,15 +18,15 @@ RUN curl -fsSL https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-P
apt-get install -y curl wget git gnupg gpg-agent software-properties-common libunwind8-dev vim less && \
# install Intel GPU driver
apt-get install -y intel-opencl-icd intel-level-zero-gpu=1.3.26241.33-647~22.04 level-zero level-zero-dev --allow-downgrades && \
- # install python 3.9
+ # install python 3.11
ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone && \
env DEBIAN_FRONTEND=noninteractive apt-get update && \
add-apt-repository ppa:deadsnakes/ppa -y && \
- apt-get install -y python3.9 && \
+ apt-get install -y python3.11 && \
rm /usr/bin/python3 && \
- ln -s /usr/bin/python3.9 /usr/bin/python3 && \
+ ln -s /usr/bin/python3.11 /usr/bin/python3 && \
ln -s /usr/bin/python3 /usr/bin/python && \
- apt-get install -y python3-pip python3.9-dev python3-wheel python3.9-distutils && \
+ apt-get install -y python3-pip python3.11-dev python3-wheel python3.11-distutils && \
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py && \
# install XPU ipex-llm
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ && \
diff --git a/docker/llm/inference/cpu/docker/Dockerfile b/docker/llm/inference/cpu/docker/Dockerfile
index f8a302f7..319ffcdf 100644
--- a/docker/llm/inference/cpu/docker/Dockerfile
+++ b/docker/llm/inference/cpu/docker/Dockerfile
@@ -9,22 +9,30 @@ ENV PYTHONUNBUFFERED=1
COPY ./start-notebook.sh /llm/start-notebook.sh
-# Install PYTHON 3.9
+# Update the software sources
RUN env DEBIAN_FRONTEND=noninteractive apt-get update && \
+# Install essential packages
apt install software-properties-common libunwind8-dev vim less -y && \
+# Install git, curl, and wget
+ apt-get install -y git curl wget && \
+# Install Python 3.11
+ # Add Python 3.11 PPA repository
add-apt-repository ppa:deadsnakes/ppa -y && \
- apt-get install -y python3.9 git curl wget && \
+ # Install Python 3.11
+ apt-get install -y python3.11 && \
+ # Remove the original /usr/bin/python3 symbolic link
rm /usr/bin/python3 && \
- ln -s /usr/bin/python3.9 /usr/bin/python3 && \
+ # Create a symbolic link pointing to Python 3.11 at /usr/bin/python3
+ ln -s /usr/bin/python3.11 /usr/bin/python3 && \
+ # Create a symbolic link pointing to /usr/bin/python3 at /usr/bin/python
ln -s /usr/bin/python3 /usr/bin/python && \
- apt-get install -y python3-pip python3.9-dev python3-wheel python3.9-distutils && \
+ # Install Python 3.11 development and utility packages
+ apt-get install -y python3-pip python3.11-dev python3-wheel python3.11-distutils && \
+# Download and install pip, install FastChat from source requires PEP 660 support
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py && \
-# Install FastChat from source requires PEP 660 support
python3 get-pip.py && \
rm get-pip.py && \
pip install --upgrade requests argparse urllib3 && \
- pip3 install --no-cache-dir --upgrade torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu && \
- pip install --pre --upgrade ipex-llm[all] && \
# Download ipex-llm-tutorial
cd /llm && \
pip install --upgrade jupyterlab && \
diff --git a/docker/llm/inference/xpu/docker/Dockerfile b/docker/llm/inference/xpu/docker/Dockerfile
index 74dec616..b3269627 100644
--- a/docker/llm/inference/xpu/docker/Dockerfile
+++ b/docker/llm/inference/xpu/docker/Dockerfile
@@ -20,16 +20,16 @@ RUN curl -fsSL https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-P
wget -qO - https://repositories.intel.com/graphics/intel-graphics.key | gpg --dearmor --output /usr/share/keyrings/intel-graphics.gpg && \
echo 'deb [arch=amd64,i386 signed-by=/usr/share/keyrings/intel-graphics.gpg] https://repositories.intel.com/graphics/ubuntu jammy arc' | tee /etc/apt/sources.list.d/intel.gpu.jammy.list && \
rm /etc/apt/sources.list.d/intel-graphics.list && \
- # Install PYTHON 3.9 and IPEX-LLM[xpu]
+ # Install PYTHON 3.11 and IPEX-LLM[xpu]
ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone && \
env DEBIAN_FRONTEND=noninteractive apt-get update && \
apt install software-properties-common libunwind8-dev vim less -y && \
add-apt-repository ppa:deadsnakes/ppa -y && \
- apt-get install -y python3.9 git curl wget && \
+ apt-get install -y python3.11 git curl wget && \
rm /usr/bin/python3 && \
- ln -s /usr/bin/python3.9 /usr/bin/python3 && \
+ ln -s /usr/bin/python3.11 /usr/bin/python3 && \
ln -s /usr/bin/python3 /usr/bin/python && \
- apt-get install -y python3-pip python3.9-dev python3-wheel python3.9-distutils && \
+ apt-get install -y python3-pip python3.11-dev python3-wheel python3.11-distutils && \
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py && \
# Install FastChat from source requires PEP 660 support
python3 get-pip.py && \
diff --git a/docker/llm/serving/cpu/docker/Dockerfile b/docker/llm/serving/cpu/docker/Dockerfile
index 06ddb7f5..e3ddb7ca 100644
--- a/docker/llm/serving/cpu/docker/Dockerfile
+++ b/docker/llm/serving/cpu/docker/Dockerfile
@@ -16,7 +16,7 @@ RUN cd /llm && \
# Fix Trivy CVE Issues
pip install Jinja2==3.1.3 transformers==4.36.2 gradio==4.19.2 cryptography==42.0.4 && \
# Fix Qwen model adpater in fastchat
- patch /usr/local/lib/python3.9/dist-packages/fastchat/model/model_adapter.py < /llm/model_adapter.py.patch && \
+ patch /usr/local/lib/python3.11/dist-packages/fastchat/model/model_adapter.py < /llm/model_adapter.py.patch && \
chmod +x /opt/entrypoint.sh && \
chmod +x /sbin/tini && \
cp /sbin/tini /usr/bin/tini
diff --git a/docs/readthedocs/source/_templates/sidebar_quicklinks.html b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
index 3ce6d153..ef1ea3eb 100644
--- a/docs/readthedocs/source/_templates/sidebar_quicklinks.html
+++ b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
@@ -29,13 +29,16 @@
Install IPEX-LLM in Docker on Windows with Intel GPU
- Run Langchain-Chatchat (RAG Application) on Intel GPU
+ Run Local RAG using Langchain-Chatchat on Intel GPU
Run Text Generation WebUI on Intel GPU
- Run Code Copilot (Continue) in VSCode with Intel GPU
+ Run Coding Copilot (Continue) in VSCode with Intel GPU
+
+
+ Run Open WebUI with IPEX-LLM on Intel GPU
Run Performance Benchmarking with IPEX-LLM
diff --git a/docs/readthedocs/source/_toc.yml b/docs/readthedocs/source/_toc.yml
index cf522a82..88a01688 100644
--- a/docs/readthedocs/source/_toc.yml
+++ b/docs/readthedocs/source/_toc.yml
@@ -25,6 +25,7 @@ subtrees:
- file: doc/LLM/Quickstart/docker_windows_gpu
- file: doc/LLM/Quickstart/chatchat_quickstart
- file: doc/LLM/Quickstart/webui_quickstart
+ - file: doc/LLM/Quickstart/open_webui_with_ollama_quickstart
- file: doc/LLM/Quickstart/continue_quickstart
- file: doc/LLM/Quickstart/benchmark_quickstart
- file: doc/LLM/Quickstart/llama_cpp_quickstart
diff --git a/docs/readthedocs/source/doc/LLM/Overview/install_cpu.md b/docs/readthedocs/source/doc/LLM/Overview/install_cpu.md
index bb2b952c..53342b77 100644
--- a/docs/readthedocs/source/doc/LLM/Overview/install_cpu.md
+++ b/docs/readthedocs/source/doc/LLM/Overview/install_cpu.md
@@ -17,7 +17,7 @@ Please refer to [Environment Setup](#environment-setup) for more information.
.. important::
- ``ipex-llm`` is tested with Python 3.9, 3.10 and 3.11; Python 3.9 is recommended for best practices.
+ ``ipex-llm`` is tested with Python 3.9, 3.10 and 3.11; Python 3.11 is recommended for best practices.
```
## Recommended Requirements
@@ -39,10 +39,10 @@ Here list the recommended hardware and OS for smooth IPEX-LLM optimization exper
For optimal performance with LLM models using IPEX-LLM optimizations on Intel CPUs, here are some best practices for setting up environment:
-First we recommend using [Conda](https://docs.conda.io/en/latest/miniconda.html) to create a python 3.9 enviroment:
+First we recommend using [Conda](https://docs.conda.io/en/latest/miniconda.html) to create a python 3.11 enviroment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/docs/readthedocs/source/doc/LLM/Overview/install_gpu.md b/docs/readthedocs/source/doc/LLM/Overview/install_gpu.md
index 22f49e1f..b58e6f1e 100644
--- a/docs/readthedocs/source/doc/LLM/Overview/install_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/Overview/install_gpu.md
@@ -22,10 +22,10 @@ To apply Intel GPU acceleration, there're several prerequisite steps for tools i
* Step 4: Install Intel® oneAPI Base Toolkit 2024.0:
- First, Create a Python 3.9 enviroment and activate it. In Anaconda Prompt:
+ First, Create a Python 3.11 enviroment and activate it. In Anaconda Prompt:
```cmd
- conda create -n llm python=3.9 libuv
+ conda create -n llm python=3.11 libuv
conda activate llm
```
@@ -33,7 +33,7 @@ To apply Intel GPU acceleration, there're several prerequisite steps for tools i
```eval_rst
.. important::
- ``ipex-llm`` is tested with Python 3.9, 3.10 and 3.11. Python 3.9 is recommended for best practices.
+ ``ipex-llm`` is tested with Python 3.9, 3.10 and 3.11. Python 3.11 is recommended for best practices.
```
Then, use `pip` to install the Intel oneAPI Base Toolkit 2024.0:
@@ -93,17 +93,17 @@ If you encounter network issues when installing IPEX, you can also install IPEX-
Download the wheels on Windows system:
```
-wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torch-2.1.0a0%2Bcxx11.abi-cp39-cp39-win_amd64.whl
-wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torchvision-0.16.0a0%2Bcxx11.abi-cp39-cp39-win_amd64.whl
-wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/intel_extension_for_pytorch-2.1.10%2Bxpu-cp39-cp39-win_amd64.whl
+wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torch-2.1.0a0%2Bcxx11.abi-cp311-cp311-win_amd64.whl
+wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torchvision-0.16.0a0%2Bcxx11.abi-cp311-cp311-win_amd64.whl
+wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/intel_extension_for_pytorch-2.1.10%2Bxpu-cp311-cp311-win_amd64.whl
```
You may install dependencies directly from the wheel archives and then install `ipex-llm` using following commands:
```
-pip install torch-2.1.0a0+cxx11.abi-cp39-cp39-win_amd64.whl
-pip install torchvision-0.16.0a0+cxx11.abi-cp39-cp39-win_amd64.whl
-pip install intel_extension_for_pytorch-2.1.10+xpu-cp39-cp39-win_amd64.whl
+pip install torch-2.1.0a0+cxx11.abi-cp311-cp311-win_amd64.whl
+pip install torchvision-0.16.0a0+cxx11.abi-cp311-cp311-win_amd64.whl
+pip install intel_extension_for_pytorch-2.1.10+xpu-cp311-cp311-win_amd64.whl
pip install --pre --upgrade ipex-llm[xpu]
```
@@ -111,7 +111,7 @@ pip install --pre --upgrade ipex-llm[xpu]
```eval_rst
.. note::
- All the wheel packages mentioned here are for Python 3.9. If you would like to use Python 3.10 or 3.11, you should modify the wheel names for ``torch``, ``torchvision``, and ``intel_extension_for_pytorch`` by replacing ``cp39`` with ``cp310`` or ``cp311``, respectively.
+ All the wheel packages mentioned here are for Python 3.11. If you would like to use Python 3.9 or 3.10, you should modify the wheel names for ``torch``, ``torchvision``, and ``intel_extension_for_pytorch`` by replacing ``cp11`` with ``cp39`` or ``cp310``, respectively.
```
### Runtime Configuration
@@ -164,7 +164,7 @@ If you met error when importing `intel_extension_for_pytorch`, please ensure tha
* Ensure that `libuv` is installed in your conda environment. This can be done during the creation of the environment with the command:
```cmd
- conda create -n llm python=3.9 libuv
+ conda create -n llm python=3.11 libuv
```
If you missed `libuv`, you can add it to your existing environment through
```cmd
@@ -399,12 +399,12 @@ IPEX-LLM GPU support on Linux has been verified on:
### Install IPEX-LLM
#### Install IPEX-LLM From PyPI
-We recommend using [miniconda](https://docs.conda.io/en/latest/miniconda.html) to create a python 3.9 enviroment:
+We recommend using [miniconda](https://docs.conda.io/en/latest/miniconda.html) to create a python 3.11 enviroment:
```eval_rst
.. important::
- ``ipex-llm`` is tested with Python 3.9, 3.10 and 3.11. Python 3.9 is recommended for best practices.
+ ``ipex-llm`` is tested with Python 3.9, 3.10 and 3.11. Python 3.11 is recommended for best practices.
```
```eval_rst
@@ -422,7 +422,7 @@ We recommend using [miniconda](https://docs.conda.io/en/latest/miniconda.html) t
.. code-block:: bash
- conda create -n llm python=3.9
+ conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -439,7 +439,7 @@ We recommend using [miniconda](https://docs.conda.io/en/latest/miniconda.html) t
.. code-block:: bash
- conda create -n llm python=3.9
+ conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/
@@ -461,7 +461,7 @@ We recommend using [miniconda](https://docs.conda.io/en/latest/miniconda.html) t
.. code-block:: bash
- conda create -n llm python=3.9
+ conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[xpu_2.0] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -470,7 +470,7 @@ We recommend using [miniconda](https://docs.conda.io/en/latest/miniconda.html) t
.. code-block:: bash
- conda create -n llm python=3.9
+ conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[xpu_2.0] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/
@@ -488,18 +488,18 @@ If you encounter network issues when installing IPEX, you can also install IPEX-
.. code-block:: bash
# get the wheels on Linux system for IPEX 2.1.10+xpu
- wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torch-2.1.0a0%2Bcxx11.abi-cp39-cp39-linux_x86_64.whl
- wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torchvision-0.16.0a0%2Bcxx11.abi-cp39-cp39-linux_x86_64.whl
- wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/intel_extension_for_pytorch-2.1.10%2Bxpu-cp39-cp39-linux_x86_64.whl
+ wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torch-2.1.0a0%2Bcxx11.abi-cp311-cp311-linux_x86_64.whl
+ wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torchvision-0.16.0a0%2Bcxx11.abi-cp311-cp311-linux_x86_64.whl
+ wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/intel_extension_for_pytorch-2.1.10%2Bxpu-cp311-cp311-linux_x86_64.whl
Then you may install directly from the wheel archives using following commands:
.. code-block:: bash
# install the packages from the wheels
- pip install torch-2.1.0a0+cxx11.abi-cp39-cp39-linux_x86_64.whl
- pip install torchvision-0.16.0a0+cxx11.abi-cp39-cp39-linux_x86_64.whl
- pip install intel_extension_for_pytorch-2.1.10+xpu-cp39-cp39-linux_x86_64.whl
+ pip install torch-2.1.0a0+cxx11.abi-cp311-cp311-linux_x86_64.whl
+ pip install torchvision-0.16.0a0+cxx11.abi-cp311-cp311-linux_x86_64.whl
+ pip install intel_extension_for_pytorch-2.1.10+xpu-cp311-cp311-linux_x86_64.whl
# install ipex-llm for Intel GPU
pip install --pre --upgrade ipex-llm[xpu]
@@ -509,18 +509,18 @@ If you encounter network issues when installing IPEX, you can also install IPEX-
.. code-block:: bash
# get the wheels on Linux system for IPEX 2.0.110+xpu
- wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torch-2.0.1a0%2Bcxx11.abi-cp39-cp39-linux_x86_64.whl
- wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torchvision-0.15.2a0%2Bcxx11.abi-cp39-cp39-linux_x86_64.whl
- wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/intel_extension_for_pytorch-2.0.110%2Bxpu-cp39-cp39-linux_x86_64.whl
+ wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torch-2.0.1a0%2Bcxx11.abi-cp311-cp311-linux_x86_64.whl
+ wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torchvision-0.15.2a0%2Bcxx11.abi-cp311-cp311-linux_x86_64.whl
+ wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/intel_extension_for_pytorch-2.0.110%2Bxpu-cp311-cp311-linux_x86_64.whl
Then you may install directly from the wheel archives using following commands:
.. code-block:: bash
# install the packages from the wheels
- pip install torch-2.0.1a0+cxx11.abi-cp39-cp39-linux_x86_64.whl
- pip install torchvision-0.15.2a0+cxx11.abi-cp39-cp39-linux_x86_64.whl
- pip install intel_extension_for_pytorch-2.0.110+xpu-cp39-cp39-linux_x86_64.whl
+ pip install torch-2.0.1a0+cxx11.abi-cp311-cp311-linux_x86_64.whl
+ pip install torchvision-0.15.2a0+cxx11.abi-cp311-cp311-linux_x86_64.whl
+ pip install intel_extension_for_pytorch-2.0.110+xpu-cp311-cp311-linux_x86_64.whl
# install ipex-llm for Intel GPU
pip install --pre --upgrade ipex-llm[xpu_2.0]
@@ -530,7 +530,7 @@ If you encounter network issues when installing IPEX, you can also install IPEX-
```eval_rst
.. note::
- All the wheel packages mentioned here are for Python 3.9. If you would like to use Python 3.10 or 3.11, you should modify the wheel names for ``torch``, ``torchvision``, and ``intel_extension_for_pytorch`` by replacing ``cp39`` with ``cp310`` or ``cp311``, respectively.
+ All the wheel packages mentioned here are for Python 3.11. If you would like to use Python 3.9 or 3.10, you should modify the wheel names for ``torch``, ``torchvision``, and ``intel_extension_for_pytorch`` by replacing ``cp11`` with ``cp39`` or ``cp310``, respectively.
```
### Runtime Configuration
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md
index 9939b860..ad5ca185 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md
@@ -6,8 +6,8 @@
- | English |
- 简体中文 |
+ English |
+ 简体中文 |
|
@@ -33,7 +33,7 @@ See the Langchain-Chatchat architecture below ([source](https://github.com/chatc
Follow the guide that corresponds to your specific system and GPU type from the links provided below:
- For systems with Intel Core Ultra integrated GPU: [Windows Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_win_mtl.md#)
-- For systems with Intel Arc A-Series GPU: [Windows Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_windows_arc.md#) | [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_arc.md#)
+- For systems with Intel Arc A-Series GPU: [Windows Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_win_arc.md#) | [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_arc.md#)
- For systems with Intel Data Center Max Series GPU: [Linux Guide](https://github.com/intel-analytics/Langchain-Chatchat/blob/ipex-llm/INSTALL_linux_max.md#)
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
index 0f75491c..d5176180 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
@@ -1,8 +1,9 @@
-# Run Code Copilot on Windows with Intel GPU
+# Run Coding Copilot on Windows with Intel GPU
-[**Continue**](https://marketplace.visualstudio.com/items?itemName=Continue.continue) is a coding copilot extension in [Microsoft Visual Studio Code](https://code.visualstudio.com/); by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily leverage local llms running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) for code explanation, code generation/completion; see the demos of using Continue with [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) running on Intel A770 GPU below.
+[**Continue**](https://marketplace.visualstudio.com/items?itemName=Continue.continue) is a coding copilot extension in [Microsoft Visual Studio Code](https://code.visualstudio.com/); by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily leverage local LLMs running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) for code explanation, code generation/completion, etc.
+See the demos of using Continue with [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) running on Intel A770 GPU below.
@@ -27,7 +28,7 @@ This guide walks you through setting up and running **Continue** within _Visual
Visit [Run Text Generation WebUI Quickstart Guide](webui_quickstart.html), and follow the steps 1) [Install IPEX-LLM](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#install-ipex-llm), 2) [Install WebUI](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#install-the-webui) and 3) [Start the Server](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#start-the-webui-server) to install and start the Text Generation WebUI API Service. **Please pay attention to below items during installation:**
-- The Text Generation WebUI API service requires Python version 3.10 or higher. But [IPEX-LLM installation instructions](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#install-ipex-llm) used ``python=3.9`` as default for creating the conda environment. We recommend changing it to ``3.11``, using below command:
+- The Text Generation WebUI API service requires Python version 3.10 or higher. We recommend use Python 3.11 as below:
```bash
conda create -n llm python=3.11 libuv
```
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/index.rst b/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
index 1ed1aa2b..ea9df495 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
@@ -13,9 +13,10 @@ This section includes efficient guide to show you how to:
* `Install IPEX-LLM on Windows with Intel GPU <./install_windows_gpu.html>`_
* `Install IPEX-LLM in Docker on Windows with Intel GPU <./docker_windows_gpu.html>`_
* `Run Performance Benchmarking with IPEX-LLM <./benchmark_quickstart.html>`_
-* `Run Langchain-Chatchat (RAG Application) on Intel GPU <./chatchat_quickstart.html>`_
+* `Run Local RAG using Langchain-Chatchat on Intel GPU <./chatchat_quickstart.html>`_
* `Run Text Generation WebUI on Intel GPU <./webui_quickstart.html>`_
-* `Run Code Copilot (Continue) in VSCode with Intel GPU <./continue_quickstart.html>`_
+* `Run Open WebUI on Intel GPU <./open_webui_with_ollama_quickstart.html>`_
+* `Run Coding Copilot (Continue) in VSCode with Intel GPU <./continue_quickstart.html>`_
* `Run llama.cpp with IPEX-LLM on Intel GPU <./llama_cpp_quickstart.html>`_
* `Run Ollama with IPEX-LLM on Intel GPU <./ollama_quickstart.html>`_
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/install_linux_gpu.md b/docs/readthedocs/source/doc/LLM/Quickstart/install_linux_gpu.md
index 157e03f4..efcf95b1 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/install_linux_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/install_linux_gpu.md
@@ -144,7 +144,7 @@ You can use `conda --version` to verify you conda installation.
After installation, create a new python environment `llm`:
```cmd
-conda create -n llm python=3.9
+conda create -n llm python=3.11
```
Activate the newly created environment `llm`:
```cmd
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md b/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md
index 14439e70..6a0c2e78 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/install_windows_gpu.md
@@ -57,7 +57,7 @@ Visit [Miniconda installation page](https://docs.anaconda.com/free/miniconda/),
Open the **Anaconda Prompt**. Then create a new python environment `llm` and activate it:
```cmd
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
```
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
index 87a0c40c..4736b6dc 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
@@ -1,6 +1,6 @@
# Run llama.cpp with IPEX-LLM on Intel GPU
-[ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp) prvoides fast LLM inference in in pure C++ across a variety of hardware; you can now use the C++ interface of `ipex-llm` as an accelerated backend for `llama.cpp` running on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
+[ggerganov/llama.cpp](https://github.com/ggerganov/llama.cpp) prvoides fast LLM inference in in pure C++ across a variety of hardware; you can now use the C++ interface of [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) as an accelerated backend for `llama.cpp` running on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
See the demo of running LLaMA2-7B on Intel Arc GPU below.
@@ -26,7 +26,7 @@ Visit the [Install IPEX-LLM on Windows with Intel GPU Guide](https://ipex-llm.re
To use `llama.cpp` with IPEX-LLM, first ensure that `ipex-llm[cpp]` is installed.
```cmd
-conda create -n llm-cpp python=3.9
+conda create -n llm-cpp python=3.11
conda activate llm-cpp
pip install --pre --upgrade ipex-llm[cpp]
```
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
index 04a9fd9b..998dd2d8 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
@@ -1,10 +1,16 @@
# Run Ollama on Linux with Intel GPU
-The [ollama/ollama](https://github.com/ollama/ollama) is popular framework designed to build and run language models on a local machine. Now you can run Ollama with [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max); see the demo of running LLaMA2-7B on an Intel A770 GPU below.
+[ollama/ollama](https://github.com/ollama/ollama) is popular framework designed to build and run language models on a local machine; you can now use the C++ interface of [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) as an accelerated backend for `ollama` running on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
+
+```eval_rst
+.. note::
+ Only Linux is currently supported.
+```
+
+See the demo of running LLaMA2-7B on Intel Arc GPU below.
-
## Quickstart
### 1 Install IPEX-LLM with Ollama Binaries
@@ -45,16 +51,16 @@ source /opt/intel/oneapi/setvars.sh
The console will display messages similar to the following:
-
+
 ### 4 Pull Model
-Keep the Ollama service on and open a new terminal and pull a model, e.g. `dolphin-phi:latest`:
+Keep the Ollama service on and open another terminal and run `./ollama pull ` to automatically pull a model. e.g. `dolphin-phi:latest`:
-
+
### 4 Pull Model
-Keep the Ollama service on and open a new terminal and pull a model, e.g. `dolphin-phi:latest`:
+Keep the Ollama service on and open another terminal and run `./ollama pull ` to automatically pull a model. e.g. `dolphin-phi:latest`:
-
+
 @@ -77,7 +83,7 @@ curl http://localhost:11434/api/generate -d '
An example output of using model `doplphin-phi` looks like the following:
-
+
@@ -77,7 +83,7 @@ curl http://localhost:11434/api/generate -d '
An example output of using model `doplphin-phi` looks like the following:
-
+
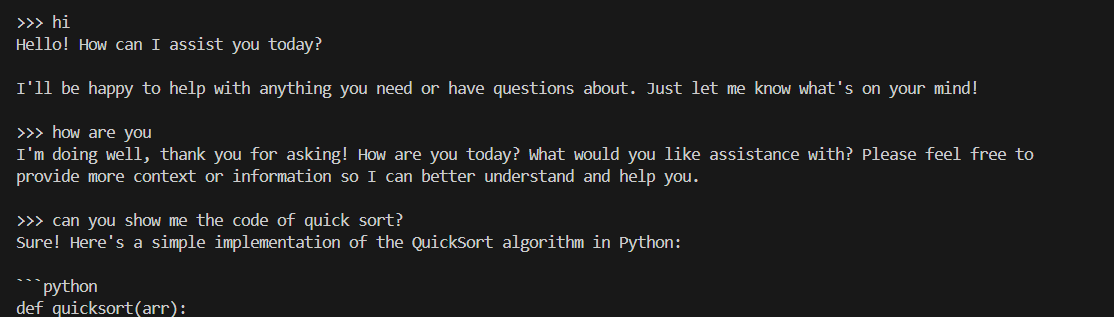
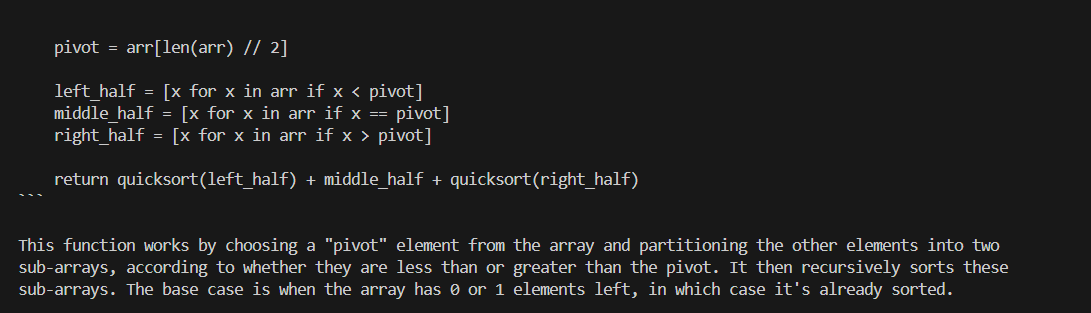
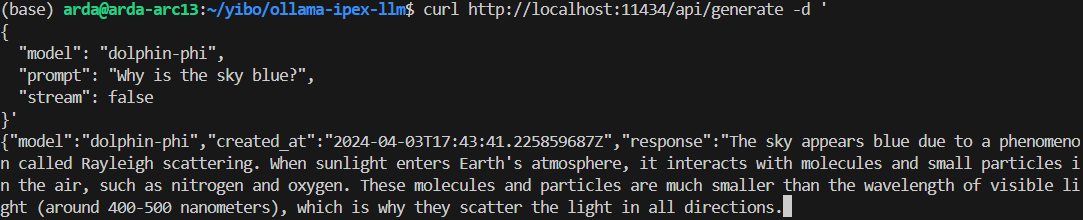 @@ -99,6 +105,6 @@ source /opt/intel/oneapi/setvars.sh
An example process of interacting with model with `ollama run` looks like the following:
-
+
@@ -99,6 +105,6 @@ source /opt/intel/oneapi/setvars.sh
An example process of interacting with model with `ollama run` looks like the following:
-
+
 diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.md
new file mode 100644
index 00000000..d6de90df
--- /dev/null
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.md
@@ -0,0 +1,151 @@
+# Run Open WebUI on Linux with Intel GPU
+
+[Open WebUI](https://github.com/open-webui/open-webui) is a user friendly GUI for running LLM locally; by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily run LLM in [Open WebUI](https://github.com/open-webui/open-webui) on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
+
+See the demo of running Mistral:7B on Intel Arc A770 below.
+
+
+
+## Quickstart
+
+This quickstart guide walks you through setting up and using [Open WebUI](https://github.com/open-webui/open-webui) with Ollama (using the C++ interface of [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) as an accelerated backend).
+
+
+### 1 Run Ollama on Linux with Intel GPU
+
+Follow the instructions on the [Run Ollama on Linux with Intel GPU](ollama_quickstart.html) to install and run "Ollam Serve". Please ensure that the Ollama server continues to run while you're using the Open WebUI.
+
+### 2 Install and Run Open-Webui
+
+
+#### Installation
+
+```eval_rst
+.. note::
+
+ Package version requirements for running Open WebUI: Node.js (>= 20.10) or Bun (>= 1.0.21), Python (>= 3.11)
+```
+
+1. Run below commands to install Node.js & npm. Once the installation is complete, verify the installation by running ```node -v``` and ```npm -v``` to check the versions of Node.js and npm, respectively.
+ ```sh
+ sudo apt update
+ sudo apt install nodejs
+ sudo apt install npm
+ ```
+
+2. Use `git` to clone the [open-webui repo](https://github.com/open-webui/open-webui.git), or download the open-webui source code zip from [this link](https://github.com/open-webui/open-webui/archive/refs/heads/main.zip) and unzip it to a directory, e.g. `~/open-webui`.
+
+3. Run below commands to install Open WebUI.
+ ```sh
+ cd ~/open-webui/
+ cp -RPp .env.example .env # Copy required .env file
+
+ # Build frontend
+ npm i
+ npm run build
+
+ # Install Dependencies
+ cd ./backend
+ pip install -r requirements.txt -U
+ ```
+
+#### Start the service
+
+Run below commands to start the service:
+
+```sh
+export no_proxy=localhost,127.0.0.1
+bash start.sh
+```
+
+
+```eval_rst
+.. note::
+
+ If you have difficulty accessing the huggingface repositories, you may use a mirror, e.g. add `export HF_ENDPOINT=https://hf-mirror.com` before running `bash start.sh`.
+```
+
+#### Access the WebUI
+Upon successful launch, URLs to access the WebUI will be displayed in the terminal. Open the provided local URL in your browser to interact with the WebUI, e.g. http://localhost:8080/.
+
+
+
+### 3. Using Open-Webui
+
+```eval_rst
+.. note::
+
+ For detailed information about how to use Open WebUI, visit the README of `open-webui official repository `_.
+
+```
+
+#### Log-in
+
+If this is your first time using it, you need to register. After registering, log in with the registered account to access the interface.
+
+
+
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.md
new file mode 100644
index 00000000..d6de90df
--- /dev/null
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.md
@@ -0,0 +1,151 @@
+# Run Open WebUI on Linux with Intel GPU
+
+[Open WebUI](https://github.com/open-webui/open-webui) is a user friendly GUI for running LLM locally; by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily run LLM in [Open WebUI](https://github.com/open-webui/open-webui) on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
+
+See the demo of running Mistral:7B on Intel Arc A770 below.
+
+
+
+## Quickstart
+
+This quickstart guide walks you through setting up and using [Open WebUI](https://github.com/open-webui/open-webui) with Ollama (using the C++ interface of [`ipex-llm`](https://github.com/intel-analytics/ipex-llm) as an accelerated backend).
+
+
+### 1 Run Ollama on Linux with Intel GPU
+
+Follow the instructions on the [Run Ollama on Linux with Intel GPU](ollama_quickstart.html) to install and run "Ollam Serve". Please ensure that the Ollama server continues to run while you're using the Open WebUI.
+
+### 2 Install and Run Open-Webui
+
+
+#### Installation
+
+```eval_rst
+.. note::
+
+ Package version requirements for running Open WebUI: Node.js (>= 20.10) or Bun (>= 1.0.21), Python (>= 3.11)
+```
+
+1. Run below commands to install Node.js & npm. Once the installation is complete, verify the installation by running ```node -v``` and ```npm -v``` to check the versions of Node.js and npm, respectively.
+ ```sh
+ sudo apt update
+ sudo apt install nodejs
+ sudo apt install npm
+ ```
+
+2. Use `git` to clone the [open-webui repo](https://github.com/open-webui/open-webui.git), or download the open-webui source code zip from [this link](https://github.com/open-webui/open-webui/archive/refs/heads/main.zip) and unzip it to a directory, e.g. `~/open-webui`.
+
+3. Run below commands to install Open WebUI.
+ ```sh
+ cd ~/open-webui/
+ cp -RPp .env.example .env # Copy required .env file
+
+ # Build frontend
+ npm i
+ npm run build
+
+ # Install Dependencies
+ cd ./backend
+ pip install -r requirements.txt -U
+ ```
+
+#### Start the service
+
+Run below commands to start the service:
+
+```sh
+export no_proxy=localhost,127.0.0.1
+bash start.sh
+```
+
+
+```eval_rst
+.. note::
+
+ If you have difficulty accessing the huggingface repositories, you may use a mirror, e.g. add `export HF_ENDPOINT=https://hf-mirror.com` before running `bash start.sh`.
+```
+
+#### Access the WebUI
+Upon successful launch, URLs to access the WebUI will be displayed in the terminal. Open the provided local URL in your browser to interact with the WebUI, e.g. http://localhost:8080/.
+
+
+
+### 3. Using Open-Webui
+
+```eval_rst
+.. note::
+
+ For detailed information about how to use Open WebUI, visit the README of `open-webui official repository `_.
+
+```
+
+#### Log-in
+
+If this is your first time using it, you need to register. After registering, log in with the registered account to access the interface.
+
+
+  +
+
+
+
+
+
+
+
+
+  +
+
+#### Configure `Ollama` service URL
+
+Access the Ollama settings through **Settings -> Connections** in the menu. By default, the **Ollama Base URL** is preset to https://localhost:11434, as illustrated in the snapshot below. To verify the status of the Ollama service connection, click the **Refresh button** located next to the textbox. If the WebUI is unable to establish a connection with the Ollama server, you will see an error message stating, `WebUI could not connect to Ollama`.
+
+
+
+
+
+
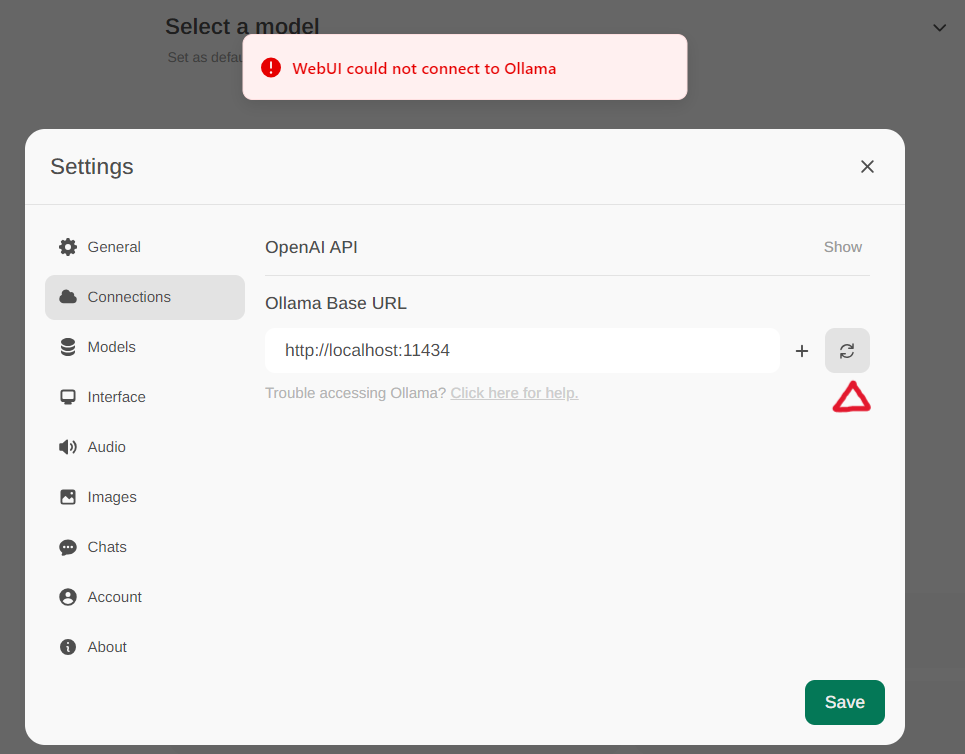
+#### Configure `Ollama` service URL
+
+Access the Ollama settings through **Settings -> Connections** in the menu. By default, the **Ollama Base URL** is preset to https://localhost:11434, as illustrated in the snapshot below. To verify the status of the Ollama service connection, click the **Refresh button** located next to the textbox. If the WebUI is unable to establish a connection with the Ollama server, you will see an error message stating, `WebUI could not connect to Ollama`.
+
+
+
+  +
+
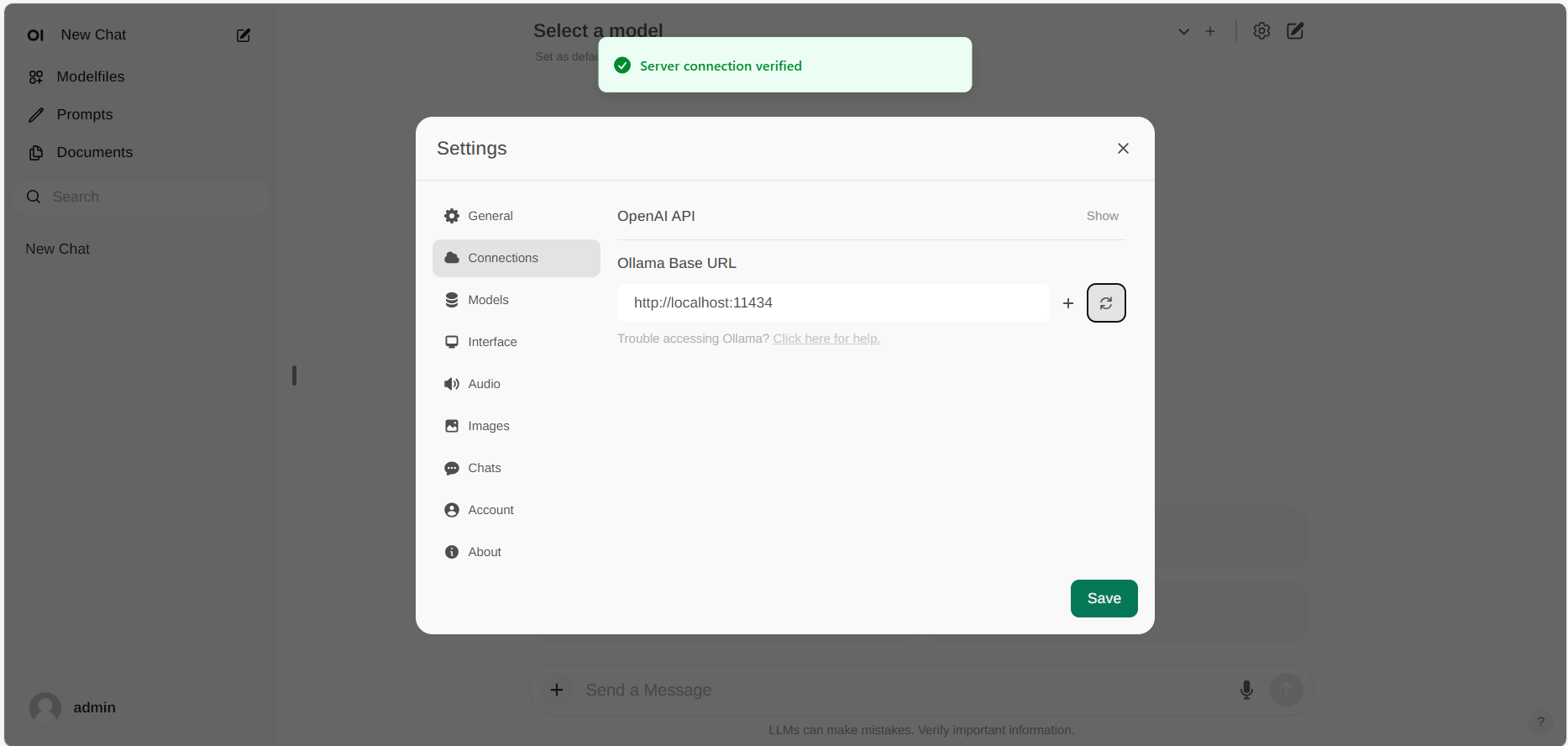
+If the connection is successful, you will see a message stating `Service Connection Verified`, as illustrated below.
+
+
+
+
+
+If the connection is successful, you will see a message stating `Service Connection Verified`, as illustrated below.
+
+
+  +
+
+```eval_rst
+.. note::
+
+ If you want to use an Ollama server hosted at a different URL, simply update the **Ollama Base URL** to the new URL and press the **Refresh** button to re-confirm the connection to Ollama.
+```
+
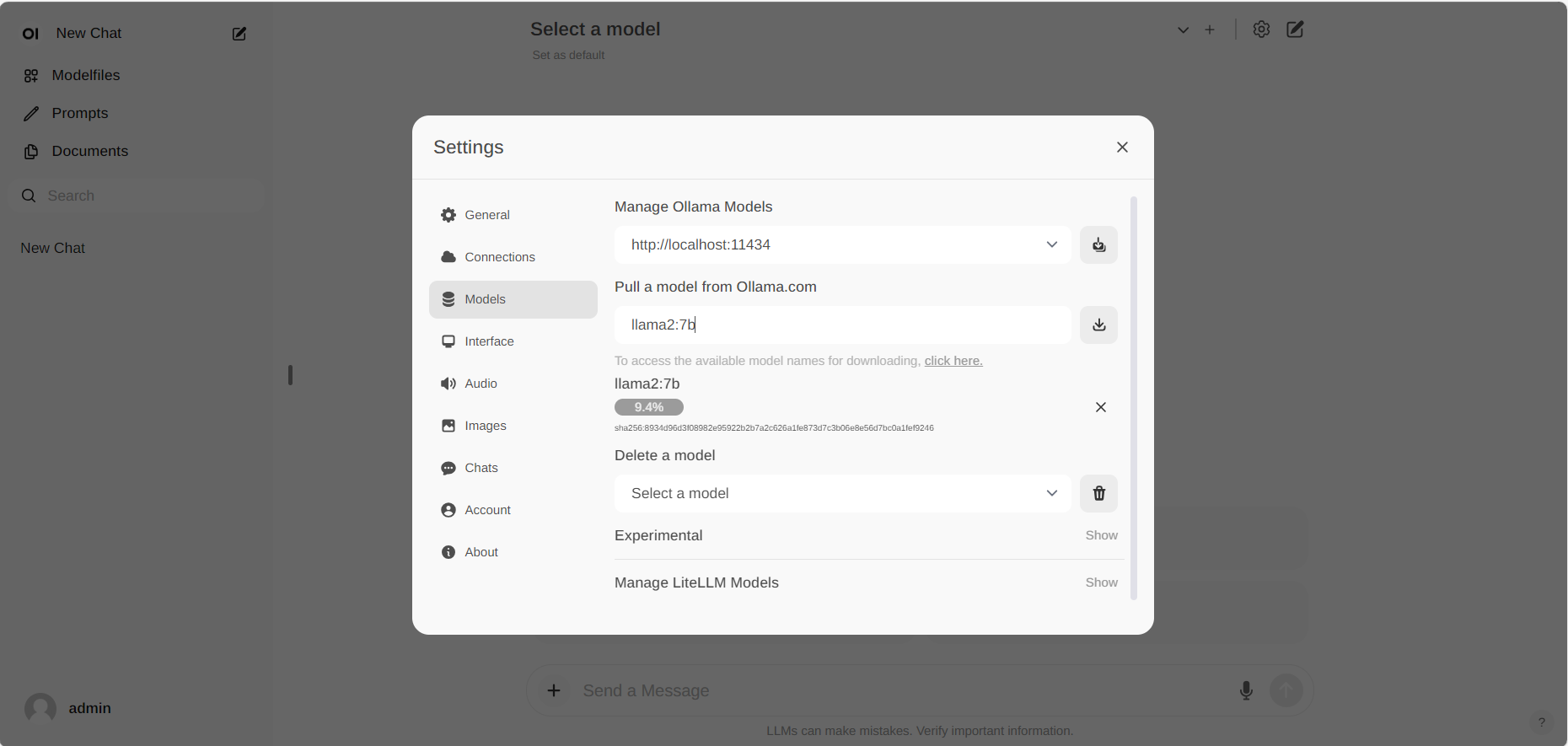
+#### Pull Model
+
+Go to **Settings -> Models** in the menu, choose a model under **Pull a model from Ollama.com** using the drop-down menu, and then hit the **Download** button on the right. Ollama will automatically download the selected model for you.
+
+
+
+
+
+```eval_rst
+.. note::
+
+ If you want to use an Ollama server hosted at a different URL, simply update the **Ollama Base URL** to the new URL and press the **Refresh** button to re-confirm the connection to Ollama.
+```
+
+#### Pull Model
+
+Go to **Settings -> Models** in the menu, choose a model under **Pull a model from Ollama.com** using the drop-down menu, and then hit the **Download** button on the right. Ollama will automatically download the selected model for you.
+
+
+  +
+
+#### Chat with the Model
+
+Start new conversations with **New chat** in the left-side menu.
+
+On the right-side, choose a downloaded model from the **Select a model** drop-down menu at the top, input your questions into the **Send a Message** textbox at the bottom, and click the button on the right to get responses.
+
+
+
+
+
+#### Chat with the Model
+
+Start new conversations with **New chat** in the left-side menu.
+
+On the right-side, choose a downloaded model from the **Select a model** drop-down menu at the top, input your questions into the **Send a Message** textbox at the bottom, and click the button on the right to get responses.
+
+
+  +
+
+
+
+
+
+
+
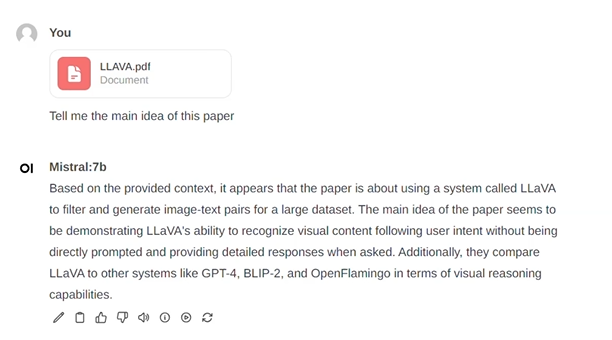
+Additionally, you can drag and drop a document into the textbox, allowing the LLM to access its contents. The LLM will then generate answers based on the document provided.
+
+
+  +
+
+#### Exit Open-Webui
+
+To shut down the open-webui server, use **Ctrl+C** in the terminal where the open-webui server is runing, then close your browser tab.
+
+
+### 4. Troubleshooting
+
+##### Error `No module named 'torch._C`
+
+When you encounter the error ``ModuleNotFoundError: No module named 'torch._C'`` after executing ```bash start.sh```, you can resolve it by reinstalling PyTorch. First, use ```pip uninstall torch``` to remove the existing PyTorch installation, and then reinstall it along with its dependencies by running ```pip install torch torchvision torchaudio```.
diff --git a/docs/readthedocs/source/index.rst b/docs/readthedocs/source/index.rst
index 086ffe75..efe4728f 100644
--- a/docs/readthedocs/source/index.rst
+++ b/docs/readthedocs/source/index.rst
@@ -33,7 +33,7 @@
It is built on top of Intel Extension for PyTorch (
+
+
+#### Exit Open-Webui
+
+To shut down the open-webui server, use **Ctrl+C** in the terminal where the open-webui server is runing, then close your browser tab.
+
+
+### 4. Troubleshooting
+
+##### Error `No module named 'torch._C`
+
+When you encounter the error ``ModuleNotFoundError: No module named 'torch._C'`` after executing ```bash start.sh```, you can resolve it by reinstalling PyTorch. First, use ```pip uninstall torch``` to remove the existing PyTorch installation, and then reinstall it along with its dependencies by running ```pip install torch torchvision torchaudio```.
diff --git a/docs/readthedocs/source/index.rst b/docs/readthedocs/source/index.rst
index 086ffe75..efe4728f 100644
--- a/docs/readthedocs/source/index.rst
+++ b/docs/readthedocs/source/index.rst
@@ -33,7 +33,7 @@
It is built on top of Intel Extension for PyTorch (IPEX), as well as the excellent work of llama.cpp, bitsandbytes, vLLM, qlora, AutoGPTQ, AutoAWQ, etc.
- It provides seamless integration with llama.cpp, Text-Generation-WebUI, HuggingFace transformers, HuggingFace PEFT, LangChain, LlamaIndex, DeepSpeed-AutoTP, vLLM, FastChat, HuggingFace TRL, AutoGen, ModeScope, etc.
+ It provides seamless integration with llama.cpp, ollama, Text-Generation-WebUI, HuggingFace transformers, HuggingFace PEFT, LangChain, LlamaIndex, DeepSpeed-AutoTP, vLLM, FastChat, HuggingFace TRL, AutoGen, ModeScope, etc.
50+ models have been optimized/verified on ipex-llm (including LLaMA2, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM, Baichuan, Qwen, RWKV, and more); see the complete list here.
@@ -44,6 +44,8 @@
************************************************
Latest update 🔥
************************************************
+
+* [2024/04] ``ipex-llm`` now provides C++ interface, which can be used as an accelerated backend for running `llama.cpp `_ and `ollama `_ on Intel GPU.
* [2024/03] ``bigdl-llm`` has now become ``ipex-llm`` (see the migration guide `here `_); you may find the original ``BigDL`` project `here `_.
* [2024/02] ``ipex-llm`` now supports directly loading model from `ModelScope `_ (`魔搭 `_).
* [2024/02] ``ipex-llm`` added inital **INT2** support (based on llama.cpp `IQ2 `_ mechanism), which makes it possible to run large-size LLM (e.g., Mixtral-8x7B) on Intel GPU with 16GB VRAM.
@@ -106,6 +108,10 @@ See the **optimized performance** of ``chatglm2-6b`` and ``llama-2-13b-chat`` mo
``ipex-llm`` Quickstart
************************************************
+============================================
+Install ``ipex-llm``
+============================================
+
* `Windows GPU `_: installing ``ipex-llm`` on Windows with Intel GPU
* `Linux GPU `_: installing ``ipex-llm`` on Linux with Intel GPU
* `Docker `_: using ``ipex-llm`` dockers on Intel CPU and GPU
@@ -118,7 +124,8 @@ See the **optimized performance** of ``chatglm2-6b`` and ``llama-2-13b-chat`` mo
Run ``ipex-llm``
============================================
-* `llama.cpp `_: running **ipex-llm for llama.cpp** (*using C++ interface of* ``ipex-llm`` *as an accelerated backend for* ``llama.cpp`` *on Intel GPU*)
+* `llama.cpp `_: running **llama.cpp** (*using C++ interface of* ``ipex-llm`` *as an accelerated backend for* ``llama.cpp``) on Intel GPU
+* `ollama `_: running **ollama** (*using C++ interface of* ``ipex-llm`` *as an accelerated backend for* ``ollama``) on Intel GPU
* `vLLM `_: running ``ipex-llm`` in ``vLLM`` on both Intel `GPU `_ and `CPU `_
* `FastChat `_: running ``ipex-llm`` in ``FastChat`` serving on on both Intel GPU and CPU
* `LangChain-Chatchat RAG `_: running ``ipex-llm`` in ``LangChain-Chatchat`` (*Knowledge Base QA using* **RAG** *pipeline*)
diff --git a/python/llm/dev/benchmark/harness/README.md b/python/llm/dev/benchmark/harness/README.md
index 4dfcf09a..50ec4b86 100644
--- a/python/llm/dev/benchmark/harness/README.md
+++ b/python/llm/dev/benchmark/harness/README.md
@@ -30,6 +30,6 @@ Taking example above, the script will fork 3 processes, each for one xpu, to exe
## Results
We follow [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) to record our metrics, `acc_norm` for `hellaswag` and `arc_challenge`, `mc2` for `truthful_qa` and `acc` for `mmlu`. For `mmlu`, there are 57 subtasks which means users may need to average them manually to get final result.
## Summarize the results
-"""python
+```python
python make_table.py
-"""
\ No newline at end of file
+```
diff --git a/python/llm/dev/benchmark/harness/harness_to_leaderboard.py b/python/llm/dev/benchmark/harness/harness_to_leaderboard.py
index 82cdc341..5dd04b9a 100644
--- a/python/llm/dev/benchmark/harness/harness_to_leaderboard.py
+++ b/python/llm/dev/benchmark/harness/harness_to_leaderboard.py
@@ -48,7 +48,7 @@ task_to_metric = dict(
drop='f1'
)
-def parse_precision(precision, model="bigdl-llm"):
+def parse_precision(precision, model="ipex-llm"):
result = match(r"([a-zA-Z_]+)(\d+)([a-zA-Z_\d]*)", precision)
datatype = result.group(1)
bit = int(result.group(2))
@@ -62,6 +62,6 @@ def parse_precision(precision, model="bigdl-llm"):
else:
if model == "hf-causal":
return f"bnb_type={precision}"
- if model == "bigdl-llm":
+ if model == "ipex-llm":
return f"load_in_low_bit={precision}"
raise RuntimeError(f"invald precision {precision}")
diff --git a/python/llm/dev/benchmark/harness/bigdl_llm.py b/python/llm/dev/benchmark/harness/ipexllm.py
similarity index 98%
rename from python/llm/dev/benchmark/harness/bigdl_llm.py
rename to python/llm/dev/benchmark/harness/ipexllm.py
index 8626fc1a..0049f1e4 100644
--- a/python/llm/dev/benchmark/harness/bigdl_llm.py
+++ b/python/llm/dev/benchmark/harness/ipexllm.py
@@ -35,7 +35,7 @@ def force_decrease_order(Reorderer):
utils.Reorderer = force_decrease_order(utils.Reorderer)
-class BigDLLM(AutoCausalLM):
+class IPEXLLM(AutoCausalLM):
AUTO_MODEL_CLASS = AutoModelForCausalLM
AutoCausalLM_ARGS = inspect.getfullargspec(AutoCausalLM.__init__).args
def __init__(self, *args, **kwargs):
diff --git a/python/llm/dev/benchmark/harness/run_llb.py b/python/llm/dev/benchmark/harness/run_llb.py
index 3e8bd03a..a3ab55b0 100644
--- a/python/llm/dev/benchmark/harness/run_llb.py
+++ b/python/llm/dev/benchmark/harness/run_llb.py
@@ -20,8 +20,8 @@ import os
from harness_to_leaderboard import *
from lm_eval import tasks, evaluator, utils, models
-from bigdl_llm import BigDLLM
-models.MODEL_REGISTRY['bigdl-llm'] = BigDLLM # patch bigdl-llm to harness
+from ipexllm import IPEXLLM
+models.MODEL_REGISTRY['ipex-llm'] = IPEXLLM # patch ipex-llm to harness
logging.getLogger("openai").setLevel(logging.WARNING)
diff --git a/python/llm/dev/benchmark/harness/run_multi_llb.py b/python/llm/dev/benchmark/harness/run_multi_llb.py
index 77596b6d..7f4b2df3 100644
--- a/python/llm/dev/benchmark/harness/run_multi_llb.py
+++ b/python/llm/dev/benchmark/harness/run_multi_llb.py
@@ -22,8 +22,9 @@ from lm_eval import tasks, evaluator, utils, models
from multiprocessing import Queue, Process
import multiprocessing as mp
from contextlib import redirect_stdout, redirect_stderr
-from bigdl_llm import BigDLLM
-models.MODEL_REGISTRY['bigdl-llm'] = BigDLLM # patch bigdl-llm to harness
+
+from ipexllm import IPEXLLM
+models.MODEL_REGISTRY['ipex-llm'] = IPEXLLM # patch ipex-llm to harness
logging.getLogger("openai").setLevel(logging.WARNING)
diff --git a/python/llm/dev/benchmark/perplexity/README.md b/python/llm/dev/benchmark/perplexity/README.md
index bdee4593..bcf42ff4 100644
--- a/python/llm/dev/benchmark/perplexity/README.md
+++ b/python/llm/dev/benchmark/perplexity/README.md
@@ -20,6 +20,6 @@ python run.py --model_path meta-llama/Llama-2-7b-chat-hf --precisions float16 sy
- If you want to test perplexity on pre-downloaded datasets, please specify the `` in the `dataset_path` argument in your command.
## Summarize the results
-"""python
+```python
python make_table.py
-"""
\ No newline at end of file
+```
diff --git a/python/llm/example/CPU/Applications/autogen/README.md b/python/llm/example/CPU/Applications/autogen/README.md
index ceb9fd7a..de045510 100644
--- a/python/llm/example/CPU/Applications/autogen/README.md
+++ b/python/llm/example/CPU/Applications/autogen/README.md
@@ -11,7 +11,7 @@ mkdir autogen
cd autogen
# create respective conda environment
-conda create -n autogen python=3.9
+conda create -n autogen python=3.11
conda activate autogen
# install fastchat-adapted ipex-llm
diff --git a/python/llm/example/CPU/Applications/hf-agent/README.md b/python/llm/example/CPU/Applications/hf-agent/README.md
index edbae072..455f10ed 100644
--- a/python/llm/example/CPU/Applications/hf-agent/README.md
+++ b/python/llm/example/CPU/Applications/hf-agent/README.md
@@ -10,7 +10,7 @@ To run this example with IPEX-LLM, we have some recommended requirements for you
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/Applications/streaming-llm/README.md b/python/llm/example/CPU/Applications/streaming-llm/README.md
index a008b1d2..571f51a3 100644
--- a/python/llm/example/CPU/Applications/streaming-llm/README.md
+++ b/python/llm/example/CPU/Applications/streaming-llm/README.md
@@ -10,7 +10,7 @@ model = AutoModelForCausalLM.from_pretrained(model_name_or_path, load_in_4bit=Tr
## Prepare Environment
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
diff --git a/python/llm/example/CPU/Deepspeed-AutoTP/README.md b/python/llm/example/CPU/Deepspeed-AutoTP/README.md
index ed738567..45256563 100644
--- a/python/llm/example/CPU/Deepspeed-AutoTP/README.md
+++ b/python/llm/example/CPU/Deepspeed-AutoTP/README.md
@@ -2,7 +2,7 @@
#### 1. Install Dependencies
-Install necessary packages (here Python 3.9 is our test environment):
+Install necessary packages (here Python 3.11 is our test environment):
```bash
bash install.sh
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/AWQ/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/AWQ/README.md
index cecbe84a..b3078cbd 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/AWQ/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/AWQ/README.md
@@ -34,7 +34,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a AWQ
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install autoawq==0.1.8 --no-deps
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF/README.md
index 33c28850..4741e604 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF/README.md
@@ -25,7 +25,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/GPTQ/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/GPTQ/README.md
index d91f997e..139fa014 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/GPTQ/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Advanced-Quantizations/GPTQ/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Llam
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila/README.md
index 63468b19..8b3cfbf3 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila/README.md
@@ -16,7 +16,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila2/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila2/README.md
index 50e7b83d..fd06613c 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila2/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila2/README.md
@@ -16,7 +16,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan/README.md
index b7ed859e..6b8d421d 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Baic
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan2/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan2/README.md
index e5d9a1aa..e9e28200 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan2/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan2/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Baic
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/bluelm/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/bluelm/README.md
index addec52f..328a86b7 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/bluelm/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/bluelm/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Blue
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm/README.md
index d56d070e..9f79516b 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm/README.md
@@ -16,10 +16,11 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
+pip install "transformers<4.34.1" # chatglm cannot work with transformers 4.34.1+
```
### 2. Run
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm2/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm2/README.md
index 54acc3b6..8a99eebe 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm2/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm2/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Chat
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
@@ -80,7 +80,7 @@ In the example [streamchat.py](./streamchat.py), we show a basic use case for a
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm3/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm3/README.md
index 966f0894..4b5f2174 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm3/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm3/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Chat
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install ipex-llm with 'all' option
@@ -81,7 +81,7 @@ In the example [streamchat.py](./streamchat.py), we show a basic use case for a
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codellama/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codellama/README.md
index be3687cf..10035051 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codellama/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codellama/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Code
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codeshell/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codeshell/README.md
index 59c935c5..a3399ab8 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codeshell/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codeshell/README.md
@@ -16,7 +16,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deciLM-7b/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deciLM-7b/README.md
index 420627c5..ac818695 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deciLM-7b/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deciLM-7b/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Deci
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deepseek-moe/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deepseek-moe/README.md
index ece21c6f..3fd87ae7 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deepseek-moe/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deepseek-moe/README.md
@@ -16,7 +16,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deepseek/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deepseek/README.md
index 232ca8be..e38600b7 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deepseek/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/deepseek/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Deep
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/distil-whisper/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/distil-whisper/README.md
index 882671c6..92d863b1 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/distil-whisper/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/distil-whisper/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/dolly_v1/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/dolly_v1/README.md
index d59677ba..1e599b4e 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/dolly_v1/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/dolly_v1/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Doll
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/dolly_v2/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/dolly_v2/README.md
index 219e13ee..b06f61cc 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/dolly_v2/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/dolly_v2/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Doll
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/falcon/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/falcon/README.md
index 20a19a76..ca7b5f45 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/falcon/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/falcon/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Falc
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/flan-t5/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/flan-t5/README.md
index 2d102180..2daa684f 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/flan-t5/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/flan-t5/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/fuyu/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/fuyu/README.md
index e54a8546..8bf15bd1 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/fuyu/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/fuyu/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/gemma/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/gemma/README.md
index 548529c8..c8572e04 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/gemma/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/gemma/README.md
@@ -14,7 +14,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -27,7 +27,7 @@ pip install transformers==4.38.1
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm-xcomposer/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm-xcomposer/README.md
index cb898b32..97235dd6 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm-xcomposer/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm-xcomposer/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm/README.md
index b37e342c..e994db9e 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Inte
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm2/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm2/README.md
index c7d8022a..01f399b9 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm2/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm2/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Inte
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama2/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama2/README.md
index 191102eb..68415979 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama2/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama2/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Llam
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mistral/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mistral/README.md
index 40fbd43d..d27fc1e7 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mistral/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mistral/README.md
@@ -13,7 +13,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mixtral/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mixtral/README.md
index edd46b62..0f9ce865 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mixtral/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mixtral/README.md
@@ -13,7 +13,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install PyTorch CPU as default
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/moss/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/moss/README.md
index a0eeeccb..0355daa9 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/moss/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/moss/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a MOSS
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mpt/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mpt/README.md
index e70aa2ac..5efb7172 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mpt/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/mpt/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for an MPT
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phi-1_5/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phi-1_5/README.md
index 7d9ece5b..e92d306b 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phi-1_5/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phi-1_5/README.md
@@ -16,7 +16,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phi-2/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phi-2/README.md
index caf033f3..10cebf03 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phi-2/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phi-2/README.md
@@ -16,7 +16,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phixtral/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phixtral/README.md
index 918c081a..2696aeb3 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phixtral/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phixtral/README.md
@@ -16,7 +16,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phoenix/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phoenix/README.md
index 601eb997..9b162d2f 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phoenix/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/phoenix/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Phoe
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen-vl/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen-vl/README.md
index bd1b66d4..16f5243c 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen-vl/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen-vl/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen/README.md
index ce689b6f..c94d76a3 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen/README.md
@@ -15,7 +15,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Qwen
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen1.5/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen1.5/README.md
index 52037de5..e4043709 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen1.5/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen1.5/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Qwen
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/redpajama/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/redpajama/README.md
index 0692286f..0e9e0c38 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/redpajama/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/redpajama/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a RedP
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/replit/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/replit/README.md
index 0ce3bbed..285b8040 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/replit/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/replit/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/skywork/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/skywork/README.md
index 53b790f2..75f81fd8 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/skywork/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/skywork/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Skyw
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/solar/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/solar/README.md
index cdfe9b8f..51c1a6b6 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/solar/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/solar/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a SOLA
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/stablelm/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/stablelm/README.md
index 5d99e902..d3e9854a 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/stablelm/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/stablelm/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/starcoder/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/starcoder/README.md
index d81e438b..20cc936f 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/starcoder/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/starcoder/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for an Sta
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/vicuna/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/vicuna/README.md
index 89604bc6..9ed7ac15 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/vicuna/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/vicuna/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Vicu
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/whisper/readme.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/whisper/readme.md
index d2e957e6..29f72a29 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/whisper/readme.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/whisper/readme.md
@@ -10,7 +10,7 @@ In the example [recognize.py](./recognize.py), we show a basic use case for a Wh
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
@@ -66,7 +66,7 @@ In the example [long-segment-recognize.py](./long-segment-recognize.py), we show
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/wizardcoder-python/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/wizardcoder-python/README.md
index 25d6f20e..1801214a 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/wizardcoder-python/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/wizardcoder-python/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Wiza
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/yi/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/yi/README.md
index 2205a4af..829af83f 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/yi/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/yi/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/yuan2/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/yuan2/README.md
index 05f7a32f..96c08614 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/yuan2/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/yuan2/README.md
@@ -13,7 +13,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/ziya/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/ziya/README.md
index 2dfb7adc..9d1fa08c 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/ziya/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/ziya/README.md
@@ -16,7 +16,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/More-Data-Types/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/More-Data-Types/README.md
index d5dc789c..93284b2e 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/More-Data-Types/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/More-Data-Types/README.md
@@ -5,7 +5,7 @@ In this example, we show a pipeline to apply IPEX-LLM low-bit optimizations (inc
## Prepare Environment
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Save-Load/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Save-Load/README.md
index d5dc789c..93284b2e 100644
--- a/python/llm/example/CPU/HF-Transformers-AutoModels/Save-Load/README.md
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Save-Load/README.md
@@ -5,7 +5,7 @@ In this example, we show a pipeline to apply IPEX-LLM low-bit optimizations (inc
## Prepare Environment
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
diff --git a/python/llm/example/CPU/ModelScope-Models/README.md b/python/llm/example/CPU/ModelScope-Models/README.md
index 8be1159d..d416a8ea 100644
--- a/python/llm/example/CPU/ModelScope-Models/README.md
+++ b/python/llm/example/CPU/ModelScope-Models/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Chat
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/Native-Models/README.md b/python/llm/example/CPU/Native-Models/README.md
index 8a181ce6..1a2d80a8 100644
--- a/python/llm/example/CPU/Native-Models/README.md
+++ b/python/llm/example/CPU/Native-Models/README.md
@@ -7,7 +7,7 @@ In this example, we show a pipeline to convert a large language model to IPEX-LL
## Prepare Environment
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/aquila2/README.md b/python/llm/example/CPU/PyTorch-Models/Model/aquila2/README.md
index 67189d60..2c9cd008 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/aquila2/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/aquila2/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/bark/README.md b/python/llm/example/CPU/PyTorch-Models/Model/bark/README.md
index 5800acae..ba4f4282 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/bark/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/bark/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/bert/README.md b/python/llm/example/CPU/PyTorch-Models/Model/bert/README.md
index 2bbbe626..5bfe4e00 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/bert/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/bert/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/bluelm/README.md b/python/llm/example/CPU/PyTorch-Models/Model/bluelm/README.md
index 437d9834..a68f2cb8 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/bluelm/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/bluelm/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/chatglm/README.md b/python/llm/example/CPU/PyTorch-Models/Model/chatglm/README.md
index 35a15620..bd5a3167 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/chatglm/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/chatglm/README.md
@@ -11,10 +11,11 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
+pip install "transformers<4.34.1" # chatglm cannot work with transformers 4.34.1+
```
### 2. Run
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/chatglm3/README.md b/python/llm/example/CPU/PyTorch-Models/Model/chatglm3/README.md
index 195fb0ee..3ee550a4 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/chatglm3/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/chatglm3/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/codellama/README.md b/python/llm/example/CPU/PyTorch-Models/Model/codellama/README.md
index a97c5bb8..9915ffd9 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/codellama/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/codellama/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/codeshell/README.md b/python/llm/example/CPU/PyTorch-Models/Model/codeshell/README.md
index 1870c4de..dff6f8e8 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/codeshell/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/codeshell/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/deciLM-7b/README.md b/python/llm/example/CPU/PyTorch-Models/Model/deciLM-7b/README.md
index 15dca0bd..bf92a5b6 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/deciLM-7b/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/deciLM-7b/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/deepseek-moe/README.md b/python/llm/example/CPU/PyTorch-Models/Model/deepseek-moe/README.md
index feca7acf..fa9b9945 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/deepseek-moe/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/deepseek-moe/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/deepseek/README.md b/python/llm/example/CPU/PyTorch-Models/Model/deepseek/README.md
index bbbb304e..9e86fa27 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/deepseek/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/deepseek/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/distil-whisper/README.md b/python/llm/example/CPU/PyTorch-Models/Model/distil-whisper/README.md
index 56efd231..ff777d77 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/distil-whisper/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/distil-whisper/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/flan-t5/README.md b/python/llm/example/CPU/PyTorch-Models/Model/flan-t5/README.md
index 2d102180..2daa684f 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/flan-t5/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/flan-t5/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/fuyu/README.md b/python/llm/example/CPU/PyTorch-Models/Model/fuyu/README.md
index e54a8546..8bf15bd1 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/fuyu/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/fuyu/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/internlm-xcomposer/README.md b/python/llm/example/CPU/PyTorch-Models/Model/internlm-xcomposer/README.md
index cedaab04..eda342d8 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/internlm-xcomposer/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/internlm-xcomposer/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/internlm2/README.md b/python/llm/example/CPU/PyTorch-Models/Model/internlm2/README.md
index 7e55c5f3..f8c1ff8c 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/internlm2/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/internlm2/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/llama2/README.md b/python/llm/example/CPU/PyTorch-Models/Model/llama2/README.md
index a630cc0c..2227e0dc 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/llama2/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/llama2/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/llava/README.md b/python/llm/example/CPU/PyTorch-Models/Model/llava/README.md
index d9b2b853..0dde00f1 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/llava/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/llava/README.md
@@ -12,15 +12,17 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
-
-git clone -b v1.1.1 --depth=1 https://github.com/haotian-liu/LLaVA.git # clone the llava libary
pip install einops # install dependencies required by llava
+pip install transformers==4.36.2
+
+git clone https://github.com/haotian-liu/LLaVA.git # clone the llava libary
cp generate.py ./LLaVA/ # copy our example to the LLaVA folder
cd LLaVA # change the working directory to the LLaVA folder
+git checkout tags/v1.2.0 -b 1.2.0 # Get the branch which is compatible with transformers 4.36
```
### 2. Run
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/llava/generate.py b/python/llm/example/CPU/PyTorch-Models/Model/llava/generate.py
index 5f3316e3..780ba963 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/llava/generate.py
+++ b/python/llm/example/CPU/PyTorch-Models/Model/llava/generate.py
@@ -39,6 +39,7 @@ import time
from transformers import AutoModelForCausalLM
from llava.model.language_model.llava_llama import LlavaLlamaForCausalLM
from transformers import AutoTokenizer
+from transformers import TextStreamer
from llava.constants import (
DEFAULT_IMAGE_PATCH_TOKEN,
@@ -311,11 +312,14 @@ if __name__ == '__main__':
print("exit...")
break
+ print(f"{roles[1]}: ", end="")
+
prompt = get_prompt(model.config.mm_use_im_start_end, first_round, conv, user_input)
first_round = False
input_ids = tokenizer_image_token(
prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0)
stopping_criteria = get_stopping_criteria(conv, tokenizer, input_ids)
+ streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
# Generate predicted tokens
with torch.inference_mode():
@@ -325,13 +329,11 @@ if __name__ == '__main__':
images=image_tensor,
do_sample=True,
max_new_tokens=args.n_predict,
+ streamer=streamer,
use_cache=True,
stopping_criteria=[stopping_criteria])
end = time.time()
#print(f'Inference time: {end-st} s')
- outputs = tokenizer.decode(
- output_ids[0, input_ids.shape[1]:], skip_special_tokens=True).strip()
+ outputs = tokenizer.decode(output_ids[0, :], skip_special_tokens=True).strip()
conv.messages[-1][-1] = outputs
- print(f"{roles[1]}: ", end="")
- print(outputs)
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/mamba/README.md b/python/llm/example/CPU/PyTorch-Models/Model/mamba/README.md
index d649ffdb..5950791f 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/mamba/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/mamba/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/meta-llama/README.md b/python/llm/example/CPU/PyTorch-Models/Model/meta-llama/README.md
index e3c040fa..4c0ccb20 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/meta-llama/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/meta-llama/README.md
@@ -10,7 +10,7 @@ In the example [example_chat_completion.py](./example_chat_completion.py), we sh
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# Install meta-llama repository
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/mistral/README.md b/python/llm/example/CPU/PyTorch-Models/Model/mistral/README.md
index 1f958267..8a4adbcd 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/mistral/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/mistral/README.md
@@ -13,7 +13,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/mixtral/README.md b/python/llm/example/CPU/PyTorch-Models/Model/mixtral/README.md
index 7baa9a4c..bc8ee08e 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/mixtral/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/mixtral/README.md
@@ -13,7 +13,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install PyTorch CPU as default
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/openai-whisper/readme.md b/python/llm/example/CPU/PyTorch-Models/Model/openai-whisper/readme.md
index 85f6594a..a1def711 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/openai-whisper/readme.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/openai-whisper/readme.md
@@ -10,7 +10,7 @@ In the example [recognize.py](./recognize.py), we show a basic use case for a Wh
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/phi-1_5/README.md b/python/llm/example/CPU/PyTorch-Models/Model/phi-1_5/README.md
index 236cee37..3b4dfac1 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/phi-1_5/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/phi-1_5/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/phi-2/README.md b/python/llm/example/CPU/PyTorch-Models/Model/phi-2/README.md
index c9e8daaf..81355b62 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/phi-2/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/phi-2/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/phixtral/README.md b/python/llm/example/CPU/PyTorch-Models/Model/phixtral/README.md
index c3a19031..9f824fad 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/phixtral/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/phixtral/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/qwen-vl/README.md b/python/llm/example/CPU/PyTorch-Models/Model/qwen-vl/README.md
index 57ccdf71..0e2c21cf 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/qwen-vl/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/qwen-vl/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/qwen1.5/README.md b/python/llm/example/CPU/PyTorch-Models/Model/qwen1.5/README.md
index a404cf03..095ee001 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/qwen1.5/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/qwen1.5/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/skywork/README.md b/python/llm/example/CPU/PyTorch-Models/Model/skywork/README.md
index 1221f2a3..b1b21407 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/skywork/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/skywork/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/solar/README.md b/python/llm/example/CPU/PyTorch-Models/Model/solar/README.md
index 0625fb2f..44c2ae4b 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/solar/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/solar/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/stablelm/README.md b/python/llm/example/CPU/PyTorch-Models/Model/stablelm/README.md
index 6332f063..8934e3f8 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/stablelm/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/stablelm/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/wizardcoder-python/README.md b/python/llm/example/CPU/PyTorch-Models/Model/wizardcoder-python/README.md
index 7cfa8d11..e4f99c47 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/wizardcoder-python/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/wizardcoder-python/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/yi/README.md b/python/llm/example/CPU/PyTorch-Models/Model/yi/README.md
index cb4d06a9..89adf93a 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/yi/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/yi/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/yuan2/README.md b/python/llm/example/CPU/PyTorch-Models/Model/yuan2/README.md
index c268f7a3..3627e815 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/yuan2/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/yuan2/README.md
@@ -13,7 +13,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/ziya/README.md b/python/llm/example/CPU/PyTorch-Models/Model/ziya/README.md
index 2a77221a..79ac293d 100644
--- a/python/llm/example/CPU/PyTorch-Models/Model/ziya/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Model/ziya/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/More-Data-Types/README.md b/python/llm/example/CPU/PyTorch-Models/More-Data-Types/README.md
index 461cb983..4bbfb55e 100644
--- a/python/llm/example/CPU/PyTorch-Models/More-Data-Types/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/More-Data-Types/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case of low-bit
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/PyTorch-Models/Save-Load/README.md b/python/llm/example/CPU/PyTorch-Models/Save-Load/README.md
index ae8c0302..f3bbb5cf 100644
--- a/python/llm/example/CPU/PyTorch-Models/Save-Load/README.md
+++ b/python/llm/example/CPU/PyTorch-Models/Save-Load/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case of saving/
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install ipex-llm with 'all' option
diff --git a/python/llm/example/CPU/QLoRA-FineTuning/README.md b/python/llm/example/CPU/QLoRA-FineTuning/README.md
index 33543c12..88106180 100644
--- a/python/llm/example/CPU/QLoRA-FineTuning/README.md
+++ b/python/llm/example/CPU/QLoRA-FineTuning/README.md
@@ -16,7 +16,7 @@ This example is ported from [bnb-4bit-training](https://colab.research.google.co
### 1. Install
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
pip install transformers==4.34.0
diff --git a/python/llm/example/CPU/QLoRA-FineTuning/alpaca-qlora/README.md b/python/llm/example/CPU/QLoRA-FineTuning/alpaca-qlora/README.md
index edd4d08d..a3d0ba36 100644
--- a/python/llm/example/CPU/QLoRA-FineTuning/alpaca-qlora/README.md
+++ b/python/llm/example/CPU/QLoRA-FineTuning/alpaca-qlora/README.md
@@ -5,7 +5,7 @@ This example ports [Alpaca-LoRA](https://github.com/tloen/alpaca-lora/tree/main)
### 1. Install
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
pip install datasets transformers==4.35.0
@@ -60,7 +60,7 @@ pip install oneccl_bind_pt --extra-index-url https://developer.intel.com/ipex-wh
2. modify conf in `finetune_one_node_two_sockets.sh` and run
```
-source ${conda_env}/lib/python3.9/site-packages/oneccl_bindings_for_pytorch/env/setvars.sh
+source ${conda_env}/lib/python3.11/site-packages/oneccl_bindings_for_pytorch/env/setvars.sh
bash finetune_one_node_two_sockets.sh
```
diff --git a/python/llm/example/CPU/Speculative-Decoding/baichuan2/README.md b/python/llm/example/CPU/Speculative-Decoding/baichuan2/README.md
index 35c0fab6..91f2ca9d 100644
--- a/python/llm/example/CPU/Speculative-Decoding/baichuan2/README.md
+++ b/python/llm/example/CPU/Speculative-Decoding/baichuan2/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
pip install intel_extension_for_pytorch==2.1.0
diff --git a/python/llm/example/CPU/Speculative-Decoding/chatglm3/README.md b/python/llm/example/CPU/Speculative-Decoding/chatglm3/README.md
index 7d4a2e24..333a6263 100644
--- a/python/llm/example/CPU/Speculative-Decoding/chatglm3/README.md
+++ b/python/llm/example/CPU/Speculative-Decoding/chatglm3/README.md
@@ -7,7 +7,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
```
diff --git a/python/llm/example/CPU/Speculative-Decoding/llama2/README.md b/python/llm/example/CPU/Speculative-Decoding/llama2/README.md
index 4f76831d..34646bcc 100644
--- a/python/llm/example/CPU/Speculative-Decoding/llama2/README.md
+++ b/python/llm/example/CPU/Speculative-Decoding/llama2/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
pip install intel_extension_for_pytorch==2.1.0
diff --git a/python/llm/example/CPU/Speculative-Decoding/mistral/README.md b/python/llm/example/CPU/Speculative-Decoding/mistral/README.md
index 0f6c0762..6f824d2b 100644
--- a/python/llm/example/CPU/Speculative-Decoding/mistral/README.md
+++ b/python/llm/example/CPU/Speculative-Decoding/mistral/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
pip install intel_extension_for_pytorch==2.1.0
diff --git a/python/llm/example/CPU/Speculative-Decoding/qwen/README.md b/python/llm/example/CPU/Speculative-Decoding/qwen/README.md
index e00d73f7..ec5866f0 100644
--- a/python/llm/example/CPU/Speculative-Decoding/qwen/README.md
+++ b/python/llm/example/CPU/Speculative-Decoding/qwen/README.md
@@ -8,7 +8,7 @@ predict the next N tokens using `generate()` API, with IPEX-LLM speculative deco
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
pip install tiktoken einops transformers_stream_generator # additional package required for Qwen to conduct generation
diff --git a/python/llm/example/CPU/Speculative-Decoding/starcoder/README.md b/python/llm/example/CPU/Speculative-Decoding/starcoder/README.md
index dcb42d99..eab5fd8a 100644
--- a/python/llm/example/CPU/Speculative-Decoding/starcoder/README.md
+++ b/python/llm/example/CPU/Speculative-Decoding/starcoder/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
pip install intel_extension_for_pytorch==2.1.0
diff --git a/python/llm/example/CPU/Speculative-Decoding/vicuna/README.md b/python/llm/example/CPU/Speculative-Decoding/vicuna/README.md
index faf31eb0..bd85910f 100644
--- a/python/llm/example/CPU/Speculative-Decoding/vicuna/README.md
+++ b/python/llm/example/CPU/Speculative-Decoding/vicuna/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
pip install intel_extension_for_pytorch==2.1.0
diff --git a/python/llm/example/CPU/Speculative-Decoding/ziya/README.md b/python/llm/example/CPU/Speculative-Decoding/ziya/README.md
index 769b5519..837aa357 100644
--- a/python/llm/example/CPU/Speculative-Decoding/ziya/README.md
+++ b/python/llm/example/CPU/Speculative-Decoding/ziya/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
pip install intel_extension_for_pytorch==2.1.0
diff --git a/python/llm/example/CPU/vLLM-Serving/README.md b/python/llm/example/CPU/vLLM-Serving/README.md
index c4e4c2bc..b7933112 100644
--- a/python/llm/example/CPU/vLLM-Serving/README.md
+++ b/python/llm/example/CPU/vLLM-Serving/README.md
@@ -14,7 +14,7 @@ To run vLLM continuous batching on Intel CPUs, install the dependencies as follo
```bash
# First create an conda environment
-conda create -n ipex-vllm python==3.9
+conda create -n ipex-vllm python=3.11
conda activate ipex-vllm
# Install dependencies
pip3 install numpy
diff --git a/python/llm/example/GPU/Applications/autogen/README.md b/python/llm/example/GPU/Applications/autogen/README.md
index 2a9f8328..9ae4104c 100644
--- a/python/llm/example/GPU/Applications/autogen/README.md
+++ b/python/llm/example/GPU/Applications/autogen/README.md
@@ -11,7 +11,7 @@ mkdir autogen
cd autogen
# create respective conda environment
-conda create -n autogen python=3.9
+conda create -n autogen python=3.11
conda activate autogen
# install xpu-supported and fastchat-adapted ipex-llm
diff --git a/python/llm/example/GPU/Applications/streaming-llm/README.md b/python/llm/example/GPU/Applications/streaming-llm/README.md
index ae0e1aa7..4e1fd1ad 100644
--- a/python/llm/example/GPU/Applications/streaming-llm/README.md
+++ b/python/llm/example/GPU/Applications/streaming-llm/README.md
@@ -10,7 +10,7 @@ model = AutoModelForCausalLM.from_pretrained(model_name_or_path, load_in_4bit=Tr
## Prepare Environment
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install -U transformers==4.34.0
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/Deepspeed-AutoTP/README.md b/python/llm/example/GPU/Deepspeed-AutoTP/README.md
index 948bf8c5..aa408d4e 100644
--- a/python/llm/example/GPU/Deepspeed-AutoTP/README.md
+++ b/python/llm/example/GPU/Deepspeed-AutoTP/README.md
@@ -10,7 +10,7 @@ To run this example with IPEX-LLM on Intel GPUs, we have some recommended requir
### 1. Install
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/AWQ/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/AWQ/README.md
index 59355f71..cf281a8f 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/AWQ/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/AWQ/README.md
@@ -33,7 +33,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a AWQ
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF-IQ2/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF-IQ2/README.md
index c90522f0..27ace787 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF-IQ2/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF-IQ2/README.md
@@ -23,7 +23,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a GGUF
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF/README.md
index c0101fde..a979d5f6 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GGUF/README.md
@@ -23,7 +23,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GPTQ/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GPTQ/README.md
index d9507532..742ba6ec 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GPTQ/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Advanced-Quantizations/GPTQ/README.md
@@ -9,7 +9,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Llam
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/aquila/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/aquila/README.md
index 10c44883..f2b57eb4 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/aquila/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/aquila/README.md
@@ -16,7 +16,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Aqui
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -24,7 +24,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/aquila2/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/aquila2/README.md
index 689d3821..b68ff6df 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/aquila2/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/aquila2/README.md
@@ -16,7 +16,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Aqui
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -25,7 +25,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan/README.md
index dbebb1d4..105e1c0b 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Baic
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install transformers_stream_generator # additional package required for Bai
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan2/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan2/README.md
index 502ae4ac..d7de8ab0 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan2/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan2/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Baic
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install transformers_stream_generator # additional package required for Bai
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan2/generate.py b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan2/generate.py
index 476d0946..68be4b1a 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan2/generate.py
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/baichuan2/generate.py
@@ -51,7 +51,7 @@ if __name__ == '__main__':
load_in_4bit=True,
trust_remote_code=True,
use_cache=True)
- model = model.to('xpu')
+ model = model.half().to('xpu')
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path,
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/bluelm/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/bluelm/README.md
index a075bbf2..af784432 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/bluelm/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/bluelm/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Blue
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -19,7 +19,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm2/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm2/README.md
index 9a6af846..9f7fbcb7 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm2/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm2/README.md
@@ -12,7 +12,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Chat
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -137,7 +137,7 @@ In the example [streamchat.py](./streamchat.py), we show a basic use case for a
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -145,7 +145,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm2/generate.py b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm2/generate.py
index 53272834..f2e65b8f 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm2/generate.py
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm2/generate.py
@@ -48,7 +48,7 @@ if __name__ == '__main__':
optimize_model=True,
trust_remote_code=True,
use_cache=True)
- model = model.to('xpu')
+ model = model.half().to('xpu')
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path,
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm3/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm3/README.md
index 8087252e..607a7a33 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm3/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm3/README.md
@@ -11,7 +11,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Chat
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -138,7 +138,7 @@ In the example [streamchat.py](./streamchat.py), we show a basic use case for a
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -147,7 +147,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm3/generate.py b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm3/generate.py
index 92190bca..da730d70 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm3/generate.py
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chatglm3/generate.py
@@ -48,7 +48,7 @@ if __name__ == '__main__':
optimize_model=True,
trust_remote_code=True,
use_cache=True)
- model = model.to('xpu')
+ model = model.half().to('xpu')
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path,
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chinese-llama2/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chinese-llama2/README.md
index 68bf861f..08c49e99 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chinese-llama2/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/chinese-llama2/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Llam
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -19,7 +19,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/codellama/readme.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/codellama/readme.md
index c19a9c71..f5f31406 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/codellama/readme.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/codellama/readme.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for an Cod
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install transformers==4.34.1 # CodeLlamaTokenizer is supported in higher ver
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/deciLM-7b/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/deciLM-7b/README.md
index e3da7af0..dd69d009 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/deciLM-7b/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/deciLM-7b/README.md
@@ -13,7 +13,7 @@ We suggest using conda to manage environment. For more information about conda i
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.0.110+xpu as default
# you can install specific ipex/torch version for your need
@@ -23,7 +23,7 @@ pip install transformers==4.35.2 # required by DeciLM-7B
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/deepseek/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/deepseek/README.md
index 45ba0849..d747ba53 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/deepseek/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/deepseek/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Deep
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.0.110+xpu as default
# you can install specific ipex/torch version for your need
@@ -20,7 +20,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/distil-whisper/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/distil-whisper/README.md
index a3bef032..664e67aa 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/distil-whisper/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/distil-whisper/README.md
@@ -13,7 +13,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -23,7 +23,7 @@ pip install datasets soundfile librosa # required by audio processing
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/dolly-v1/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/dolly-v1/README.md
index ebcf31b2..027ff4e8 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/dolly-v1/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/dolly-v1/README.md
@@ -12,7 +12,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Doll
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -21,7 +21,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/dolly-v2/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/dolly-v2/README.md
index 7a73f8c2..5ab0cf0e 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/dolly-v2/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/dolly-v2/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Doll
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -19,7 +19,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/falcon/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/falcon/README.md
index 8d415381..c5e96f1c 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/falcon/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/falcon/README.md
@@ -11,7 +11,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Falc
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -21,7 +21,7 @@ pip install einops # additional package required for falcon-7b-instruct to condu
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/flan-t5/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/flan-t5/README.md
index 51d750b3..f73665f6 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/flan-t5/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/flan-t5/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -22,7 +22,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gemma/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gemma/README.md
index 99db8511..98b775f1 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gemma/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gemma/README.md
@@ -14,7 +14,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -27,7 +27,7 @@ pip install transformers==4.38.1
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gpt-j/readme.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gpt-j/readme.md
index dcf79586..c8659217 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gpt-j/readme.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gpt-j/readme.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a GPT-
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -19,7 +19,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/internlm/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/internlm/README.md
index 0b35a40e..c784dedb 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/internlm/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/internlm/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Inte
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -19,7 +19,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/internlm2/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/internlm2/README.md
index d58d103e..a6e32dd8 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/internlm2/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/internlm2/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Inte
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -19,7 +19,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/llama2/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/llama2/README.md
index dbeb9520..97b6deee 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/llama2/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/llama2/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Llam
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -19,7 +19,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/llama2/generate.py b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/llama2/generate.py
index 09f389ad..f678dec3 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/llama2/generate.py
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/llama2/generate.py
@@ -61,7 +61,7 @@ if __name__ == '__main__':
optimize_model=True,
trust_remote_code=True,
use_cache=True)
- model = model.to('xpu')
+ model = model.half().to('xpu')
# Load tokenizer
tokenizer = LlamaTokenizer.from_pretrained(model_path, trust_remote_code=True)
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mistral/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mistral/README.md
index 4dd1bac0..78413419 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mistral/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mistral/README.md
@@ -14,7 +14,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -27,7 +27,7 @@ pip install transformers==4.34.0
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mistral/generate.py b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mistral/generate.py
index 3734724a..585b1936 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mistral/generate.py
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mistral/generate.py
@@ -47,7 +47,7 @@ if __name__ == '__main__':
optimize_model=True,
trust_remote_code=True,
use_cache=True)
- model = model.to('xpu')
+ model = model.half().to('xpu')
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mixtral/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mixtral/README.md
index d87c8bab..47c9e728 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mixtral/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mixtral/README.md
@@ -14,7 +14,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -27,7 +27,7 @@ pip install transformers==4.36.0
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mpt/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mpt/README.md
index e9bea490..99092cf9 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mpt/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/mpt/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for an MPT
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install einops # additional package required for mpt-7b-chat and mpt-30b-ch
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phi-1_5/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phi-1_5/README.md
index 198e73ba..98868833 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phi-1_5/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phi-1_5/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a phi-
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install einops # additional package required for phi-1_5 to conduct generati
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phi-2/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phi-2/README.md
index f7030b26..353d6e51 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phi-2/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phi-2/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a phi-
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -19,7 +19,7 @@ pip install einops # additional package required for phi-2 to conduct generation
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phixtral/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phixtral/README.md
index 7a05488d..e91daf29 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phixtral/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/phixtral/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Inte
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -19,7 +19,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen-vl/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen-vl/README.md
index fe044d10..f8d67544 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen-vl/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen-vl/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -22,7 +22,7 @@ pip install accelerate tiktoken einops transformers_stream_generator==0.0.4 scip
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen/README.md
index 7b20fcf1..b475d831 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Qwen
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install tiktoken einops transformers_stream_generator # additional package
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen/generate.py b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen/generate.py
index 2d0a5f8a..3e47ab47 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen/generate.py
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen/generate.py
@@ -54,7 +54,7 @@ if __name__ == '__main__':
optimize_model=True,
trust_remote_code=True,
use_cache=True)
- model = model.to('xpu')
+ model = model.half().to('xpu')
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path,
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen1.5/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen1.5/README.md
index 656e8933..830d4d26 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen1.5/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen1.5/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Qwen
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install transformers==4.37.0 # install transformers which supports Qwen2
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen1.5/generate.py b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen1.5/generate.py
index 557b0d55..902b9170 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen1.5/generate.py
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/qwen1.5/generate.py
@@ -44,7 +44,7 @@ if __name__ == '__main__':
model = AutoModelForCausalLM.from_pretrained(model_path,
load_in_4bit=True,
trust_remote_code=True)
- model = model.to("xpu")
+ model = model.half().to("xpu")
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path,
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/redpajama/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/redpajama/README.md
index ddb34896..201046af 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/redpajama/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/redpajama/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -21,7 +21,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/replit/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/replit/README.md
index a4626d99..9e6930a5 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/replit/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/replit/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -22,7 +22,7 @@ pip install "transformers<4.35"
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/rwkv4/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/rwkv4/README.md
index b2a1ccf6..5ec3e3f0 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/rwkv4/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/rwkv4/README.md
@@ -12,7 +12,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a RWKV
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/rwkv5/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/rwkv5/README.md
index b0d783fd..c924fc25 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/rwkv5/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/rwkv5/README.md
@@ -12,7 +12,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a RWKV
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/solar/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/solar/README.md
index 34358217..72a3562d 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/solar/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/solar/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a SOLA
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install transformers==4.35.2 # required by SOLAR
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/stablelm/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/stablelm/README.md
index b58df91c..ce694c49 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/stablelm/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/stablelm/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -25,7 +25,7 @@ pip install transformers==4.38.0
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/starcoder/readme.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/starcoder/readme.md
index 41ddf26c..d0c6a257 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/starcoder/readme.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/starcoder/readme.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for an Sta
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -19,7 +19,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/vicuna/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/vicuna/README.md
index f53ecb71..9b719625 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/vicuna/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/vicuna/README.md
@@ -12,7 +12,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Vicu
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -21,7 +21,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/voiceassistant/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/voiceassistant/README.md
index 07d0d4af..74afab59 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/voiceassistant/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/voiceassistant/README.md
@@ -12,7 +12,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Whis
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -26,7 +26,7 @@ pip install PyAudio inquirer sounddevice
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -163,7 +163,7 @@ frame_data = np.frombuffer(audio.frame_data, np.int16).flatten().astype(np.float
#### Sample Output
```bash
(llm) ipex@ipex-llm:~/Documents/voiceassistant$ python generate.py --llama2-repo-id-or-model-path /mnt/windows/demo/models/Llama-2-7b-chat-hf --whisper-repo-id-or-model-path /mnt/windows/demo/models/whisper-medium
-/home/ipex/anaconda3/envs/llm/lib/python3.9/site-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: ''If you don't plan on using image functionality from `torchvision.io`, you can ignore this warning. Otherwise, there might be something wrong with your environment. Did you have `libjpeg` or `libpng` installed before building `torchvision` from source?
+/home/ipex/anaconda3/envs/llm/lib/python3.11/site-packages/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension: ''If you don't plan on using image functionality from `torchvision.io`, you can ignore this warning. Otherwise, there might be something wrong with your environment. Did you have `libjpeg` or `libpng` installed before building `torchvision` from source?
warn(
[?] Which microphone do you choose?: Default
@@ -189,11 +189,11 @@ Extracting data files: 100%|█████████████████
Generating validation split: 73 examples [00:00, 5328.37 examples/s]
Converting and loading models...
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:09<00:00, 3.04s/it]
-/home/ipex/anaconda3/envs/yina-llm/lib/python3.9/site-packages/transformers/generation/configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.9` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`. This was detected when initializing the generation config instance, which means the corresponding file may hold incorrect parameterization and should be fixed.
+/home/ipex/anaconda3/envs/yina-llm/lib/python3.11/site-packages/transformers/generation/configuration_utils.py:362: UserWarning: `do_sample` is set to `False`. However, `temperature` is set to `0.9` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `temperature`. This was detected when initializing the generation config instance, which means the corresponding file may hold incorrect parameterization and should be fixed.
warnings.warn(
-/home/ipex/anaconda3/envs/yina-llm/lib/python3.9/site-packages/transformers/generation/configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.6` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`. This was detected when initializing the generation config instance, which means the corresponding file may hold incorrect parameterization and should be fixed.
+/home/ipex/anaconda3/envs/yina-llm/lib/python3.11/site-packages/transformers/generation/configuration_utils.py:367: UserWarning: `do_sample` is set to `False`. However, `top_p` is set to `0.6` -- this flag is only used in sample-based generation modes. You should set `do_sample=True` or unset `top_p`. This was detected when initializing the generation config instance, which means the corresponding file may hold incorrect parameterization and should be fixed.
warnings.warn(
-/home/ipex/anaconda3/envs/yina-llm/lib/python3.9/site-packages/transformers/generation/utils.py:1411: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation )
+/home/ipex/anaconda3/envs/yina-llm/lib/python3.11/site-packages/transformers/generation/utils.py:1411: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation )
warnings.warn(
Calibrating...
Listening now...
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/whisper/readme.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/whisper/readme.md
index dd684114..377b8592 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/whisper/readme.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/whisper/readme.md
@@ -11,7 +11,7 @@ In the example [recognize.py](./recognize.py), we show a basic use case for a Wh
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -21,7 +21,7 @@ pip install datasets soundfile librosa # required by audio processing
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/yi/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/yi/README.md
index 6995e24b..cb020717 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/yi/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/yi/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -23,7 +23,7 @@ pip install einops # additional package required for Yi-6B to conduct generation
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/yuan2/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/yuan2/README.md
index b0a66413..d67ac916 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/yuan2/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/yuan2/README.md
@@ -12,7 +12,7 @@ In the example [generate.py](./generate.py), we show a basic use case for an Yua
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
@@ -22,7 +22,7 @@ pip install pandas # additional package required for Yuan2 to conduct generation
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/More-Data-Types/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/More-Data-Types/README.md
index 2a8a7661..d97d0e40 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/More-Data-Types/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/More-Data-Types/README.md
@@ -5,7 +5,7 @@ In this example, we show a pipeline to apply IPEX-LLM low-bit optimizations (inc
## Prepare Environment
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Save-Load/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Save-Load/README.md
index 53c38b13..f9849ff8 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Save-Load/README.md
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Save-Load/README.md
@@ -11,7 +11,7 @@ In the example [generate.py](./generate.py), we show a basic use case of saving/
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/LLM-Finetuning/DPO/README.md b/python/llm/example/GPU/LLM-Finetuning/DPO/README.md
index eeed9519..076e5642 100644
--- a/python/llm/example/GPU/LLM-Finetuning/DPO/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/DPO/README.md
@@ -13,7 +13,7 @@ This example is ported from [Fine_tune_a_Mistral_7b_model_with_DPO](https://gith
### 1. Install
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/LLM-Finetuning/HF-PEFT/README.md b/python/llm/example/GPU/LLM-Finetuning/HF-PEFT/README.md
index b847fdce..7da65981 100644
--- a/python/llm/example/GPU/LLM-Finetuning/HF-PEFT/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/HF-PEFT/README.md
@@ -10,7 +10,7 @@ To run this example with IPEX-LLM on Intel GPUs, we have some recommended requir
### 1. Install
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/LLM-Finetuning/LoRA/README.md b/python/llm/example/GPU/LLM-Finetuning/LoRA/README.md
index 4af01ab0..8ef75a28 100644
--- a/python/llm/example/GPU/LLM-Finetuning/LoRA/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/LoRA/README.md
@@ -8,7 +8,7 @@ To run this example with IPEX-LLM on Intel GPUs, we have some recommended requir
### 1. Install
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/LLM-Finetuning/QA-LoRA/README.md b/python/llm/example/GPU/LLM-Finetuning/QA-LoRA/README.md
index 5ab124f0..006f6630 100644
--- a/python/llm/example/GPU/LLM-Finetuning/QA-LoRA/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/QA-LoRA/README.md
@@ -8,7 +8,7 @@ To run this example with IPEX-LLM on Intel GPUs, we have some recommended requir
### 1. Install
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/LLM-Finetuning/QLoRA/alpaca-qlora/README.md b/python/llm/example/GPU/LLM-Finetuning/QLoRA/alpaca-qlora/README.md
index 9893c763..4cdb3d26 100644
--- a/python/llm/example/GPU/LLM-Finetuning/QLoRA/alpaca-qlora/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/QLoRA/alpaca-qlora/README.md
@@ -10,7 +10,7 @@ To run this example with IPEX-LLM on Intel GPUs, we have some recommended requir
### 1. Install
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/LLM-Finetuning/QLoRA/simple-example/README.md b/python/llm/example/GPU/LLM-Finetuning/QLoRA/simple-example/README.md
index 15b63674..fe682829 100644
--- a/python/llm/example/GPU/LLM-Finetuning/QLoRA/simple-example/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/QLoRA/simple-example/README.md
@@ -13,7 +13,7 @@ This example is referred to [bnb-4bit-training](https://colab.research.google.co
### 1. Install
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/LLM-Finetuning/QLoRA/trl-example/README.md b/python/llm/example/GPU/LLM-Finetuning/QLoRA/trl-example/README.md
index 0ba053f8..46e8992b 100644
--- a/python/llm/example/GPU/LLM-Finetuning/QLoRA/trl-example/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/QLoRA/trl-example/README.md
@@ -13,7 +13,7 @@ This example utilizes a subset of [yahma/alpaca-cleaned](https://huggingface.co/
### 1. Install
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/LLM-Finetuning/README.md b/python/llm/example/GPU/LLM-Finetuning/README.md
index e2ab7acb..5ffd83dd 100644
--- a/python/llm/example/GPU/LLM-Finetuning/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/README.md
@@ -9,6 +9,7 @@ This folder contains examples of running different training mode with IPEX-LLM o
- [DPO](DPO): examples of running DPO finetuning
- [common](common): common templates and utility classes in finetuning examples
- [HF-PEFT](HF-PEFT): run finetuning on Intel GPU using Hugging Face PEFT code without modification
+- [axolotl](axolotl): LLM finetuning on Intel GPU using axolotl without writing code
## Troubleshooting
diff --git a/python/llm/example/GPU/LLM-Finetuning/ReLora/README.md b/python/llm/example/GPU/LLM-Finetuning/ReLora/README.md
index 3218948b..0e94a63a 100644
--- a/python/llm/example/GPU/LLM-Finetuning/ReLora/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/ReLora/README.md
@@ -8,7 +8,7 @@ To run this example with IPEX-LLM on Intel GPUs, we have some recommended requir
### 1. Install
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/LLM-Finetuning/axolotl/README.md b/python/llm/example/GPU/LLM-Finetuning/axolotl/README.md
new file mode 100644
index 00000000..5a0439bf
--- /dev/null
+++ b/python/llm/example/GPU/LLM-Finetuning/axolotl/README.md
@@ -0,0 +1,76 @@
+# Finetune LLM on Intel GPU using axolotl without writing code
+
+This example demonstrates how to easily run LLM finetuning application using axolotl and IPEX-LLM 4bit optimizations with [Intel GPUs](../../../README.md). By applying IPEX-LLM patch, you could use axolotl on Intel GPUs using IPEX-LLM optimization without writing code.
+
+Note, this example is just used for illustrating related usage and don't guarantee convergence of training.
+
+### 0. Requirements
+
+To run this example with IPEX-LLM on Intel GPUs, we have some recommended requirements for your machine, please refer to [here](../../README.md#requirements) for more information.
+
+### 1. Install
+
+```bash
+conda create -n llm python=3.11
+conda activate llm
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+pip install transformers==4.34.0 datasets
+pip install fire peft==0.5.0
+# install axolotl v0.3.0
+git clone https://github.com/OpenAccess-AI-Collective/axolotl
+cd axolotl
+git checkout v0.3.0
+# replace default requirements.txt in axolotl to avoid conflict
+cp ../requirements.txt .
+pip install -e .
+```
+
+### 2. Configures OneAPI environment variables and accelerate
+
+```bash
+source /opt/intel/oneapi/setvars.sh
+```
+
+Config `accelerate`
+
+```bash
+accelerate config
+```
+
+Ensure `use_cpu` is disable in config (`~/.cache/huggingface/accelerate/default_config.yaml`).
+
+### 3. Finetune
+
+This example shows how to run [Alpaca QLoRA finetune on Llama-2](https://github.com/artidoro/qlora) directly on Intel GPU, based on [axolotl Llama-2 qlora example](https://github.com/OpenAccess-AI-Collective/axolotl/blob/v0.3.0/examples/llama-2/qlora.yml).
+
+Modify parameters in `qlora.yml` based on your requirements.
+
+```
+accelerate launch finetune.py qlora.yml
+```
+
+Output in console
+
+```
+{'eval_loss': 0.9382301568984985, 'eval_runtime': 6.2513, 'eval_samples_per_second': 3.199, 'eval_steps_per_second': 3.199, 'epoch': 0.36}
+{'loss': 0.944, 'learning_rate': 0.00019752490425051743, 'epoch': 0.38}
+{'loss': 1.0179, 'learning_rate': 0.00019705675197106016, 'epoch': 0.4}
+{'loss': 0.9346, 'learning_rate': 0.00019654872959986937, 'epoch': 0.41}
+{'loss': 0.9747, 'learning_rate': 0.0001960010458282326, 'epoch': 0.43}
+{'loss': 0.8928, 'learning_rate': 0.00019541392564000488, 'epoch': 0.45}
+{'loss': 0.9317, 'learning_rate': 0.00019478761021918728, 'epoch': 0.47}
+{'loss': 1.0534, 'learning_rate': 0.00019412235685085035, 'epoch': 0.49}
+{'loss': 0.8777, 'learning_rate': 0.00019341843881544372, 'epoch': 0.5}
+{'loss': 0.9447, 'learning_rate': 0.00019267614527653488, 'epoch': 0.52}
+{'loss': 0.9651, 'learning_rate': 0.00019189578116202307, 'epoch': 0.54}
+{'loss': 0.9067, 'learning_rate': 0.00019107766703887764, 'epoch': 0.56}
+```
+
+### 4. Other examples
+
+Please refer to [axolotl examples](https://github.com/OpenAccess-AI-Collective/axolotl/tree/v0.3.0/examples) for more models. Download `xxx.yml` and replace `qlora.yml` with new `xxx.yml`.
+
+```
+accelerate launch finetune.py xxx.yml
+```
diff --git a/python/llm/example/GPU/LLM-Finetuning/axolotl/finetune.py b/python/llm/example/GPU/LLM-Finetuning/axolotl/finetune.py
new file mode 100644
index 00000000..e434e529
--- /dev/null
+++ b/python/llm/example/GPU/LLM-Finetuning/axolotl/finetune.py
@@ -0,0 +1,280 @@
+"""Prepare and train a model on a dataset. Can also infer from a model or merge lora"""
+
+import importlib
+import logging
+import os
+import random
+import sys
+from pathlib import Path
+from typing import Any, Dict, List, Optional, Union
+
+from ipex_llm import llm_patch
+llm_patch(train=True)
+import fire
+import torch
+import transformers
+import yaml
+
+# add src to the pythonpath so we don't need to pip install this
+from art import text2art
+from transformers import GenerationConfig, TextStreamer
+
+from axolotl.common.cli import TrainerCliArgs, load_model_and_tokenizer
+from axolotl.logging_config import configure_logging
+from axolotl.train import TrainDatasetMeta, train
+from axolotl.utils.config import normalize_config, validate_config
+from axolotl.utils.data import prepare_dataset
+from axolotl.utils.dict import DictDefault
+from axolotl.utils.distributed import is_main_process
+from axolotl.utils.models import load_tokenizer
+from axolotl.utils.tokenization import check_dataset_labels
+from axolotl.utils.wandb import setup_wandb_env_vars
+
+project_root = os.path.abspath(os.path.join(os.path.dirname(__file__), ".."))
+src_dir = os.path.join(project_root, "src")
+sys.path.insert(0, src_dir)
+
+configure_logging()
+LOG = logging.getLogger("axolotl.scripts")
+
+os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
+
+
+def print_axolotl_text_art(suffix=None):
+ font = "nancyj"
+ ascii_text = " axolotl"
+ if suffix:
+ ascii_text += f" x {suffix}"
+ ascii_art = text2art(" axolotl", font=font)
+
+ if is_main_process():
+ print(ascii_art)
+
+
+def get_multi_line_input() -> Optional[str]:
+ print("Give me an instruction (Ctrl + D to finish): ")
+ instruction = ""
+ for line in sys.stdin:
+ instruction += line # pylint: disable=consider-using-join
+ # instruction = pathlib.Path("/proc/self/fd/0").read_text()
+ return instruction
+
+
+def do_merge_lora(
+ *,
+ cfg: DictDefault,
+ cli_args: TrainerCliArgs,
+):
+ model, tokenizer = load_model_and_tokenizer(cfg=cfg, cli_args=cli_args)
+ safe_serialization = cfg.save_safetensors is True
+
+ LOG.info("running merge of LoRA with base model")
+ model = model.merge_and_unload()
+ model.to(dtype=torch.float16)
+
+ if cfg.local_rank == 0:
+ LOG.info("saving merged model")
+ model.save_pretrained(
+ str(Path(cfg.output_dir) / "merged"),
+ safe_serialization=safe_serialization,
+ )
+ tokenizer.save_pretrained(str(Path(cfg.output_dir) / "merged"))
+
+
+def shard(
+ *,
+ cfg: DictDefault,
+ cli_args: TrainerCliArgs,
+):
+ model, _ = load_model_and_tokenizer(cfg=cfg, cli_args=cli_args)
+ safe_serialization = cfg.save_safetensors is True
+ LOG.debug("Re-saving model w/ sharding")
+ model.save_pretrained(cfg.output_dir, safe_serialization=safe_serialization)
+
+
+def do_inference(
+ *,
+ cfg: DictDefault,
+ cli_args: TrainerCliArgs,
+):
+ model, tokenizer = load_model_and_tokenizer(cfg=cfg, cli_args=cli_args)
+ prompter = cli_args.prompter
+ default_tokens = {"unk_token": "", "bos_token": "", "eos_token": ""}
+
+ for token, symbol in default_tokens.items():
+ # If the token isn't already specified in the config, add it
+ if not (cfg.special_tokens and token in cfg.special_tokens):
+ tokenizer.add_special_tokens({token: symbol})
+
+ prompter_module = None
+ if prompter:
+ prompter_module = getattr(
+ importlib.import_module("axolotl.prompters"), prompter
+ )
+
+ if cfg.landmark_attention:
+ from axolotl.monkeypatch.llama_landmark_attn import set_model_mem_id
+
+ set_model_mem_id(model, tokenizer)
+ model.set_mem_cache_args(
+ max_seq_len=255, mem_freq=50, top_k=5, max_cache_size=None
+ )
+
+ model = model.to(cfg.device)
+
+ while True:
+ print("=" * 80)
+ # support for multiline inputs
+ instruction = get_multi_line_input()
+ if not instruction:
+ return
+ if prompter_module:
+ prompt: str = next(
+ prompter_module().build_prompt(instruction=instruction.strip("\n"))
+ )
+ else:
+ prompt = instruction.strip()
+ batch = tokenizer(prompt, return_tensors="pt", add_special_tokens=True)
+
+ print("=" * 40)
+ model.eval()
+ with torch.no_grad():
+ generation_config = GenerationConfig(
+ repetition_penalty=1.1,
+ max_new_tokens=1024,
+ temperature=0.9,
+ top_p=0.95,
+ top_k=40,
+ bos_token_id=tokenizer.bos_token_id,
+ eos_token_id=tokenizer.eos_token_id,
+ pad_token_id=tokenizer.pad_token_id,
+ do_sample=True,
+ use_cache=True,
+ return_dict_in_generate=True,
+ output_attentions=False,
+ output_hidden_states=False,
+ output_scores=False,
+ )
+ streamer = TextStreamer(tokenizer)
+ generated = model.generate(
+ inputs=batch["input_ids"].to(cfg.device),
+ generation_config=generation_config,
+ streamer=streamer,
+ )
+ print("=" * 40)
+ print(tokenizer.decode(generated["sequences"].cpu().tolist()[0]))
+
+
+def choose_config(path: Path):
+ yaml_files = list(path.glob("*.yml"))
+
+ if not yaml_files:
+ raise ValueError(
+ "No YAML config files found in the specified directory. Are you using a .yml extension?"
+ )
+
+ if len(yaml_files) == 1:
+ print(f"Using default YAML file '{yaml_files[0]}'")
+ return yaml_files[0]
+
+ print("Choose a YAML file:")
+ for idx, file in enumerate(yaml_files):
+ print(f"{idx + 1}. {file}")
+
+ chosen_file = None
+ while chosen_file is None:
+ try:
+ choice = int(input("Enter the number of your choice: "))
+ if 1 <= choice <= len(yaml_files):
+ chosen_file = yaml_files[choice - 1]
+ else:
+ print("Invalid choice. Please choose a number from the list.")
+ except ValueError:
+ print("Invalid input. Please enter a number.")
+
+ return chosen_file
+
+
+def check_not_in(list1: List[str], list2: Union[Dict[str, Any], List[str]]) -> bool:
+ return not any(el in list2 for el in list1)
+
+
+def load_cfg(config: Path = Path("examples/"), **kwargs):
+ if Path(config).is_dir():
+ config = choose_config(config)
+
+ # load the config from the yaml file
+ with open(config, encoding="utf-8") as file:
+ cfg: DictDefault = DictDefault(yaml.safe_load(file))
+ # if there are any options passed in the cli, if it is something that seems valid from the yaml,
+ # then overwrite the value
+ cfg_keys = cfg.keys()
+ for k, _ in kwargs.items():
+ # if not strict, allow writing to cfg even if it's not in the yml already
+ if k in cfg_keys or not cfg.strict:
+ # handle booleans
+ if isinstance(cfg[k], bool):
+ cfg[k] = bool(kwargs[k])
+ else:
+ cfg[k] = kwargs[k]
+
+ validate_config(cfg)
+
+ normalize_config(cfg)
+
+ setup_wandb_env_vars(cfg)
+ return cfg
+
+
+def load_datasets(
+ *,
+ cfg: DictDefault,
+ cli_args: TrainerCliArgs,
+) -> TrainDatasetMeta:
+ tokenizer = load_tokenizer(cfg)
+
+ train_dataset, eval_dataset, total_num_steps = prepare_dataset(cfg, tokenizer)
+
+ if cli_args.debug or cfg.debug:
+ LOG.info("check_dataset_labels...")
+ check_dataset_labels(
+ train_dataset.select(
+ [
+ random.randrange(0, len(train_dataset) - 1) # nosec
+ for _ in range(cli_args.debug_num_examples)
+ ]
+ ),
+ tokenizer,
+ num_examples=cli_args.debug_num_examples,
+ text_only=cli_args.debug_text_only,
+ )
+
+ return TrainDatasetMeta(
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ total_num_steps=total_num_steps,
+ )
+
+
+def do_cli(config: Path = Path("examples/"), **kwargs):
+ print_axolotl_text_art()
+ parsed_cfg = load_cfg(config, **kwargs)
+ parser = transformers.HfArgumentParser((TrainerCliArgs))
+ parsed_cli_args, _ = parser.parse_args_into_dataclasses(
+ return_remaining_strings=True
+ )
+ if parsed_cli_args.inference:
+ do_inference(cfg=parsed_cfg, cli_args=parsed_cli_args)
+ elif parsed_cli_args.merge_lora:
+ do_merge_lora(cfg=parsed_cfg, cli_args=parsed_cli_args)
+ elif parsed_cli_args.shard:
+ shard(cfg=parsed_cfg, cli_args=parsed_cli_args)
+ else:
+ dataset_meta = load_datasets(cfg=parsed_cfg, cli_args=parsed_cli_args)
+ if parsed_cli_args.prepare_ds_only:
+ return
+ train(cfg=parsed_cfg, cli_args=parsed_cli_args, dataset_meta=dataset_meta)
+
+
+if __name__ == "__main__":
+ fire.Fire(do_cli)
diff --git a/python/llm/example/GPU/LLM-Finetuning/axolotl/qlora.yml b/python/llm/example/GPU/LLM-Finetuning/axolotl/qlora.yml
new file mode 100644
index 00000000..d9f3d86f
--- /dev/null
+++ b/python/llm/example/GPU/LLM-Finetuning/axolotl/qlora.yml
@@ -0,0 +1,73 @@
+base_model: meta-llama/Llama-2-7b-hf
+base_model_config: meta-llama/Llama-2-7b-hf
+model_type: LlamaForCausalLM
+tokenizer_type: LlamaTokenizer
+is_llama_derived_model: true
+
+load_in_8bit: false
+load_in_4bit: true
+strict: false
+
+datasets:
+ - path: mhenrichsen/alpaca_2k_test
+ type: alpaca
+dataset_prepared_path: last_run_prepared
+val_set_size: 0.01
+output_dir: ./qlora-out
+
+adapter: qlora
+lora_model_dir:
+
+sequence_len: 4096
+sample_packing: true
+pad_to_sequence_len: true
+
+lora_r: 8
+lora_alpha: 16
+lora_dropout: 0.05
+lora_target_modules:
+lora_target_linear: true
+lora_fan_in_fan_out:
+
+wandb_project:
+wandb_entity:
+wandb_watch:
+wandb_run_id:
+wandb_log_model:
+
+gradient_accumulation_steps: 2
+micro_batch_size: 1
+num_epochs: 3
+# change optimizer from paged_adamw_32bit to adamw_torch
+# due to bitsandbytes issue https://github.com/TimDettmers/bitsandbytes/issues/244
+# optimizer: paged_adamw_32bit
+optimizer: adamw_torch
+lr_scheduler: cosine
+learning_rate: 0.0002
+
+train_on_inputs: false
+group_by_length: false
+bf16: true
+fp16: false
+tf32: false
+
+gradient_checkpointing: true
+early_stopping_patience:
+resume_from_checkpoint:
+local_rank:
+logging_steps: 1
+xformers_attention:
+flash_attention: false
+
+warmup_steps: 10
+eval_steps: 20
+save_steps:
+debug:
+deepspeed:
+weight_decay: 0.0
+fsdp:
+fsdp_config:
+special_tokens:
+ bos_token: ""
+ eos_token: ""
+ unk_token: ""
diff --git a/python/llm/example/GPU/LLM-Finetuning/axolotl/requirements.txt b/python/llm/example/GPU/LLM-Finetuning/axolotl/requirements.txt
new file mode 100644
index 00000000..8eac25cd
--- /dev/null
+++ b/python/llm/example/GPU/LLM-Finetuning/axolotl/requirements.txt
@@ -0,0 +1,32 @@
+--extra-index-url https://download.pytorch.org/whl/cu118
+--extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
+# torch==2.1.0
+#auto-gptq
+packaging
+peft==0.5.0
+transformers==4.34.0
+bitsandbytes>=0.41.1
+accelerate==0.23.0
+addict
+evaluate
+fire
+PyYAML>=6.0
+datasets
+flash-attn>=2.2.1
+sentencepiece
+wandb
+einops
+#xformers
+optimum
+hf_transfer
+colorama
+numba
+numpy>=1.24.4
+# qlora things
+bert-score==0.3.13
+evaluate==0.4.0
+rouge-score==0.1.2
+scipy
+scikit-learn==1.2.2
+pynvml
+art
diff --git a/python/llm/example/GPU/Long-Context/LLaMA2-32K/8k.txt b/python/llm/example/GPU/Long-Context/LLaMA2-32K/8k.txt
new file mode 100644
index 00000000..4ca8b2e9
--- /dev/null
+++ b/python/llm/example/GPU/Long-Context/LLaMA2-32K/8k.txt
@@ -0,0 +1 @@
+461 U.S. 238 (1983) OLIM ET AL. v. WAKINEKONA No. 81-1581. Supreme Court of United States. Argued January 19, 1983. Decided April 26, 1983. CERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT *239 Michael A. Lilly, First Deputy Attorney General of Hawaii, argued the cause for petitioners. With him on the brief was James H. Dannenberg, Deputy Attorney General. Robert Gilbert Johnston argued the cause for respondent. With him on the brief was Clayton C. Ikei.[*] *240 JUSTICE BLACKMUN delivered the opinion of the Court. The issue in this case is whether the transfer of a prisoner from a state prison in Hawaii to one in California implicates a liberty interest within the meaning of the Due Process Clause of the Fourteenth Amendment. I A Respondent Delbert Kaahanui Wakinekona is serving a sentence of life imprisonment without the possibility of parole as a result of his murder conviction in a Hawaii state court. He also is serving sentences for various other crimes, including rape, robbery, and escape. At the Hawaii State Prison outside Honolulu, respondent was classified as a maximum security risk and placed in the maximum control unit. Petitioner Antone Olim is the Administrator of the Hawaii State Prison. The other petitioners constituted a prison 'Program Committee.' On August 2, 1976, the Committee held hearings to determine the reasons for a breakdown in discipline and the failure of certain programs within the prison's maximum control unit. Inmates of the unit appeared at these hearings. The Committee singled out respondent and another inmate as troublemakers. On August 5, respondent received notice that the Committee, at a hearing to be held on August 10, would review his correctional program to determine whether his classification within the system should be changed and whether he should be transferred to another Hawaii facility or to a mainland institution. *241 The August 10 hearing was conducted by the same persons who had presided over the hearings on August 2. Respondent retained counsel to represent him. The Committee recommended that respondent's classification as a maximum security risk be continued and that he be transferred to a prison on the mainland. He received the following explanation from the Committee: 'The Program Committee, having reviewed your entire file, your testimony and arguments by your counsel, concluded that your control classification remains at Maximum. You are still considered a security risk in view of your escapes and subsequent convictions for serious felonies. The Committee noted the progress you made in vocational training and your expressed desire to continue in this endeavor. However your relationship with staff, who reported that you threaten and intimidate them, raises grave concerns regarding your potential for further disruptive and violent behavior. Since there is no other Maximum security prison in Hawaii which can offer you the correctional programs you require and you cannot remain at [the maximum control unit] because of impending construction of a new facility, the Program Committee recommends your transfer to an institution on the mainland.' App. 7-8. Petitioner Olim, as Administrator, accepted the Committee's recommendation, and a few days later respondent was transferred to Folsom State Prison in California. B Rule IV of the Supplementary Rules and Regulations of the Corrections Division, Department of Social Services and Housing, State of Hawaii, approved in June 1976, recites that the inmate classification process is not concerned with punishment. Rather, it is intended to promote the best interests *242 of the inmate, the State, and the prison community.[1] Paragraph 3 of Rule IV requires a hearing prior to a prison transfer involving 'a grievous loss to the inmate,' which the Rule defines 'generally' as 'a serious loss to a reasonable man.' App. 21.[2] The Administrator, under ¶ 2 of the Rule, is required to establish 'an impartial Program Committee' to conduct such a hearing, the Committee to be 'composed of at least three members who were not actively involved in the process by which the inmate . . . was brought before the Committee.' App. 20. Under ¶ 3, the Committee must give the inmate written notice of the hearing, permit him, with certain stated exceptions, to confront and cross-examine witnesses, afford him an opportunity to be heard, and apprise him of the Committee's findings. App. 21-24.[3] The Committee is directed to make a recommendation to the Administrator, who then decides what action to take: '[The Administrator] may, as the final decisionmaker: '(a) Affirm or reverse, in whole or in part, the recommendation; or '(b) hold in abeyance any action he believes jeopardizes the safety, security, or welfare of the staff, inmate *243. . . , other inmates . . . , institution, or community and refer the matter back to the Program Committee for further study and recommendation.' Rule IV, ¶ 3d(3), App. 24. The regulations contain no standards governing the Administrator's exercise of his discretion. See Lono v. Ariyoshi, 63 Haw. 138, 144-145, 621 P. 2d 976, 980-981 (1981). C Respondent filed suit under 42 U. S. C. § 1983 against petitioners as the state officials who caused his transfer. He alleged that he had been denied procedural due process because the Committee that recommended his transfer consisted of the same persons who had initiated the hearing, this being in specific violation of Rule IV, ¶ 2, and because the Committee was biased against him. The United States District Court for the District of Hawaii dismissed the complaint, holding that the Hawaii regulations governing prison transfers do not create a substantive liberty interest protected by the Due Process Clause. 459 F. Supp. 473 (1978).[4] The United States Court of Appeals for the Ninth Circuit, by a divided vote, reversed. 664 F. 2d 708 (1981). It held that Hawaii had created a constitutionally protected liberty interest by promulgating Rule IV. In so doing, the court declined to follow cases from other Courts of Appeals holding that certain procedures mandated by prison transfer regulations do not create a liberty interest. See, e. g., Cofone v. Manson, 594 F. 2d 934 (CA2 1979); Lombardo v. Meachum, 548 F. 2d 13 (CA1 1977). The court reasoned that Rule IV gives Hawaii prisoners a justifiable expectation that they will not be transferred to the mainland absent a hearing, before an impartial committee, concerning the facts alleged in the *244 prehearing notice.[5] Because the Court of Appeals' decision created a conflict among the Circuits, and because the case presents the further question whether the Due Process Clause in and of itself protects against interstate prison transfers, we granted certiorari. 456 U. S. 1005 (1982). II In Meachum v. Fano, 427 U. S. 215 (1976), and Montanye v. Haymes, 427 U. S. 236 (1976), this Court held that an intrastate prison transfer does not directly implicate the Due Process Clause of the Fourteenth Amendment. In Meachum, inmates at a Massachusetts medium security prison had been transferred to a maximum security prison in that Commonwealth. In Montanye, a companion case, an inmate had been transferred from one maximum security New York prison to another as punishment for a breach of prison rules. This Court rejected 'the notion that any grievous loss visited upon a person by the State is sufficient to invoke the procedural protections of the Due Process Clause.' Meachum, 427 U. S., at 224 (emphasis in original). It went on to state: 'The initial decision to assign the convict to a particular institution is not subject to audit under the Due Process Clause, although the degree of confinement in one prison may be quite different from that in another. The conviction has sufficiently extinguished the defendant's liberty *245 interest to empower the State to confine him in any of its prisons. 'Neither, in our view, does the Due Process Clause in and of itself protect a duly convicted prisoner against transfer from one institution to another within the state prison system. Confinement in any of the State's institutions is within the normal limits or range of custody which the conviction has authorized the State to impose.' Id., at 224-225 (emphasis in original). The Court observed that, although prisoners retain a residuum of liberty, see Wolff v. McDonnell, 418 U. S. 539, 555-556 (1974), a holding that 'any substantial deprivation imposed by prison authorities triggers the procedural protections of the Due Process Clause would subject to judicial review a wide spectrum of discretionary actions that traditionally have been the business of prison administrators rather than of the federal courts.' 427 U. S., at 225 (emphasis in original). Applying the Meachum and Montanye principles in Vitek v. Jones, 445 U. S. 480 (1980), this Court held that the transfer of an inmate from a prison to a mental hospital did implicate a liberty interest. Placement in the mental hospital was 'not within the range of conditions of confinement to which a prison sentence subjects an individual,' because it brought about 'consequences . . . qualitatively different from the punishment characteristically suffered by a person convicted of crime.' Id., at 493. Respondent argues that the same is true of confinement of a Hawaii prisoner on the mainland, and that Vitek therefore controls. We do not agree. Just as an inmate has no justifiable expectation that he will be incarcerated in any particular prison within a State, he has no justifiable expectation that he will be incarcerated in any particular State.[6] Often, confinement *246 in the inmate's home State will not be possible. A person convicted of a federal crime in a State without a federal correctional facility usually will serve his sentence in another State. Overcrowding and the need to separate particular prisoners may necessitate interstate transfers. For any number of reasons, a State may lack prison facilities capable of providing appropriate correctional programs for all offenders. Statutes and interstate agreements recognize that, from time to time, it is necessary to transfer inmates to prisons in other States. On the federal level, 18 U. S. C. § 5003(a) authorizes the Attorney General to contract with a State for the transfer of a state prisoner to a federal prison, whether in that State or another. See Howe v. Smith, 452 U. S. 473 (1981).[7] Title 18 U. S. C. § 4002 (1976 ed. and Supp. V) permits the Attorney General to contract with any State for the placement of a federal prisoner in state custody for up to three years. Neither statute requires that the prisoner remain in the State in which he was convicted and sentenced. On the state level, many States have statutes providing for the transfer of a state prisoner to a federal prison, e. g., Haw. Rev. Stat. § 353-18 (1976), or another State's prison, e. g., Alaska Stat. Ann. § 33.30.100 (1982). Corrections compacts between States, implemented by statutes, authorize incarceration of a prisoner of one State in another State's prison. See, e. g., Cal. Penal Code Ann. § 11189 (West 1982) (codifying Interstate Corrections Compact); § 11190 (codifying Western Interstate Corrections Compact); Conn. Gen. *247 Stat. § 18-102 (1981) (codifying New England Interstate Corrections Compact); § 18-106 (codifying Interstate Corrections Compact); Haw. Rev. Stat. § 355-1 (1976) (codifying Western Interstate Corrections Compact); Idaho Code § 20-701 (1979) (codifying Interstate Corrections Compact); Ky. Rev. Stat. § 196.610 (1982) (same). And prison regulations such as Hawaii's Rule IV anticipate that inmates sometimes will be transferred to prisons in other States. In short, it is neither unreasonable nor unusual for an inmate to serve practically his entire sentence in a State other than the one in which he was convicted and sentenced, or to be transferred to an out-of-state prison after serving a portion of his sentence in his home State. Confinement in another State, unlike confinement in a mental institution, is 'within the normal limits or range of custody which the conviction has authorized the State to impose.' Meachum, 427 U. S., at 225.[8] Even when, as here, the transfer involves long distances and an ocean crossing, the confinement remains within constitutional limits. The difference between such a transfer and an intrastate or interstate transfer of *248 shorter distance is a matter of degree, not of kind,[9] and Meachum instructs that 'the determining factor is the nature of the interest involved rather than its weight.' 427 U. S., at 224. The reasoning of Meachum and Montanye compels the conclusion that an interstate prison transfer, including one from Hawaii to California, does not deprive an inmate of any liberty interest protected by the Due Process Clause in and of itself. III The Court of Appeals held that Hawaii's prison regulations create a constitutionally protected liberty interest. In Meachum, however, the State had 'conferred no right on the *249 prisoner to remain in the prison to which he was initially assigned, defeasible only upon proof of specific acts of misconduct,' 427 U. S., at 226, and 'ha[d] not represented that transfers [would] occur only on the occurrence of certain events,' id., at 228. Because the State had retained 'discretion to transfer [the prisoner] for whatever reason or for no reason at all,' ibid., the Court found that the State had not created a constitutionally protected liberty interest. Similarly, because the state law at issue in Montanye 'impose[d] no conditions on the discretionary power to transfer,' 427 U. S., at 243, there was no basis for invoking the protections of the Due Process Clause. These cases demonstrate that a State creates a protected liberty interest by placing substantive limitations on official discretion. An inmate must show 'that particularized standards or criteria guide the State's decisionmakers.' Connecticut Board of Pardons v. Dumschat, 452 U. S. 458, 467 (1981) (BRENNAN, J., concurring). If the decisionmaker is not 'required to base its decisions on objective and defined criteria,' but instead 'can deny the requested relief for any constitutionally permissible reason or for no reason at all,' ibid., the State has not created a constitutionally protected liberty interest. See id., at 466-467 (opinion of the Court); see also Vitek v. Jones, 445 U. S., at 488-491 (summarizing cases). Hawaii's prison regulations place no substantive limitations on official discretion and thus create no liberty interest entitled to protection under the Due Process Clause. As Rule IV itself makes clear, and as the Supreme Court of Hawaii has held in Lono v. Ariyoshi, 63 Haw., at 144-145, 621 P. 2d, at 980-981, the prison Administrator's discretion to transfer an inmate is completely unfettered. No standards govern or restrict the Administrator's determination. Because the Administrator is the only decisionmaker under Rule IV, we need not decide whether the introductory paragraph *250 of Rule IV, see n. 1, supra, places any substantive limitations on the purely advisory Program Committee.[10] The Court of Appeals thus erred in attributing significance to the fact that the prison regulations require a particular kind of hearing before the Administrator can exercise his unfettered discretion.[11] As the United States Court of Appeals for the Seventh Circuit recently stated in Shango v. Jurich, 681 F. 2d 1091, 1100-1101 (1982), '[a] liberty interest is of course a substantive interest of an individual; it cannot be the right to demand needless formality.'[12] Process is not an end in itself. Its constitutional purpose is to protect a substantive interest to which the individual has a legitimate claim of entitlement. See generally Simon, Liberty and Property in the Supreme Court: A Defense of Roth and Perry, 71 Calif. L. Rev. 146, 186 (1983). If officials may transfer a prisoner 'for whatever reason or for no reason at all,' Meachum, 427 U. S., at 228, there is no such interest for process to protect. The State may choose to require procedures for reasons other than protection against deprivation of substantive *251 rights, of course,[13] but in making that choice the State does not create an independent substantive right. See Hewitt v. Helms, 459 U. S. 460, 471 (1983). IV In sum, we hold that the transfer of respondent from Hawaii to California did not implicate the Due Process Clause directly, and that Hawaii's prison regulations do not create a protected liberty interest.[14] Accordingly, the judgment of the Court of Appeals is Reversed. JUSTICE MARSHALL, with whom JUSTICE BRENNAN joins, and with whom JUSTICE STEVENS joins as to Part I, dissenting. In my view, the transfer of respondent Delbert Kaahanui Wakinekona from a prison in Hawaii to a prison in California implicated an interest in liberty protected by the Due Process Clause of the Fourteenth Amendment. I respectfully dissent. I An inmate's liberty interest is not limited to whatever a State chooses to bestow upon him. An inmate retains a significant residuum of constitutionally protected liberty following his incarceration independent of any state law. As we stated in Wolff v. McDonnell, 418 U. S. 539, 555-556 (1974): '[A] prisoner is not wholly stripped of constitutional protections when he is imprisoned for crime. There is no iron curtain drawn between the Constitution and the prisons *252 of this country. . . . [Prisoners] may not be deprived of life, liberty, or property without due process of law.' In determining whether a change in the conditions of imprisonment implicates a prisoner's retained liberty interest, the relevant question is whether the change constitutes a sufficiently 'grievous loss' to trigger the protection of due process. Vitek v. Jones, 445 U. S. 480, 488 (1980). See Morrissey v. Brewer, 408 U. S. 471, 481 (1972), citing Joint Anti-Fascist Refugee Committee v. McGrath, 341 U. S. 123, 168 (1951) (Frankfurter, J., concurring). The answer depends in part on a comparison of 'the treatment of the particular prisoner with the customary, habitual treatment of the population of the prison as a whole.' Hewitt v. Helms, 459 U. S. 460, 486 (1983) (STEVENS, J., dissenting). This principle was established in our decision in Vitek, which held that the transfer of an inmate from a prison to a mental hospital implicated a liberty interest because it brought about 'consequences . . . qualitatively different from the punishment characteristically suffered by a person convicted of crime.' 445 U. S., at 493. Because a significant qualitative change in the conditions of confinement is not 'within the range of conditions of confinement to which a prison sentence subjects an individual,' ibid., such a change implicates a prisoner's protected liberty interest. There can be little doubt that the transfer of Wakinekona from a Hawaii prison to a prison in California represents a substantial qualitative change in the conditions of his confinement. In addition to being incarcerated, which is the ordinary consequence of a criminal conviction and sentence, Wakinekona has in effect been banished from his home, a punishment historically considered to be 'among the severest.'[1] For an indeterminate period of time, possibly the *253 rest of his life, nearly 2,500 miles of ocean will separate him from his family and friends. As a practical matter, Wakinekona may be entirely cut off from his only contacts with the outside world, just as if he had been imprisoned in an institution which prohibited visits by outsiders. Surely the isolation imposed on him by the transfer is far more drastic than that which normally accompanies imprisonment. I cannot agree with the Court that Meachum v. Fano, 427 U. S. 215 (1976), and Montanye v. Haymes, 427 U. S. 236, 243 (1976), compel the conclusion that Wakinekona's transfer implicates no liberty interest. Ante, at 248. Both cases involved transfers of prisoners between institutions located within the same State in which they were convicted, and the Court expressly phrased its holdings in terms of intrastate transfers.[2] Both decisions rested on the premise that no liberty interest is implicated by an initial decision to place a prisoner in one institution in the State rather than another. See Meachum, supra, at 224; Montanye, supra, at 243. On the basis of that premise, the Court concluded that the subsequent transfer of a prisoner to a different facility within the State likewise implicates no liberty interest. In this case, however, we cannot assume that a State's initial placement of an individual in a prison far removed from his family and residence would raise no due process questions. None of our *254 prior decisions has indicated that such a decision would be immune from scrutiny under the Due Process Clause. Actual experience simply does not bear out the Court's assumptions that interstate transfers are routine and that it is 'not unusual' for a prisoner 'to serve practically his entire sentence in a State other than the one in which he was convicted and sentenced.' Ante, at 247. In Hawaii less than three percent of the state prisoners were transferred to prisons in other jurisdictions in 1979, and on a nationwide basis less than one percent of the prisoners held in state institutions were transferred to other jurisdictions.[3] Moreover, the vast majority of state prisoners are held in facilities located less than 250 miles from their homes.[4] Measured against these norms, Wakinekona's transfer to a California prison represents a punishment 'qualitively different from the punishment characteristically suffered by a person convicted of crime.' Vitek v. Jones, supra, at 493. I therefore cannot agree that a State may transfer its prisoners at will, to any place, for any reason, without ever implicating any interest in liberty protected by the Due Process Clause. II Nor can I agree with the majority's conclusion that Hawaii's prison regulations do not create a liberty interest. This Court's prior decisions establish that a liberty interest *255 may be 'created'[5] by state laws, prison rules, regulations, or practices. State laws that impose substantive criteria which limit or guide the discretion of officials have been held to create a protected liberty interest. See, e. g., Hewitt v. Helms, 459 U. S. 460 (1983); Wolff v. McDonnell, 418 U. S. 539 (1974); Greenholtz v. Nebraska Penal Inmates, 442 U. S. 1 (1979); Wright v. Enomoto, 462 F. Supp. 397 (ND Cal. 1976), summarily aff'd, 434 U. S. 1052 (1978). By contrast, a liberty interest is not created by a law which 'imposes no conditions on [prison officials'] discretionary power,' Montanye, supra, at 243, authorizes prison officials to act 'for whatever reason or for no reason at all,' Meachum, supra, at 228, or accords officials 'unfettered discretion,' Connecticut Board of Pardons v. Dumschat, 452 U. S. 458, 466 (1981). The Court misapplies these principles in concluding that Hawaii's prison regulations leave prison officials with unfettered discretion to transfer inmates. Ante, at 249-250. Rule IV establishes a scheme under which inmates are classified upon initial placement in an institution, and must subsequently be reclassified before they can be transferred to another institution. Under the Rule the standard for classifying inmates is their 'optimum placement within the Corrections Division' in light of the 'best interests of the individual, the State, and the community.'[6] In classifying inmates, the Program *256 Committee may not consider punitive aims. It may consider only factors relevant to determining where the individual will be 'best situated,' such as 'his history, his changing needs, the resources and facilities available to the Corrections Divisions, the other inmates/wards, the exigencies of the community, and any other relevant factors.' Paragraph 3 of Rule IV establishes a detailed set of procedures applicable when, as in this case, the reclassification of a prisoner may lead to a transfer involving a 'grievous loss,' a phrase contained in the Rule itself.[7] The procedural rules are cast in mandatory language, and cover such matters as notice, access to information, hearing, confrontation and cross-examination, and the basis on which the Committee is to make its recommendation to the facility administrator. The limitations imposed by Rule IV are at least as substantial as those found sufficient to create a liberty interest in Hewitt v. Helms, supra, decided earlier this Term. In Hewitt an inmate contended that his confinement in administrative custody implicated an interest in liberty protected by the Due Process Clause. State law provided that a prison official could place inmates in administrative custody 'upon his assessment of the situation and the need for control,' or 'where it has been determined that there is a threat of a serious disturbance, or a serious threat to the individual or others,' and mandated certain procedures such as notice and a *257 hearing.[8] This Court construed the phrases ' `the need for control,' or `the threat of a serious disturbance,' ' as 'substantive predicates' which restricted official discretion. Id., at 472. These restrictions, in combination with the mandatory procedural safeguards, 'deman[ded] a conclusion that the State has created a protected liberty interest.' Ibid. Rule IV is not distinguishable in any meaningful respect from the provisions at issue in Helms. The procedural requirements contained in Rule IV are, if anything, far more elaborate than those involved in Helms, and are likewise couched in 'language of an unmistakably mandatory character.' Id., at 471. Moreover, Rule IV, to no less an extent than the state law at issue in Helms, imposes substantive criteria restricting official discretion. In Helms this Court held that a statutory phrase such as 'the need for control' constituted a limitation on the discretion of prison officials to place inmates in administrative custody. In my view Rule IV, which states that transfers are intended to ensure an inmate's 'optimum placement' in accordance with considerations which include 'his changing needs [and] the resources and facilities available to the Corrections Division,' also restricts official discretion in ordering transfers.[9] The Court suggests that, even if the Program Committee does not have unlimited discretion in making recommendations for classifications and transfers, this cannot give rise to a state-created liberty interest because the prison Administrator retains 'completely unfettered' 'discretion to transfer *258 an inmate,' ante, at 249. I disagree. Rule IV, ¶ 3(d)(3), provides for review by the prison Administrator of recommendations forwarded to him by the Program Committee.[10] Even if this provision must be construed as authorizing the Administrator to transfer a prisoner for wholly arbitrary reasons,[11] that mere possibility does not defeat the protectible expectation otherwise created by Hawaii's reclassification and transfer scheme that transfers will take place only if required to ensure an inmate's optimum placement. In Helms a prison regulation also left open the possibility that the Superintendent could decide, for any reason or no reason at all, whether an inmate should be confined in administrative custody.[12] This Court nevertheless held that the state scheme as a whole created an interest in liberty protected by the Due Process Clause. 459 U. S., at 471-472. Helms thus necessarily rejects the view that state laws which impose substantive *259 limitations and elaborate procedural requirements on official conduct create no liberty interest solely because there remains the possibility that an official will act in an arbitrary manner at the end of the process.[13] For the foregoing reasons, I dissent. NOTES [*] Briefs of amici curiae urging reversal were filed for the State of Alaska et al. by Paul L. Douglas, Attorney General of Nebraska, J. Kirk Brown, Assistant Attorney General, Judith W. Rogers, Corporation Counsel of the District of Columbia, and the Attorneys General for their respective jurisdictions as follows: Wilson L. Condon of Alaska, Aviata F. Fa'alevao of American Samoa, Robert K. Corbin of Arizona, Jim Smith of Florida, David H. Leroy of Idaho, William J. Guste, Jr., of Louisiana, William A. Allain of Mississippi, Michael T. Greely of Montana, Richard H. Bryan of Nevada, Irwin I. Kimmelman of New Jersey, Jeff Bingaman of New Mexico, Rufus L. Edmisten of North Carolina, Robert Wefald of North Dakota, William J. Brown of Ohio, Dennis J. Roberts II of Rhode Island, Mark V. Meierhenry of South Dakota, William M. Leech, Jr., of Tennessee, John J. Easton of Vermont, Gerald L. Baliles of Virginia, Kenneth O. Eikenberry of Washington, Chauncey H. Browning of West Virginia, Bronson C. La Follette of Wisconsin, and Steven F. Freudenthal of Wyoming; and for the Commonwealth of Massachusetts et al. by Francis X. Bellotti, Attorney General of Massachusetts, Stephen R. Delinsky, Barbara A. H. Smith, and Leo J. Cushing, Assistant Attorneys General, Anthony Ching, Solicitor General of Arizona, and the Attorneys General for their respective jurisdictions as follows: Wilson L. Condon of Alaska, Aviata F. Fa'alevao of American Samoa, Robert K. Corbin of Arizona, Jim Smith of Florida, David H. Leroy of Idaho, William A. Allain of Mississippi, Michael T. Greely of Montana, Irwin I. Kimmelman of New Jersey, Jeff Bingaman of New Mexico, Rufus L. Edmisten of North Carolina, Robert O. Wefald of North Dakota, William J. Brown of Ohio, Dennis J. Roberts II of Rhode Island, Mark V. Meierhenry of South Dakota, William M. Leech, Jr., of Tennessee, John J. Easton of Vermont, Chauncey H. Browning of West Virginia, and Bronson C. La Follette of Wisconsin. [1] Paragraph 1 of Rule IV states: 'An inmate's . . . classification determines where he is best situated within the Corrections Division. Rather than being concerned with isolated aspects of the individual or punishment (as is the adjustment process), classification is a dynamic process which considers the individual, his history, his changing needs, the resources and facilities available to the Corrections Division, the other inmates . . . , the exigencies of the community, and any other relevant factors. It never inflicts punishment; on the contrary, even the imposition of a stricter classification is intended to be in the best interests of the individual, the State, and the community. In short, classification is a continuing evaluation of each individual to ensure that he is given the optimum placement within the Corrections Division.' App. 20. [2] Petitioners concede, 'for purposes of the argument,' that respondent suffered a 'grievous loss' within the meaning of Rule IV when he was transferred from Hawaii to the mainland. Tr. of Oral Arg. 9, 25. [3] Rule V provides that an inmate may retain legal counsel if his hearing concerns a 'potential Interstate transfer.' App. 25. [4] Respondent also had alleged that the transfer violated the Hawaii Constitution and state regulations and statutes. In light of its dismissal of respondent's federal claims, the District Court declined to exercise pendent jurisdiction over these state-law claims. 459 F. Supp., at 476. [5] Several months before the Court of Appeals handed down its decision, the Supreme Court of Hawaii had held that because Hawaii's prison regulations do not limit the Administrator's discretion to transfer prisoners to the mainland, they do not create any liberty interest. Lono v. Ariyoshi, 63 Haw"
\ No newline at end of file
diff --git a/python/llm/example/GPU/Long-Context/LLaMA2-32K/README.md b/python/llm/example/GPU/Long-Context/LLaMA2-32K/README.md
new file mode 100644
index 00000000..677b4742
--- /dev/null
+++ b/python/llm/example/GPU/Long-Context/LLaMA2-32K/README.md
@@ -0,0 +1,130 @@
+# Llama2
+In this directory, you will find examples on how you could apply IPEX-LLM INT4 optimizations on Llama2-32K models on [Intel GPUs](../../../README.md). For illustration purposes, we utilize the [togethercomputer/Llama-2-7B-32K-Instruct](https://huggingface.co/togethercomputer/Llama-2-7B-32K-Instruct) as reference Llama2-32K models.
+
+## 0. Requirements
+To run these examples with IPEX-LLM on Intel GPUs, we have some recommended requirements for your machine, please refer to [here](../../../README.md#requirements) for more information.
+
+## Example: Predict Tokens using `generate()` API
+In the example [generate.py](./generate.py), we show a basic use case for a Llama2 model to predict the next N tokens using `generate()` API, with IPEX-LLM INT4 optimizations on Intel GPUs.
+### 1. Install
+#### 1.1 Installation on Linux
+We suggest using conda to manage environment:
+```bash
+conda create -n llm python=3.11
+conda activate llm
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+```
+
+#### 1.2 Installation on Windows
+We suggest using conda to manage environment:
+```bash
+conda create -n llm python=3.11 libuv
+conda activate llm
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+```
+
+### 2. Configures OneAPI environment variables
+#### 2.1 Configurations for Linux
+```bash
+source /opt/intel/oneapi/setvars.sh
+```
+#### 2.2 Configurations for Windows
+```cmd
+call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
+```
+> Note: Please make sure you are using **CMD** (**Anaconda Prompt** if using conda) to run the command as PowerShell is not supported.
+### 3. Runtime Configurations
+For optimal performance, it is recommended to set several environment variables. Please check out the suggestions based on your device.
+#### 3.1 Configurations for Linux
+
+
+For Intel Arc™ A-Series Graphics and Intel Data Center GPU Flex Series
+
+```bash
+export USE_XETLA=OFF
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+```
+
+
+
+
+
+For Intel Data Center GPU Max Series
+
+```bash
+export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libtcmalloc.so
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+export ENABLE_SDP_FUSION=1
+```
+> Note: Please note that `libtcmalloc.so` can be installed by `conda install -c conda-forge -y gperftools=2.10`.
+
+
+#### 3.2 Configurations for Windows
+
+
+For Intel iGPU
+
+```cmd
+set SYCL_CACHE_PERSISTENT=1
+set BIGDL_LLM_XMX_DISABLED=1
+```
+
+
+
+
+
+For Intel Arc™ A300-Series or Pro A60
+
+```cmd
+set SYCL_CACHE_PERSISTENT=1
+```
+
+
+
+
+
+For other Intel dGPU Series
+
+There is no need to set further environment variables.
+
+
+
+> Note: For the first time that each model runs on Intel iGPU/Intel Arc™ A300-Series or Pro A60, it may take several minutes to compile.
+### 4. Running examples
+#### 4.1 Using simple prompt
+```
+python ./generate.py --repo-id-or-model-path REPO_ID_OR_MODEL_PATH --prompt PROMPT --n-predict N_PREDICT
+```
+
+Arguments info:
+- `--repo-id-or-model-path REPO_ID_OR_MODEL_PATH`: argument defining the huggingface repo id for the Llama2 model (e.g. `togethercomputer/Llama-2-7B-32K-Instruct`) to be downloaded, or the path to the huggingface checkpoint folder. It is default to be `'togethercomputer/Llama-2-7B-32K-Instruct'`.
+- `--prompt PROMPT`: argument defining the prompt to be infered (with integrated prompt format for chat). It is default to be `'What is AI?'`.
+- `--n-predict N_PREDICT`: argument defining the max number of tokens to predict. It is default to be `32`.
+
+#### 4.2 Using 8k input size prompt
+You can set the `prompt` argument to be a `.txt` file path containing the 8k size prompt text. An example command using the 8k input size prompt we provide is given below:
+```
+python ./generate.py --repo-id-or-model-path togethercomputer/Llama-2-7B-32K-Instruct --prompt 8k.txt
+```
+> Note: If you need to use less memory, please set `IPEX_LLM_LOW_MEM=1`, which will enable memory optimization and may slightly affect the latency performance.
+#### Sample Output
+#### [togethercomputer/Llama-2-7B-32K-Instruct](https://huggingface.co/togethercomputer/Llama-2-7B-32K-Instruct)
+```log
+Inference time: xxxx s
+-------------------- Prompt --------------------
+[INST] <>
+
+<>
+
+What is AI? [/INST]
+-------------------- Output --------------------
+[INST] <>
+
+<>
+
+What is AI? [/INST]
+
+AI is a broad field of study that deals with the creation of intelligent agents, which are systems that can perform tasks that typically require human intelligence
+```
diff --git a/python/llm/example/GPU/Long-Context/LLaMA2-32K/generate.py b/python/llm/example/GPU/Long-Context/LLaMA2-32K/generate.py
new file mode 100644
index 00000000..73b5c535
--- /dev/null
+++ b/python/llm/example/GPU/Long-Context/LLaMA2-32K/generate.py
@@ -0,0 +1,97 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import torch
+import time
+import argparse
+
+from ipex_llm.transformers import AutoModelForCausalLM
+from transformers import LlamaTokenizer
+
+# you could tune the prompt based on your own model,
+# here the prompt tuning refers to https://huggingface.co/georgesung/llama2_7b_chat_uncensored#prompt-style
+DEFAULT_SYSTEM_PROMPT = """\
+"""
+
+def get_prompt(message: str, chat_history: list[tuple[str, str]],
+ system_prompt: str) -> str:
+ texts = [f'[INST] <>\n{system_prompt}\n<>\n\n']
+ # The first user input is _not_ stripped
+ do_strip = False
+ for user_input, response in chat_history:
+ user_input = user_input.strip() if do_strip else user_input
+ do_strip = True
+ texts.append(f'{user_input} [/INST] {response.strip()} [INST] ')
+ message = message.strip() if do_strip else message
+ texts.append(f'{message} [/INST]')
+ return ''.join(texts)
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Predict Tokens using `generate()` API for Llama2-32K model')
+ parser.add_argument('--repo-id-or-model-path', type=str, default="togethercomputer/Llama-2-7B-32K-Instruct",
+ help='The huggingface repo id for the Llama2-32K (e.g. `togethercomputer/Llama-2-7B-32K-Instruct`) to be downloaded'
+ ', or the path to the huggingface checkpoint folder')
+ parser.add_argument('--prompt', type=str, default="What is AI?",
+ help='Prompt to infer')
+ parser.add_argument('--n-predict', type=int, default=32,
+ help='Max tokens to predict')
+
+ args = parser.parse_args()
+ model_path = args.repo_id_or_model_path
+
+ # Load model in 4 bit,
+ # which convert the relevant layers in the model into INT4 format
+ # When running LLMs on Intel iGPUs for Windows users, we recommend setting `cpu_embedding=True` in the from_pretrained function.
+ # This will allow the memory-intensive embedding layer to utilize the CPU instead of iGPU.
+ model = AutoModelForCausalLM.from_pretrained(model_path,
+ load_in_4bit=True,
+ optimize_model=True,
+ trust_remote_code=True,
+ use_cache=True)
+ model = model.half().to('xpu')
+
+ # Load tokenizer
+ tokenizer = LlamaTokenizer.from_pretrained(model_path, trust_remote_code=True)
+
+ # Generate predicted tokens
+ with torch.inference_mode():
+ if not args.prompt.endswith('.txt'):
+ prompt = get_prompt(args.prompt, [], system_prompt=DEFAULT_SYSTEM_PROMPT)
+ else:
+ with open(args.prompt, 'r') as f:
+ prompt = f.read()
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to('xpu')
+ # ipex_llm model needs a warmup, then inference time can be accurate
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+
+ # start inference
+ st = time.time()
+ # if your selected model is capable of utilizing previous key/value attentions
+ # to enhance decoding speed, but has `"use_cache": false` in its model config,
+ # it is important to set `use_cache=True` explicitly in the `generate` function
+ # to obtain optimal performance with IPEX-LLM INT4 optimizations
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+ torch.xpu.synchronize()
+ end = time.time()
+ output = output.cpu()
+ output_str = tokenizer.decode(output[0], skip_special_tokens=True)
+ print(f'Inference time: {end-st} s')
+ print('-'*20, 'Prompt', '-'*20)
+ print(prompt)
+ print('-'*20, 'Output', '-'*20)
+ print(output_str)
diff --git a/python/llm/example/GPU/ModelScope-Models/README.md b/python/llm/example/GPU/ModelScope-Models/README.md
index 331638a3..fe3227c2 100644
--- a/python/llm/example/GPU/ModelScope-Models/README.md
+++ b/python/llm/example/GPU/ModelScope-Models/README.md
@@ -11,7 +11,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Chat
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -22,7 +22,7 @@ pip install modelscope==1.11.0
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/ModelScope-Models/Save-Load/README.md b/python/llm/example/GPU/ModelScope-Models/Save-Load/README.md
index 2dfcc238..33b1b900 100644
--- a/python/llm/example/GPU/ModelScope-Models/Save-Load/README.md
+++ b/python/llm/example/GPU/ModelScope-Models/Save-Load/README.md
@@ -11,7 +11,7 @@ In the example [generate.py](./generate.py), we show a basic use case of saving/
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -21,7 +21,7 @@ pip install modelscope==1.11.0
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/Pipeline-Parallel-Inference/README.md b/python/llm/example/GPU/Pipeline-Parallel-Inference/README.md
index 7162b757..58379184 100644
--- a/python/llm/example/GPU/Pipeline-Parallel-Inference/README.md
+++ b/python/llm/example/GPU/Pipeline-Parallel-Inference/README.md
@@ -10,7 +10,7 @@ To run this example with IPEX-LLM on Intel GPUs, we have some recommended requir
### 1.1 Install IPEX-LLM
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
# you can install specific ipex/torch version for your need
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/aquila2/README.md b/python/llm/example/GPU/PyTorch-Models/Model/aquila2/README.md
index a9597f97..32da14ea 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/aquila2/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/aquila2/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -22,7 +22,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/baichuan/README.md b/python/llm/example/GPU/PyTorch-Models/Model/baichuan/README.md
index ce470ec9..be7501ec 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/baichuan/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/baichuan/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -23,7 +23,7 @@ pip install transformers_stream_generator # additional package required for Bai
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/baichuan2/README.md b/python/llm/example/GPU/PyTorch-Models/Model/baichuan2/README.md
index fdf78524..11e5dad8 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/baichuan2/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/baichuan2/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -23,7 +23,7 @@ pip install transformers_stream_generator # additional package required for Bai
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/bark/README.md b/python/llm/example/GPU/PyTorch-Models/Model/bark/README.md
index 07d9411a..05f34949 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/bark/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/bark/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -23,7 +23,7 @@ pip install scipy
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/bluelm/README.md b/python/llm/example/GPU/PyTorch-Models/Model/bluelm/README.md
index 8eac3142..fc6f47fb 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/bluelm/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/bluelm/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -22,7 +22,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/chatglm2/README.md b/python/llm/example/GPU/PyTorch-Models/Model/chatglm2/README.md
index 72c0e775..afda5bb6 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/chatglm2/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/chatglm2/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -22,7 +22,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -136,7 +136,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -146,7 +146,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/chatglm3/README.md b/python/llm/example/GPU/PyTorch-Models/Model/chatglm3/README.md
index df8ed461..278888b9 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/chatglm3/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/chatglm3/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -22,7 +22,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -135,7 +135,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -145,7 +145,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/codellama/README.md b/python/llm/example/GPU/PyTorch-Models/Model/codellama/README.md
index 0c9ac640..01115cef 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/codellama/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/codellama/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -23,7 +23,7 @@ pip install transformers==4.34.1 # CodeLlamaTokenizer is supported in higher ver
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/deciLM-7b/README.md b/python/llm/example/GPU/PyTorch-Models/Model/deciLM-7b/README.md
index 01206c19..644c0205 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/deciLM-7b/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/deciLM-7b/README.md
@@ -13,7 +13,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.0.110+xpu as default
@@ -25,7 +25,7 @@ pip install transformers==4.35.2 # required by DeciLM-7B
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/deepseek/README.md b/python/llm/example/GPU/PyTorch-Models/Model/deepseek/README.md
index 55d5eaab..d3c76f9f 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/deepseek/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/deepseek/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.0.110+xpu as default
@@ -23,7 +23,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/distil-whisper/README.md b/python/llm/example/GPU/PyTorch-Models/Model/distil-whisper/README.md
index 9de7587b..d72abcf3 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/distil-whisper/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/distil-whisper/README.md
@@ -13,7 +13,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -23,7 +23,7 @@ pip install datasets soundfile librosa # required by audio processing
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/dolly-v1/README.md b/python/llm/example/GPU/PyTorch-Models/Model/dolly-v1/README.md
index 6a67390c..4f80a814 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/dolly-v1/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/dolly-v1/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -22,7 +22,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/dolly-v2/README.md b/python/llm/example/GPU/PyTorch-Models/Model/dolly-v2/README.md
index 24871ddb..28dab67b 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/dolly-v2/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/dolly-v2/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -22,7 +22,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/flan-t5/README.md b/python/llm/example/GPU/PyTorch-Models/Model/flan-t5/README.md
index 84714a32..d42a7cb2 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/flan-t5/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/flan-t5/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -22,7 +22,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/internlm2/README.md b/python/llm/example/GPU/PyTorch-Models/Model/internlm2/README.md
index d58d103e..a6e32dd8 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/internlm2/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/internlm2/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Inte
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -19,7 +19,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/llama2/README.md b/python/llm/example/GPU/PyTorch-Models/Model/llama2/README.md
index ab29daa6..b801c7fb 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/llama2/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/llama2/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -22,7 +22,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/llama2/low_memory_generate.py b/python/llm/example/GPU/PyTorch-Models/Model/llama2/low_memory_generate.py
index 55c9e70b..e5d2d65d 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/llama2/low_memory_generate.py
+++ b/python/llm/example/GPU/PyTorch-Models/Model/llama2/low_memory_generate.py
@@ -28,6 +28,7 @@ import torch.nn as nn
from accelerate import init_empty_weights
from safetensors.torch import load_file, save_file
from tqdm.auto import tqdm
+import transformers
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationMixin
from transformers.modeling_outputs import CausalLMOutputWithPast
@@ -247,6 +248,12 @@ class LowMemoryLlama(GenerationMixin):
*args,
**kwargs,
):
+ from packaging import version
+ trans_version = transformers.__version__
+ if version.parse(trans_version) >= version.parse("4.36.0"):
+ transformers_4_36 = True
+ else:
+ transformers_4_36 = False
# Reinit model and clean memory
del self.model
@@ -257,18 +264,23 @@ class LowMemoryLlama(GenerationMixin):
# Send batch to device
inputs = input_ids.to(self.device)
+ current_shape = inputs.shape[1]
# Set up kv cache
- kv_cache = {}
- if past_key_values is None:
- past_key_values = {}
+ if transformers_4_36:
+ from transformers.cache_utils import Cache, DynamicCache
+ use_legacy_cache = not isinstance(past_key_values, Cache)
+ if use_legacy_cache:
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+ pre_shape = past_key_values.get_usable_length(current_shape)
+ else:
+ if past_key_values is not None:
+ pre_shape = past_key_values[0][0].size(2)
+ else:
+ pre_shape = 0
+ past_key_values = [None] * len(self.model.model.layers)
with torch.inference_mode():
# Generate attention mask and position ids
- current_shape = inputs.shape[1]
- if past_key_values.get(self.layer_names[1], None):
- pre_shape = past_key_values[self.layer_names[1]][0].size(2)
- else:
- pre_shape = 0
pos = self.position_ids[:, pre_shape : current_shape + pre_shape]
attn = self.attention_mask[:, :, -current_shape:, - current_shape - pre_shape:]
@@ -282,9 +294,14 @@ class LowMemoryLlama(GenerationMixin):
if layer_name in ("model.embed_tokens", "model.norm", "lm_head"):
inputs = layer(inputs)
else:
- inputs, new_kv_cache = layer(inputs, use_cache=True, past_key_value=past_key_values.get(layer_name, None),
+ decoder_layer_index = int(layer_name.split('.')[-1])
+ past_key_value = past_key_values if transformers_4_36 else past_key_values[decoder_layer_index]
+ inputs, new_kv_cache = layer(inputs, use_cache=True, past_key_value=past_key_value,
position_ids=pos, attention_mask=attn)
- kv_cache[layer_name] = new_kv_cache
+ if transformers_4_36:
+ past_key_values = new_kv_cache
+ else:
+ past_key_values[decoder_layer_index] = new_kv_cache
# Delete weight before moving to('meta')
for module in layer.modules():
@@ -296,7 +313,7 @@ class LowMemoryLlama(GenerationMixin):
result = CausalLMOutputWithPast(
logits=inputs.detach(),
- past_key_values=kv_cache,
+ past_key_values=past_key_values,
)
return result
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/llava/README.md b/python/llm/example/GPU/PyTorch-Models/Model/llava/README.md
index aff37cd1..668c63a8 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/llava/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/llava/README.md
@@ -12,30 +12,35 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
-
-git clone -b v1.1.1 --depth=1 https://github.com/haotian-liu/LLaVA.git # clone the llava libary
pip install einops # install dependencies required by llava
+pip install transformers==4.36.2
+
+git clone https://github.com/haotian-liu/LLaVA.git # clone the llava libary
cp generate.py ./LLaVA/ # copy our example to the LLaVA folder
cd LLaVA # change the working directory to the LLaVA folder
+git checkout tags/v1.2.0 -b 1.2.0 # Get the branch which is compatible with transformers 4.36
```
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
-
-git clone -b v1.1.1 --depth=1 https://github.com/haotian-liu/LLaVA.git # clone the llava libary
pip install einops # install dependencies required by llava
+pip install transformers==4.36.2
+
+git clone https://github.com/haotian-liu/LLaVA.git # clone the llava libary
cp generate.py ./LLaVA/ # copy our example to the LLaVA folder
cd LLaVA # change the working directory to the LLaVA folder
+git checkout tags/v1.2.0 -b 1.2.0 # Get the branch which is compatible with transformers 4.36
+
```
### 2. Configures OneAPI environment variables
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/llava/generate.py b/python/llm/example/GPU/PyTorch-Models/Model/llava/generate.py
index ce3275df..84c8b726 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/llava/generate.py
+++ b/python/llm/example/GPU/PyTorch-Models/Model/llava/generate.py
@@ -39,6 +39,7 @@ import time
from transformers import AutoModelForCausalLM
from llava.model.language_model.llava_llama import LlavaLlamaForCausalLM
from transformers import AutoTokenizer
+from transformers import TextStreamer
from llava.constants import (
DEFAULT_IMAGE_PATCH_TOKEN,
@@ -312,11 +313,14 @@ if __name__ == '__main__':
print("exit...")
break
+ print(f"{roles[1]}: ", end="")
+
prompt = get_prompt(model.config.mm_use_im_start_end, first_round, conv, user_input)
first_round = False
input_ids = tokenizer_image_token(
prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).to('xpu')
stopping_criteria = get_stopping_criteria(conv, tokenizer, input_ids)
+ streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
# Generate predicted tokens
with torch.inference_mode():
@@ -326,13 +330,11 @@ if __name__ == '__main__':
images=image_tensor,
do_sample=True,
max_new_tokens=args.n_predict,
+ streamer=streamer,
use_cache=True,
stopping_criteria=[stopping_criteria])
end = time.time()
#print(f'Inference time: {end-st} s')
- outputs = tokenizer.decode(
- output_ids[0, input_ids.shape[1]:].cpu(), skip_special_tokens=True).strip()
+ outputs = tokenizer.decode(output_ids[0, :].cpu(), skip_special_tokens=True).strip()
conv.messages[-1][-1] = outputs
- print(f"{roles[1]}: ", end="")
- print(outputs)
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/mamba/README.md b/python/llm/example/GPU/PyTorch-Models/Model/mamba/README.md
index 085e440d..7c30497a 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/mamba/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/mamba/README.md
@@ -11,7 +11,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.0.110+xpu as default
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/mistral/README.md b/python/llm/example/GPU/PyTorch-Models/Model/mistral/README.md
index 8fdaa738..565470e5 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/mistral/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/mistral/README.md
@@ -14,7 +14,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -27,7 +27,7 @@ pip install transformers==4.34.0
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/mixtral/README.md b/python/llm/example/GPU/PyTorch-Models/Model/mixtral/README.md
index d617ed4e..8f4a4dab 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/mixtral/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/mixtral/README.md
@@ -14,7 +14,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -27,7 +27,7 @@ pip install transformers==4.36.0
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/phi-1_5/README.md b/python/llm/example/GPU/PyTorch-Models/Model/phi-1_5/README.md
index 3a45012b..54a72a07 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/phi-1_5/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/phi-1_5/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -22,7 +22,7 @@ pip install einops # additional package required for phi-1_5 to conduct generati
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/phi-2/README.md b/python/llm/example/GPU/PyTorch-Models/Model/phi-2/README.md
index 0f6c8bbf..4a201625 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/phi-2/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/phi-2/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -21,7 +21,7 @@ pip install einops # additional package required for phi-2 to conduct generation
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/phixtral/README.md b/python/llm/example/GPU/PyTorch-Models/Model/phixtral/README.md
index 61743b12..9f1a33be 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/phixtral/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/phixtral/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -22,7 +22,7 @@ pip install einops # additional package required for phixtral to conduct generat
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/qwen-vl/README.md b/python/llm/example/GPU/PyTorch-Models/Model/qwen-vl/README.md
index 80a65a59..473cac40 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/qwen-vl/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/qwen-vl/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -22,7 +22,7 @@ pip install accelerate tiktoken einops transformers_stream_generator==0.0.4 scip
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/qwen1.5/README.md b/python/llm/example/GPU/PyTorch-Models/Model/qwen1.5/README.md
index daed4390..86b0f8c7 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/qwen1.5/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/qwen1.5/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case for a Qwen
#### 1.1 Installation on Linux
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
@@ -20,7 +20,7 @@ pip install transformers==4.37.0 # install transformers which supports Qwen2
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/replit/README.md b/python/llm/example/GPU/PyTorch-Models/Model/replit/README.md
index f9c19c19..8ad73633 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/replit/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/replit/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -23,7 +23,7 @@ pip install "transformers<4.35"
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/solar/README.md b/python/llm/example/GPU/PyTorch-Models/Model/solar/README.md
index 6eb6f052..e0802db7 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/solar/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/solar/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -23,7 +23,7 @@ pip install transformers==4.35.2 # required by SOLAR
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/speech-t5/README.md b/python/llm/example/GPU/PyTorch-Models/Model/speech-t5/README.md
index 239877c6..a0a1020c 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/speech-t5/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/speech-t5/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -23,7 +23,7 @@ pip install "datasets<2.18" soundfile # additional package required for SpeechT5
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/stablelm/README.md b/python/llm/example/GPU/PyTorch-Models/Model/stablelm/README.md
index 656195b1..f322d64f 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/stablelm/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/stablelm/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -25,7 +25,7 @@ pip install transformers==4.38.0
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/starcoder/README.md b/python/llm/example/GPU/PyTorch-Models/Model/starcoder/README.md
index ae0eee66..9580c1a8 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/starcoder/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/starcoder/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -22,7 +22,7 @@ pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-exte
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/yi/README.md b/python/llm/example/GPU/PyTorch-Models/Model/yi/README.md
index 4562972e..bac21baf 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/yi/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/yi/README.md
@@ -12,7 +12,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9 # recommend to use Python 3.9
+conda create -n llm python=3.11 # recommend to use Python 3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
@@ -23,7 +23,7 @@ pip install einops # additional package required for Yi-6B to conduct generation
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/yuan2/README.md b/python/llm/example/GPU/PyTorch-Models/Model/yuan2/README.md
index c5364a42..2def531d 100644
--- a/python/llm/example/GPU/PyTorch-Models/Model/yuan2/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Model/yuan2/README.md
@@ -14,7 +14,7 @@ We suggest using conda to manage the Python environment. For more information ab
After installing conda, create a Python environment for IPEX-LLM:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all] # install the latest ipex-llm nightly build with 'all' option
@@ -24,7 +24,7 @@ pip install pandas # additional package required for Yuan2 to conduct generation
#### 1.2 Installation on Windows
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9 libuv
+conda create -n llm python=3.11 libuv
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/More-Data-Types/README.md b/python/llm/example/GPU/PyTorch-Models/More-Data-Types/README.md
index e3b223df..4a739e55 100644
--- a/python/llm/example/GPU/PyTorch-Models/More-Data-Types/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/More-Data-Types/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case of low-bit
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/PyTorch-Models/Save-Load/README.md b/python/llm/example/GPU/PyTorch-Models/Save-Load/README.md
index 93962516..0efc1af2 100644
--- a/python/llm/example/GPU/PyTorch-Models/Save-Load/README.md
+++ b/python/llm/example/GPU/PyTorch-Models/Save-Load/README.md
@@ -10,7 +10,7 @@ In the example [generate.py](./generate.py), we show a basic use case of saving/
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/Speculative-Decoding/baichuan2/README.md b/python/llm/example/GPU/Speculative-Decoding/baichuan2/README.md
index 8f82d35f..2f9fd573 100644
--- a/python/llm/example/GPU/Speculative-Decoding/baichuan2/README.md
+++ b/python/llm/example/GPU/Speculative-Decoding/baichuan2/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/Speculative-Decoding/chatglm3/README.md b/python/llm/example/GPU/Speculative-Decoding/chatglm3/README.md
index eec1f6ed..8766bf3d 100644
--- a/python/llm/example/GPU/Speculative-Decoding/chatglm3/README.md
+++ b/python/llm/example/GPU/Speculative-Decoding/chatglm3/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/Speculative-Decoding/gpt-j/README.md b/python/llm/example/GPU/Speculative-Decoding/gpt-j/README.md
index 9ec03e5e..9f82533a 100644
--- a/python/llm/example/GPU/Speculative-Decoding/gpt-j/README.md
+++ b/python/llm/example/GPU/Speculative-Decoding/gpt-j/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/Speculative-Decoding/llama2/README.md b/python/llm/example/GPU/Speculative-Decoding/llama2/README.md
index a8648c1d..d25f77c6 100644
--- a/python/llm/example/GPU/Speculative-Decoding/llama2/README.md
+++ b/python/llm/example/GPU/Speculative-Decoding/llama2/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/Speculative-Decoding/mistral/README.md b/python/llm/example/GPU/Speculative-Decoding/mistral/README.md
index eebad70a..12fbeb41 100644
--- a/python/llm/example/GPU/Speculative-Decoding/mistral/README.md
+++ b/python/llm/example/GPU/Speculative-Decoding/mistral/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/Speculative-Decoding/qwen/README.md b/python/llm/example/GPU/Speculative-Decoding/qwen/README.md
index 40607d1f..515aaf7b 100644
--- a/python/llm/example/GPU/Speculative-Decoding/qwen/README.md
+++ b/python/llm/example/GPU/Speculative-Decoding/qwen/README.md
@@ -9,7 +9,7 @@ In the example [speculative.py](./speculative.py), we show a basic use case for
### 1. Install
We suggest using conda to manage environment:
```bash
-conda create -n llm python=3.9
+conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
diff --git a/python/llm/example/GPU/vLLM-Serving/README.md b/python/llm/example/GPU/vLLM-Serving/README.md
index 02f72379..92079c89 100644
--- a/python/llm/example/GPU/vLLM-Serving/README.md
+++ b/python/llm/example/GPU/vLLM-Serving/README.md
@@ -31,7 +31,7 @@ To run vLLM continuous batching on Intel GPUs, install the dependencies as follo
```bash
# First create an conda environment
-conda create -n ipex-vllm python==3.9
+conda create -n ipex-vllm python=3.11
conda activate ipex-vllm
# Install dependencies
pip3 install psutil
diff --git a/python/llm/scripts/env-check.sh b/python/llm/scripts/env-check.sh
index 7169858e..75cd1614 100644
--- a/python/llm/scripts/env-check.sh
+++ b/python/llm/scripts/env-check.sh
@@ -20,7 +20,7 @@ check_python()
retval="0"
fi
else
- echo "No Python found! Please use `conda create -n llm python=3.9` to create environment. More details could be found in the README.md"
+ echo "No Python found! Please use `conda create -n llm python=3.11` to create environment. More details could be found in the README.md"
retval="1"
fi
return "$retval"
@@ -65,18 +65,16 @@ check_cpu_info()
lscpu | head -n 17
}
-check_memory_type()
-{
- echo "-----------------------------------------------------------------"
- echo "CPU type: "
- sudo dmidecode -t 17 | grep DDR
-
-}
-
check_mem_info()
{
echo "-----------------------------------------------------------------"
- cat /proc/meminfo | grep "MemTotal" | awk '{print "Total Memory: " $2/1024/1024 " GB"}'
+ cat /proc/meminfo | grep "MemTotal" | awk '{print "Total CPU Memory: " $2/1024/1024 " GB"}'
+
+ # Check if sudo session exists
+ if sudo -n true 2>/dev/null; then
+ echo -n "Memory Type: "
+ sudo dmidecode --type memory | grep -m 1 DDR | awk '{print $2, $3}'
+ fi
}
@@ -123,9 +121,9 @@ check_xpu_smi()
check_ipex()
{
echo "-----------------------------------------------------------------"
- if python -c "import intel_extension_for_pytorch as ipex; print(ipex.__version__)" >/dev/null 2>&1
+ if python -c "import warnings; warnings.filterwarnings('ignore'); import intel_extension_for_pytorch as ipex; print(ipex.__version__)" >/dev/null 2>&1
then
- VERSION=`python -c "import intel_extension_for_pytorch as ipex; print(ipex.__version__)"`
+ VERSION=`python -c "import warnings; warnings.filterwarnings('ignore'); import intel_extension_for_pytorch as ipex; print(ipex.__version__)"`
echo "ipex=$VERSION"
else
echo "IPEX is not installed. "
@@ -135,7 +133,7 @@ check_ipex()
check_xpu_info()
{
echo "-----------------------------------------------------------------"
- lspci -v | grep -i vga -A 8
+ lspci -v | grep -i vga -A 8 | awk '/Memory/ {gsub(/\[size=[0-9]+G\]/,"\033[1;33m&\033[0m")} 1'
}
check_linux_kernel_version()
@@ -167,6 +165,11 @@ check_igpu()
fi
}
+check_gpu_memory()
+{
+ lspci -v | grep -i vga -A 8 | awk '/VGA compatible controller/ {getline; getline; getline; getline; print "GPU" i++ " Memory", substr($0, length($0)-index($0," "), index($0," "))}'
+}
+
main()
{
# first guarantee correct python is installed.
@@ -186,11 +189,9 @@ main()
# verify hardware (how many gpu availables, gpu status, cpu info, memory info, etc.)
check_cpu_info
check_mem_info
- # check_memory_type
# check_ulimit
check_os
# check_env
- check_xpu_info
check_linux_kernel_version
check_xpu_driver
check_OpenCL_driver
@@ -206,6 +207,10 @@ main()
check_xpu_smi
fi
+ check_gpu_memory
+
+ check_xpu_info
+
echo "-----------------------------------------------------------------"
}
diff --git a/python/llm/setup.py b/python/llm/setup.py
index 02fabbbb..48689570 100644
--- a/python/llm/setup.py
+++ b/python/llm/setup.py
@@ -291,7 +291,7 @@ def setup_package():
"torchvision==0.16.0a0",
"intel_extension_for_pytorch==2.1.10+xpu",
"bigdl-core-xe-21==" + CORE_XE_VERSION,
- "bigdl-core-xe-esimd-21==" + CORE_XE_VERSION + ";platform_system=='Linux'"]
+ "bigdl-core-xe-esimd-21==" + CORE_XE_VERSION]
# default to ipex 2.1 for linux and windows
xpu_requires = copy.deepcopy(xpu_21_requires)
diff --git a/python/llm/src/ipex_llm/transformers/convert.py b/python/llm/src/ipex_llm/transformers/convert.py
index e8c24db1..ff133b35 100644
--- a/python/llm/src/ipex_llm/transformers/convert.py
+++ b/python/llm/src/ipex_llm/transformers/convert.py
@@ -527,6 +527,16 @@ def replace_with_low_bit_linear_for_module(model, qtype, module_name=None,
def _optimize_pre(model):
+ try:
+ from sentence_transformers.SentenceTransformer import SentenceTransformer
+ if isinstance(model, SentenceTransformer):
+ if str(model._modules['0']).strip().split(' ')[-1] == 'BertModel':
+ from ipex_llm.transformers.models.bert import merge_qkv
+ model.apply(merge_qkv)
+ return model
+ except ModuleNotFoundError:
+ pass
+
from transformers.modeling_utils import PreTrainedModel
# All huggingface format models are inherited from `PreTrainedModel`
if not isinstance(model, PreTrainedModel):
@@ -793,6 +803,24 @@ def _optimize_post(model, lightweight_bmm=False):
from ipex_llm.transformers.models.llama import llama_model_forward
from transformers.modeling_utils import PreTrainedModel
+ try:
+ from sentence_transformers.SentenceTransformer import SentenceTransformer
+ if isinstance(model, SentenceTransformer):
+ if str(model._modules['0']).strip().split(' ')[-1] == 'BertModel':
+ modeling_module_name = model._modules['0'].auto_model.__class__.__module__
+ module = importlib.import_module(modeling_module_name)
+ from ipex_llm.transformers.models.bert import self_attention_forward
+ from ipex_llm.transformers.models.bert import encoder_forward
+ convert_forward(model,
+ module.BertSelfAttention,
+ self_attention_forward)
+ convert_forward(model,
+ module.BertEncoder,
+ encoder_forward)
+ return model
+ except ModuleNotFoundError:
+ pass
+
# All huggingface format models are inherited from `PreTrainedModel`
if not isinstance(model, PreTrainedModel):
logger.info("Only HuggingFace Transformers models are currently "
@@ -861,7 +889,8 @@ def _optimize_post(model, lightweight_bmm=False):
if model.config.architectures is not None \
and model.config.architectures[0] in ["ChatGLMModel", "ChatGLMForConditionalGeneration"]:
- if model.config.num_layers == 28 and hasattr(model.config, 'rope_ratio'):
+ if (model.config.num_layers == 28 and hasattr(model.config, 'rope_ratio')
+ and model.config.rope_ratio == 16):
# chatglm2-6b-32k
modeling_module_name = model.__class__.__module__
module = importlib.import_module(modeling_module_name)
@@ -1004,10 +1033,18 @@ def _optimize_post(model, lightweight_bmm=False):
convert_forward(model,
module.MLP,
baichuan_mlp_forward)
- replace_func(model,
- module.BaichuanModel,
- "get_alibi_mask",
- baichuan_13b_get_alibi_mask)
+ if hasattr(model.model, 'get_alibi_mask_orig'):
+ # deepspeed rewrite "get_alibi_mask" to support baichuan
+ # https://github.com/microsoft/DeepSpeed/pull/4721
+ replace_func(model,
+ module.BaichuanModel,
+ "get_alibi_mask_orig",
+ baichuan_13b_get_alibi_mask)
+ else:
+ replace_func(model,
+ module.BaichuanModel,
+ "get_alibi_mask",
+ baichuan_13b_get_alibi_mask)
elif model.config.model_type == "baichuan":
# baichuan1
if model.config.hidden_size == 4096:
diff --git a/python/llm/src/ipex_llm/transformers/low_bit_linear.py b/python/llm/src/ipex_llm/transformers/low_bit_linear.py
index 96f57167..0acca42a 100644
--- a/python/llm/src/ipex_llm/transformers/low_bit_linear.py
+++ b/python/llm/src/ipex_llm/transformers/low_bit_linear.py
@@ -75,10 +75,12 @@ IQ2_XS = ggml_tensor_qtype["gguf_iq2_xs"]
Q2_K = ggml_tensor_qtype["q2_k"]
IQ1_S = ggml_tensor_qtype["gguf_iq1_s"]
+
+# For sym_int4
# The ggml_weight is col major and packs two rows at a stride of Q4_0//2.
#
# The returning weight is row major and packs two rows at a stride of 16//2.
-# 16 is the tile_size_y used in mm_int4, so that we can do something like
+# 16 is the tile_size_y used in mm_xetla, so that we can do something like
# new_weight_tile = concat(weight_tile & 0x0F, weight_tile >> 4).
#
# A more complex packing strategy is to permute the weight so that the
@@ -87,43 +89,97 @@ IQ1_S = ggml_tensor_qtype["gguf_iq1_s"]
#
# Note this format cannot be used directly in IPEX-LLM's mm_int4, which expects
# row major but packing two consecutive columns.
+#
+# For fp8, just remove the scales (which are all ones) and transpose
+def ggml_xpu_to_ipex_llm_xetla(ggml_weight, weight_shape, qtype):
+ if qtype == ggml_tensor_qtype["sym_int4"]:
+ from ipex_llm.transformers.low_bit_linear import get_block_size
+ Q4_0 = get_block_size("sym_int4")
+
+ n, k = weight_shape
+ ggml_weight_only = ggml_weight[:n*k//2]
+ ggml_scales = ggml_weight[n*k//2:]
+
+ qweight = ggml_weight_only.clone()
+ scales = ggml_scales.view(torch.float16).clone()
+
+ qweight_0 = qweight & 0x0F
+ qweight_1 = qweight >> 4
+
+ qweight_0 = qweight_0.reshape(n, -1, Q4_0//2)
+ qweight_1 = qweight_1.reshape(n, -1, Q4_0//2)
+ qweight = torch.cat([qweight_0, qweight_1], dim=-1)
+ qweight = qweight.reshape(n, k//16, 2, 8)
+ qweight = qweight.bitwise_left_shift(
+ torch.tensor([0, 4], dtype=torch.uint8, device=ggml_weight.device).reshape(1, 1, 2, 1))
+
+ qweight = torch.bitwise_or(qweight[:, :, 0, :], qweight[:, :, 1, :])
+ qweight = qweight.reshape(n, k//2)
+ qweight = qweight.transpose(0, 1).contiguous()
+
+ scales = scales.reshape(n, k//Q4_0).transpose(0, 1).contiguous()
+
+ # 119 is the value of 0x77
+ zeros = torch.ones([k//Q4_0, n//2], dtype=torch.uint8, device=ggml_weight.device) * (119)
+
+ qweight_bytes = qweight.view(torch.uint8).view(-1)
+ scales_bytes = scales.view(torch.uint8).view(-1)
+ zeros_bytes = zeros.view(torch.uint8).view(-1)
+
+ weight = torch.concat([qweight_bytes, zeros_bytes, scales_bytes], dim=0)
+ elif qtype == ggml_tensor_qtype["fp8_e5m2"]:
+ n, k = weight_shape
+ weight = ggml_weight[:n*k].view(n, k).transpose(0, 1).contiguous()
+ else:
+ invalidInputError(False, f"Unsupported qtype {qtype}")
+ return weight
-def q4_0_xpu_transpose(ggml_weight, weight_shape):
+def ipex_llm_xetla_to_ggml_xpu(xetla_weight, weight_shape, qtype):
from ipex_llm.transformers.low_bit_linear import get_block_size
- Q4_0 = get_block_size("sym_int4")
+ if qtype == ggml_tensor_qtype["sym_int4"]:
+ Q4_0 = get_block_size("sym_int4")
+ n, k = weight_shape
+ weight_size = n*k//2
+ zeros_size = n*k//Q4_0//2
+ scales_size = n*k//Q4_0 * 2
+ xetla_weight_only = xetla_weight[:weight_size]
+ scales_start = weight_size + zeros_size
+ xetla_scales = xetla_weight[scales_start:scales_start+scales_size]
- n, k = weight_shape
- ggml_weight_only = ggml_weight[:n*k//2]
- ggml_scales = ggml_weight[n*k//2:]
+ qweight = xetla_weight_only.clone()
+ scales = xetla_scales.view(torch.float16).clone()
- qweight = ggml_weight_only.clone()
- scales = ggml_scales.view(torch.float16).clone()
+ qweight_0 = qweight & 0x0F
+ qweight_1 = qweight >> 4
+ qweight_0 = qweight_0.reshape(-1, 8, n)
+ qweight_1 = qweight_1.reshape(-1, 8, n)
+ qweight = torch.cat([qweight_0, qweight_1], dim=1)
- qweight_0 = qweight & 0x0F
- qweight_1 = qweight >> 4
+ qweight = qweight.reshape(k, n).transpose(0, 1).contiguous().reshape(n, k//Q4_0,
+ 2, Q4_0//2)
+ qweight = qweight.bitwise_left_shift(
+ torch.tensor([0, 4], dtype=torch.uint8,
+ device=xetla_weight_only.device).reshape(1, 1, 2, 1))
- qweight_0 = qweight_0.reshape(n, -1, Q4_0//2)
- qweight_1 = qweight_1.reshape(n, -1, Q4_0//2)
- qweight = torch.cat([qweight_0, qweight_1], dim=-1)
- qweight = qweight.reshape(n, k//16, 2, 8)
- qweight = qweight.bitwise_left_shift(
- torch.tensor([0, 4], dtype=torch.uint8, device=ggml_weight.device).reshape(1, 1, 2, 1))
+ qweight = torch.bitwise_or(qweight[:, :, 0, :], qweight[:, :, 1, :])
+ qweight = qweight.reshape(n, k//2)
- qweight = torch.bitwise_or(qweight[:, :, 0, :], qweight[:, :, 1, :])
- qweight = qweight.reshape(n, k//2)
- qweight = qweight.transpose(0, 1).contiguous()
+ scales = scales.reshape(k//Q4_0, n).transpose(0, 1).contiguous()
- scales = scales.reshape(n, k//Q4_0).transpose(0, 1).contiguous()
-
- # 119 is the value of 0x77
- zeros = torch.ones([k//Q4_0, n//2], dtype=torch.uint8, device=ggml_weight.device) * (119)
-
- qweight_bytes = qweight.view(torch.uint8).view(-1)
- scales_bytes = scales.view(torch.uint8).view(-1)
- zeros_bytes = zeros.view(torch.uint8).view(-1)
-
- weight = torch.concat([qweight_bytes, zeros_bytes, scales_bytes], dim=0)
+ qweight_bytes = qweight.view(torch.uint8).view(-1)
+ scales_bytes = scales.view(torch.uint8).view(-1)
+ weight = torch.concat([qweight_bytes, scales_bytes], dim=0)
+ elif qtype == ggml_tensor_qtype["fp8_e5m2"]:
+ Q8_0 = get_block_size("fp8_e5m2")
+ n, k = weight_shape
+ qweight = xetla_weight[:n*k].transpose(0, 1).contiguous()
+ scales = torch.ones([n*k//Q8_0], dtype=torch.float, device=xetla_weight.device)
+ qweight_bytes = qweight.view(torch.uint8).view(-1)
+ scales_bytes = scales.view(torch.uint8).view(-1)
+ weight = torch.concat([qweight_bytes, scales_bytes], dim=0)
+ else:
+ invalidInputError(False, f"Unsupported qtype {qtype}")
return weight
@@ -373,7 +429,7 @@ class FP4Params(torch.nn.Parameter):
reduce(mul, self._shape, 1),
self.qtype)
if self.enable_xetla:
- self.data = q4_0_xpu_transpose(self.data, self._shape)
+ self.data = ggml_xpu_to_ipex_llm_xetla(self.data, self._shape, self.qtype)
new_param = FP4Params(super().to(device=device,
dtype=dtype,
non_blocking=non_blocking),
@@ -397,9 +453,12 @@ class FP4Params(torch.nn.Parameter):
qtype=self.qtype,
enable_xetla=self.enable_xetla)
if self.enable_xetla:
- invalidInputError(False,
- "xetla is not supported on CPUs but got enable_xetla=True")
- new_param.data = ggml_q_format_convet_xpu2cpu(new_param.data,
+ ggml_xpu = ipex_llm_xetla_to_ggml_xpu(new_param.data,
+ new_param._shape,
+ new_param.qtype)
+ else:
+ ggml_xpu = new_param.data
+ new_param.data = ggml_q_format_convet_xpu2cpu(ggml_xpu,
reduce(mul, new_param._shape, 1),
new_param.qtype)
return new_param
@@ -610,7 +669,7 @@ class LowBitLinear(nn.Linear):
input_seq_size)
elif self.enable_xetla:
x_2d = x_2d.half()
- result = linear_q4_0.mm_int4(x_2d, self.weight.data)
+ result = linear_q4_0.mm_xetla(x_2d, self.weight.data, self.qtype)
else:
# inference path
# current workaround to reduce first token latency of fp32 input
diff --git a/python/llm/src/ipex_llm/transformers/model.py b/python/llm/src/ipex_llm/transformers/model.py
index be3f13a5..44b2e0ad 100644
--- a/python/llm/src/ipex_llm/transformers/model.py
+++ b/python/llm/src/ipex_llm/transformers/model.py
@@ -295,6 +295,15 @@ class _BaseAutoModelClass:
)
else:
kwargs["torch_dtype"] = torch.float16
+ elif load_in_low_bit == "bf16":
+ if torch_dtype is not None and torch_dtype != torch.bfloat16:
+ invalidInputError(
+ False,
+ f"Please use torch_dtype=torch.bfloat16"
+ f" when setting load_in_low_bit='bf16'."
+ )
+ else:
+ kwargs["torch_dtype"] = torch.bfloat16
else:
kwargs["torch_dtype"] = torch_dtype or "auto"
# Avoid tensor parallel F.Linear Operations
diff --git a/python/llm/src/ipex_llm/transformers/models/aquila.py b/python/llm/src/ipex_llm/transformers/models/aquila.py
index 1b1d252a..02054dcc 100644
--- a/python/llm/src/ipex_llm/transformers/models/aquila.py
+++ b/python/llm/src/ipex_llm/transformers/models/aquila.py
@@ -48,7 +48,9 @@ from ipex_llm.transformers.models.utils import apply_rotary_pos_emb
from ipex_llm.transformers.models.utils import apply_rotary_pos_emb_no_cache_xpu
from ipex_llm.utils.common import log4Error
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def aquila_attention_forward(
diff --git a/python/llm/src/ipex_llm/transformers/models/baichuan.py b/python/llm/src/ipex_llm/transformers/models/baichuan.py
index 0c9e8216..0fef9131 100644
--- a/python/llm/src/ipex_llm/transformers/models/baichuan.py
+++ b/python/llm/src/ipex_llm/transformers/models/baichuan.py
@@ -35,7 +35,9 @@ from ipex_llm.transformers.models.utils import init_fp8_kv_cache, append_fp8_kv_
from ipex_llm.transformers.models.utils import rotate_half, apply_rotary_pos_emb
from ipex_llm.transformers.models.utils import apply_rotary_pos_emb_no_cache_xpu
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def baichuan_attention_forward_7b(
diff --git a/python/llm/src/ipex_llm/transformers/models/baichuan2.py b/python/llm/src/ipex_llm/transformers/models/baichuan2.py
index 38a47592..309972d2 100644
--- a/python/llm/src/ipex_llm/transformers/models/baichuan2.py
+++ b/python/llm/src/ipex_llm/transformers/models/baichuan2.py
@@ -44,8 +44,9 @@ except ImportError:
"accelerate training use the following command to install Xformers\npip install xformers."
)
+import os
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def baichuan_13b_rms_norm_forward(self, hidden_states):
diff --git a/python/llm/src/ipex_llm/transformers/models/bloom.py b/python/llm/src/ipex_llm/transformers/models/bloom.py
index 46489e8b..5c2e658a 100644
--- a/python/llm/src/ipex_llm/transformers/models/bloom.py
+++ b/python/llm/src/ipex_llm/transformers/models/bloom.py
@@ -40,8 +40,9 @@ from torch.nn import functional as F
from ipex_llm.transformers.models.utils import use_fused_layer_norm
from ipex_llm.transformers.models.utils import init_kv_cache, extend_kv_cache, append_kv_cache
+import os
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def dropout_add(x: torch.Tensor, residual: torch.Tensor, prob: float, training: bool):
diff --git a/python/llm/src/ipex_llm/transformers/models/chatglm.py b/python/llm/src/ipex_llm/transformers/models/chatglm.py
index ac9a98a1..0cd1cc94 100644
--- a/python/llm/src/ipex_llm/transformers/models/chatglm.py
+++ b/python/llm/src/ipex_llm/transformers/models/chatglm.py
@@ -38,7 +38,9 @@ def apply_rotary_pos_emb_index(q, k, cos, sin, position_id):
q, k = (q * cos) + (rotate_half(q) * sin), (k * cos) + (rotate_half(k) * sin)
return q, k
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
KV_CACHE_ALLOC_MIN_LENGTH = 512
diff --git a/python/llm/src/ipex_llm/transformers/models/chatglm2.py b/python/llm/src/ipex_llm/transformers/models/chatglm2.py
index 3d69cd18..9812926f 100644
--- a/python/llm/src/ipex_llm/transformers/models/chatglm2.py
+++ b/python/llm/src/ipex_llm/transformers/models/chatglm2.py
@@ -28,7 +28,9 @@ from ipex_llm.transformers.models.utils import init_fp8_kv_cache, append_fp8_kv_
from ipex_llm.transformers.models.utils import use_esimd_sdp
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
KV_CACHE_ALLOC_MIN_LENGTH = 512
@@ -250,10 +252,31 @@ def chatglm2_quantized_attention_forward_8eb45c(
else:
key, value = key_layer, value_layer
- if attention_mask is None:
- context_layer = F.scaled_dot_product_attention(query_layer, key, value, is_causal=True)
+ # split tensor for memory block limitation
+ # support fp16 and set input length threshold at 5000 for now
+ if query_layer.dtype == torch.float16 and query_layer.shape[2] >= 5000:
+ # split second dim to block size = 8
+ block_size = 8
+ query_split = torch.split(query_layer, block_size, dim=1)
+ key_split = torch.split(key, block_size, dim=1)
+ value_split = torch.split(value, block_size, dim=1)
+ context_layer = torch.empty(batch_size, n_head,
+ seq_len, head_dim).to(query_layer.device)
+ idx = 0
+ for q, k, v in zip(query_split, key_split, value_split):
+ if attention_mask is None:
+ result = F.scaled_dot_product_attention(q, k, v, is_causal=True)
+ else:
+ result = F.scaled_dot_product_attention(q, k, v, attention_mask)
+ context_layer[:, idx:idx+q.shape[1], :, :] = result
+ idx = idx + q.shape[1]
else:
- context_layer = F.scaled_dot_product_attention(query_layer, key, value, attention_mask)
+ if attention_mask is None:
+ context_layer = F.scaled_dot_product_attention(query_layer, key,
+ value, is_causal=True)
+ else:
+ context_layer = F.scaled_dot_product_attention(query_layer, key,
+ value, attention_mask)
context_layer = context_layer.to(query_layer.dtype)
if use_cache:
@@ -515,15 +538,19 @@ def core_attn_forward_8eb45c(query_layer, key_layer, value_layer, attention_mask
# split tensor for memory block limitation
# support fp16 and set input length threshold at 5000 for now
if query_layer.dtype == torch.float16 and L >= 5000:
- # split first dim 32 -> 8
- query_sp = torch.split(query_layer.to(key_layer.dtype), 8, dim=1)
- key_sp = torch.split(key_layer, 8, dim=1)
- value_sp = torch.split(value_layer, 8, dim=1)
- results = []
- for q, k, v in zip(query_sp, key_sp, value_sp):
+ # split second dim to block size = 8
+ block_size = 8
+ query_split = torch.split(query_layer.to(key_layer.dtype), block_size, dim=1)
+ key_split = torch.split(key_layer, block_size, dim=1)
+ value_split = torch.split(value_layer, block_size, dim=1)
+ batch_size, n_head, seq_len, head_dim = query_layer.shape
+ context_layer = torch.empty(batch_size, n_head, seq_len,
+ head_dim).to(query_layer.device).to(key_layer.dtype)
+ idx = 0
+ for q, k, v in zip(query_split, key_split, value_split):
result = F.scaled_dot_product_attention(q, k, v, is_causal=True).to(k.dtype)
- results.append(result)
- context_layer = torch.cat(results, dim=1)
+ context_layer[:, idx:idx+q.shape[1], :, :] = result
+ idx = idx + q.shape[1]
else:
context_layer = F.scaled_dot_product_attention(query_layer.to(key_layer.dtype),
key_layer,
diff --git a/python/llm/src/ipex_llm/transformers/models/chatglm2_32k.py b/python/llm/src/ipex_llm/transformers/models/chatglm2_32k.py
index 94856152..38357e44 100644
--- a/python/llm/src/ipex_llm/transformers/models/chatglm2_32k.py
+++ b/python/llm/src/ipex_llm/transformers/models/chatglm2_32k.py
@@ -23,7 +23,9 @@ import torch.nn.functional as F
from ipex_llm.transformers.models.utils import init_kv_cache, extend_kv_cache, append_kv_cache
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
KV_CACHE_ALLOC_MIN_LENGTH = 512
diff --git a/python/llm/src/ipex_llm/transformers/models/decilm.py b/python/llm/src/ipex_llm/transformers/models/decilm.py
index 67bc5e49..771cf8b9 100644
--- a/python/llm/src/ipex_llm/transformers/models/decilm.py
+++ b/python/llm/src/ipex_llm/transformers/models/decilm.py
@@ -41,7 +41,9 @@ from ipex_llm.transformers.models.utils import apply_rotary_pos_emb_no_cache_xpu
from ipex_llm.transformers.models.llama import should_use_fuse_rope, repeat_kv
from ipex_llm.utils.common import invalidInputError
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def decilm_attention_forward_4_35_2(
diff --git a/python/llm/src/ipex_llm/transformers/models/falcon.py b/python/llm/src/ipex_llm/transformers/models/falcon.py
index 4932aeab..14d08d09 100644
--- a/python/llm/src/ipex_llm/transformers/models/falcon.py
+++ b/python/llm/src/ipex_llm/transformers/models/falcon.py
@@ -41,8 +41,9 @@ from ipex_llm.utils.common import invalidInputError
from ipex_llm.transformers.models.utils import init_kv_cache, extend_kv_cache, append_kv_cache
import warnings
+import os
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
# Copied from transformers.models.llama.modeling_llama.rotate_half
diff --git a/python/llm/src/ipex_llm/transformers/models/gemma.py b/python/llm/src/ipex_llm/transformers/models/gemma.py
index f6bf2db5..4eb6f5fe 100644
--- a/python/llm/src/ipex_llm/transformers/models/gemma.py
+++ b/python/llm/src/ipex_llm/transformers/models/gemma.py
@@ -43,7 +43,9 @@ from ipex_llm.transformers.models.utils import is_enough_kv_cache_room_4_36, rot
from ipex_llm.transformers.low_bit_linear import SYM_INT4, FP8E5
from ipex_llm.transformers.models.utils import decoding_fast_path_qtype_check
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
diff --git a/python/llm/src/ipex_llm/transformers/models/gptj.py b/python/llm/src/ipex_llm/transformers/models/gptj.py
index 38df3cb1..71bd4f7d 100644
--- a/python/llm/src/ipex_llm/transformers/models/gptj.py
+++ b/python/llm/src/ipex_llm/transformers/models/gptj.py
@@ -26,8 +26,9 @@ from transformers.modeling_outputs import BaseModelOutputWithPast
from transformers.models.gptj.modeling_gptj import GPTJModel
from ipex_llm.utils.common import invalidInputError
+import os
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def _get_embed_positions(self, position_ids):
diff --git a/python/llm/src/ipex_llm/transformers/models/gptneox.py b/python/llm/src/ipex_llm/transformers/models/gptneox.py
index 52466042..4e0129c9 100644
--- a/python/llm/src/ipex_llm/transformers/models/gptneox.py
+++ b/python/llm/src/ipex_llm/transformers/models/gptneox.py
@@ -38,8 +38,9 @@ from ipex_llm.transformers.models.utils import init_kv_cache, extend_kv_cache, \
append_kv_cache, is_enough_kv_cache_room_4_31
from ipex_llm.transformers.models.utils import apply_rotary_pos_emb_no_cache_xpu
+import os
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def gptneox_attention_forward(
diff --git a/python/llm/src/ipex_llm/transformers/models/internlm.py b/python/llm/src/ipex_llm/transformers/models/internlm.py
index 038a63d8..fe9f708c 100644
--- a/python/llm/src/ipex_llm/transformers/models/internlm.py
+++ b/python/llm/src/ipex_llm/transformers/models/internlm.py
@@ -48,8 +48,9 @@ from ipex_llm.transformers.models.utils import init_kv_cache, extend_kv_cache, \
from ipex_llm.transformers.models.utils import apply_rotary_pos_emb
from ipex_llm.transformers.models.utils import apply_rotary_pos_emb_no_cache_xpu
+import os
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def internlm_attention_forward(
diff --git a/python/llm/src/ipex_llm/transformers/models/llama.py b/python/llm/src/ipex_llm/transformers/models/llama.py
index ee367131..47f5aec7 100644
--- a/python/llm/src/ipex_llm/transformers/models/llama.py
+++ b/python/llm/src/ipex_llm/transformers/models/llama.py
@@ -114,7 +114,8 @@ def llama_model_forward_4_36(
) -> Union[Tuple, BaseModelOutputWithPast]:
from ipex_llm.transformers.kv import DynamicFp8Cache
use_cache = use_cache if use_cache is not None else self.config.use_cache
- if use_cache and use_quantize_kv_cache(self.layers[0].mlp.up_proj, input_ids):
+ input = input_ids if input_ids is not None else inputs_embeds
+ if use_cache and use_quantize_kv_cache(self.layers[0].mlp.up_proj, input):
if not isinstance(past_key_values, DynamicFp8Cache):
past_key_values = DynamicFp8Cache.from_legacy_cache(past_key_values)
return llama_model_forward_4_36_internal(
@@ -273,33 +274,46 @@ def llama_decoder_forward(
return outputs
-def fuse_qkv_weight(q_proj, k_proj, v_proj):
- weight_size = q_proj.out_len * q_proj.in_len // 2
- zeros_size = q_proj.in_len * q_proj.out_len // 2 // 64
- zeros_end = weight_size + zeros_size
- weight_byte_shape = (q_proj.in_len//2, q_proj.out_len)
- zeros_byte_shape = (q_proj.in_len//64, q_proj.out_len//2)
- scales_byte_shape = (q_proj.in_len//64, q_proj.out_len*2)
- qweight = torch.concat([q_proj.weight.data[:weight_size].reshape(weight_byte_shape),
- k_proj.weight.data[:weight_size].reshape(weight_byte_shape),
- v_proj.weight.data[:weight_size].reshape(weight_byte_shape),
- ], dim=-1).reshape(-1)
- qzeros = torch.concat([q_proj.weight.data[weight_size:zeros_end].reshape(zeros_byte_shape),
- k_proj.weight.data[weight_size:zeros_end].reshape(zeros_byte_shape),
- v_proj.weight.data[weight_size:zeros_end].reshape(zeros_byte_shape),
- ], dim=-1).reshape(-1)
- qscales = torch.concat([q_proj.weight.data[zeros_end:].reshape(scales_byte_shape),
- k_proj.weight.data[zeros_end:].reshape(scales_byte_shape),
- v_proj.weight.data[zeros_end:].reshape(scales_byte_shape),
- ], dim=-1).reshape(-1)
- q_proj.weight.data = torch.empty(0)
- k_proj.weight.data = torch.empty(0)
- v_proj.weight.data = torch.empty(0)
- return torch.cat([qweight, qzeros, qscales], dim=0)
+def fuse_qkv_weight_xetla(q_proj, k_proj, v_proj, qtype):
+ if qtype == SYM_INT4:
+ weight_size = q_proj.out_len * q_proj.in_len // 2
+ zeros_size = q_proj.in_len * q_proj.out_len // 2 // 64
+ zeros_end = weight_size + zeros_size
+ weight_byte_shape = (q_proj.in_len//2, q_proj.out_len)
+ zeros_byte_shape = (q_proj.in_len//64, q_proj.out_len//2)
+ scales_byte_shape = (q_proj.in_len//64, q_proj.out_len*2)
+ qweight = torch.concat([q_proj.weight.data[:weight_size].reshape(weight_byte_shape),
+ k_proj.weight.data[:weight_size].reshape(weight_byte_shape),
+ v_proj.weight.data[:weight_size].reshape(weight_byte_shape),
+ ], dim=-1).reshape(-1)
+ qzeros = torch.concat([q_proj.weight.data[weight_size:zeros_end].reshape(zeros_byte_shape),
+ k_proj.weight.data[weight_size:zeros_end].reshape(zeros_byte_shape),
+ v_proj.weight.data[weight_size:zeros_end].reshape(zeros_byte_shape),
+ ], dim=-1).reshape(-1)
+ qscales = torch.concat([q_proj.weight.data[zeros_end:].reshape(scales_byte_shape),
+ k_proj.weight.data[zeros_end:].reshape(scales_byte_shape),
+ v_proj.weight.data[zeros_end:].reshape(scales_byte_shape),
+ ], dim=-1).reshape(-1)
+ q_proj.weight.data = torch.empty(0)
+ k_proj.weight.data = torch.empty(0)
+ v_proj.weight.data = torch.empty(0)
+ return torch.cat([qweight, qzeros, qscales], dim=0)
+ elif qtype == FP8E5:
+ result = torch.cat([q_proj.weight, k_proj.weight, v_proj.weight], dim=1).contiguous()
+ q_proj.weight.data = torch.empty(0)
+ k_proj.weight.data = torch.empty(0)
+ v_proj.weight.data = torch.empty(0)
+ return result
+ else:
+ invalidInputError(False, f"Unsupported qtype {qtype}")
-def should_use_mm_int4_qkv(self, device):
- return device.type == "xpu" and self.q_proj.qtype == SYM_INT4 and self.q_proj.enable_xetla
+def should_use_xetla_mm_qkv(self, device):
+ full_attn = self.q_proj.out_len == self.k_proj.out_len == self.v_proj.out_len
+ supported_qtype = self.q_proj.qtype == SYM_INT4 and full_attn
+ supported_qtype = supported_qtype or self.q_proj.qtype == FP8E5
+ enable_xetla = self.q_proj.enable_xetla
+ return device.type == "xpu" and enable_xetla and supported_qtype
def llama_attention_forward_4_31(
@@ -352,6 +366,7 @@ def llama_attention_forward_4_31_quantized(
no_tp = not self.config.pretraining_tp > 1
decoding_fast_path = (no_tp and qtype_check and use_fuse_rope
and enough_kv_room and bsz * q_len == 1)
+ decoding_fast_path = decoding_fast_path and not self.q_proj.enable_xetla
# single batch decoding fast path
# forward_qkv takes will perform QKV projection, rotary position embedding
@@ -553,16 +568,21 @@ def llama_attention_forward_4_31_original(
query_states, key_states, value_states
)
else:
- if should_use_mm_int4_qkv(self, device):
+ if should_use_xetla_mm_qkv(self, device):
if not hasattr(self, "qkv_proj_qweight"):
- self.qkv_proj_qweight = fuse_qkv_weight(self.q_proj,
- self.k_proj,
- self.v_proj)
+ self.qkv_proj_qweight = fuse_qkv_weight_xetla(self.q_proj,
+ self.k_proj,
+ self.v_proj,
+ self.q_proj.weight.qtype,)
import linear_q4_0
- qkv_states = linear_q4_0.mm_int4(hidden_states, self.qkv_proj_qweight)
- query_states = qkv_states[:, :, :hidden_size]
- key_states = qkv_states[:, :, hidden_size:2*hidden_size]
- value_states = qkv_states[:, :, 2*hidden_size:]
+ q_out_len = self.q_proj.out_len
+ k_out_len = self.k_proj.out_len
+ v_out_len = self.v_proj.out_len
+ qkv_states = linear_q4_0.mm_xetla(hidden_states, self.qkv_proj_qweight,
+ self.q_proj.weight.qtype)
+ query_states = qkv_states[:, :, :q_out_len]
+ key_states = qkv_states[:, :, q_out_len:q_out_len + k_out_len]
+ value_states = qkv_states[:, :, q_out_len + k_out_len:]
else:
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
@@ -932,6 +952,7 @@ def llama_attention_forward_4_36_quantized(
no_tp = not self.config.pretraining_tp > 1
decoding_fast_path = (no_tp and qtype_check and use_fuse_rope
and enough_kv_room and bsz * q_len == 1)
+ decoding_fast_path = decoding_fast_path and not self.q_proj.enable_xetla
if decoding_fast_path:
hidden_states = hidden_states.view(1, -1)
tmp_cache_k, tmp_cache_v = init_kv_cache(
@@ -991,8 +1012,10 @@ def llama_attention_forward_4_36_quantized(
kv_seq_len = key_states.shape[-2]
if len(past_key_value.key_cache) <= self.layer_idx:
+ repeated_key_states = repeat_kv(key_states, self.num_key_value_groups)
+ repeated_value_states = repeat_kv(value_states, self.num_key_value_groups)
attn_weights = torch.matmul(query_states,
- key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
+ repeated_key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
invalidInputError(
@@ -1018,7 +1041,7 @@ def llama_attention_forward_4_36_quantized(
# upcast attention to fp32
attn_weights = nn.functional.softmax(attn_weights, dim=-1,
dtype=torch.float32).to(query_states.dtype)
- attn_output = torch.matmul(attn_weights, value_states)
+ attn_output = torch.matmul(attn_weights, repeated_value_states)
if use_cache:
cache_kwargs = None
key_states, value_states = past_key_value.update(key_states, value_states,
@@ -1196,16 +1219,22 @@ def llama_attention_forward_4_36_original(
query_states, key_states, value_states
)
else:
- if should_use_mm_int4_qkv(self, device):
+ if should_use_xetla_mm_qkv(self, device):
if not hasattr(self, "qkv_proj_qweight"):
- self.qkv_proj_qweight = fuse_qkv_weight(self.q_proj,
- self.k_proj,
- self.v_proj)
+ self.qkv_proj_qweight = fuse_qkv_weight_xetla(self.q_proj,
+ self.k_proj,
+ self.v_proj,
+ self.q_proj.weight.qtype,)
import linear_q4_0
- qkv_states = linear_q4_0.mm_int4(hidden_states, self.qkv_proj_qweight)
- query_states = qkv_states[:, :, :hidden_size]
- key_states = qkv_states[:, :, hidden_size:2*hidden_size]
- value_states = qkv_states[:, :, 2*hidden_size:]
+ q_out_len = self.q_proj.out_len
+ k_out_len = self.k_proj.out_len
+ v_out_len = self.v_proj.out_len
+ qkv_states = linear_q4_0.mm_xetla(hidden_states,
+ self.qkv_proj_qweight,
+ self.q_proj.weight.qtype)
+ query_states = qkv_states[:, :, :q_out_len]
+ key_states = qkv_states[:, :, q_out_len:q_out_len + k_out_len]
+ value_states = qkv_states[:, :, q_out_len + k_out_len:]
else:
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
diff --git a/python/llm/src/ipex_llm/transformers/models/mistral.py b/python/llm/src/ipex_llm/transformers/models/mistral.py
index 818b98f3..c81cafff 100644
--- a/python/llm/src/ipex_llm/transformers/models/mistral.py
+++ b/python/llm/src/ipex_llm/transformers/models/mistral.py
@@ -54,11 +54,16 @@ from ipex_llm.transformers.models.utils import is_enough_kv_cache_room_4_31, \
from ipex_llm.transformers.low_bit_linear import SYM_INT4, FP8E5, IQ2_XXS
from ipex_llm.transformers.models.utils import use_flash_attention, use_esimd_sdp
from ipex_llm.transformers.models.llama import llama_decoding_fast_path_qtype_check
+from ipex_llm.transformers.models.llama import should_use_xetla_mm_qkv
+from ipex_llm.transformers.models.llama import fuse_qkv_weight_xetla
try:
from transformers.cache_utils import Cache
except ImportError:
Cache = Tuple[torch.Tensor]
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
@@ -84,7 +89,8 @@ def should_use_fuse_rope(self, hidden_states, position_ids):
def use_decoding_fast_path(proj, use_fuse_rope, enough_kv_room, bs):
return llama_decoding_fast_path_qtype_check(proj) and \
- use_fuse_rope and enough_kv_room and bs == 1
+ use_fuse_rope and enough_kv_room and bs == 1 and \
+ not proj.enable_xetla
def compute_attn_outputs_weights(query_states, key_states, value_states, bsz, q_len, kv_seq_len,
@@ -382,7 +388,6 @@ def mistral_attention_forward_original(
use_fuse_rope,
enough_kv_room,
bsz * q_len)
- decoding_fast_path = decoding_fast_path and not self.q_proj.enable_xetla
if decoding_fast_path:
hidden_states = hidden_states.view(1, -1)
@@ -402,9 +407,27 @@ def mistral_attention_forward_original(
self.head_dim)
kv_seq_len += 1
else:
- query_states = self.q_proj(hidden_states)
- key_states = self.k_proj(hidden_states)
- value_states = self.v_proj(hidden_states)
+
+ if should_use_xetla_mm_qkv(self, device):
+ if not hasattr(self, "qkv_proj_qweight"):
+ self.qkv_proj_qweight = fuse_qkv_weight_xetla(self.q_proj,
+ self.k_proj,
+ self.v_proj,
+ self.q_proj.qtype)
+ import linear_q4_0
+ q_out_len = self.q_proj.out_len
+ k_out_len = self.k_proj.out_len
+ v_out_len = self.v_proj.out_len
+ qkv_states = linear_q4_0.mm_xetla(hidden_states,
+ self.qkv_proj_qweight,
+ self.q_proj.qtype)
+ query_states = qkv_states[:, :, :q_out_len]
+ key_states = qkv_states[:, :, q_out_len:q_out_len + k_out_len]
+ value_states = qkv_states[:, :, q_out_len + k_out_len:]
+ else:
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len,
@@ -769,9 +792,26 @@ def mistral_attention_forward_4_36_original(
past_key_value.value_cache[self.layer_idx] = value_states
else:
- query_states = self.q_proj(hidden_states)
- key_states = self.k_proj(hidden_states)
- value_states = self.v_proj(hidden_states)
+ if should_use_xetla_mm_qkv(self, device):
+ if not hasattr(self, "qkv_proj_qweight"):
+ self.qkv_proj_qweight = fuse_qkv_weight_xetla(self.q_proj,
+ self.k_proj,
+ self.v_proj,
+ self.q_proj.qtype)
+ import linear_q4_0
+ q_out_len = self.q_proj.out_len
+ k_out_len = self.k_proj.out_len
+ v_out_len = self.v_proj.out_len
+ qkv_states = linear_q4_0.mm_xetla(hidden_states,
+ self.qkv_proj_qweight,
+ self.q_proj.qtype)
+ query_states = qkv_states[:, :, :q_out_len]
+ key_states = qkv_states[:, :, q_out_len:q_out_len + k_out_len]
+ value_states = qkv_states[:, :, q_out_len + k_out_len:]
+ else:
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len,
@@ -859,6 +899,15 @@ def mistral_attention_forward_4_36_original(
attn_weights = None
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+ elif use_esimd_sdp(q_len, key_states.shape[2], self.head_dim, query_states):
+ import linear_fp16_esimd
+ attn_output = linear_fp16_esimd.sdp_forward(query_states,
+ key_states,
+ value_states)
+ attn_output = attn_output.view(query_states.shape)
+ attn_weights = None
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
else:
attn_output, attn_weights = compute_attn_outputs_weights(query_states,
key_states,
diff --git a/python/llm/src/ipex_llm/transformers/models/mixtral.py b/python/llm/src/ipex_llm/transformers/models/mixtral.py
index c25e1425..9bf3af14 100644
--- a/python/llm/src/ipex_llm/transformers/models/mixtral.py
+++ b/python/llm/src/ipex_llm/transformers/models/mixtral.py
@@ -58,8 +58,9 @@ from ipex_llm.transformers.models.utils import use_flash_attention, use_esimd_sd
from ipex_llm.transformers.models.utils import mlp_fusion_check, SILU
from ipex_llm.transformers.low_bit_linear import IQ2_XXS
+import os
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
diff --git a/python/llm/src/ipex_llm/transformers/models/mpt.py b/python/llm/src/ipex_llm/transformers/models/mpt.py
index 4d4a191a..f6603d73 100644
--- a/python/llm/src/ipex_llm/transformers/models/mpt.py
+++ b/python/llm/src/ipex_llm/transformers/models/mpt.py
@@ -25,8 +25,9 @@ import torch.nn.functional as F
from ipex_llm.utils.common import invalidInputError
from ipex_llm.transformers.models.utils import extend_kv_cache, init_kv_cache, append_kv_cache
+import os
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def mpt_multihead_attention_forward(self, x, past_key_value=None, attn_bias=None,
diff --git a/python/llm/src/ipex_llm/transformers/models/phixtral.py b/python/llm/src/ipex_llm/transformers/models/phixtral.py
index 66595d5c..8feaabe8 100644
--- a/python/llm/src/ipex_llm/transformers/models/phixtral.py
+++ b/python/llm/src/ipex_llm/transformers/models/phixtral.py
@@ -52,8 +52,9 @@ from ipex_llm.transformers.models.mistral import should_use_fuse_rope, use_decod
from ipex_llm.transformers.models.utils import use_flash_attention
from ipex_llm.transformers.models.utils import mlp_fusion_check
+import os
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
diff --git a/python/llm/src/ipex_llm/transformers/models/qwen.py b/python/llm/src/ipex_llm/transformers/models/qwen.py
index 09709136..271607ef 100644
--- a/python/llm/src/ipex_llm/transformers/models/qwen.py
+++ b/python/llm/src/ipex_llm/transformers/models/qwen.py
@@ -54,7 +54,9 @@ flash_attn_unpadded_func = None
logger = logging.get_logger(__name__)
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
SUPPORT_TORCH2 = hasattr(torch, '__version__') and int(torch.__version__.split(".")[0]) >= 2
@@ -142,6 +144,7 @@ def qwen_attention_forward_original(
use_fuse_rope = should_use_fuse_rope(self, hidden_states)
qtype_check = decoding_fast_path_qtype_check(self.q_proj)
decoding_fast_path = (qtype_check and use_fuse_rope and bsz * q_len == 1)
+ decoding_fast_path = decoding_fast_path and not self.q_proj.enable_xetla
if decoding_fast_path:
hidden_states = hidden_states.view(1, -1)
cache_k, cache_v = layer_past[0], layer_past[1]
diff --git a/python/llm/src/ipex_llm/transformers/models/qwen2.py b/python/llm/src/ipex_llm/transformers/models/qwen2.py
index 66f86692..2369c5a7 100644
--- a/python/llm/src/ipex_llm/transformers/models/qwen2.py
+++ b/python/llm/src/ipex_llm/transformers/models/qwen2.py
@@ -69,7 +69,9 @@ from transformers import logging
logger = logging.get_logger(__name__)
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def should_use_fuse_rope(self, query_states, position_ids):
diff --git a/python/llm/src/ipex_llm/transformers/models/qwen_vl.py b/python/llm/src/ipex_llm/transformers/models/qwen_vl.py
index 34f79052..cfc390b7 100644
--- a/python/llm/src/ipex_llm/transformers/models/qwen_vl.py
+++ b/python/llm/src/ipex_llm/transformers/models/qwen_vl.py
@@ -35,7 +35,9 @@ from ipex_llm.transformers.models.utils import rotate_half
from ipex_llm.transformers.models.utils import use_esimd_sdp
from ipex_llm.transformers.models.utils import decoding_fast_path_qtype_check
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def apply_rotary_pos_emb(t, freqs):
@@ -91,6 +93,7 @@ def qwen_attention_forward_vl(
use_fuse_rope = should_use_fuse_rope(self, hidden_states)
qtype_check = decoding_fast_path_qtype_check(self.q_proj)
decoding_fast_path = (qtype_check and use_fuse_rope and bsz * q_len == 1)
+ decoding_fast_path = decoding_fast_path and not self.q_proj.enable_xetla
if decoding_fast_path:
hidden_states = hidden_states.view(1, -1)
cache_k, cache_v = layer_past[0], layer_past[1]
diff --git a/python/llm/src/ipex_llm/transformers/models/rwkv5.py b/python/llm/src/ipex_llm/transformers/models/rwkv5.py
index 358c5a79..5619c16f 100644
--- a/python/llm/src/ipex_llm/transformers/models/rwkv5.py
+++ b/python/llm/src/ipex_llm/transformers/models/rwkv5.py
@@ -36,6 +36,7 @@ import torch
import torch.nn.functional as F
from typing import List, Optional
+from ipex_llm.utils.common.log4Error import invalidInputError
def extract_key_value(self, hidden, state=None):
@@ -265,6 +266,8 @@ def rwkv_model_forward_wrapper(origin_rwkv_model_forward):
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
+ invalidInputError(self.embeddings.weight.dtype == torch.float,
+ "Only fp32 is supported for now, fp16 and bf16 are not supported")
use_cache = use_cache if use_cache is not None else self.config.use_cache
# change `state` layout and put `num_hidden_layers` to the highest dim
if input_ids.device.type == "xpu" and use_cache and state is None:
diff --git a/python/llm/src/ipex_llm/transformers/models/stablelm.py b/python/llm/src/ipex_llm/transformers/models/stablelm.py
index 53372e81..a6cd1bfb 100644
--- a/python/llm/src/ipex_llm/transformers/models/stablelm.py
+++ b/python/llm/src/ipex_llm/transformers/models/stablelm.py
@@ -60,8 +60,9 @@ try:
except ImportError:
Cache = Tuple[torch.Tensor]
+import os
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def merge_qkv(module: torch.nn.Module):
diff --git a/python/llm/src/ipex_llm/transformers/models/utils.py b/python/llm/src/ipex_llm/transformers/models/utils.py
index 24168693..8f3b98a8 100644
--- a/python/llm/src/ipex_llm/transformers/models/utils.py
+++ b/python/llm/src/ipex_llm/transformers/models/utils.py
@@ -395,6 +395,8 @@ def use_fused_layer_norm(x: torch.Tensor, training: bool):
def fp16_fusion_check(proj, x, training):
# only use fp16 fusion on PVC inference
+ if not hasattr(proj, "qtype"):
+ return False
if proj.qtype != ggml_tensor_qtype["fp16"]:
return False
if proj.weight_type != 2:
diff --git a/python/llm/src/ipex_llm/transformers/models/yuan.py b/python/llm/src/ipex_llm/transformers/models/yuan.py
index 71f4d817..43f86732 100644
--- a/python/llm/src/ipex_llm/transformers/models/yuan.py
+++ b/python/llm/src/ipex_llm/transformers/models/yuan.py
@@ -38,12 +38,15 @@ from ipex_llm.transformers.models.utils import is_enough_kv_cache_room_4_31, SIL
from ipex_llm.transformers.low_bit_linear import SYM_INT4, FP8E5
from ipex_llm.transformers.models.utils import decoding_fast_path_qtype_check
-KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+import os
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = os.environ.get("KV_CACHE_ALLOC_BLOCK_LENGTH", 256)
def use_decoding_fast_path(proj, use_fuse_rope, enough_kv_room, bs):
return decoding_fast_path_qtype_check(proj) and \
- use_fuse_rope and enough_kv_room and bs == 1
+ use_fuse_rope and enough_kv_room and bs == 1 \
+ and not proj.enable_xetla
def should_use_fuse_rope(self, hidden_states, position_ids):