diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
index 78e606d0..08f7aadd 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/continue_quickstart.md
@@ -3,18 +3,9 @@
[**Continue**](https://marketplace.visualstudio.com/items?itemName=Continue.continue) is a coding copilot extension in [Microsoft Visual Studio Code](https://code.visualstudio.com/); by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily leverage local LLMs running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) for code explanation, code generation/completion, etc.
-See the demos of using Continue with [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) running on Intel A770 GPU below.
+Below is a demo of using `Continue` with [CodeQWen1.5-7B](https://huggingface.co/Qwen/CodeQwen1.5-7B-Chat) running on Intel A770 GPU. This demo illustrates how a programmer used `Continue` to find a solution for the [Kaggle's _Titanic_ challenge](https://www.kaggle.com/competitions/titanic/), which involves asking `Continue` to complete the code for model fitting, evaluation, hyper parameter tuning, feature engineering, and explain generated code.
-
-
- | Code Generation |
- Code Explanation |
-
-
- |
- |
-
-
+
## Quickstart
@@ -22,27 +13,29 @@ This guide walks you through setting up and running **Continue** within _Visual
### 1. Install and Run Ollama Serve
-Visit [Run Ollama with IPEX-LLM on Intel GPU](./ollama_quickstart.html), and follow the steps 1) [Install IPEX-LLM for Ollama](./ollama_quickstart.html#install-ipex-llm-for-ollama), 2) [Initialize Ollama](./ollama_quickstart.html#initialize-ollama) and 3) [Run Ollama Serve](./ollama_quickstart.html#run-ollama-serve) to install and initialize and start the Ollama Service.
+Visit [Run Ollama with IPEX-LLM on Intel GPU](./ollama_quickstart.html), and follow the steps 1) [Install IPEX-LLM for Ollama](./ollama_quickstart.html#install-ipex-llm-for-ollama), 2) [Initialize Ollama](./ollama_quickstart.html#initialize-ollama) 3) [Run Ollama Serve](./ollama_quickstart.html#run-ollama-serve) to install, init and start the Ollama Service.
+
```eval_rst
.. important::
- Please make sure you have set ``OLLAMA_HOST=0.0.0.0`` before starting the Ollama service, so that connections from all IP addresses can be accepted.
+ If the `Continue` plugin is not installed on the same machine where Ollama is running (which means `Continue` needs to connect to a remote Ollama service), you must configure the Ollama service to accept connections from any IP address. To achieve this, set or export the environment variable `OLLAMA_HOST=0.0.0.0` before executing the command `ollama serve`.
.. tip::
- If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS, it is recommended to additionaly set the following environment variable for optimal performance before the Ollama service is started:
+ If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS, it is recommended to additionaly set the following environment variable for optimal performance before executing `ollama serve`:
.. code-block:: bash
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
```
-### 2. Prepare and Run Model
+### 2. Pull and Prepare the Model
-#### Pull [`codeqwen:latest`](https://ollama.com/library/codeqwen)
+#### 2.1 Pull Model
+
+Now we need to pull a model for coding. Here we use [CodeQWen1.5-7B](https://huggingface.co/Qwen/CodeQwen1.5-7B-Chat) model as an example. Open a new terminal window, run the following command to pull [`codeqwen:latest`](https://ollama.com/library/codeqwen).
-In a new terminal window:
```eval_rst
.. tabs::
@@ -64,124 +57,113 @@ In a new terminal window:
.. seealso::
- Here's a list of models that can be used for coding copilot on local PC:
-
- - Code Llama:
- - WizardCoder
- - Mistral
- - StarCoder
- - DeepSeek Coder
-
- You could find them in the `Ollama model library `_ and have a try.
+ Besides CodeQWen, there are other coding models you might want to explore, such as Magicoder, Wizardcoder, Codellama, Codegemma, Starcoder, Starcoder2, and etc. You can find these models in the `Ollama model library `_. Simply search for the model, pull it in a similar manner, and give it a try.
```
-#### Create and Run Model
+#### 2.2 Prepare the Model and Pre-load
-First, create a `Modelfile` file with contents:
+To make `Continue` run more smoothly with Ollama, we will create a new model in Ollama using the original model with an adjusted num_ctx parameter of 4096.
-```
+Start by creating a file named `Modelfile` with the following content:
+
+
+```dockerfile
FROM codeqwen:latest
PARAMETER num_ctx 4096
```
+Next, use the following commands in the terminal (Linux) or Anaconda Prompt (Windows) to create a new model in Ollama named `codeqwen:latest-continue`:
-then:
-```eval_rst
-.. tabs::
- .. tab:: Linux
-
- .. code-block:: bash
-
- ./ollama create codeqwen:latest-continue -f Modelfile
-
- .. tab:: Windows
-
- Please run the following command in Anaconda Prompt.
-
- .. code-block:: cmd
-
- ollama create codeqwen:latest-continue -f Modelfile
+```bash
+ ollama create codeqwen:latest-continue -f Modelfile
```
-You can now find `codeqwen:latest-continue` in `ollama list`.
+After creation, run `ollama list` to see `codeqwen:latest-continue` in the list of models.
-Finially, run the `codeqwen:latest-continue`:
+Finally, preload the new model by executing the following command in a new terminal (Linux) or Anaconda prompt (Windows):
-```eval_rst
-.. tabs::
- .. tab:: Linux
-
- .. code-block:: bash
-
- ./ollama run codeqwen:latest-continue
-
- .. tab:: Windows
-
- Please run the following command in Anaconda Prompt.
-
- .. code-block:: cmd
-
- ollama run codeqwen:latest-continue
+```bash
+ollama run codeqwen:latest-continue
```
+
+
### 3. Install `Continue` Extension
-1. Click `Install` on the [Continue extension in the Visual Studio Marketplace](https://marketplace.visualstudio.com/items?itemName=Continue.continue)
-2. This will open the Continue extension page in VS Code, where you will need to click `Install` again
-3. Once you do this, you will see the Continue logo show up on the left side bar. If you click it, the Continue extension will open up:
-
-  +Search for `Continue` in the VSCode `Extensions Marketplace` and install it just like any other extension.
+
+
+Search for `Continue` in the VSCode `Extensions Marketplace` and install it just like any other extension.
+
+  -```eval_rst
-.. note::
+
-```eval_rst
-.. note::
+
- Note: We strongly recommend moving Continue to VS Code's right sidebar. This helps keep the file explorer open while using Continue, and the sidebar can be toggled with a simple keyboard shortcut.
-```
-
-### 4. Configure `Continue`
-
-
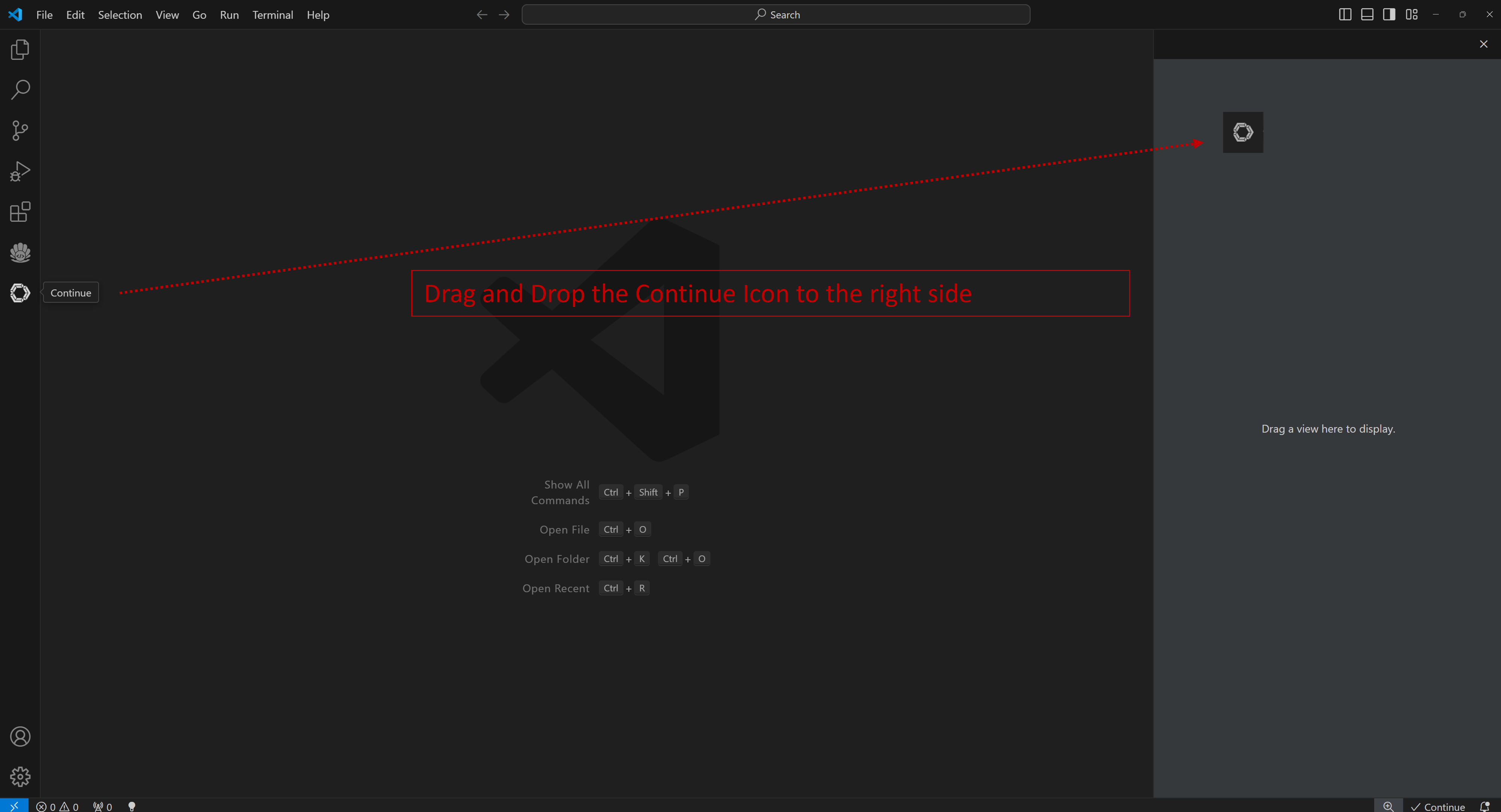
-  +Once installed, the `Continue` icon will appear on the left sidebar. You can drag and drop the icon to the right sidebar for easy access to the `Continue` view.
+
+
+Once installed, the `Continue` icon will appear on the left sidebar. You can drag and drop the icon to the right sidebar for easy access to the `Continue` view.
+
+  -Once you've started the API server, you can now use your local LLMs on Continue. After opening Continue(you can either click the extension icon on the left sidebar or press `Ctrl+Shift+L`), you can click the `+` button next to the model dropdown, and scroll down to the bottom and click `Open config.json`.
+
-Once you've started the API server, you can now use your local LLMs on Continue. After opening Continue(you can either click the extension icon on the left sidebar or press `Ctrl+Shift+L`), you can click the `+` button next to the model dropdown, and scroll down to the bottom and click `Open config.json`.
+
+
+If the icon does not appear or you cannot open the view, press `Ctrl+Shift+L` or follow the steps below to open the `Continue` view on the right side.
+
+ 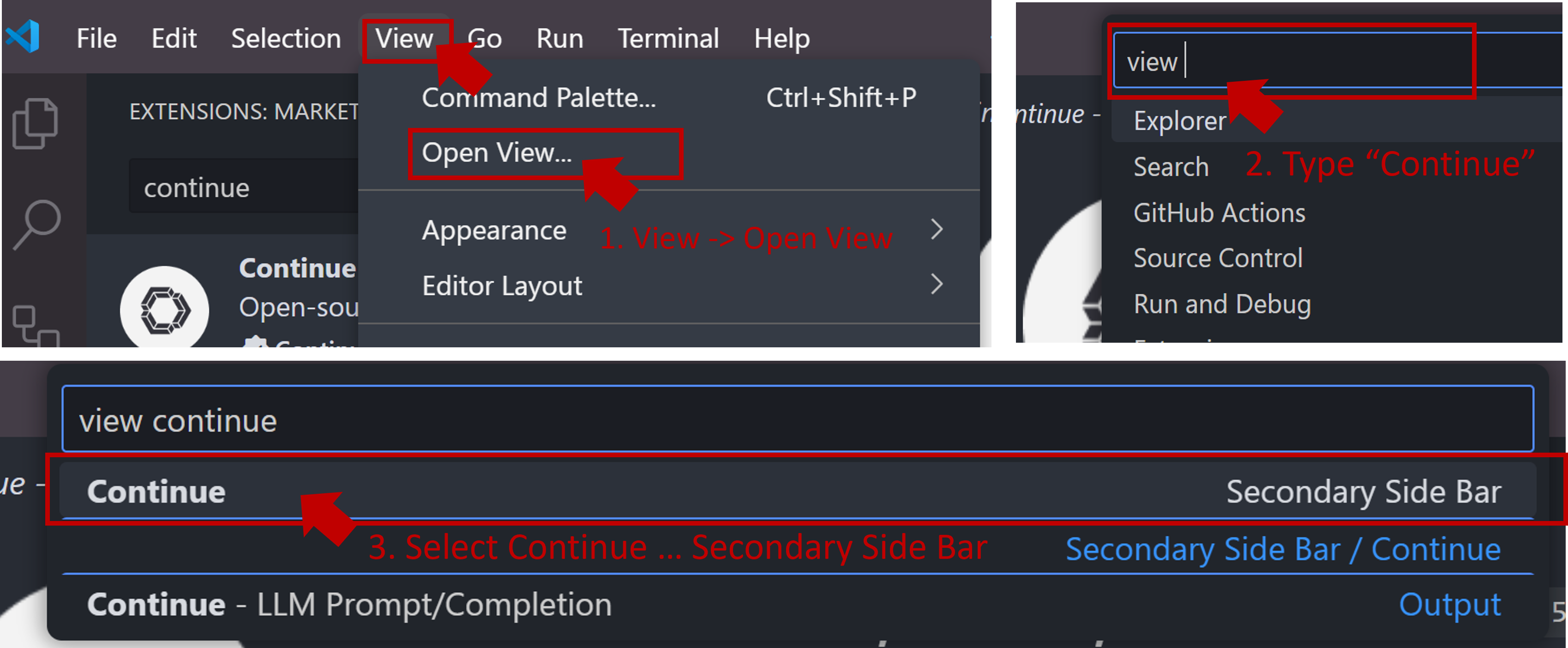 +
+
+
+
+
+
+
+Once you have successfully opened the `Continue` view, you will see the welcome screen as shown below. Select **Fully local** -> **Continue** -> **Continue** as illustrated.
+
+ 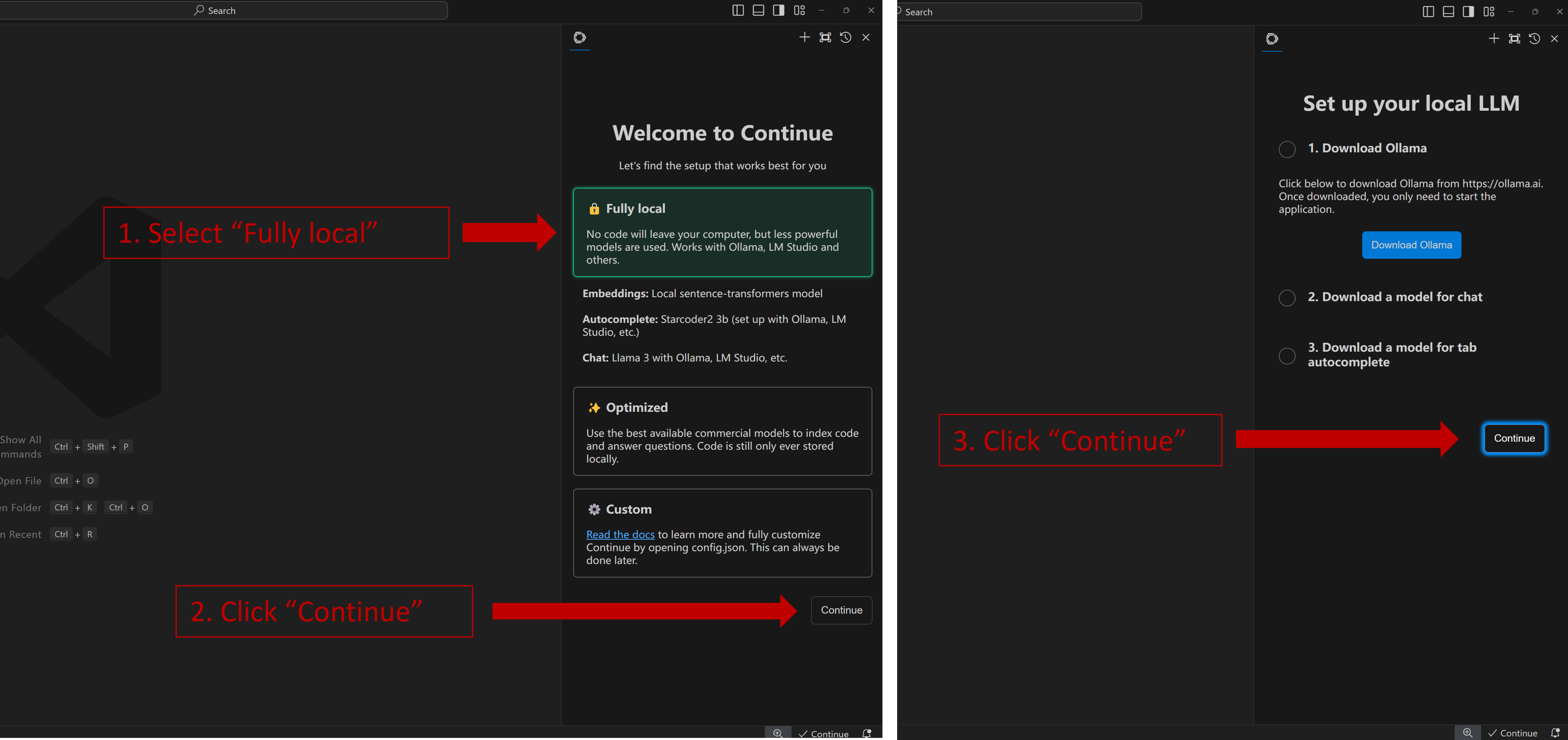 +
+
+When you see the screen below, your plug-in is ready to use.
+
+
+
+
+
+When you see the screen below, your plug-in is ready to use.
+
+
+ 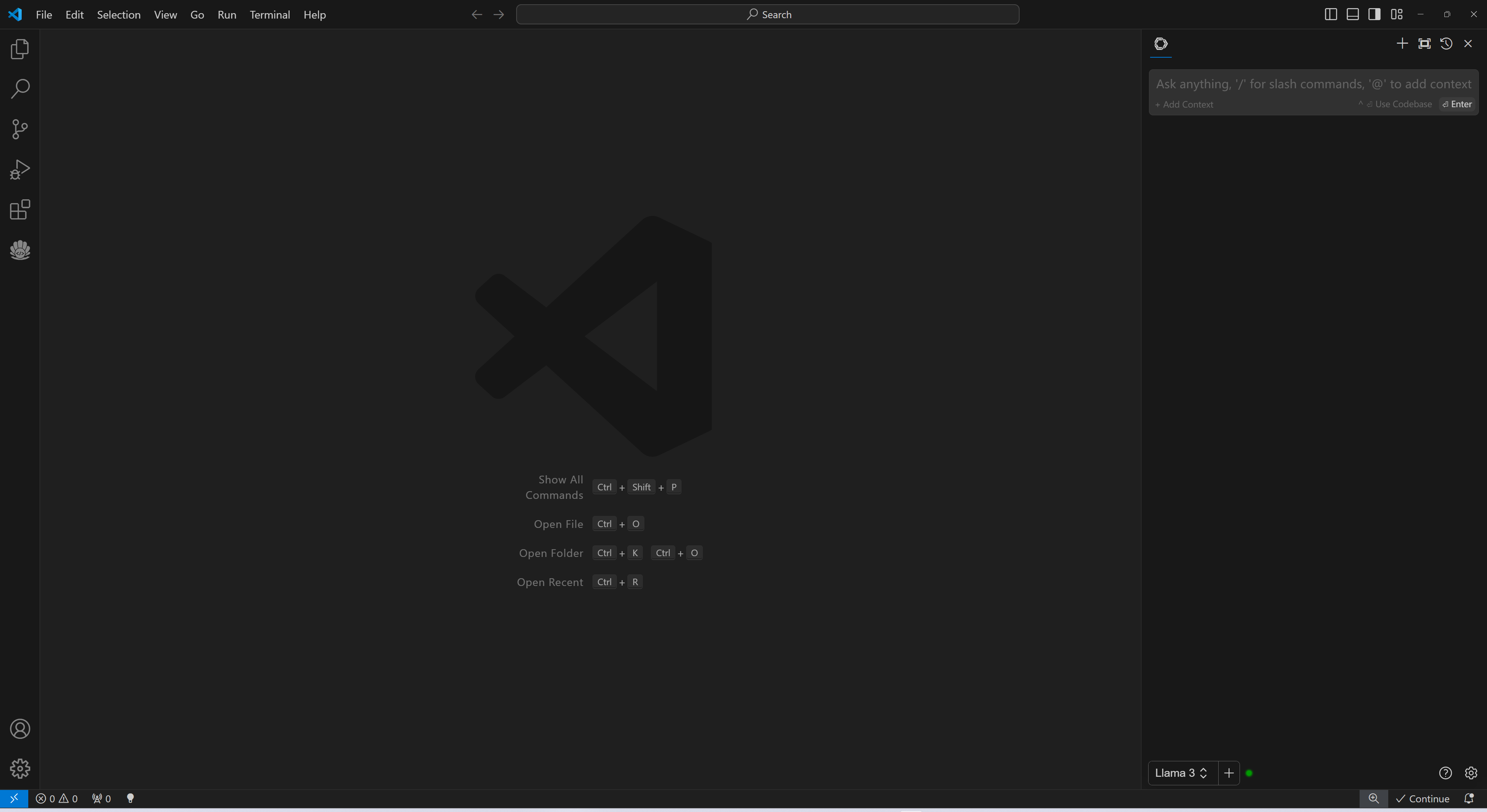 +
+
+### 4. `Continue` Configuration
+
+Once `Continue` is installed and ready, simply select the model "`Ollama - codeqwen:latest-continue`" from the bottom of the `Continue` view (all models in `ollama list` will appear in the format `Ollama-xxx`).
+
+Now you can start using `Continue`.
+
+#### Connecting to Remote Ollama Service
+
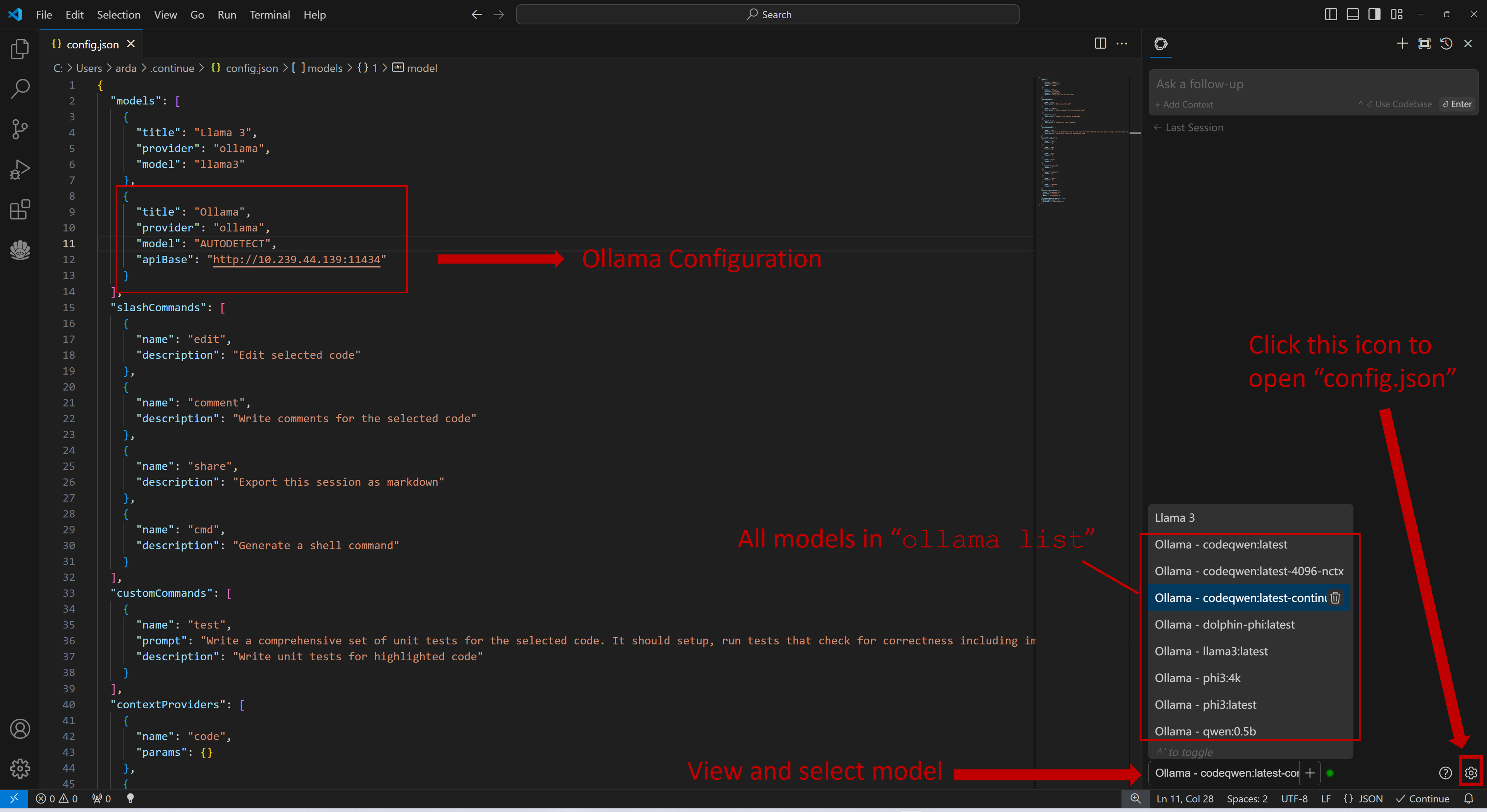
+You can configure `Continue` by clicking the small gear icon located at the bottom right of the `Continue` view to open `config.json`. In `config.json`, you will find all necessary configuration settings.
+
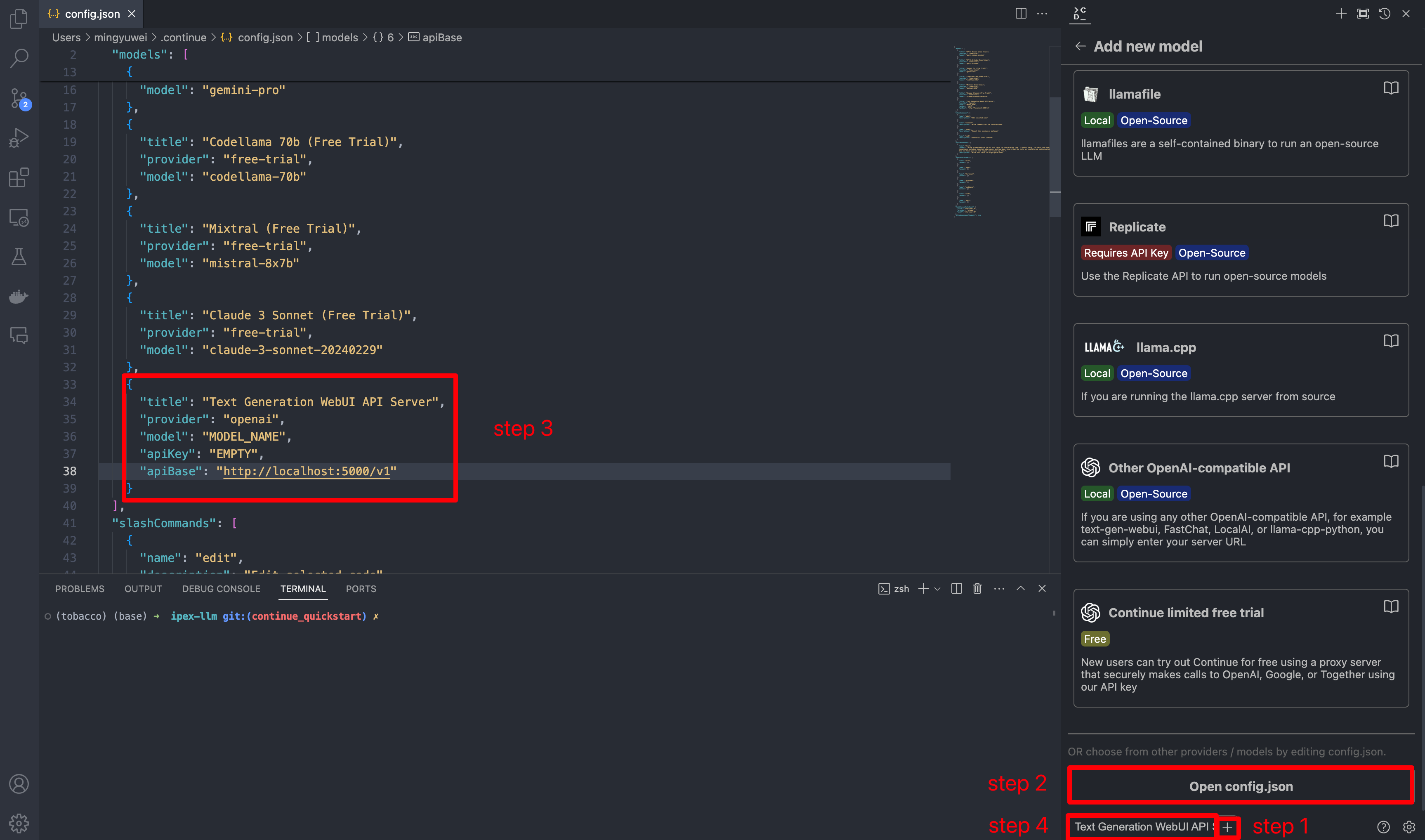
+If you are running Ollama on the same machine as `Continue`, no changes are necessary. If Ollama is running on a different machine, you'll need to update the `apiBase` key in `Ollama` item in `config.json` to point to the remote Ollama URL, as shown in the example below and in the figure.
-In `config.json`, you'll find the `models` property, a list of the models that you have saved to use with Continue. Please add the following configuration to `models`. Note that `model`, `apiKey`, `apiBase` should align with what you specified when starting the `Text Generation WebUI` server. Finally, remember to select this model in the model dropdown menu.
```json
-{
- "models": [
{
- "title": "Text Generation WebUI API Server",
- "provider": "openai",
- "model": "MODEL_NAME",
- "apiKey": "EMPTY",
- "apiBase": "http://localhost:5000/v1"
+ "title": "Ollama",
+ "provider": "ollama",
+ "model": "AUTODETECT",
+ "apiBase": "http://your-ollama-service-ip:11434"
}
- ]
-}
```
+
+
+
+
+### 4. `Continue` Configuration
+
+Once `Continue` is installed and ready, simply select the model "`Ollama - codeqwen:latest-continue`" from the bottom of the `Continue` view (all models in `ollama list` will appear in the format `Ollama-xxx`).
+
+Now you can start using `Continue`.
+
+#### Connecting to Remote Ollama Service
+
+You can configure `Continue` by clicking the small gear icon located at the bottom right of the `Continue` view to open `config.json`. In `config.json`, you will find all necessary configuration settings.
+
+If you are running Ollama on the same machine as `Continue`, no changes are necessary. If Ollama is running on a different machine, you'll need to update the `apiBase` key in `Ollama` item in `config.json` to point to the remote Ollama URL, as shown in the example below and in the figure.
-In `config.json`, you'll find the `models` property, a list of the models that you have saved to use with Continue. Please add the following configuration to `models`. Note that `model`, `apiKey`, `apiBase` should align with what you specified when starting the `Text Generation WebUI` server. Finally, remember to select this model in the model dropdown menu.
```json
-{
- "models": [
{
- "title": "Text Generation WebUI API Server",
- "provider": "openai",
- "model": "MODEL_NAME",
- "apiKey": "EMPTY",
- "apiBase": "http://localhost:5000/v1"
+ "title": "Ollama",
+ "provider": "ollama",
+ "model": "AUTODETECT",
+ "apiBase": "http://your-ollama-service-ip:11434"
}
- ]
-}
```
+
+  +
+
+
+
### 5. How to Use `Continue`
For detailed tutorials please refer to [this link](https://continue.dev/docs/how-to-use-continue). Here we are only showing the most common scenarios.
-#### Ask about highlighted code or an entire file
+#### Q&A over specific code
If you don't understand how some code works, highlight(press `Ctrl+Shift+L`) it and ask "how does this code work?"
+
+
+
+
### 5. How to Use `Continue`
For detailed tutorials please refer to [this link](https://continue.dev/docs/how-to-use-continue). Here we are only showing the most common scenarios.
-#### Ask about highlighted code or an entire file
+#### Q&A over specific code
If you don't understand how some code works, highlight(press `Ctrl+Shift+L`) it and ask "how does this code work?"
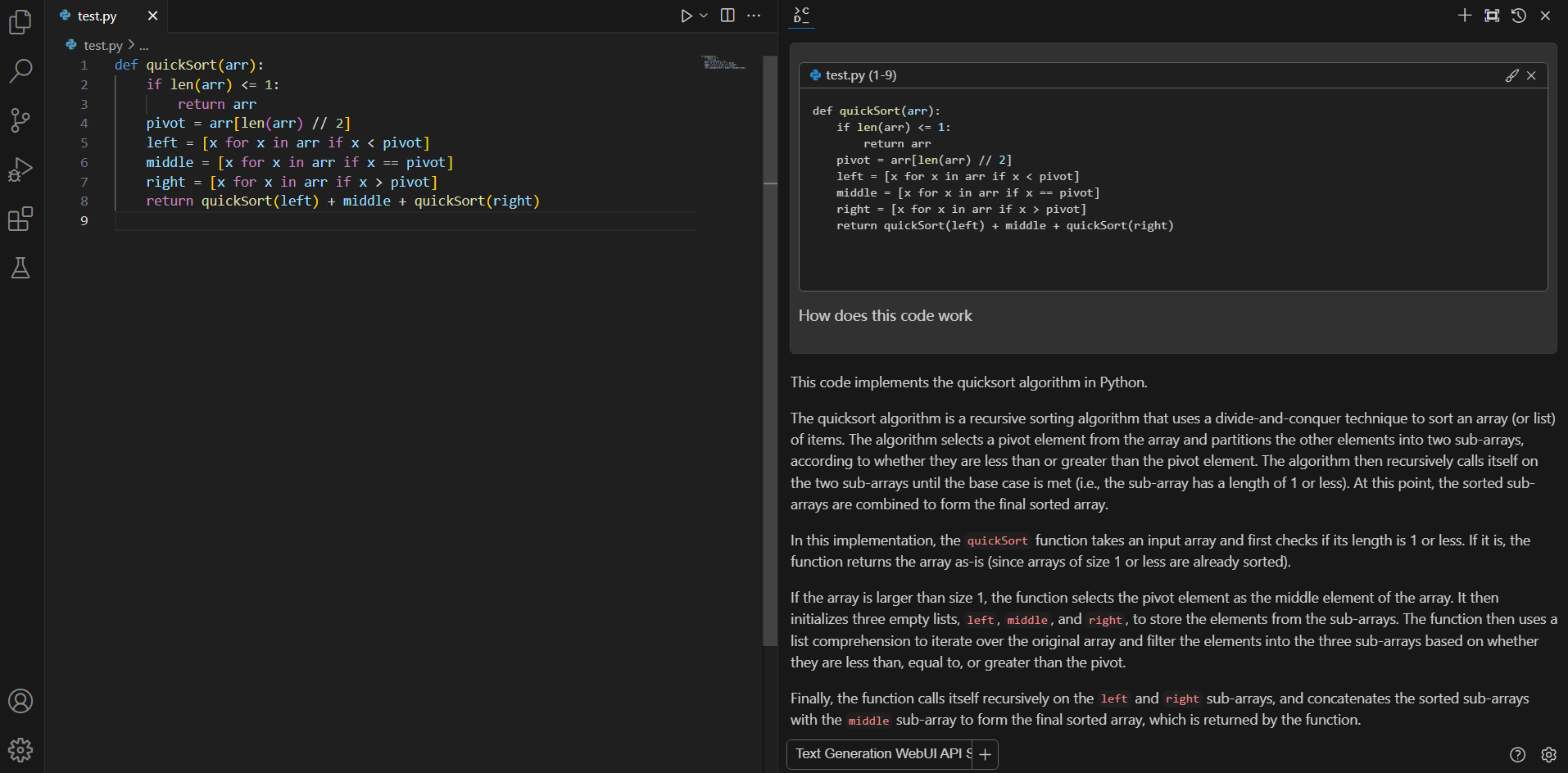 -#### Editing existing code
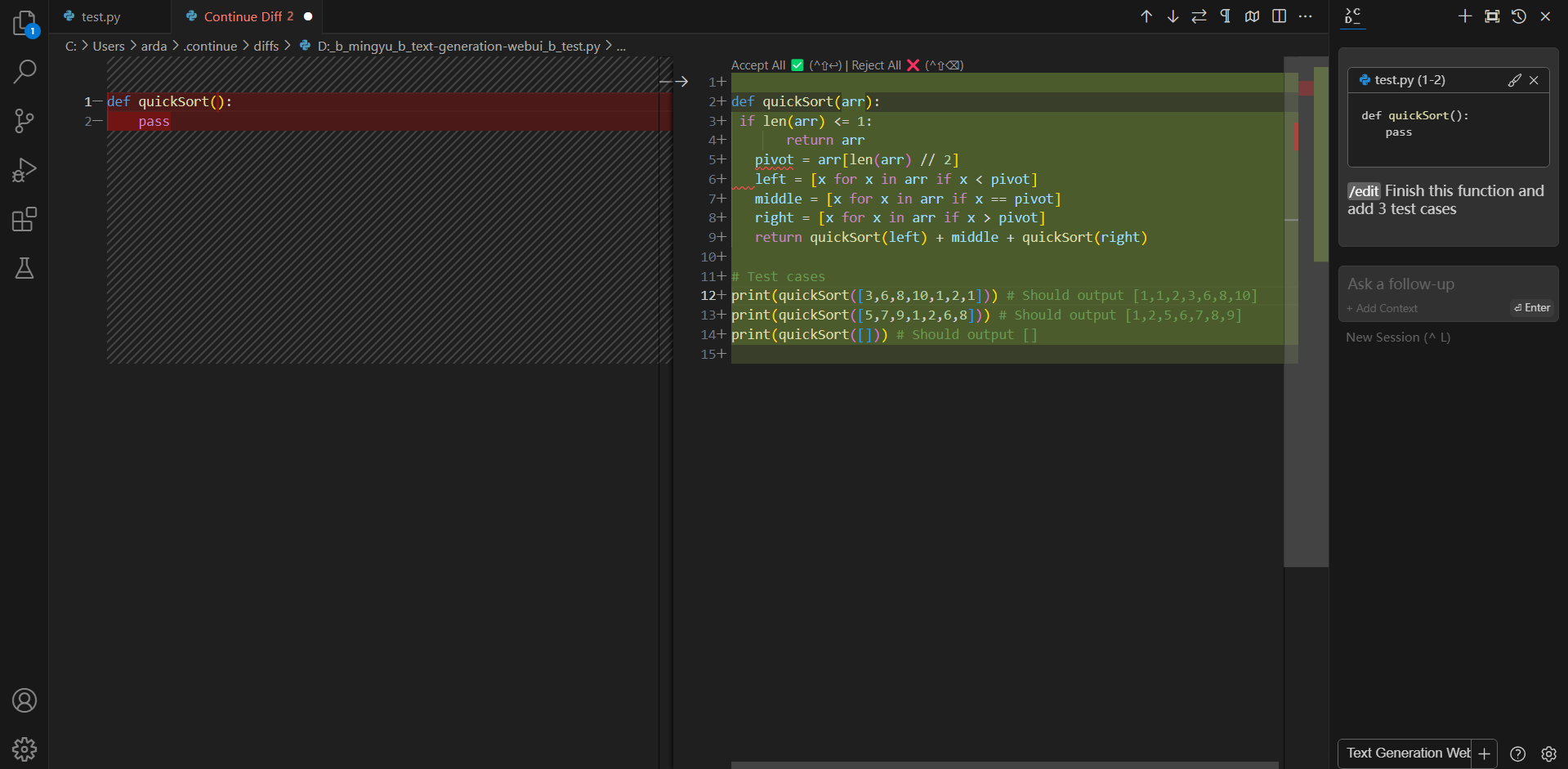
+#### Editing code
You can ask Continue to edit your highlighted code with the command `/edit`.
-#### Editing existing code
+#### Editing code
You can ask Continue to edit your highlighted code with the command `/edit`.
 -### Troubleshooting
-
-#### Failed to load the extension `openai`
-
-If you encounter `TypeError: unsupported operand type(s) for |: 'type' and 'NoneType'` when you run `python server.py --load-in-4bit --api`, please make sure you are using `Python 3.11` instead of lower versions.
-### Troubleshooting
-
-#### Failed to load the extension `openai`
-
-If you encounter `TypeError: unsupported operand type(s) for |: 'type' and 'NoneType'` when you run `python server.py --load-in-4bit --api`, please make sure you are using `Python 3.11` instead of lower versions.