diff --git a/docs/readthedocs/source/_templates/sidebar_quicklinks.html b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
index 150b5ef7..8bf983bc 100644
--- a/docs/readthedocs/source/_templates/sidebar_quicklinks.html
+++ b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
@@ -29,13 +29,16 @@
Install IPEX-LLM in Docker on Windows with Intel GPU
- Use Text Generation WebUI on Windows with Intel GPU
+ Run Code Copilot (Continue) in VSCode with Intel GPU
- IPEX-LLM Benchmarking
+ Run Text Generation WebUI on Intel GPU
- Use llama.cpp with IPEX-LLM on Intel GPU
+ Run Performance Benchmarking with IPEX-LLM
+
+
+ Run llama.cpp with IPEX-LLM on Intel GPU
diff --git a/docs/readthedocs/source/_toc.yml b/docs/readthedocs/source/_toc.yml
index 507aa869..6ef02e87 100644
--- a/docs/readthedocs/source/_toc.yml
+++ b/docs/readthedocs/source/_toc.yml
@@ -24,6 +24,7 @@ subtrees:
- file: doc/LLM/Quickstart/install_windows_gpu
- file: doc/LLM/Quickstart/docker_windows_gpu
- file: doc/LLM/Quickstart/webui_quickstart
+ - file: doc/LLM/Quickstart/continue_quickstart
- file: doc/LLM/Quickstart/benchmark_quickstart
- file: doc/LLM/Quickstart/llama_cpp_quickstart
- file: doc/LLM/Overview/KeyFeatures/index
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/benchmark_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/benchmark_quickstart.md
index 15639c53..84d80dbd 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/benchmark_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/benchmark_quickstart.md
@@ -1,4 +1,4 @@
-# IPEX-LLM Benchmarking
+# Run Performance Benchmarking with IPEX-LLM
We can do benchmarking for IPEX-LLM on Intel CPUs and GPUs using the benchmark scripts we provide.
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
index c747c82c..addc696a 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
@@ -17,30 +17,14 @@ This guide walks you through setting up and running **Continue** within _Visual
### 1. Install and Run Text Generation WebUI
-Visit [Run Text Generation WebUI Quickstart Guide](webui_quickstart.html), and follow the steps 1) [Install IPEX-LLM](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#install-ipex-llm), 2) [Install WebUI](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#install-the-webui) and 3) [Start the Server](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#start-the-webui-server) to install and start the **Text Generation WebUI API Service**, with a few exceptions as below:
-
-
+Visit [Run Text Generation WebUI Quickstart Guide](webui_quickstart.html), and follow the steps 1) [Install IPEX-LLM](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#install-ipex-llm), 2) [Install WebUI](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#install-the-webui) and 3) [Start the Server](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#start-the-webui-server) to install and start the Text Generation WebUI API Service. **Please pay attention to below items during installation:**
- The Text Generation WebUI API service requires Python version 3.10 or higher. But [IPEX-LLM installation instructions](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#install-ipex-llm) used ``python=3.9`` as default for creating the conda environment. We recommend changing it to ``3.11``, using below command:
```bash
conda create -n llm python=3.11 libuv
```
-- When following instructions in [Install Python Dependencies](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#install-dependencies), install an extra dependency for the API service, i.e. `extensions/openai/requirements.txt`:
- ```cmd
- cd C:\text-generation-webui
- pip install -r requirements_cpu_only.txt
- pip install -r extensions/openai/requirements.txt
- ```
-- When following the instructios in [Launch the Server](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#launch-the-server), add a few additional command line arguments for the API service:
- ```
- python server.py --load-in-4bit --api --api-port 5000 --listen
- ```
+- Remember to launch the server **with API service** as specified in [Launch the Server](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/webui_quickstart.html#launch-the-server)
-```eval_rst
-.. note::
-
- The API server will by default use port ``5000``. To change the port, use ``--api-port 1234`` in the command above. You can also specify using SSL or API Key in the command. Please see `this guide `_ for the full list of arguments.
-```
### 2. Use WebUI to Load Model
@@ -89,7 +73,7 @@ Follow the steps in [Model Download](https://ipex-llm.readthedocs.io/en/latest/d
-## 4. Configure `Continue`
+### 4. Configure `Continue`
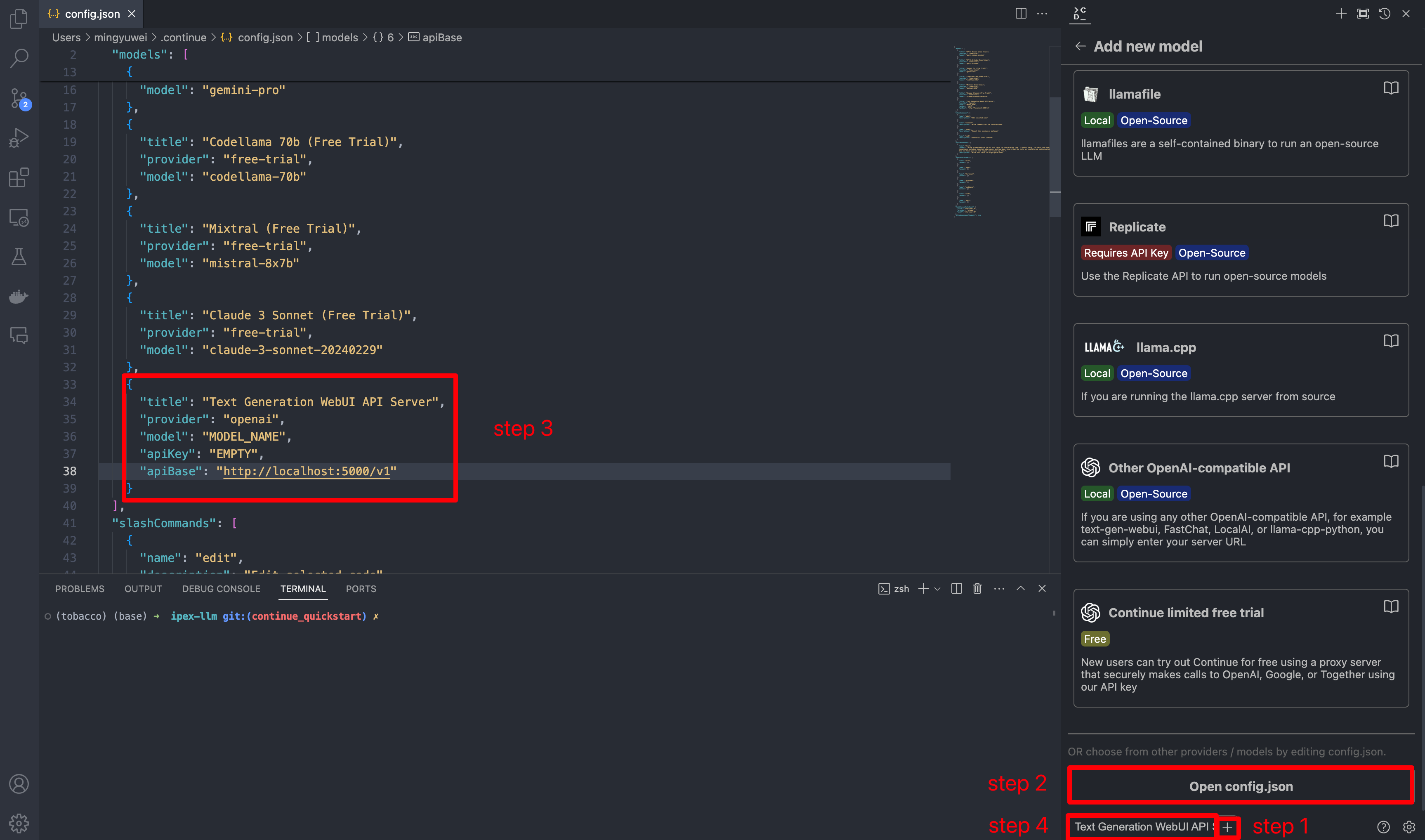 @@ -112,17 +96,17 @@ In `config.json`, you'll find the `models` property, a list of the models that y
}
```
-## 5. How to Use Continue
+### 5. How to Use Continue
For detailed tutorials please refer to [this link](https://continue.dev/docs/how-to-use-continue). Here we are only showing the most common scenarios.
-### Ask about highlighted code or an entire file
+#### Ask about highlighted code or an entire file
If you don't understand how some code works, highlight(press `Ctrl+Shift+L`) it and ask "how does this code work?"
@@ -112,17 +96,17 @@ In `config.json`, you'll find the `models` property, a list of the models that y
}
```
-## 5. How to Use Continue
+### 5. How to Use Continue
For detailed tutorials please refer to [this link](https://continue.dev/docs/how-to-use-continue). Here we are only showing the most common scenarios.
-### Ask about highlighted code or an entire file
+#### Ask about highlighted code or an entire file
If you don't understand how some code works, highlight(press `Ctrl+Shift+L`) it and ask "how does this code work?"
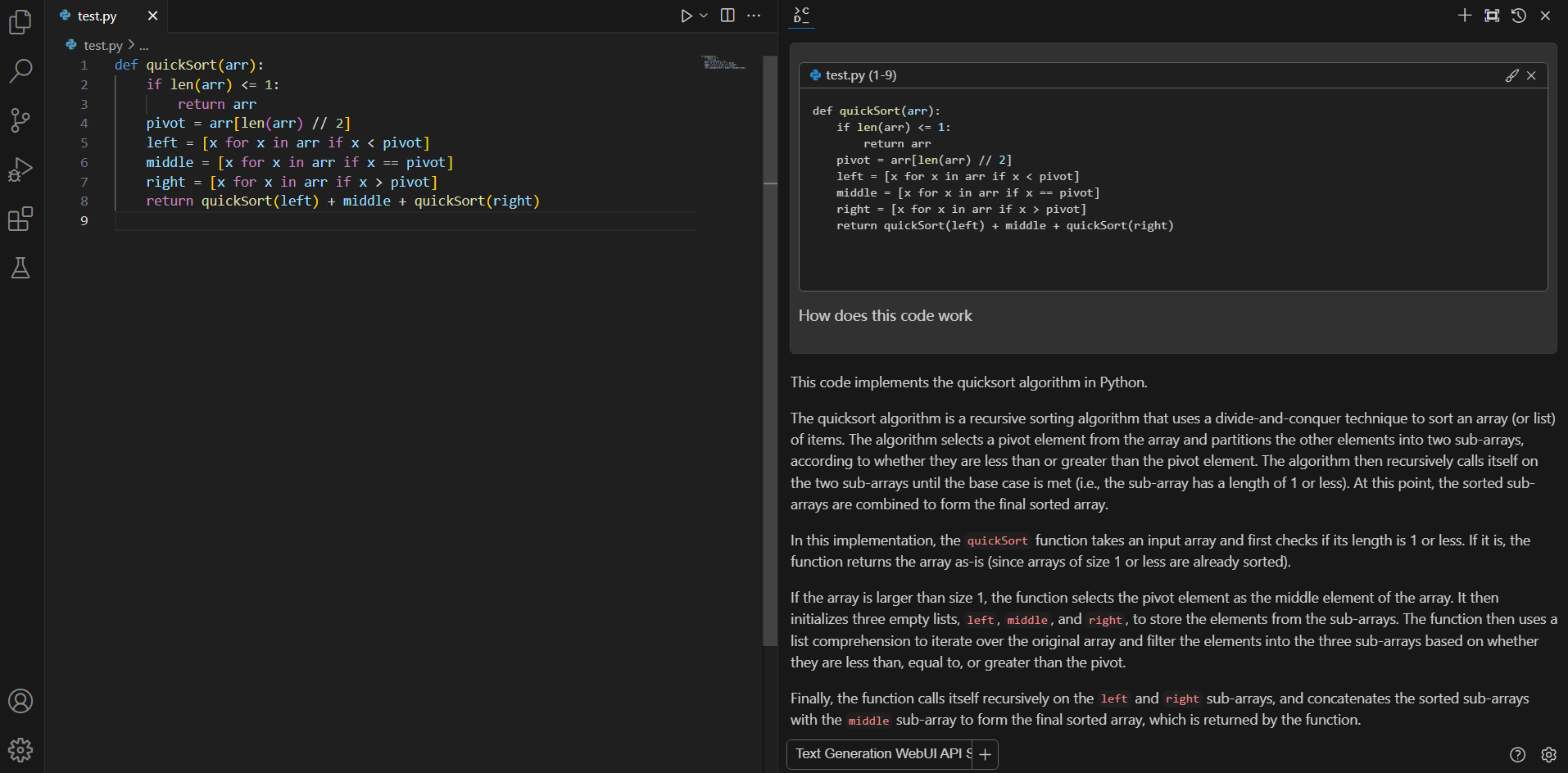 -### Editing existing code
+#### Editing existing code
You can ask Continue to edit your highlighted code with the command `/edit`.
@@ -130,9 +114,9 @@ You can ask Continue to edit your highlighted code with the command `/edit`.
-## Troubleshooting
+### Troubleshooting
-### Failed to load the extension `openai`
+#### Failed to load the extension `openai`
If you encounter `TypeError: unsupported operand type(s) for |: 'type' and 'NoneType'` when you run `python server.py --load-in-4bit --api`, please make sure you are using `Python 3.11` instead of lower versions.
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
index 82222dc1..9fd3107a 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
@@ -1,4 +1,4 @@
-# Use llama.cpp with IPEX-LLM on Intel GPU
+# Run llama.cpp with IPEX-LLM on Intel GPU
Now you can use IPEX-LLM as an Intel GPU accelerated backend of [llama.cpp](https://github.com/ggerganov/llama.cpp). This quickstart guide walks you through setting up and using [llama.cpp](https://github.com/ggerganov/llama.cpp) with `ipex-llm` on Intel GPU (both iGPU and dGPU).
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
index 65d28bb5..ad587b28 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
@@ -36,6 +36,13 @@ Then, change to the directory of WebUI (e.g.,`C:\text-generation-webui`) and ins
```cmd
cd C:\text-generation-webui
pip install -r requirements_cpu_only.txt
+pip install -r extensions/openai/requirements.txt
+```
+
+```eval_rst
+.. note::
+
+ `extensions/openai/requirements.txt` is for API service. If you don't need the API service, you can omit this command.
```
### 3 Start the WebUI Server
@@ -59,17 +66,34 @@ set BIGDL_LLM_XMX_DISABLED=1
```
#### Launch the Server
-In **Anaconda Prompt** with the conda environment `llm` activated, navigate to the text-generation-webui folder and start the server using the following command:
+In **Anaconda Prompt** with the conda environment `llm` activated, navigate to the `text-generation-webui` folder and execute the following commands (You can optionally lanch the server with or without the API service):
+##### without API service
+ ```cmd
+ python server.py --load-in-4bit
+ ```
+##### with API service
+ ```
+ python server.py --load-in-4bit --api --api-port 5000 --listen
+ ```
```eval_rst
.. note::
with ``--load-in-4bit`` option, the models will be optimized and run at 4-bit precision. For configuration for other formats and precisions, refer to `this link `_
```
- ```cmd
- python server.py --load-in-4bit
- ```
+```eval_rst
+.. note::
+
+ The API service allows user to access models using OpenAI-compatible API. For usage examples, refer to [this link](https://github.com/oobabooga/text-generation-webui/wiki/12-%E2%80%90-OpenAI-API#examples)
+```
+
+```eval_rst
+.. note::
+
+ The API server will by default use port ``5000``. To change the port, use ``--api-port 1234`` in the command above. You can also specify using SSL or API Key in the command. Please see `this guide `_ for the full list of arguments.
+```
+
#### Access the WebUI
Upon successful launch, URLs to access the WebUI will be displayed in the terminal as shown below. Open the provided local URL in your browser to interact with the WebUI.
-### Editing existing code
+#### Editing existing code
You can ask Continue to edit your highlighted code with the command `/edit`.
@@ -130,9 +114,9 @@ You can ask Continue to edit your highlighted code with the command `/edit`.
-## Troubleshooting
+### Troubleshooting
-### Failed to load the extension `openai`
+#### Failed to load the extension `openai`
If you encounter `TypeError: unsupported operand type(s) for |: 'type' and 'NoneType'` when you run `python server.py --load-in-4bit --api`, please make sure you are using `Python 3.11` instead of lower versions.
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
index 82222dc1..9fd3107a 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
@@ -1,4 +1,4 @@
-# Use llama.cpp with IPEX-LLM on Intel GPU
+# Run llama.cpp with IPEX-LLM on Intel GPU
Now you can use IPEX-LLM as an Intel GPU accelerated backend of [llama.cpp](https://github.com/ggerganov/llama.cpp). This quickstart guide walks you through setting up and using [llama.cpp](https://github.com/ggerganov/llama.cpp) with `ipex-llm` on Intel GPU (both iGPU and dGPU).
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
index 65d28bb5..ad587b28 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/webui_quickstart.md
@@ -36,6 +36,13 @@ Then, change to the directory of WebUI (e.g.,`C:\text-generation-webui`) and ins
```cmd
cd C:\text-generation-webui
pip install -r requirements_cpu_only.txt
+pip install -r extensions/openai/requirements.txt
+```
+
+```eval_rst
+.. note::
+
+ `extensions/openai/requirements.txt` is for API service. If you don't need the API service, you can omit this command.
```
### 3 Start the WebUI Server
@@ -59,17 +66,34 @@ set BIGDL_LLM_XMX_DISABLED=1
```
#### Launch the Server
-In **Anaconda Prompt** with the conda environment `llm` activated, navigate to the text-generation-webui folder and start the server using the following command:
+In **Anaconda Prompt** with the conda environment `llm` activated, navigate to the `text-generation-webui` folder and execute the following commands (You can optionally lanch the server with or without the API service):
+##### without API service
+ ```cmd
+ python server.py --load-in-4bit
+ ```
+##### with API service
+ ```
+ python server.py --load-in-4bit --api --api-port 5000 --listen
+ ```
```eval_rst
.. note::
with ``--load-in-4bit`` option, the models will be optimized and run at 4-bit precision. For configuration for other formats and precisions, refer to `this link `_
```
- ```cmd
- python server.py --load-in-4bit
- ```
+```eval_rst
+.. note::
+
+ The API service allows user to access models using OpenAI-compatible API. For usage examples, refer to [this link](https://github.com/oobabooga/text-generation-webui/wiki/12-%E2%80%90-OpenAI-API#examples)
+```
+
+```eval_rst
+.. note::
+
+ The API server will by default use port ``5000``. To change the port, use ``--api-port 1234`` in the command above. You can also specify using SSL or API Key in the command. Please see `this guide `_ for the full list of arguments.
+```
+
#### Access the WebUI
Upon successful launch, URLs to access the WebUI will be displayed in the terminal as shown below. Open the provided local URL in your browser to interact with the WebUI.