diff --git a/python/llm/portable-executable/.gitignore b/python/llm/portable-executable/.gitignore
new file mode 100644
index 00000000..23c0161c
--- /dev/null
+++ b/python/llm/portable-executable/.gitignore
@@ -0,0 +1,2 @@
+python-embed
+portable-executable.zip
\ No newline at end of file
diff --git a/python/llm/portable-executable/README.md b/python/llm/portable-executable/README.md
new file mode 100644
index 00000000..0f1df88f
--- /dev/null
+++ b/python/llm/portable-executable/README.md
@@ -0,0 +1,33 @@
+# BigDL-LLM Portable Executable For Windows: User Guide
+
+This portable executable includes everything you need to run LLM (except models). Please refer to How to use section to get started.
+
+## 13B model running on an Intel 11-Gen Core PC (real-time screen capture)
+
+
+  +
+
+
+
+
+## Verified Models
+
+- ChatGLM2-6b
+- Baichuan-13B-Chat
+- Baichuan2-7B-Chat
+- internlm-chat-7b-8k
+- Llama-2-7b-chat-hf
+
+## How to use
+
+1. Download the model to your computer. Please ensure there is a file named `config.json` in the model folder, otherwise the script won't work.
+
+ 
+
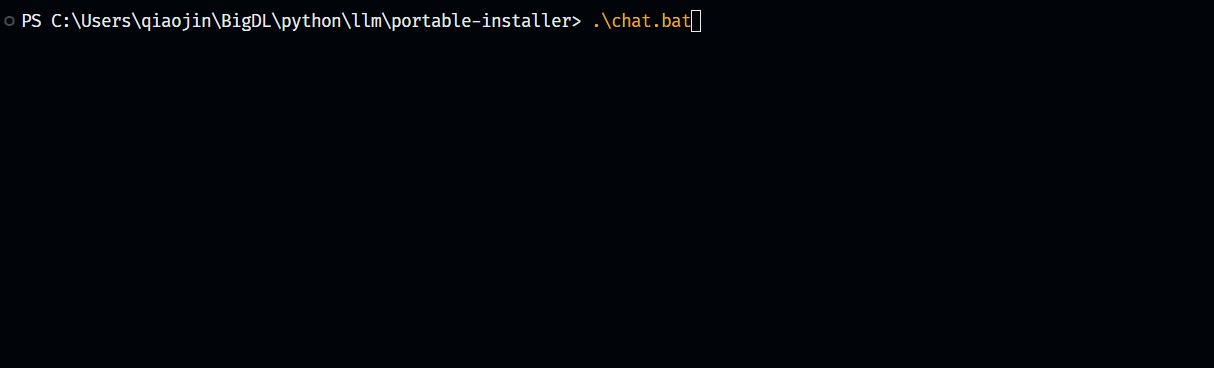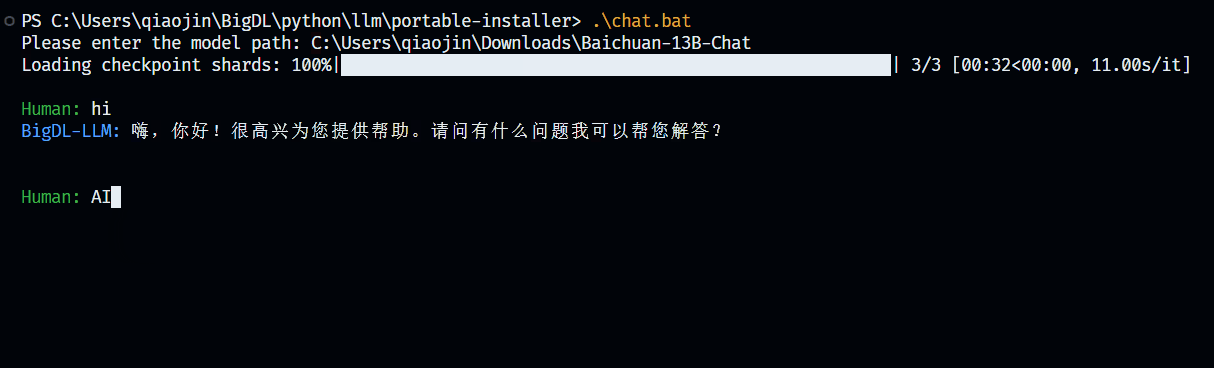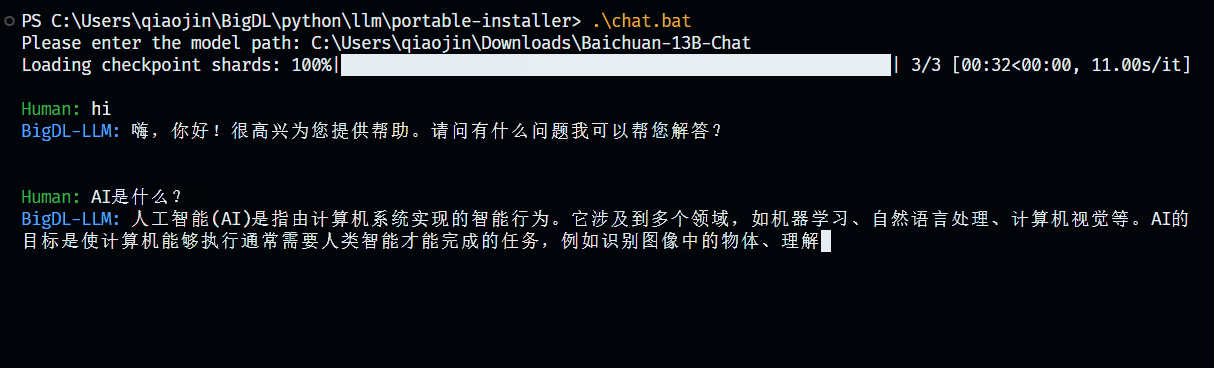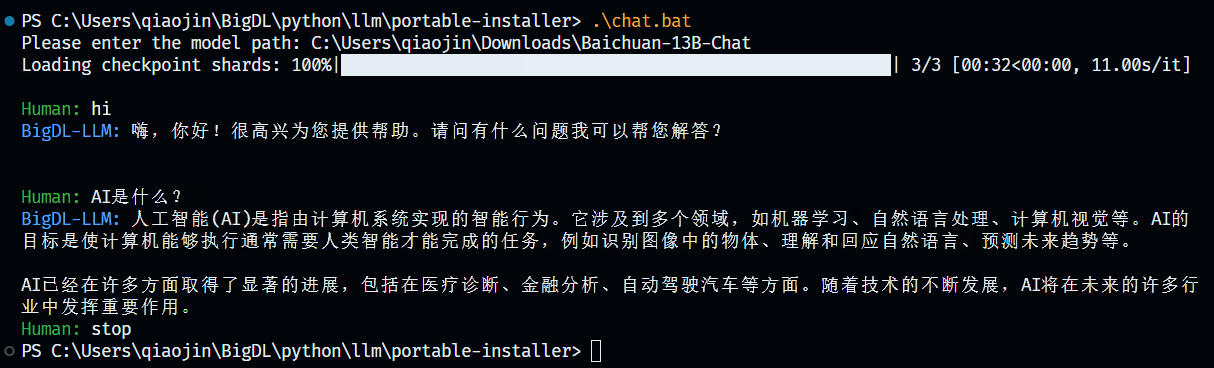
+2. Run `chat.bat` in Terminal and input the path of the model (e.g. `path\to\model`, note that there's no slash at the end of the path).
+
+ 
+
+3. Press Enter and wait until model finishes loading. Then enjoy chatting with the model!
+4. If you want to stop chatting, just input `stop` and the model will stop running.
+
+ 
diff --git a/python/llm/portable-executable/chat.bat b/python/llm/portable-executable/chat.bat
new file mode 100644
index 00000000..b02c9615
--- /dev/null
+++ b/python/llm/portable-executable/chat.bat
@@ -0,0 +1,8 @@
+@echo off
+
+
+:: execute chat script
+set PYTHONUNBUFFERED=1
+
+set /p modelpath="Please enter the model path: "
+.\python-embed\python.exe .\chat.py --model-path="%modelpath%"
\ No newline at end of file
diff --git a/python/llm/portable-executable/chat.py b/python/llm/portable-executable/chat.py
new file mode 100644
index 00000000..8a282a97
--- /dev/null
+++ b/python/llm/portable-executable/chat.py
@@ -0,0 +1,116 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import torch
+import argparse
+import sys
+
+# todo: support more model class
+from transformers import AutoModel, AutoModelForCausalLM, AutoTokenizer, AutoConfig
+from transformers import TextIteratorStreamer
+from transformers.tools.agents import StopSequenceCriteria
+from transformers.generation.stopping_criteria import StoppingCriteriaList
+
+from colorama import Fore
+
+from bigdl.llm import optimize_model
+
+SYSTEM_PROMPT = "A chat between a curious human and an artificial intelligence assistant .\
+The assistant gives helpful, detailed, and polite answers to the human's questions."
+HUMAN_ID = ""
+BOT_ID = ""
+
+# chat_history formated in [(iput_str, output_str)]
+def format_prompt(input_str,
+ chat_history):
+ prompt = [f"{SYSTEM_PROMPT}\n"]
+ for history_input_str, history_output_str in chat_history:
+ prompt.append(f"{HUMAN_ID} {history_input_str}\n{BOT_ID} {history_output_str}\n")
+ prompt.append(f"{HUMAN_ID} {input_str}\n{BOT_ID} ")
+
+ return "".join(prompt)
+
+def stream_chat(model,
+ tokenizer,
+ stopping_criteria,
+ input_str,
+ chat_history):
+ prompt = format_prompt(input_str, chat_history)
+ # print(prompt)
+ input_ids = tokenizer([prompt], return_tensors="pt")
+ streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
+ generate_kwargs = dict(input_ids, streamer=streamer, max_new_tokens=512, stopping_criteria=stopping_criteria)
+
+ from threading import Thread
+ # to ensure non-blocking access to the generated text, generation process should be ran in a separate thread
+ thread = Thread(target=model.generate, kwargs=generate_kwargs)
+ thread.start()
+
+ output_str = []
+ print(Fore.BLUE+"BigDL-LLM: "+Fore.RESET, end="")
+ for partial_output_str in streamer:
+ output_str.append(partial_output_str)
+ # remove the last HUMAN_ID if exists
+ print(partial_output_str.replace(f"{HUMAN_ID}", ""), end="")
+
+ chat_history.append((input_str, "".join(output_str).replace(f"{HUMAN_ID}", "").rstrip()))
+
+def auto_select_model(model_name):
+ try:
+ try:
+ model = AutoModelForCausalLM.from_pretrained(model_path,
+ low_cpu_mem_usage=True,
+ torch_dtype="auto",
+ trust_remote_code=True,
+ use_cache=True)
+ except:
+ model = AutoModel.from_pretrained(model_path,
+ low_cpu_mem_usage=True,
+ torch_dtype="auto",
+ trust_remote_code=True,
+ use_cache=True)
+ except:
+ print("Sorry, the model you entered is not supported in installer.")
+ sys.exit()
+
+ return model
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model-path", type=str, help="path to an llm")
+ args = parser.parse_args()
+
+ model_path = args.model_path
+
+ model = auto_select_model(model_path)
+ model = optimize_model(model)
+
+ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
+
+ stopping_criteria = StoppingCriteriaList([StopSequenceCriteria(HUMAN_ID, tokenizer)])
+
+ chat_history = []
+
+ while True:
+ with torch.inference_mode():
+ user_input = input(Fore.GREEN+"\nHuman: "+Fore.RESET)
+ if user_input == "stop": # let's stop the conversation when user input "stop"
+ break
+ stream_chat(model=model,
+ tokenizer=tokenizer,
+ stopping_criteria=stopping_criteria,
+ input_str=user_input,
+ chat_history=chat_history)
\ No newline at end of file
diff --git a/python/llm/portable-executable/setup.bat b/python/llm/portable-executable/setup.bat
new file mode 100644
index 00000000..de8ad28c
--- /dev/null
+++ b/python/llm/portable-executable/setup.bat
@@ -0,0 +1,23 @@
+:: download python and extract zip
+powershell -Command "Start-BitsTransfer -Source https://www.python.org/ftp/python/3.9.13/python-3.9.13-embed-amd64.zip -Destination python-3.9.13-embed-amd64.zip"
+powershell -Command "Expand-Archive .\python-3.9.13-embed-amd64.zip -DestinationPath .\python-embed"
+del .\python-3.9.13-embed-amd64.zip
+
+set "python-embed=.\python-embed\python.exe"
+
+:: download get-pip.py and install
+powershell -Command "Invoke-WebRequest https://bootstrap.pypa.io/get-pip.py -OutFile .\python-embed\get-pip.py"
+%python-embed% .\python-embed\get-pip.py
+
+:: enable run site.main() automatically
+cd .\python-embed
+set "search=#import site"
+set "replace=import site"
+powershell -Command "(gc python39._pth) -replace '%search%', '%replace%' | Out-File -encoding ASCII python39._pth"
+cd ..
+
+:: install pip packages
+%python-embed% -m pip install bigdl-llm[all] transformers_stream_generator tiktoken einops colorama
+
+:: compress the python and scripts
+powershell -Command "Compress-Archive -Path '.\python-embed', '.\chat.bat', '.\chat.py', '.\README.md' -DestinationPath .\portable-executable.zip"
diff --git a/python/llm/portable-executable/setup.md b/python/llm/portable-executable/setup.md
new file mode 100644
index 00000000..22520c64
--- /dev/null
+++ b/python/llm/portable-executable/setup.md
@@ -0,0 +1,5 @@
+# BigDL-LLM Portable Executable Setup Script For Windows
+
+# How to use
+
+Just simply run `setup.bat` and it will download and install all dependency and generate a zip file for user to use.